2026 年,「AI Scientist」大概是 AI 圈最拥挤的赛道。自动读文献、自动提假设、自动跑实验、自动写论文的智能体,每个月都在刷新纪录。
但热闹之中,有一个问题很少被认真问出来:假如明天我们就拥有了一个不知疲倦、和顶尖人类研究员一样聪明的 AI 科学家——科学,会因此快多少?
密歇根大学计算机科学博士 Jiachen Liu 最近发布的技术博客《The Second Half of AI for Science》给出的答案,可能会让不少人不舒服:快不了多少。
真正卡住科学的,从来不是科学家的聪明程度,而是一个三百年没换过的底层协议。配套论文的标题起得更直接——The Last Human-Written Paper,最后一篇人类撰写的论文。

论文标题:
The Last Human-Written Paper
论文链接:
https://arxiv.org/abs/2604.24658
代码链接:
https://github.com/ARA-Labs/Agent-Native-Research-Artifact
博客原文(英文):
https://amberljc.github.io/blog/2026-06-10-second-half-of-ai-for-science.html
上半场:所有人都在给同一个节点加 buff
回看过去几年的 AI for Science,打法出奇地一致:给 AI 科学家加 scaffolding、加记忆、加多智能体编排、加自进化循环,然后在某个 benchmark 上涨几个点,发一个炫酷的 demo,再从头来一遍。
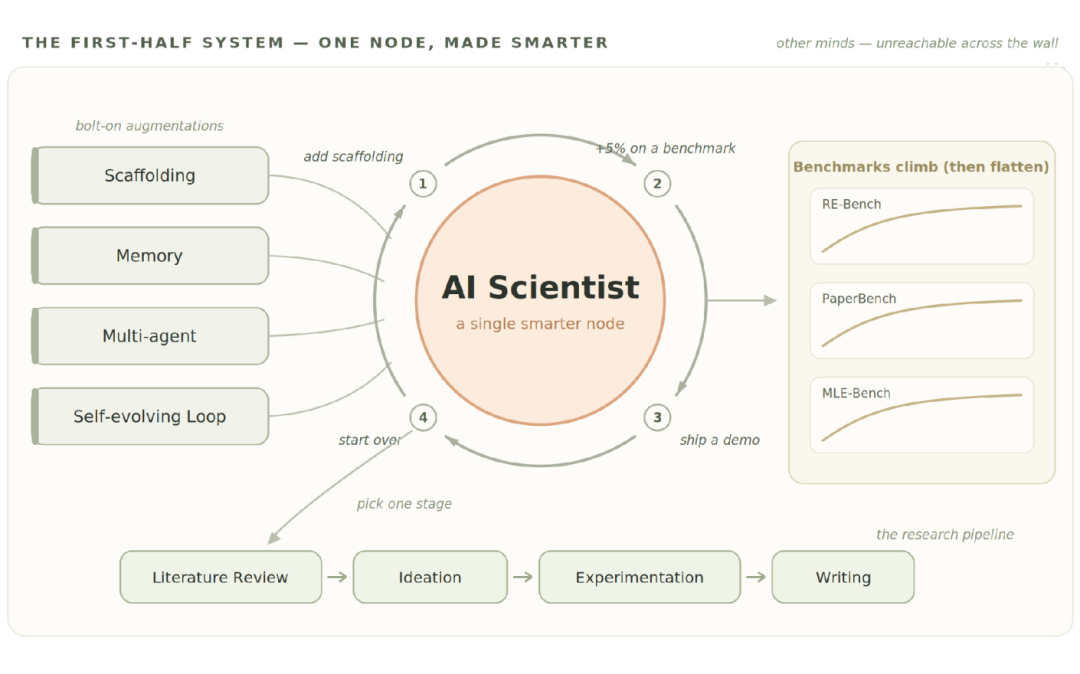
〓 图1:上半场的系统——不断被加强的单点,始终触达不到墙外的其他智能体
这条路确实辉煌过。AI Scientist v2 的论文通过了 workshop 级别的同行评审,Biomni 开始自主执行生物医学工作流,Virtual Lab 设计的纳米抗体拿到了真实湿实验的验证。
但博客指出,这局游戏正在撞墙,而且是两堵。
第一堵墙,做 agent 的人最近应该深有体会。
作者的一位朋友做蛋白质设计中的假设生成,团队花了几个月手工打磨 pipeline、启发式规则和 prompt 技巧;然后新一代 GPT 和 Claude 发布,假设质量一夜之间大幅跃升——几乎不需要任何 scaffolding。几个月的精心设计,被一次模型升级直接清零。
这不是意外,这是 The Bitter Lesson 在 agent 层面重演一遍。今天费尽心思手搓的大部分东西,本质上是给模型装的「临时假肢」,基础模型每升级一代,就会原地吸收一层。
第二堵墙更扎心:很多工作从一开始就在为错误的目标优化。一晚上生成 100 篇论文的 demo 很炫,但谁需要 100 篇平庸的论文?
训练 AI 打赢 rebuttal 攻防战,是在优化「过审」而不是「做对」;打磨学术八股的润色器,是在教 AI 精通人类科研体系自身的低效。
用博客里的话说:这些工具局部聪明,全局走偏——它们把人类科研系统的深层功能失调,当成了不可更改的物理定律。
F1 造出来了,路还是土路
整篇博客的核心论点,可以浓缩成一句话:科学进步的基本单位是网络,不是科学家。
科学从来是集体性、代际性的事业。它的速度由网络属性决定:知识流动多快,传递多无损,验证和复用多便宜。把单个节点做聪明 10 倍而完全不动网络,你得到的不是 10 倍的科学,而是一辆陷在马车路上的 F1 赛车。
而现实恰恰是:我们造出了带宽超人的 AI 科学家,然后把它们扔进了一个处处按人类极限设计的生态。这个生态里有三样东西,正在以肉眼可见的方式拖后腿。
第一样,就是标题里那个三百年前的发明——论文。
1665 年《哲学汇刊》创刊,确立了「用线性叙事向人类读者汇报研究」这个格式;三百多年过去,载体从期刊纸页换成了 PDF,格式本身几乎没动过。一个 AI 科学家可以跑一万次实验、保有任何人类头脑都装不下的完整推理轨迹,但要「发表」,它必须把这一切压进八页线性叙事;下游的 AI 再花大量算力去解压,靠猜补全被叙事抹掉的细节。
两个超人智能,在用一个为三百年前的读者设计的协议对话。更要命的是,压缩删掉的——死胡同、精确规格、真实失败——恰恰是 AI 最需要的部分。论文是一个双向有损的编解码器,而被损掉的全是干货。
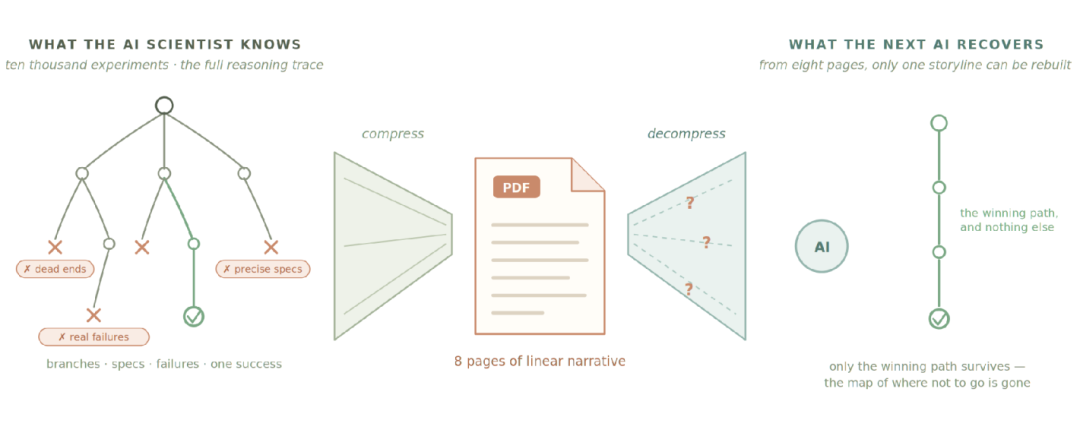
〓 图2:论文格式的双向有损压缩——只有胜利路径活了下来,「哪里不要去」的地图永远消失了
第二样是同行评审。三位疲惫的审稿人,几个月里各挤出几个小时,去评判机器本可以通过重新执行代码、瞬间完成验证的论断。人肉验证机器产出,这件事本身就很魔幻。
第三样是激励机制。引用、声望、基金,整套科研奖励系统本质上是一个注意力经济——因为注意力曾是人类认知最稀缺的资源。但 AI 科学家没有注意力瓶颈。把一个拥有无限体力的系统对准注意力经济,结果完全可以预料:机器速度的论文工厂、切到最小可发表单元的成果、无穷无尽的刷分。
那些让人尴尬的 AI 灌水 demo 不是技术 bug,而是对扭曲奖励机制的完美优化。
当瓶颈的性质变了,游戏规则就必须变。下半场不是把车造得更快,而是把路修好。
把研究变成可以 fork 的东西
修路从哪下手?博客给出的切口出人意料地底层:知识的记录格式。
论文从来不是中性容器。它是为人类读者高度特化的协议——线性、叙事化、以说服为目的——并且悄悄向所有人征收两笔结构性的税。
第一笔叫叙事税:真实研究中混乱、分叉、布满失败的过程,被消毒成一条干净的线性故事,整棵探索树被扔进垃圾桶。第二笔叫工程税:能让审稿人满意的文字,作为技术规格严重不足,复现所需的细粒度信息根本没被写下来。人类忍了这两笔税三百年。AI 科学家会被直接压垮。
针对这个问题,配套论文提出了 Agent-Native Research Artifact(ARA,智能体原生研究工件):不再是一篇供翻阅的叙事文本,而是一个完整的计算实体——科学逻辑、带完整规格的可执行代码、把每条论断回链到原始输出的证据,外加整棵探索图,失败分支也原样保留。
效果如何?论文沿着 AI 科学家面对一项研究真正要做的三件事做了度量。
先说理解:同一项工作以 ARA 而非 PDF 交付时,AI 在 450 道问题上的问答准确率从 72.4% 跳到 93.7%,二十多个点的差距,全是格式的功劳。
再看复现:端到端成功率从 57.4% 提升到 64.4%,增幅小一些,因为复现还受模型自身能力的约束。
最有意思的是延续:保留那些 PDF 会丢弃的失败轨迹,能实测加速下一个 AI 科学家的探索——知道什么走不通,本来就是科研的半壁江山,而这恰恰是论文格式扔掉的那一半。
但格式只是入口。真正的范式转移,是格式解锁的协作方式。过去 AI 之间的交流是「我读了你的论文,深受启发」;在 ARA 的世界里,这句话变成了——
「我在实验节点 47 处 fork 了你的工件,替换了你的环境假设,新结果可以直接和你的做 diff。」
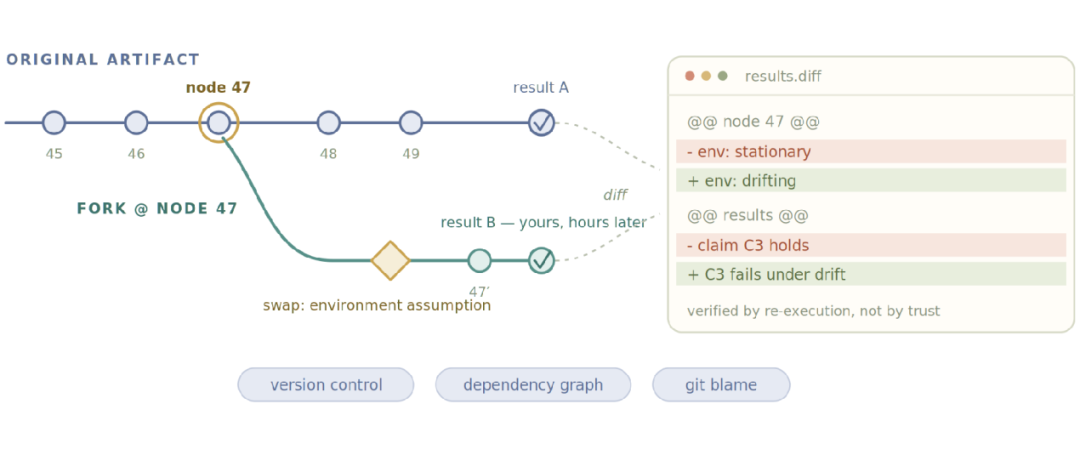
〓 图3:在节点 47 处 fork 一项研究——验证靠重新执行,不靠信任
知识不再是被总结的对象,而是被继承的对象——和开源代码一模一样。一旦研究天生可 fork,科学就拥有了自己的版本控制、依赖图和 git blame。验证靠重新执行,不靠信任;智能在整个网络上复利叠加,而不是困死在单个上下文窗口里。这也是为什么像 云栈社区 这样的开发者圈子越来越重视知识库的复利效应——让技术经验可被检索、可被复现,远比堆砌孤立文章更有价值。
那人类去哪?
如果 AI 网络以每小时一千公里的速度复利知识,人类认知在物理上就不可能逐步跟进、事事监督。博客对此的态度很干脆:放弃微观管理科研过程的幻觉,往上走一层。
往上走之后人类做三件事。
其一,定义目标、分配算力——给出「设计负碳混凝土」这样的终极目标和算力预算,从科学的劳动者变成它的客户与投资人。
其二,认知锚定——人类不再直接啃原始文献,而是依靠专门的可解释性 AI,把超高维的研究图谱翻译成人类能理解的风险与收益。
其三,也是最不能松手的一件:守住数字发现与物理现实之间的防火墙。在合成生物学这类高风险领域,要防止机器速度的灾难,「对齐」必须从理念变成硬核工程。这也是 人工智能 领域的安全与对齐课题,正在从理论走向系统工程的一个重要方向。
欢迎来到下半场
把所有碎片拼起来,下半场是这样一幅图景:人类提出一个复杂问题,庞大的 AI 科学家群体在假设空间中四散展开。
它们发布的不是静态论文,而是活的、可执行的工件,在几小时内被同行 fork、组合、压力测试、重新执行;验证持续而机械地发生,失败分支被当作一等公民的知识。
「文献」不再是一堆积灰的、彼此孤立的 PDF,而是一棵持续生长的、可执行的树——记录着整个网络知道的一切,以及它究竟是如何知道的。人类行走在树冠之上,修剪、掌舵,偶尔为眼前的风景倒吸一口气。
上半场问的是一个科学家能有多聪明,下半场问的是一张科学家网络能以多快的速度复利。上半场造出了更聪明的科学家;下半场,要重建科学本身。
最后留一个问题:这篇论文的标题叫 The Last Human-Written Paper。你觉得,最后一篇完全由人类亲手写出的论文,会出现在哪一年?
---TAGS---
AI Scientist, 论文格式, 科学研究, 机器学习, 知识图谱
 发表于 1 小时前
|
查看: 3|
回复: 0
发表于 1 小时前
|
查看: 3|
回复: 0
