OPD相关论文近几个月几乎每周都有新作冒出,其态势与当年的 xPO (DPO之后)、xGRPO (GRPO之后)如出一辙,大家围绕这一范式展开了大量的排列组合。本文旨在对近期这波工作进行初步梳理,厘清哪些工作是同一个问题的不同表述,哪些又触及了不同的核心模块。

AOPD:按优势符号切分正负信号
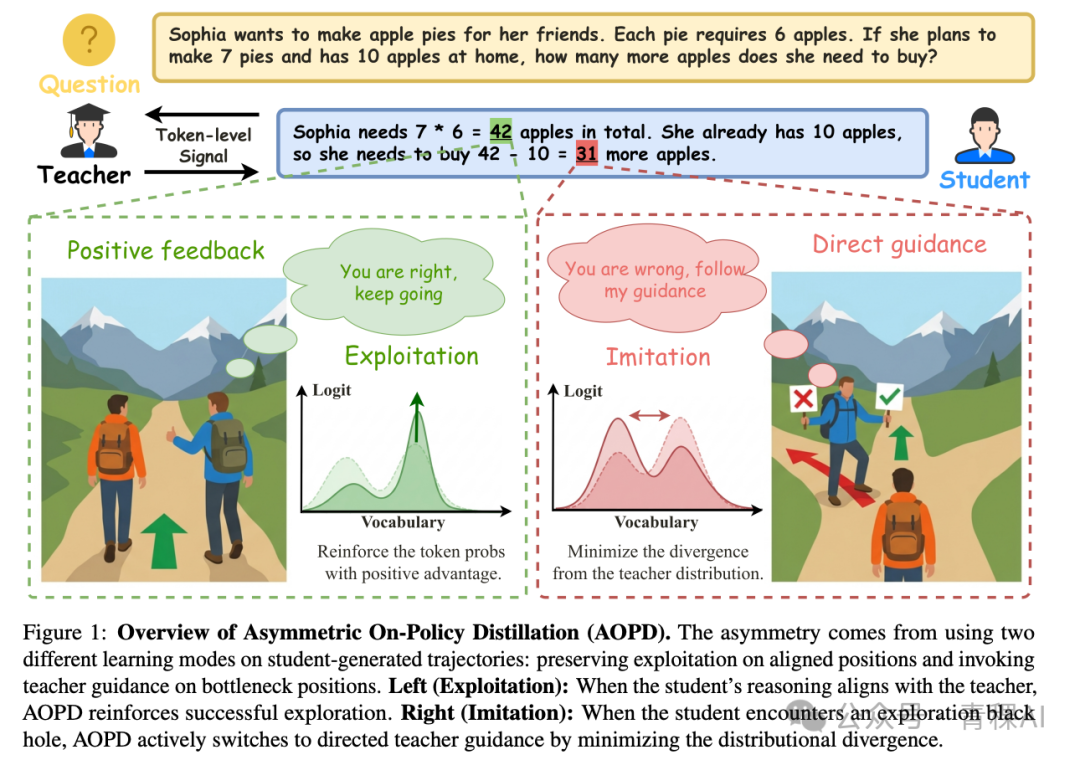
AOPD[1] 的切入点非常直接。GRPO 的策略梯度在不同优势(advantage)区域的信噪比(SNR)差异巨大:在零优势区,梯度消失;负优势区成为高方差噪声源;唯有正优势区才是真正可信的学习信号。
因此,作者提出按优势符号将学习过程一分为二——正优势保留策略梯度(exploitation),非正优势则直接切换为KL散度最小化(imitation)。实验表明,该方法在强初始化模型上带来 4.09% 的提升,在弱初始化模型上则高达 8.34%。
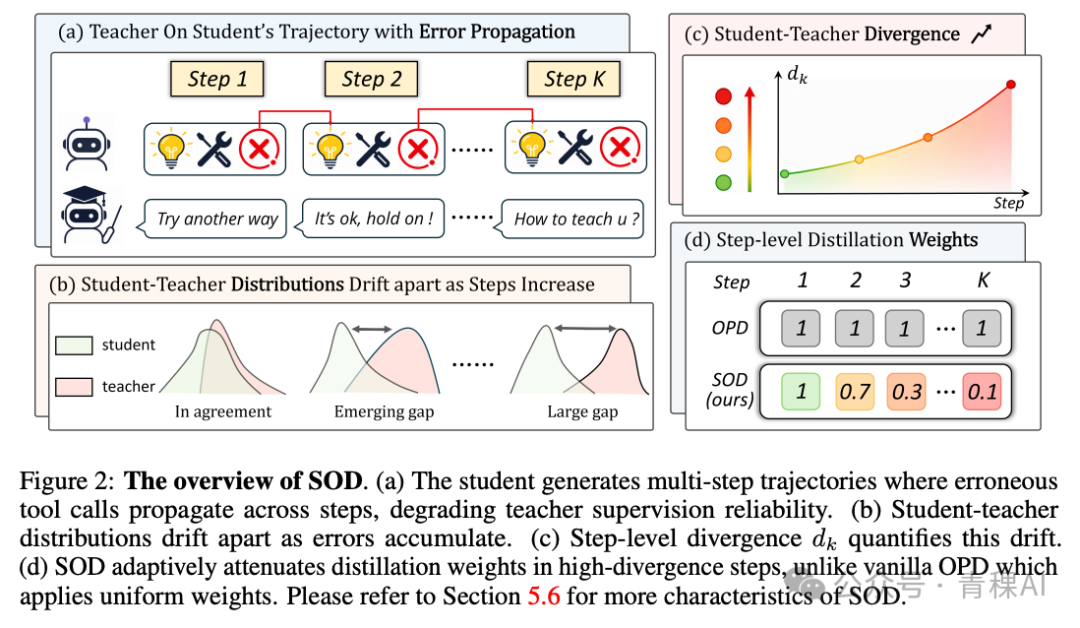
Hy 等人的 SOD[2] 关注一个非常具体的失效模式:在工具调用场景中,一旦出现一次幻觉调用,后续轨迹便会彻底被污染。此时,教师在受污染状态下提供的监督几乎全是噪声,而原生 OPD 的 token 级均匀加权会放大这种影响。
其解法是将轨迹按工具观察(tool observation)切分为 K+1 个步骤,为每一步计算一个散度分数,并据此生成自适应权重:当学生越走越偏(散度上升),教师信号的权重就被衰减;当重新对齐时,权重才得以恢复。本质上是为教师监督引入了一个“信任度门控”。
效果方面,0.6B 的学生模型在 AIME2025 上取得 26% 的成绩,成为首个达到此水平的 sub-1B 模型,相对 OPD 提升了 20.86%。
ROPD:质疑 “logit 匹配” 的必要性
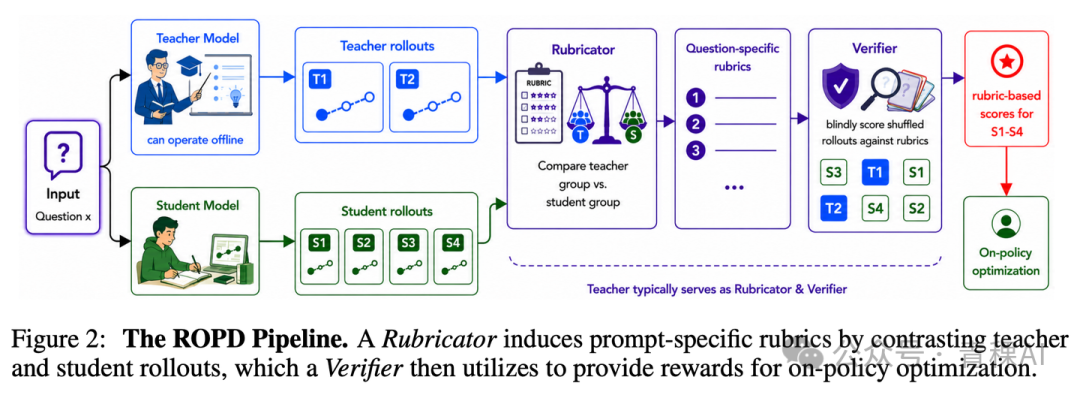
来自 NUS 和腾讯的 ROPD[3] 旨在打破 OPD 的一个隐含假设:教师信号必须是 logits。
其做法分为两步。首先,对每个 prompt,对比 4 条教师回答与 8 条学生回答,让 LLM 生成 4 至 12 条带权重的评分标准(rubric);然后,LLM 依据这些标准对学生 rollout 进行 0/1 评分,加权总分直接作为 GRPO 的奖励。
整个过程无需教师 logits,这意味着像 GPT-5.2 这类纯黑盒教师也能被蒸馏。一个关键数据是 AUC:rubric reward 在预测最终答案正确性上的 AUC 高达 0.90,而教师 logits 的 AUC 仅有 0.35(近乎随机)。换言之,当教师 logit 信号的预测 AUC 已接近随机水平时,再执着于优化反向 KL 散度无异于缘木求鱼。ROPD 实现了 10 倍样本效率与 6.3 倍的 wall-clock 加速,从根本上质疑了 OPD 中的“Distillation”一词必须等同于 logit 匹配的认知。
Apple Unmasking OPD:揭露多数 token 梯度实为噪声
Apple 的这篇诊断性工作[4] 试图回答一个根本问题:“OPD 到底何时有效,何时失灵?”
研究发现:
- 在学生失败的轨迹上,教师信号的余弦对齐度约为 0.05,呈显著正向。
- 在学生已成功的轨迹上,对齐度接近 0.001,几乎正交——等同于白白浪费梯度预算。
- Token 级方差极大(标准差约 0.83),同一条路径中对齐度会在正负之间反复横跳。
- 仅保留正对齐的 token,即可用 52% 的 token 获取 10-15 倍的有效信号。
论文由此提出“可理解性假设”:梯度信号仅在学生能够理解(parse)时才有效。实验显示,0.6B 小模型用自蒸馏效果比使用 32B 外部教师好 2-3 倍;1.7B 模型使用同家族 8B 教师又能反超;在复杂数学题上,概括后的教师轨迹反而有害,因为小模型根本无法理解压缩后的论证过程。
Uni-OPD:桥接 token 级与 trajectory 级信号
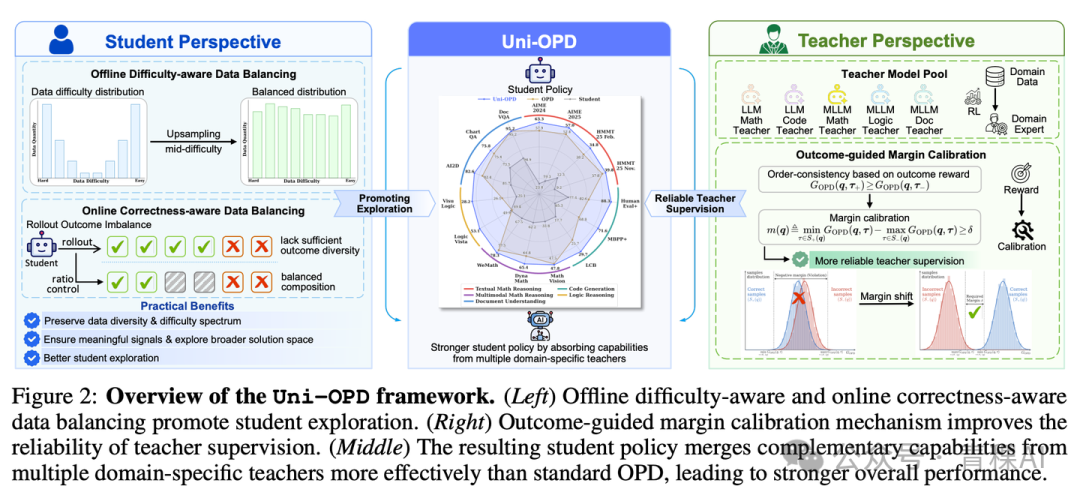
Hy 的 Uni-OPD[5] 指出原生 OPD 的一个隐藏缺陷:token 级的反向 KL 散度之和,可能与最终的 outcome 不一致。例如,学生虽写出错误答案,但其 token 模式酷似教师的高频区,导致其 trajectory 级蒸馏回报反而比正确轨迹更高。
其修复方案是“结果引导的边界校准”:定义一个轨迹级回报,要求它与 outcome reward 的排序保持一致。若不满足,则对正确轨迹的回报施加一个边界(margin)进行修正。此外,工作还从学生/教师双视角引入了数据均衡策略(离线难度均衡与在线正确性均衡),并支持多教师蒸馏。在 30B→4B 与 30B→1.7B 的蒸馏任务上,均有 1.5 至 3 个百分点的增益。其本质是将 OPD 与 RLVR(基于可验证奖励的强化学习)桥接起来,使 token 级 KL 散度不再“自说自话”,而是接受 trajectory 级 outcome 的监督。
Lightning OPD:将 on-policy 转变成 on-distribution
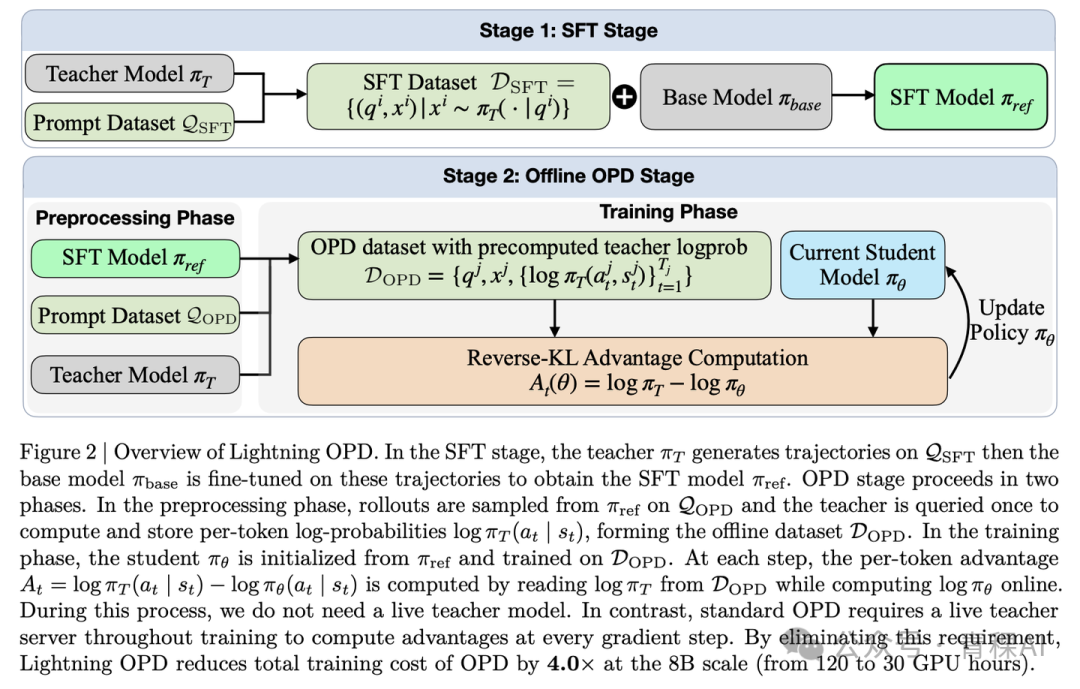
Lightning OPD[6] 的核心洞察在于:OPD 真正的算力开销并非 KL 散度计算,而是教师的实时推理。他们证明了一个定理:只要 SFT 阶段与 OPD 阶段使用同一个教师,那么将教师在 SFT rollout 上的 logits 预先计算并缓存下来,可与在线 OPD 共享一个最优解(梯度偏差可控)。
此举带来了 4 倍的算力节省,用 Qwen3-8B 在 30 GPU 小时内便可在 AIME24 上达到 69.9% 的准确率。严格来说,这不再是“on-policy”,而是“教师所见过的 on-distribution”,但在工程上极具价值。更重要的是,这个技巧几乎与所有其他 xOPD 方法正交,可直接叠加使用。
OPSDL:让模型“短版本的自己”教“长版本的自己”
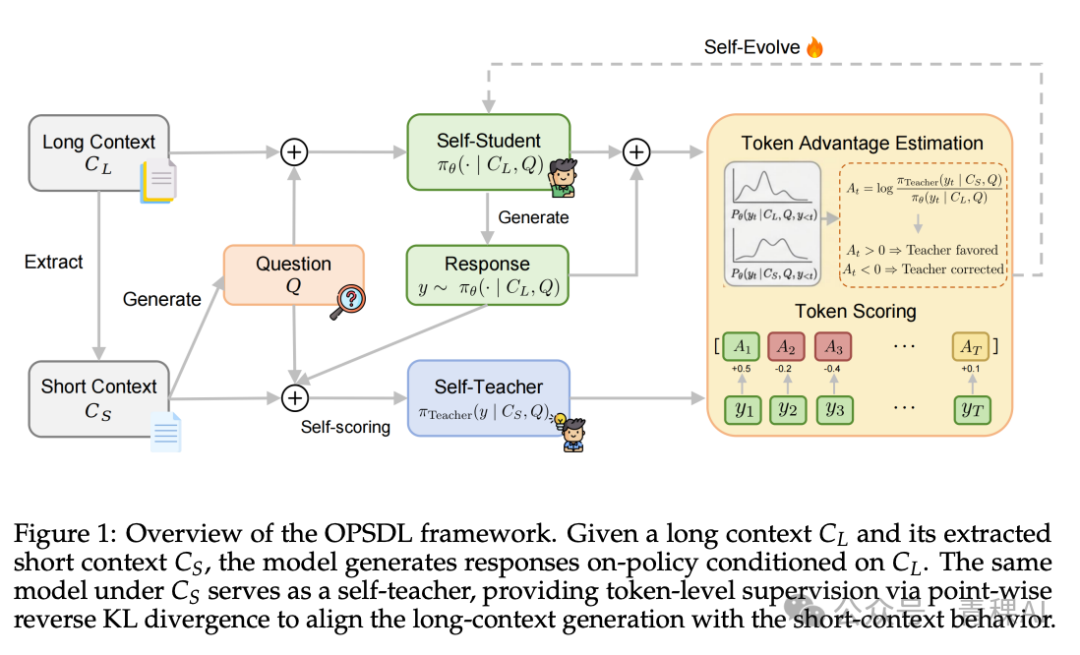
百度的 OPSDL[7] 解决的是一个特定场景问题:模型在长上下文中 rollout 时容易被无关信息干扰,但同一个模型在短上下文中的表现却更为可靠。与其寻找昂贵且未必更好的外部长上下文教师,不如让模型自己做老师。学生在完整长上下文中 rollout,但从中抽取真正相关的短上下文片段,让模型在该短上下文中为自己提供监督。
其本质是自蒸馏加上一层特权信息(privileged information)——这里的特权不是答案或更多上下文,而是“被精简过的、模型能更好处理”的上下文。这与 Apple 的可理解性假设相互印证:教师信号是否有效,关键在于学生能否理解;模型自身的短上下文版本,正是它最能理解的教师。
Self-Distilled Reasoner:以自蒸馏替代 RLVR
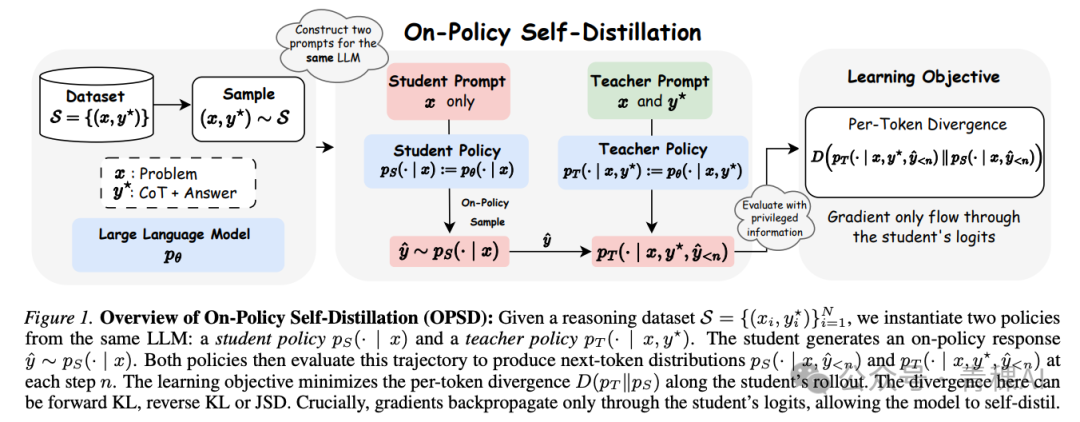
来自 UCLA 和 Meta 的 Self-Distilled Reasoner[8] 是正式确立 OPSD(On-Policy Self-Distillation)名称的工作。其设定非常清晰:同一模型实例化出两份策略——教师看到问题与特权信息(已验证的推理轨迹或标准答案),学生仅看到问题,两份策略共享同一组权重。
学生自行 rollout,随后两份策略在学生的轨迹上各自计算一次概率,并最小化每个位置的散度。梯度仅回传给学生侧。这篇工作有两个值得注意的发现。
第一,前向 KL 散度在此设定下反而胜出。 此前所有涉及外部教师的 OPD 均采用反向 KL,理由是它具有模式寻求(mode-seeking)特性,避免小模型被迫覆盖自身无法表达的模式。但在自蒸馏设定下,由于师生共享权重,能力鸿沟不复存在;教师的条件分布不过是学生条件分布在特权信息加持下锐化后的版本,它推高的每一个 token 都是学生本身就能表达、只是未注意到的。此时,模式覆盖(mode-covering)恰恰才是期望的行为。
第二,逐 token 的 KL 裁剪(clipping)是必要的。 研究发现,风格化 token(如标点、连接词)的逐 token 散度远高于承载推理的 token,若不进行裁剪,噪声将主导训练。简单的逐 token 截断便能使训练稳定,并在百步内快速收敛。
效果上,OPSD 在多个数学推理基准上拿到了比 GRPO 高 4 到 8 倍的 token 效率,并超越了离线蒸馏方法。
SDPO:首次将自蒸馏接入 RLVR
RLVR 长期受困于奖励信号稀疏的问题——几千 token 的轨迹最后只获得一个 0/1 的奖励,我们无从得知究竟是哪几个 token 发挥了关键作用,这就是经典的信用分配难题。
SDPO[9] 的解法是:让同一个模型同时扮演学生和教师。教师通过多看一些特权上下文(即学生自己写出的某条正确 rollout),就能在每个 token 位置上提供更可靠的概率信号,为学生提供 token 级的密集反馈。其损失函数是 logit 级的 KL 散度,并加在 GRPO 的替代损失上,对所有 rollout(无论对错)生效。核心隐喻是“用完成态反哺过程态”。
SRPO:让教师只在学生犯错时出手
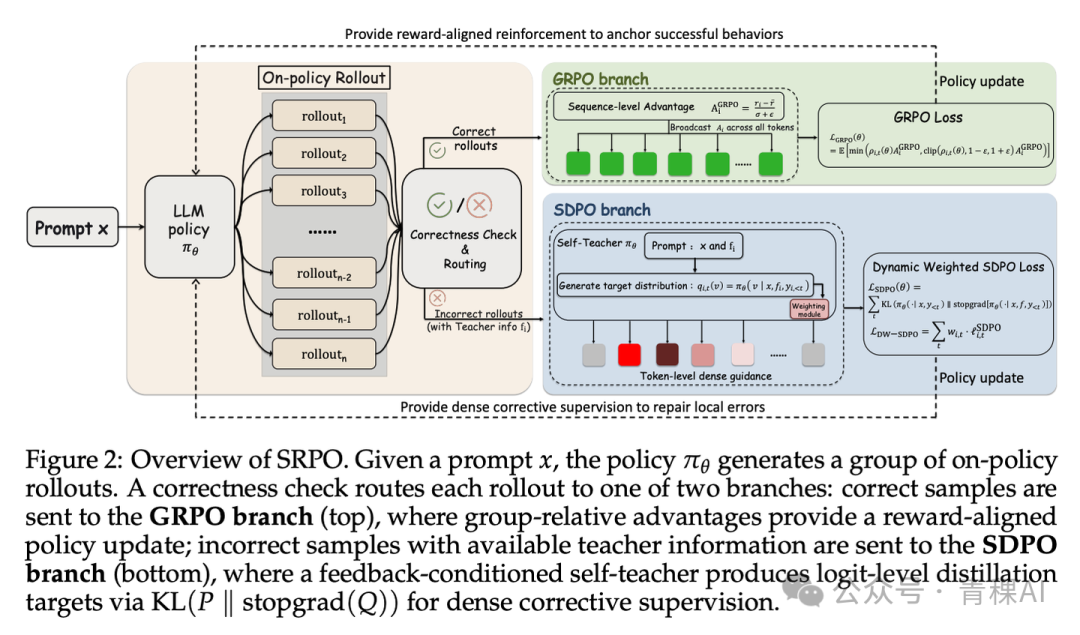
SRPO[9] 在 SDPO 的基础上加入了样本路由。教师查看的仍是正确 rollout,损失仍是 logit KL,唯一的改动是:仅在错误轨迹(reward = 0)上应用 SDPO loss,正确轨迹(reward = 1)退回原生的 GRPO,并配以熵感知的动态权重。
这个朴素的设计原则预示了一个重要趋势:在 RLVR 中,教师并非越多越好,至少在成功轨迹上,其边际价值是可疑的。
RLSD:让教师成为更新幅度的调节器
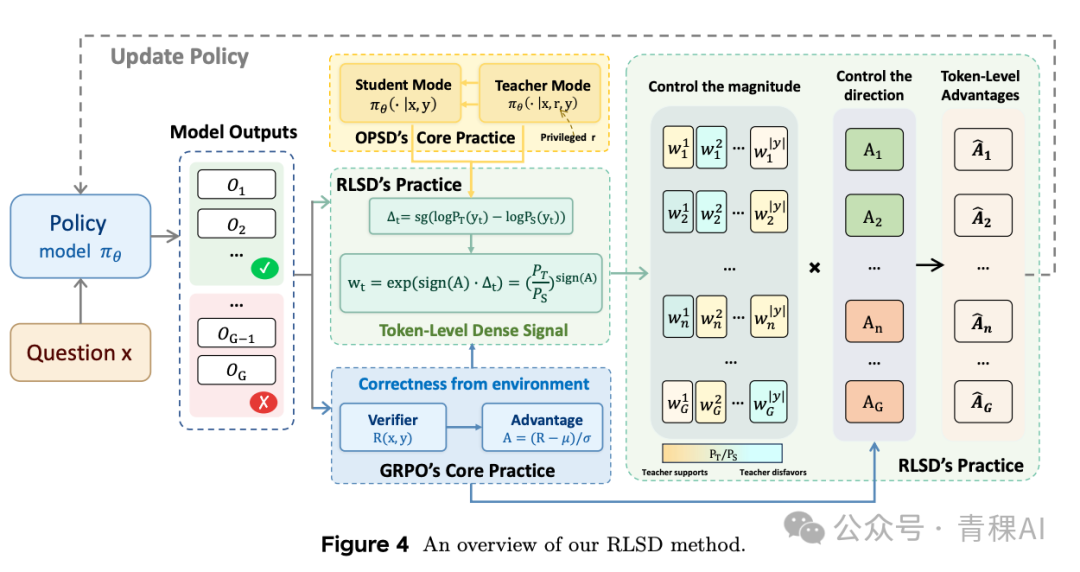
RLSD[10] 采用了截然不同的思路。教师的特权上下文不再是某条 rollout,而是标准答案——让教师在“知晓标准答案”的条件下,重新为每条轨迹的每个 token 计算概率。
更彻底的是,损失函数也不再使用 KL 散度,而是直接将师生 token 概率比作为优势(advantage)上的逐 token 权重。具体形式为 w_t = P_T / P_S,可验证奖励决定更新方向,教师只负责决定幅度——每个 token 该被加权多少。
RLRT:第一次将更新方向颠倒过来
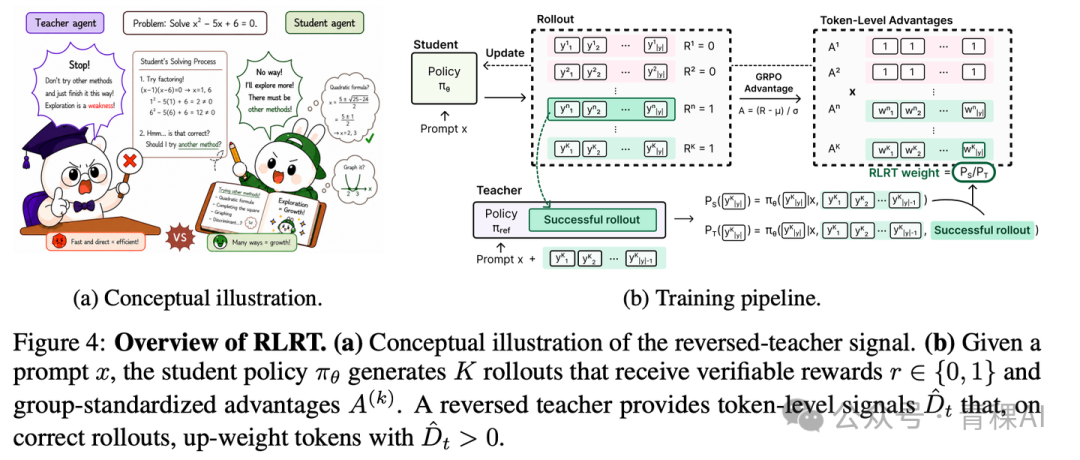
RLRT[11] 的反转尤为值得玩味。它将 RLSD 的 token 权重分子分母对调(变为 w_t = P_S / P_T),并且仅在正确轨迹上应用,错误轨迹完全退回原生 GRPO。
这一翻转将“在所有轨迹上奖励教师偏好的 token”转变为“在成功轨迹上奖励学生偏离教师选择的 token”。仅仅如此,Qwen3-4B-Base 在六个数学基准上比 GRPO 提升了 18%。
其论据在于信息不对称。教师因多看标准答案而偏爱标准解法;如果学生在某个关键位置选择了一个反常识但最终走通的 token,教师由于看到了参考解法,根本不会选择该 token。RLSD 的做法会惩罚这种“学生自行摸索出的反常识 token”,在每次成功后磨掉学生独有的多样性。RLRT 则反其道而行之,认为这些位置上的自主探索是金矿,必须重点强化。
RLCSD:用对错对比抵消风格漂移
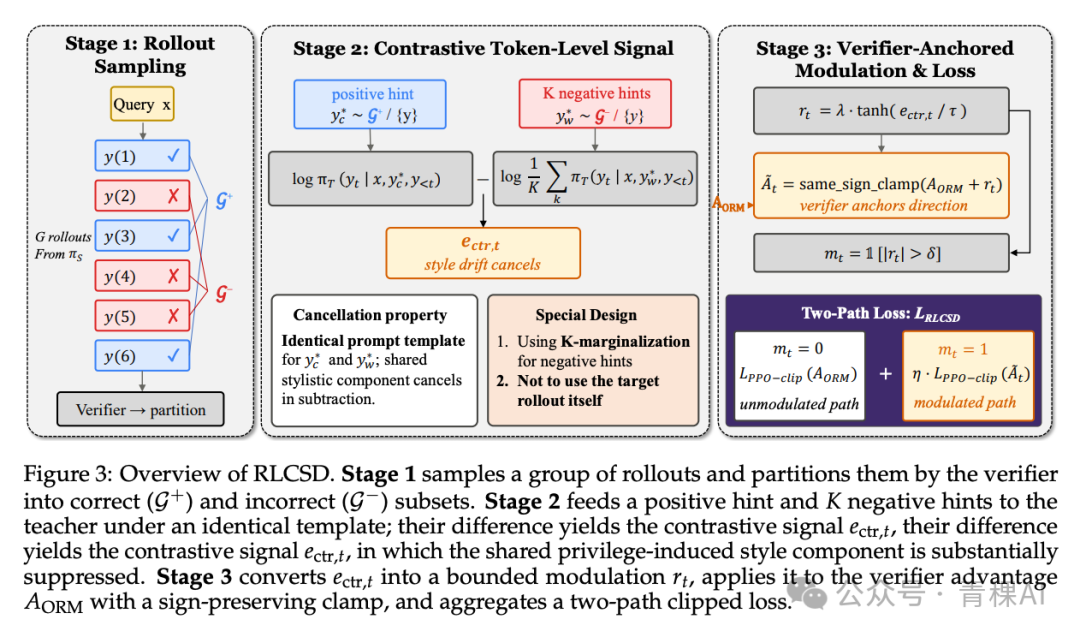
来自清华的 RLCSD[13] 与 RLSD/RLRT 同属一支,但它率先揪出了一个此前未被正面命名的问题:特权引发的风格漂移。当教师看过正确答案再回头给学生的 token 打分时,倾向于写得更直接、更短,导致师生之间的 gap 信号,其大头压在风格 token(如 “Wait”、“Therefore”、格式符号)上,而非真正承载推理的数字和算符。论文数据显示,风格 token 上的信号均值高达 0.263,而任务 token 仅有 0.083,相差三倍之多。
其解法相当巧妙:既然“看了提示就发生的风格偏移”与提示内容是否正确无关,那就拿一条错误提示来做对照。将一条错误 rollout 也套进完全相同的“参考解”模板喂给教师,算出一个 gap;再用正确提示算一次 gap;两者相减,模板逐字节相同,共享的风格漂移便直接抵消,留下的才是真正与任务对错相关的干净信号。
拿到干净信号后,它先通过 tanh 压缩到一个有界区间,再 mask 掉信号弱的 token,最后做一个保留符号的裁剪,确保调制不会颠覆验证器(verifier)决定的方向。
SDAR:将 OPSD 降级为多轮智能体的门控辅助
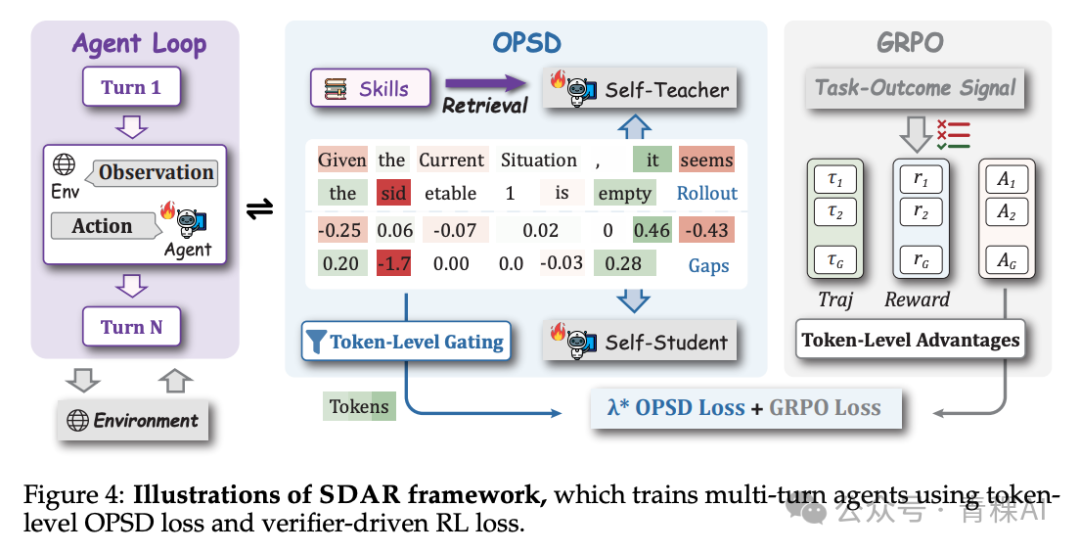
SDAR[14](浙大+美团+清华)切入的是多轮智能体这一具体场景。它将 OPSD 直接套用会崩溃的原因归结为两层:一是多轮不稳定性,错误会跨轮复利;二是不对称的信任,当特权上下文是检索回的技能片段时,若检索本身不完美,教师的“否定信号”便未必可信。
其解法是将 OPSD 从主优化目标降级为门控辅助项,RL 仍是主目标。对于师生差距,通过一个 sigmoid 门进行控制:教师认可的正向 gap token,门打开,蒸馏信号加强;教师拒绝的负向 gap token,门关小,进行软性衰减,而非一刀切的对称处理。这在 ALFWorld、WebShop 等智能体基准上比 GRPO 提升了 7 到 10 个百分点。
Many Faces of OPD:系统诊断 OPSD 的成败边界
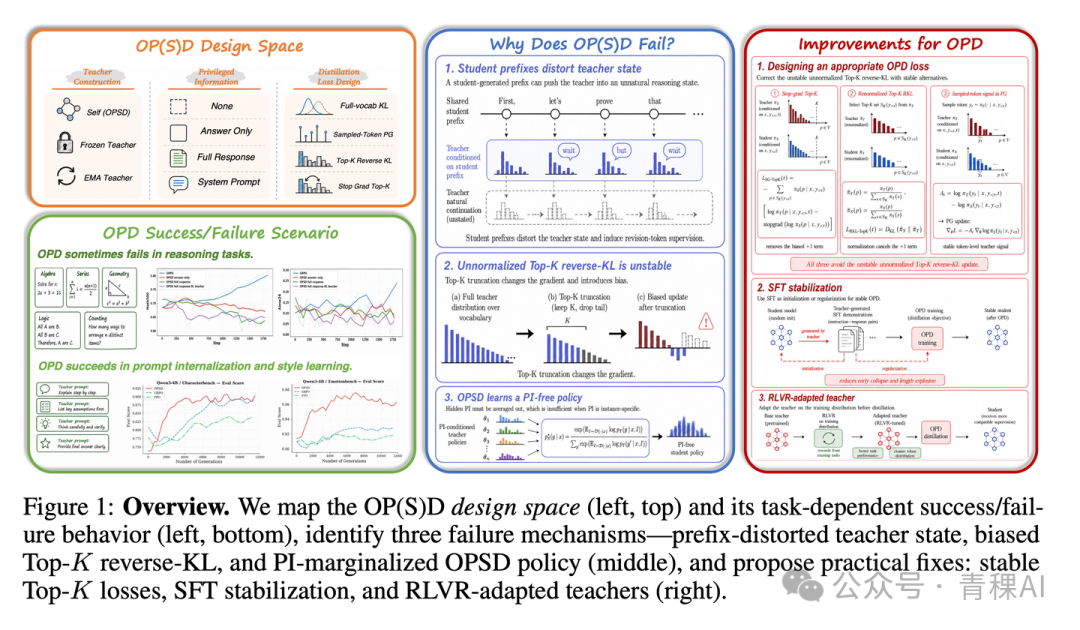
UIUC、人大与北大合作的这篇工作[15] 做了自蒸馏领域长期缺失的一件事:系统地拆解“OPSD 何时 work、何时不 work”。
其核心论断是:OPSD 的学生在数学上学到的不是一个具体的、由特权信息(PI)约束的教师,而是所有 PI 上的边际聚合策略。当 PI 是跨样本共享的规则时,聚合即内化,效果出色;但当 PI 是针对特定实例的标准答案时,聚合意味着将各异的解题路径硬拍成模糊一团,OPSD 在 Math500、AIME24/25 上全线溃败。一个有趣的失败模式是,学生在推理时会幻觉般地说出“如参考答案所言”——它学到的并非解题能力,而是“答案在条件里”这一统计痕迹。
这解释了为何 RLSD、RLRT 和 RLCSD 要在注入实例级 PI 时反复调整:RLSD 动幅度,RLRT 动方向,RLCSD 则用对照实验减掉风格污染。三者都是在与实例级 PI 的副作用搏斗,只是下手点不同。
TrOPD:为反向 KL 估计量划定信任区域
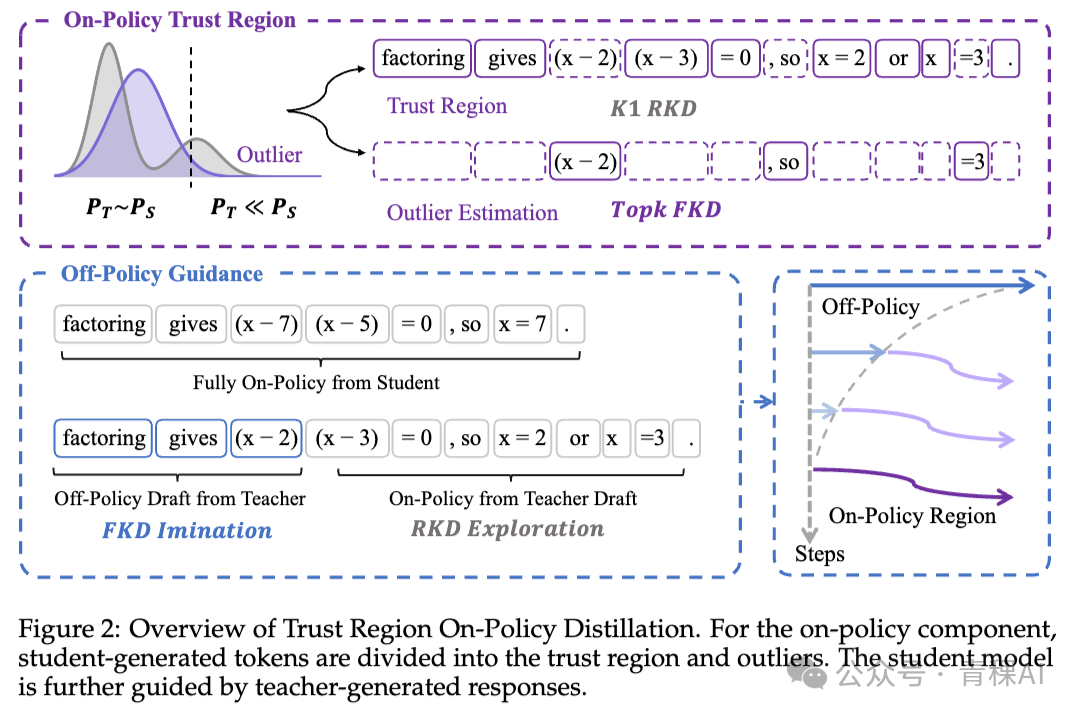
TrOPD[16] 针对的是原生 OPD 一个底层的数值问题。为节省显存,长推理任务中的反向 KL 通常使用一个无偏估计量,但当师生分布差异巨大时,学生采样出的 token 在教师那里的概率极低,策略梯度会冲向无穷大,引发梯度爆炸。
其解法借鉴了投机解码的思路,定义一个信任区域。教师认可的 token 被完全信任,正常走反向 KL;教师不认可的 outlier token,则被划入另一区。对于 outlier 区,它并未简单丢弃,而是切换到前向 KL——从教师的 top-k 视角给予安全的模仿监督。这一切换是消融实验中收益最大的部分,因为 outlier 区恰恰是师生分歧最剧烈、信息量最大的地方。
异同点:差异就几条主线
将这些工作横向展开,差异点可提炼为几个核心问题:
损失函数如何设计? 是反向 KL、token 概率比权重、按优势符号切分 RL/KL、按信任区域切换正反向 KL,还是产出 rubric reward 喂给 GRPO,甚至将 OPSD 整体降级为辅助门控项。
教师信号从何而来? 是白盒 logits、黑盒 rubric、自蒸馏的特权上下文、同组正确与错误 rollout 的对比,还是模型自身不同模态的表现。
哪些 token 或样本该被加权? 是均匀加权、按优势符号区分、按 step 散度衰减、按信任区域处理 outliner、按教师认可/拒绝的极性分配权重、用对错对比抵消风格噪声,还是仅在失败或仅在成功轨迹上应用。
教师拉动的方向如何? 绝大多数工作都将学生拉向教师,RLRT 率先逆向而行;Apple 的诊断则表明,某些 token 上根本不该拉;TrOPD 更提醒我们,有时不是不该拉,而是反向 KL 这个估计量在数值上会崩,得换个方向才能拉得动。
关于算力效率: 是在线采样还是离线缓存(如 Lightning),还是自蒸馏完全无需外部教师(如 OPSDL 及整套自蒸馏支线)。
关于 PI 的结构: 自蒸馏支线还多一根隐藏轴,即你喂给教师的特权信息究竟是跨样本的通用规则,还是针对特定实例的标准答案。
一些思考
从这波工作中,我们能看出一条隐藏的演化主线。
原生 OPD 默认教师全程手把手教学。Apple 的诊断却说,它在成功轨迹上给的几乎是噪声,是在帮倒忙。SOD 说它该有信任度门控,学生走偏时就该少听。TrOPD 说它的话有时在数值上根本没法听,得换个方向才接得住。ROPD 说它的 logit 信号 AUC 都不到 0.5,干脆换个别的方式吧。
Lightning 说它不用全程在场,离线缓存就够了。SRPO 说它在学生做对时该闭嘴。RLCSD 说它给的信号里混了层无关的风格腔调,得用对照实验把它剥离出来。SDAR 说它的拒绝信号本身就未必可靠,得软性处理。RLRT 更彻底——成功时它该退场到只保留“标记哪些是学生自己的选择”这一鉴别功能,更新方向甚至要跟它的偏好相反。走到 RLRT 这里,“教师”这个词已近乎反讽了。
这波 xOPD 表面上是各种损失函数的变种竞赛,底下的主线其实是:我们正在重新学习“教师”这个概念,在学生学习的动态过程中,它究竟该出现在哪些位置、以何种强度、扮演怎样的角色。
将自蒸馏支线也接入这条主线,会发现一个更深的洞见。所谓“教师”,不过是“学生在更好信息条件下的一个版本”,其价值取决于那份特权信息是否是一条跨样本的共同规律。当 PI 是共享规则时,“在更好信息下的自己”就是那条规律的化身,蒸馏即内化;当 PI 是实例特化的答案时,“在更好信息下的自己”是一个永远无法部署的状态,蒸馏即幻觉。
这不禁让人联想到人类教育学中长达一个世纪的争论:建构主义认为,教师该搭脚手架让学生自己构建认知;更激进的“非学校化”主张认为,连脚手架都不该有;传统课堂则默认教师应提供标准答案。OPD 这波的演化,几乎是把这场争论在算法层面重演了一遍——从“教师即标准答案”,到“教师只在卡壳时出手”,再到“教师只负责识别学生自己的选择,越是被它忽视却走通的,越要被珍视”。如果教育学的百年争论没有给出唯一解,那么后训练领域大概率也不会有唯一正确的方法,更可能出现的格局是,教师角色的多种配置在不同任务、不同学生能力、不同信号可靠度的场景下各擅胜场。
[1] AOPD: https://arxiv.org/abs/2605.06387
[2] SOD: https://arxiv.org/abs/2605.07725
[3] ROPD: https://arxiv.org/abs/2605.07396
[4] unmasking 工作: https://arxiv.org/abs/2605.10889
[5] Uni-OPD: https://arxiv.org/abs/2605.03677
[6] Lightning OPD: https://arxiv.org/abs/2604.13010
[7] OPSDL: https://arxiv.org/abs/2604.17535
[8] Self-Distilled Reasoner: https://arxiv.org/abs/2601.18734
[9] SDPO, SRPO: https://arxiv.org/abs/2601.20802 & https://arxiv.org/abs/2604.02288
[10] RLSD: https://arxiv.org/abs/2604.03128
[11] RLRT: https://arxiv.org/abs/2605.10781
[12] nrehiew blog: https://nrehiew.github.io/blog/sft_rl_opd/
[13] RLCSD: https://arxiv.org/abs/2606.11709
[14] SDAR: https://arxiv.org/abs/2605.15155
[15] Many Faces of On-Policy Distillation: https://arxiv.org/abs/2605.11182
[16] TrOPD: https://arxiv.org/abs/2606.01249
OPD 会是终局吗?大概率不会,但它揭示的视角会是终局的一部分。OPD 真正的贡献不在于“反向 KL + 学生采样”这一特定 loss 形式,而在于它揭示了一个更底层的认知:后训练的教师信号不应该是静态的,它应随学生当前的状态、能力、置信度及对错情况而动态调整。正如 DPO 之后的所有 xPO,最终并未有谁能笑到最后,但它们共同推动了“偏好学习无需显式奖励模型”这一深层认知的建立。OPD 这波浪潮,最终也很可能通向同一个结局——“教师信号必须是动态的、自适应的,且必须接受学生状态信息”,这将成为下一代后训练方法的常识基础。
必读论文清单
| Paper |
链接/标识 |
推荐理由 |
| Thinking Machines OPD blog |
thinkingmachines.ai/blog/on-policy-distillation |
⭐⭐⭐ 入门必读 |
| A Survey of OPD for LLMs |
arXiv 2604.00626 |
⭐⭐⭐ 全景综述 |
| Apple Unmasking OPD |
arXiv 2605.10889 |
⭐⭐⭐⭐ 诊断性研究 |
| Many Faces of OPD |
arXiv 2605.11182 |
⭐⭐⭐⭐ OPSD成败诊断 |
| RLRT (Rebellious Student) |
arXiv 2605.10781 |
⭐⭐⭐ 教师角色翻转 |
| RLCSD |
arXiv 2606.11709 |
⭐⭐⭐ 对比抵消风格漂移 |
| Self-Distilled Reasoner |
arXiv 2601.18734 |
⭐⭐⭐ OPSD 源头工作 |
| SDAR |
arXiv 2605.15155 |
⭐⭐⭐ 多轮Agent蒸馏 |
| TrOPD |
arXiv 2606.01249 |
⭐⭐⭐ 信任区域与outlier处理 |
| SOD |
arXiv 2605.07725 |
⭐⭐⭐ tool-use Agent |
| ROPD |
arXiv 2605.07396 |
⭐⭐⭐ 信号源形式解放 |
| Lightning OPD |
arXiv 2604.13010 |
⭐⭐⭐ 离线缓存 |
| Uni-OPD |
arXiv 2605.03677 |
⭐⭐ 双视角均衡 |
| AOPD |
arXiv 2605.06387 |
⭐⭐ 非对称处理 |
| OPSDL |
arXiv 2604.17535 |
⭐⭐ 长上下文自蒸馏 |
| SDPO / SRPO / RLSD |
arXiv 2601.20802 / 2604.02288 / 2604.03128 |
⭐⭐ RLVR 自蒸馏支线 |
| SFT, RL, and OPD (nrehiew blog) |
nrehiew.github.io/blog/sft_rl_opd |
⭐⭐ 采样与教师能力之辩 |
这份阅读清单将持续更新。
 发表于 2 小时前
|
查看: 2|
回复: 0
发表于 2 小时前
|
查看: 2|
回复: 0
