依然是在探索AI时代的替代性和人何以自处的问题。这次先说一个你可能没想过的事。
替代这件事,从来不是技术驱动的。
技术只是工具,驱动替代发生的,是利润。
只要压缩成本能带来利润,替代就会发生——不管当时的工具叫外挂、叫工作流、叫自动化,还是今天叫AI。
这个动机自古就有。AI只是让它变得更快,覆盖面更广。
所以你现在感受到的那种焦虑,不是新问题。是一个旧问题,换了一张新脸。
想清楚这件事之后,问题就变了。不是“我怎么跑赢AI”,而是——这个牌局是怎么设计的,我现在站在哪个位置。
AI时代的利益结构,从上到下有五层
整体是这样的:
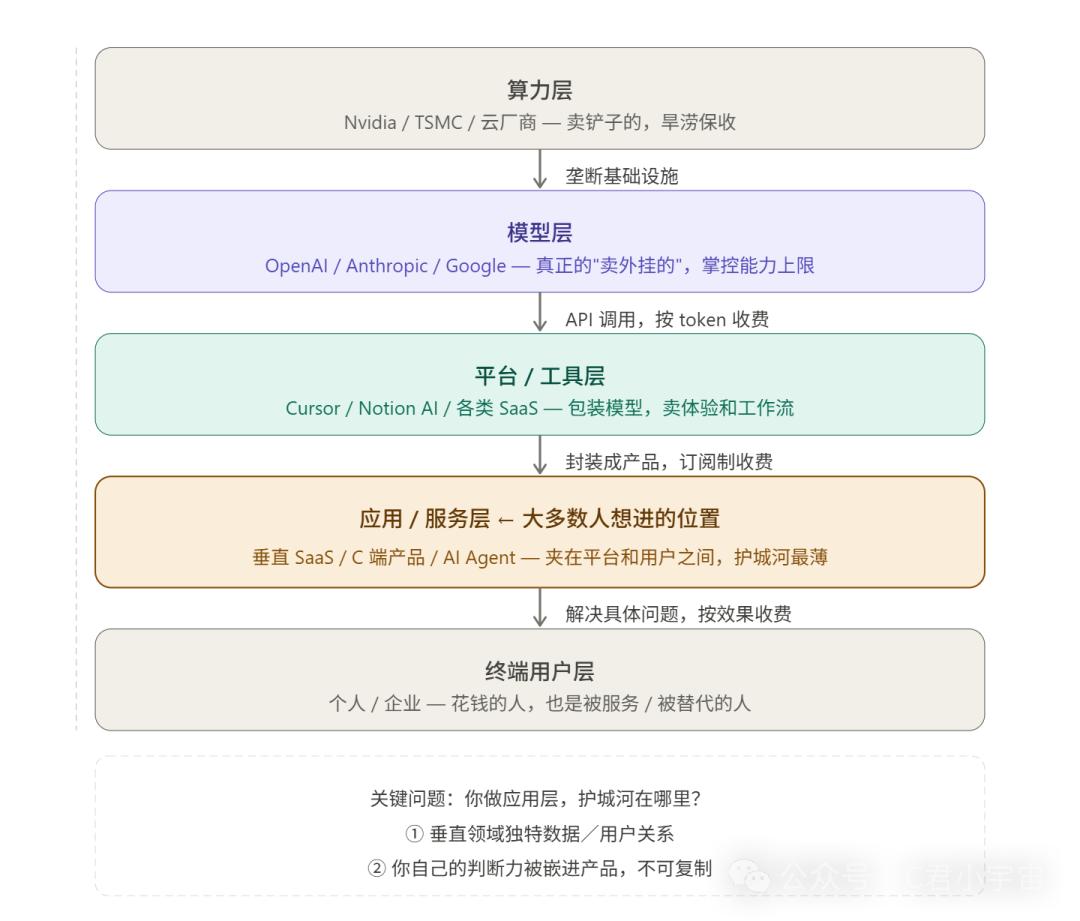
在这个层级里有个不同的规律:越靠近用户,你能触达的人越多,但你的护城河就越薄。
算力层和模型层是真正“卖铲子”的——他们不在乎上面跑什么应用,只要有人用AI,他们就收钱。
你现在在哪一层?你想去哪一层?这两个问题,值得先停在这里想一想。
每一层都在争,但争的点不一样
|>> 第一层:算力层
算力层是整个AI产业里最“硬”的一层,竞争格局也最清晰,因为它高度集中。现在算力层是一个近乎垄断的结构。
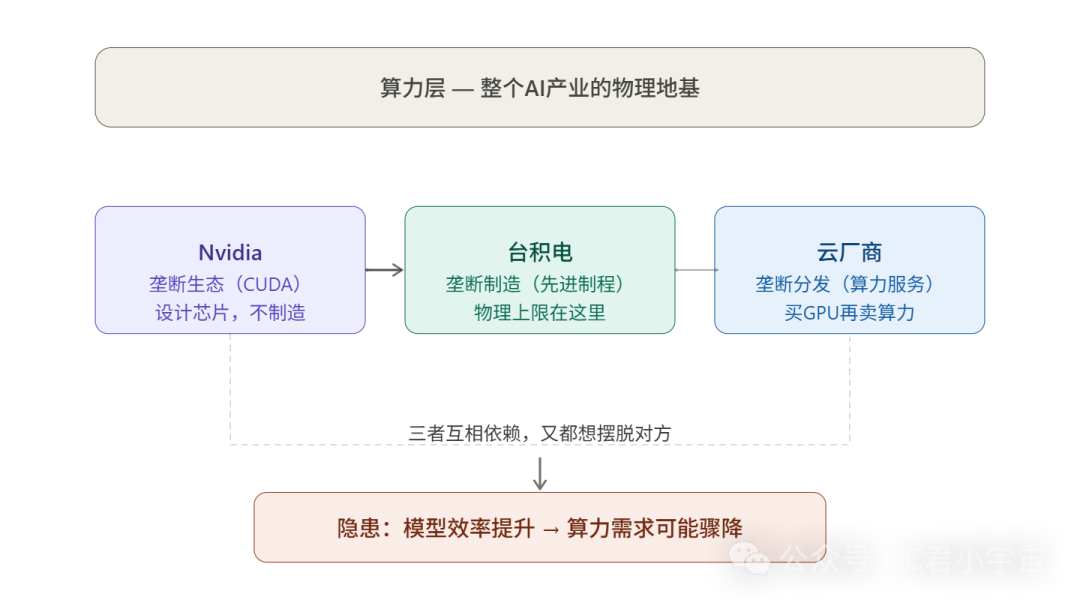
Nvidia是绝对核心。
不是因为他们的芯片最便宜,而是因为CUDA。
CUDA是Nvidia在2006年就开始推的编程生态,二十年了,全球的AI研究员、框架、工具链都建在上面。
你换一块AMD或者Intel的芯片,性能可能差不多,但你所有的代码、所有的优化经验、所有的工程师肌肉记忆,都要重来。
这就是为什么AMD的MI300X在纸面参数上很能打,但市场份额还是很小——护城河不是芯片,是生态。
台积电是隐形的卡脖子点。
Nvidia设计芯片,但芯片是台积电造的。全球最先进制程(3nm、4nm)几乎只有台积电能做,三星勉强跟上,Intel Foundry还在追。
这意味着整个AI算力的物理上限,其实掌握在台湾海峡边上的一家公司手里。这也是为什么地缘政治风险会直接影响AI股价。
云厂商是第三个维度。
AWS、Azure、Google Cloud,他们不造芯片,但他们大规模采购Nvidia的GPU,然后以“算力服务”的形式卖给所有人。
对大多数公司来说,不会自己买GPU,而是租云上的算力。这让云厂商成了算力的“经销商”,同时也在自研芯片想绕过Nvidia——Google的TPU、Amazon的Trainium、微软投资OpenAI背后也有自研芯片的动机。
这里有一个深层矛盾值得注意:
算力层是整个产业链里最重的资产,建一个数据中心动辄几十亿美元,但它服务的上层(模型、应用)变化极快。
意思是,如果模型效率突然大幅提升——比如需要的算力减少十倍——算力层的需求会瞬间收缩,那些重金押注的数据中心就成了烫手山芋。
所以算力层的竞争格局,用一句话概括就是:
Nvidia垄断生态,台积电垄断制造,云厂商垄断分发,三者互相依赖又互相想摆脱对方。
他们是整个AI产业的物理地基——不管上面盖什么,地基都要收钱。
|>> 第二层:模型层
这是这整条链路里真正“卖外挂的”,典型的模型公司,如OpenAI、Anthropic、Google。他们掌控能力上限,是整个链条里最接近“庄家”的位置。
模型公司的护城河,表面上看是技术,但技术本身其实很脆弱。你看这几年,GPT-4出来没多久,各家就追上来了,开源模型也在不断逼近闭源。所以单靠模型能力本身,护城河并不深。
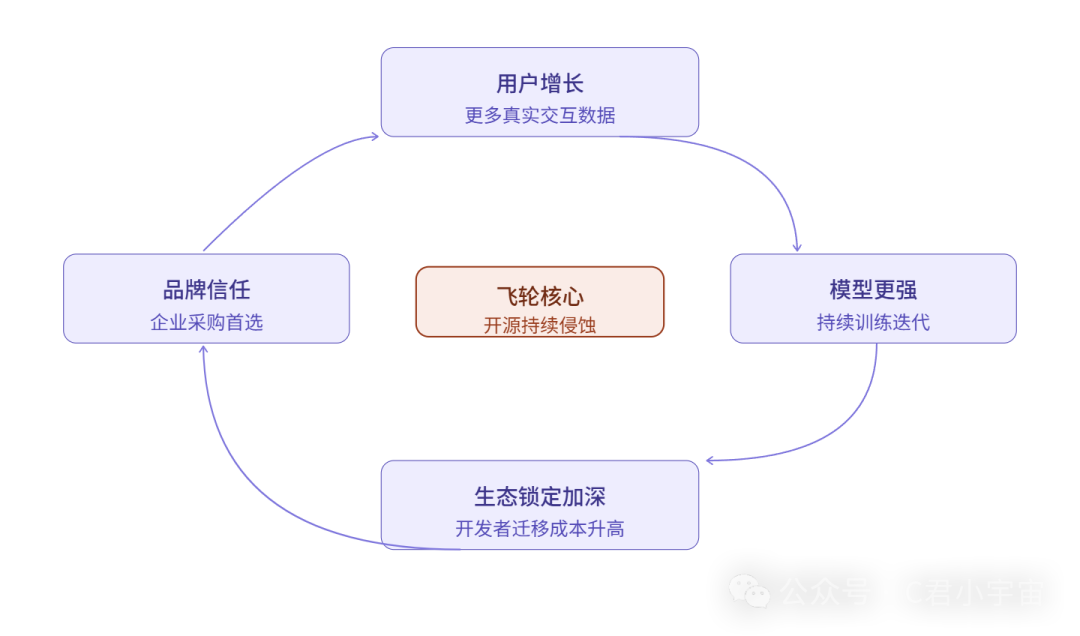
真正的护城河是三层叠在一起的:
第一层,数据飞轮。 用的人越多,产生的交互数据越多,拿这些数据继续训练,模型越来越好,好了又吸引更多人用。
这个循环一旦转起来,后来者很难复制,因为你没有那个量级的真实用户数据。OpenAI靠ChatGPT积累的对话数据,是别人用钱都买不到的。
第二层,生态锁定。 API接入的开发者越多,围绕这个API建起来的产品和工作流就越多,迁移成本就越高。
就像当年Windows,不是因为系统最好,而是因为软件生态最全,没人敢换。Anthropic的Claude API现在接入的企业客户,换模型的成本真实存在着。
第三层,品牌信任。 这个在To B端尤其重要。企业采购AI,不只是买能力,买的是“出了问题谁来负责”的安全感。
OpenAI和Anthropic已经在大企业决策者脑子里建立了一定的心智,这个很难被一个新出来的便宜模型直接替代。
这三层护城河,其实都在被一件事持续侵蚀:开源模型的崛起。
就像Meta的Llama系列一出,很多中小企业直接自己部署,不付任何API费用。模型能力差距在缩小,但价格差距是数量级的。
如果把这个跟刚才那张图放在一起看,会发现一件有趣的事:
模型层的护城河,本质上是在跟时间赛跑,赌自己在开源追上来之前,把数据飞轮和生态锁定做到足够厚。
|>> 第三层:工具平台层
算力层靠重资产垄断,模型层靠数据飞轮,但工具平台层靠的是一个更微妙的东西——习惯和工作流的嵌入深度。
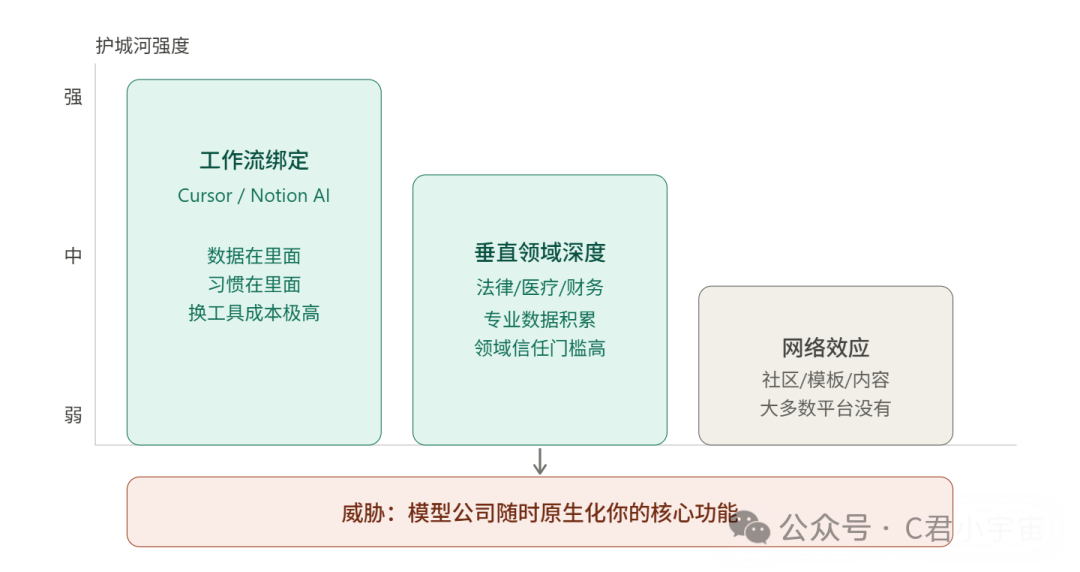
护城河01:工作流绑定
Cursor为什么能在一堆AI编程工具里跑出来?不是因为模型最好,模型是调的Claude和GPT。
是因为它把自己嵌进了工程师每天开发的动作里——你的项目在里面,你的快捷键肌肉记忆在里面,你的团队协作在里面。
换一个工具,不是换个软件,是改变整个工作方式,成本极高。
Notion AI也是同样逻辑。你的文档、知识库、项目管理全在Notion里,AI只是在上面加了一层,但这层把你锁得更死了。
这就叫上下文锁定——你的数据和习惯都在里面,离开成本太高。
护城河02:垂直领域的深度
通用工具平台很难打,但垂直做深是有机会的。
比如专门做法律合同审查的AI工具,专门做医学影像的,专门做财务分析的。
这些领域有两个特点:一是专业门槛高,模型本身不够,需要大量领域知识的调校;二是用户的信任成本高,换工具需要重新验证可靠性,不是随便换的。
这类公司的护城河不是技术,是领域信任加上专业数据积累。
护城河03:网络效应
少数工具平台能做到这一点。比如一个AI设计工具,用的人越多,产生的模板、素材、社区内容越丰富,对新用户越有吸引力,形成正循环。
但这个很难复制,大多数工具平台其实没有真正的网络效应,只有用户增长,这两个是不一样的。
听起来这一层的机会很多,但它有个致命威胁:
工具平台的护城河,随时可能被模型公司从下面抽掉。
OpenAI推出GPTs,Anthropic推Projects,Google把AI直接嵌进Workspace——他们随时可以把你的核心功能做进原生产品,而且他们的分发能力是工具平台完全无法匹敌的。
Cursor现在很强,但如果哪天VS Code原生的AI能力追上来,Cursor的处境就很微妙了。这不是假设,微软已经在持续加强GitHub Copilot。
所以工具平台层的生存逻辑,可以说是:
在模型公司的手伸过来之前,把用户的工作流绑得足够深,或者在某个垂直领域深到模型公司懒得进来。
|>> 第四层:应用层
做AI应用/SaaS,最大的结构性风险就是你夹在中间——上面是模型公司,下面是用户,你两边都得罪不起,两边都可能把你挤掉。
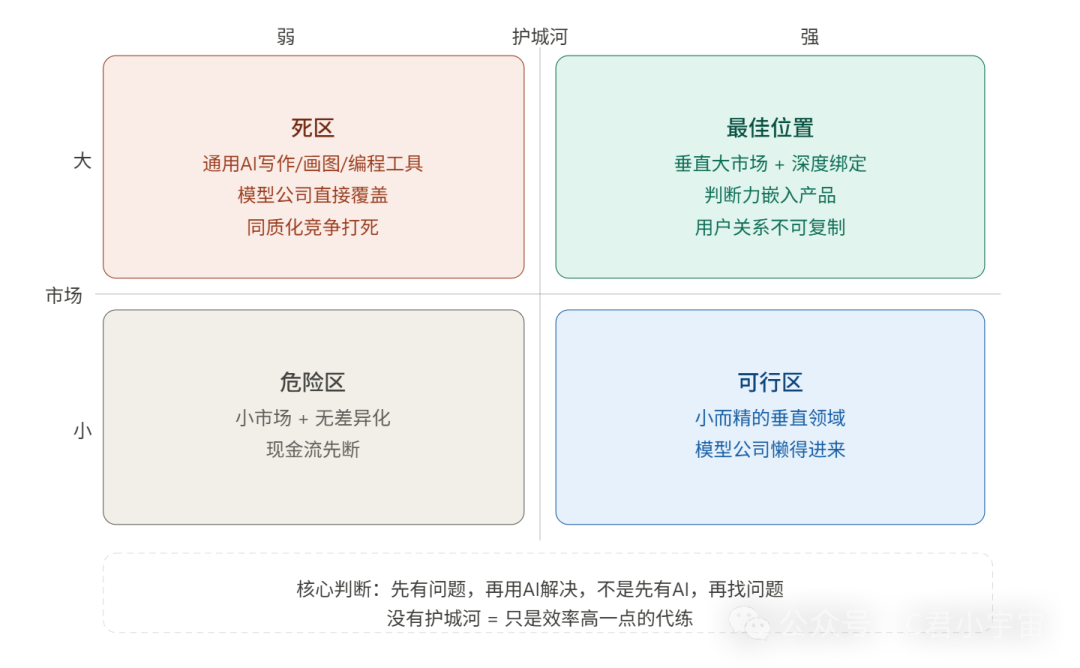
这一层也是目前大多数觉得有机会的地方。这个点在个人使用上没毛病,但如果想要商业化规模化是有问题的。
先说机会,机会是真实存在的,但有条件。
机会不在于“用AI做一个产品”,而在于你有没有一样东西是AI本身给不了的。
第一种,有独特的用户触达。 你在某个圈子里有信任,有关系,有渠道,你推的东西用户愿意用,别人推同样的东西用户不理。
这个不是技术壁垒,是人的壁垒,反而更难复制。
例如,我认识了很多年的一个商业老师,他自己做的软件应用给同学们用大家的心理门槛就很低,甚至会抱着对这个人的信任,去看一个从未有编程背景的人能做出什么样的东西。
第二种,有领域判断力。 你深耕某个垂直领域多年,你知道这个行业真正的痛点在哪里,哪些流程是最低效的,哪些决策是最需要辅助的。
你用AI解决的,不是一个泛化问题,而是一个只有内行才看得到的具体问题。
还是那位商业老师在做的,他从事各种教育已经有近10年,积累的个人数据是很多的。
模型公司不会来抢这个,因为他们不懂,也不屑于做这么细。
第三种,把自己的判断力嵌进产品。 不是单纯的AI工具,而是你的经验和决策逻辑被产品化了。
用户买的不是AI,买的是你这个人的判断,只是通过产品的形式交付。这个是最难被复制的,因为复制不了你这个人。
还是那位商业老师的例子,他的数字人据说融入了他七成功力,收获了很多学员好评,是独属于这个人的风格和知识体系。
再说说如果要大规模的商业化,具体的三个死法:
第一个,被模型公司原生化。你辛苦做了一个AI写作助手,OpenAI直接在ChatGPT里加了同样的功能,你的产品瞬间失去差异化。这不是假设,这已经发生过很多次了。
第二个,被同质化竞争打死。AI应用的复制成本极低,你做出来一个东西,三个月后有十个长得一模一样的,而且可能更便宜。没有护城河的情况下,只能打价格战,最后一起亏钱。
第三个,模型成本把你拖死。很多AI应用早期靠补贴用户,token成本算进去根本不赚钱,赌的是规模上来之后成本下降。但规模没到之前,现金流就断了。
把这两边放在一起看,会发现一个规律:
失败的AI应用,基本都是“先有技术,再找问题”——看到人工智能能做什么,就做一个产品出来,等着用户来。
活下来的AI应用,基本都是“先有问题,再用AI解决”。
在某个具体场景里,有真实的痛点,AI恰好是最好的解决方式,产品只是载体。这和AI没到来之前做产品的逻辑是一样的。
|>> 第五层:终端用户层
终端用户在AI时代的处境和机会是什么。
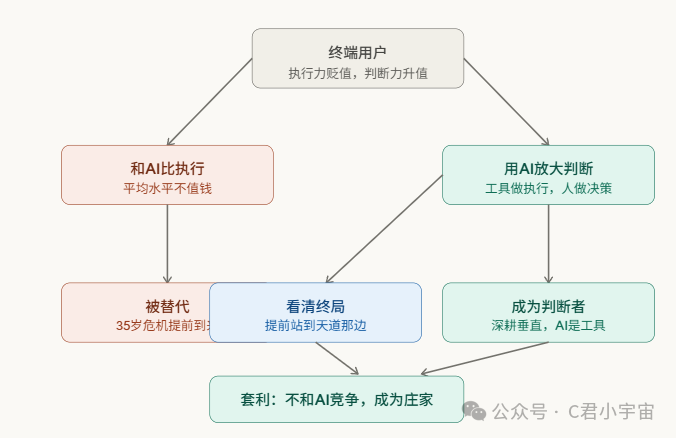
先说处境。
终端用户在这个结构里,是被服务的对象,也是被替代的对象。这两件事同时在发生,而且不矛盾。
作为消费者,用户获得了巨大的红利。
以前要雇一个律师才能做的合同审查,现在自己用AI做;以前要外包给设计师的东西,现在自己生成。工具越来越便宜,能力门槛越来越低。
但作为劳动者,用户提供的很多服务,正在被同样的工具替代。这也是开头说到的,技术不在乎你,它只在乎效率。
这个处境下的核心矛盾是:
AI让每个人的能力上限提高了,但同时也让“平均水平”变得不值钱了。
以前会写代码,就有竞争力。现在会写代码是基本盘,AI也会写,问题是你比AI多了什么。
以前会写文案,是稀缺技能。现在文案生成成本趋近于零,稀缺的是判断哪个文案好、为什么好。
所以:能力的价值在重新定价,判断力的价值在上升,执行力的价值在下降。
再说机会。
第一,做AI的放大器而不是竞争者
不要跟AI比你能做什么,而是想你有什么AI做不了。AI没有你的人际关系,没有你在某个圈子里的信任,没有你对某个具体场景的直觉。
把这些东西跟AI结合,你的产出可以是原来的十倍,而成本几乎不变。
第二,成为某个垂直领域的判断者
执行可以外包给AI,但判断不行。一个懂某个行业的人,用AI做执行,产出的质量远高于一个不懂行业的人用同样的AI。
差距不在工具,在判断力。所以深耕一个领域,让自己成为那个能判断AI输出好坏的人,比学会用更多AI工具更值钱。
第三,早于别人看到某个终局,然后站到那一边
就像西风那篇文章的做法,他不是比代练更努力,他是看到代练会被外挂干掉,然后去卖外挂。
终端用户里,早看到某个行业会被AI重塑、然后提前布局的人,跟等着被重塑的人,三五年甚至两三年后处境会完全不同。
这三个机会都有一个共同前提——你得有一样东西是真实的,不是靠AI凑出来的。可以是领域积累,可以是人际信任,可以是某种独特的判断力。
这五层也是我在做的个人梳理,不是为了得到该去那一层(这也不是我一个普通人能做到的),而是希望除了无用的焦虑之外(因为平庸的可标准化的技能注定被替代),我们可以一起尝试看看这个系统在发生什么。
所以,不是“我怎么跑赢AI”,而是 “看清楚牌局,然后坐到庄家那边”。
但我想说的不是你现在要去做AI软件卖给别人。那个结论太浅了,而且很可能只是把自己从终端用户层,换到了一个护城河同样很薄的应用层。
真正值得问的是另一个问题:
在这五层里,你已经在哪里积累了别人没有的东西?以及,如果积累很少,现在应该从哪儿开始。
这些问题,或许你可以在 云栈社区 找到更多来自开发者的视角和实践讨论。下次再聊。
 发表于 2026-4-21 21:57:59
|
查看: 172|
回复: 0
发表于 2026-4-21 21:57:59
|
查看: 172|
回复: 0
