
大语言模型驱动的长程(Long-horizon)智能体(Agent)在与环境进行多轮交互时,常常会陷入一个困境:性能越用越慢,稳定性越用越差。这是因为历史交互轨迹会不断累积,导致上下文(Context)线性膨胀。这不仅会带来高昂的Token成本,还可能触发“中间迷失”(Lost in the Middle)效应,最终导致模型性能和稳定性持续下滑。
目前的主流解决方案大多依赖外置记忆库结合RAG技术,被动地检索与当前查询相似的历史片段。但这种方式存在一个根本问题:检索到的“相似”内容,并不等同于对完成最终任务“最关键”的信息。这种记忆管理方式难以与任务目标进行端到端的联合优化,使得Agent和记忆库更像是各自为政的独立模块。
同时,一些基于强化学习改进Agent记忆管理的方法,也往往缺乏一种有效的机制来引导和优化记忆内容本身的质量。那么,我们能否让Agent在交互过程中自主地组织历史信息,并通过强化学习来优化记忆的信息质量,使其最终与任务目标对齐呢?
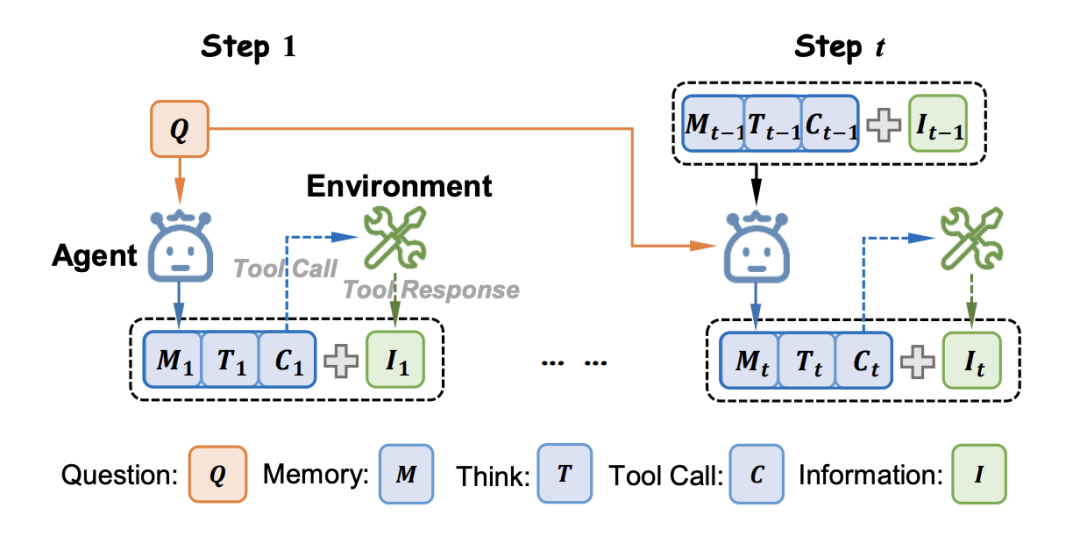
来自通义实验室和清华大学的研究团队提出的 MemPO(Self-Memory Policy Optimization) 提供了一种新的思路。该方法让模型能够对记忆(Memory)进行自我管理,并引入了基于有效信息含量的记忆层级优势估计,从而引导记忆保留对解决任务更有价值的信息,显著提升了记忆的有效性。
实验结果显示,在长程任务基准上,MemPO的F1分数最高提升了25.98%(相较于基线模型)和7.1%(相较于SOTA方法),同时Token使用量下降了67.58%和73.12%。

论文标题:MemPO: Self-Memory Policy Optimization for Long-Horizon Agents
论文地址:https://arxiv.org/abs/2603.00680
代码地址:https://github.com/TheNewBeeKing/MemPO
模型和数据集地址:https://huggingface.co/collections/NewBeeKing/mempo
核心痛点:上下文膨胀与被动记忆
长程多轮交互正日益成为LLM Agent解决复杂问题的关键能力。为了缓解由此带来的长上下文压力,许多研究开始为Agent引入记忆模块。
当前的主流方法是外置记忆库加RAG检索,即根据相似度从历史中召回片段,再拼接到提示词中。这种方式的核心问题在于,检索“相似”不等于检索到“对任务最关键”的信息,难以与最终任务目标进行端到端的联合优化。这导致记忆管理更像是一个被动的流水线操作,而非模型内生的、可学习的能力。
也有一些工作尝试用强化学习来改进Agent能力,但在“记忆”这个具体问题上仍存在局限:要么将记忆管理设计为独立的工具或组件,没有与回答、推理的策略共同优化;要么虽然将记忆融入了推理流程,却缺少针对记忆内容质量的显式优化目标,训练信号仍然主要来自最终的任务回报。
在长程交互中,奖励信号稀疏,信用分配困难。模型很难学清楚“到底是哪一步写入的记忆质量好或坏”最终影响了任务的成败,这容易导致记忆内容冗余或遗漏关键信息。
因此,MemPO的核心目标不仅是“用强化学习训练Agent”,更是要为记忆本身设计可学习、可归因的优化信号,让模型在交互过程中主动地压缩、组织并保留最有助于任务完成的信息。
MemPO:引入记忆层优势估计,引导记忆保留有效信息
MemPO采用多轮强化学习框架。在采样阶段,模型与外界进行多轮交互,在每一轮交互中,模型都会基于历史上下文生成记忆。
在计算优势函数时,MemPO采用两类优势估计相结合的方式来得到最终结果。
全局轨迹优势用于衡量整个交互轨迹的准确性,其奖励基于答案准确性和格式准确性进行计算:
$$
G^T = \{ (\tau_1, R^T(\tau_1)), (\tau_2, R^T(\tau_2)), ..., (\tau_N, R^T(\tau_N)) \}.
$$
此部分的优势估计可以表示为:
$$
A^T(\tau_i) = \frac{R^T(\tau_i) - \text{mean}(\{R^T(\tau_j)\}_{j=1}^N)}{\text{std}(\{R^T(\tau_j)\}_{j=1}^N)}.
$$
而信息性记忆优势则用于衡量每一段生成的记忆中,保留了多少对于解决问题真正有效的信息。
其奖励通过“在已知记忆内容的情况下,模型生成最终正确答案的后验概率”来表示:
$$
R^M(\tau_i(s_t^{mem})) = P[s^{ans} | \tau_i(s_t^{mem})] - \epsilon, \quad 1 \le i \le N, 1 \le t \le T.
$$
其中,后验概率具体由正确答案各个Token概率的几何平均来表示:
$$
\sqrt[L]{\prod_{l=1}^{L} \pi_\theta(a_l | q, \tau_i(s_t^{mem}), a_{<l})}.
$$
此部分的优势估计可以表示为:
$$
A^M(\tau_i(s_t^{mem})) = \frac{R^M(\tau_i(s_t^{mem})) - M(\tau_i(s_t^{mem}))}{\text{std}\{R^M(\tau_i(s_t^{mem}))\}}.
$$
通过这种方式,模型在训练过程中就能根据奖励反馈,学习到什么样的记忆内容对于解决最终问题更加有效,从而极大地缓解了记忆内容的不可控性和盲目性。
最终,整体的优势估计可以表示为:
$$
A_{i,k} = \begin{cases}
A^T(\tau_i) + A^M(\tau_i(s_t^{mem})), & \tau_{i,k} \in \tau_i(s_t^{mem}) \\
A^T(\tau_i), & \text{otherwise}.
\end{cases}
$$
实验结果
在多目标的网页搜索数据集上,与基础的ReAct、Agentic-RL模型以及基于RAG/RL的记忆算法相比,MemPO均取得了显著的SOTA性能。其中,Token消耗降低至ReAct方法的约三分之一,同时性能提升了近三倍。
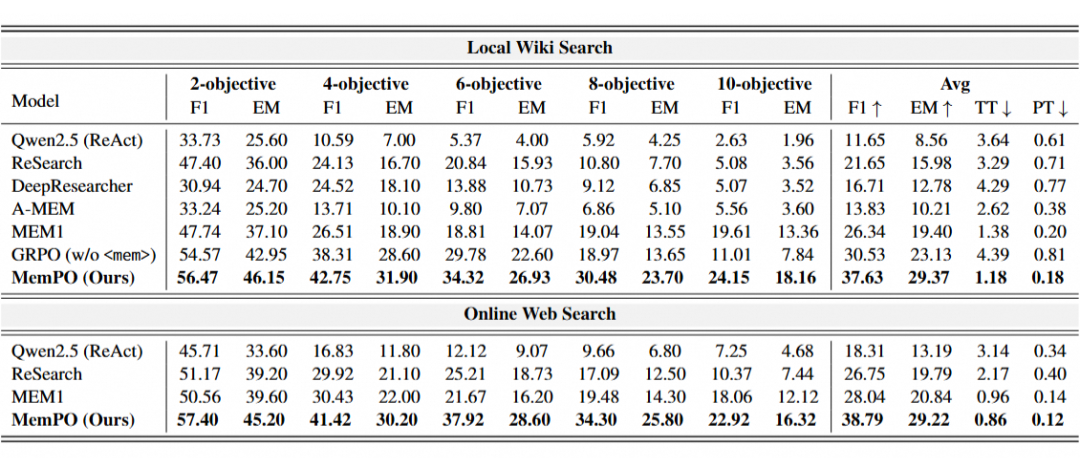
主实验结果
MemPO在提升样本正确答案条件概率的同时,也显著增加了预测结果的准确率。在复杂的长程交互任务上,MemPO显著提升了交互轮次与正确答案条件概率之间的正向关联。
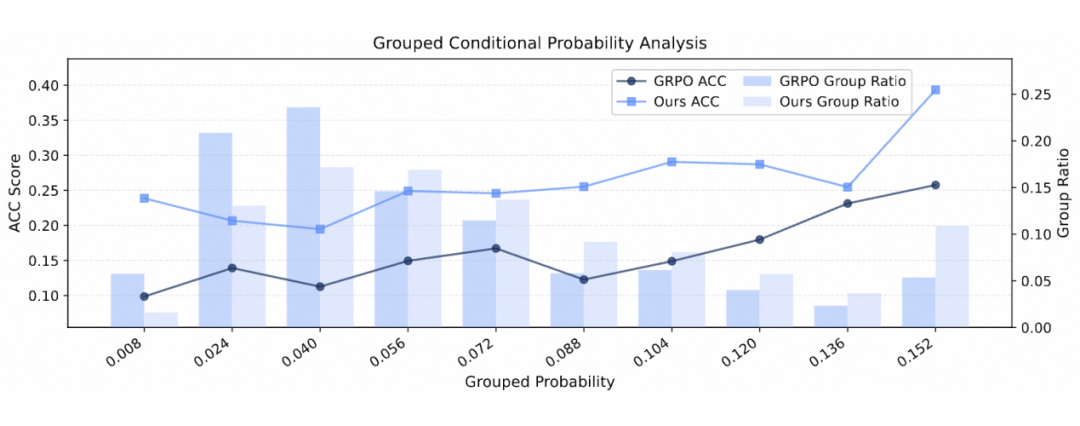
正确答案条件概率分桶样本数量分布(Ratio)与准确率(ACC)
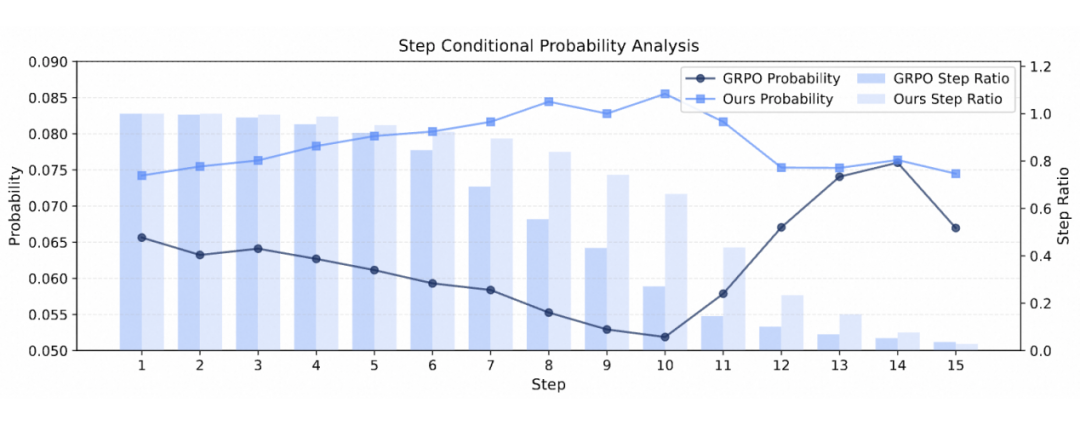
交互轮次分桶样本数量分布(Ratio)与正确答案条件概率(Probability)
随着任务复杂度提升,MemPO相比基线方法GRPO展现出更明显的优势。实验还发现,对于较为简单的任务,模型需要更丰富的上下文信息;而在更为复杂的长程交互任务上,过多的历史交互上下文反而会引入干扰信息,导致性能下降。
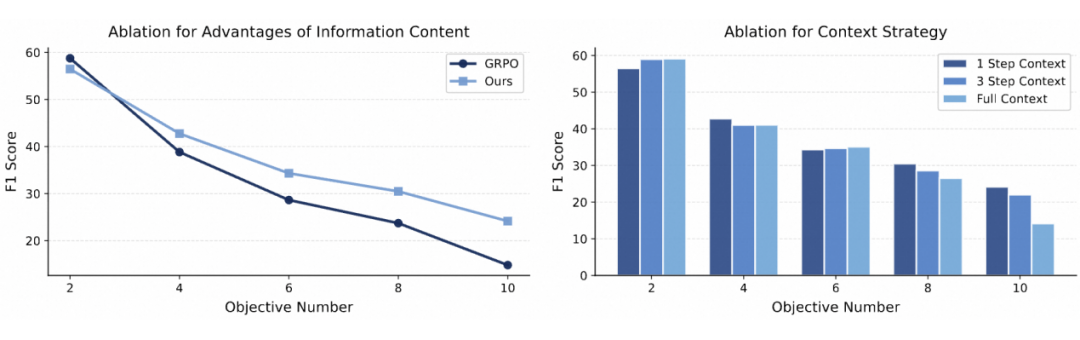
消融分析:MemPO vs. GRPO (左) / 推理时历史上下文填充策略(右)
总结
MemPO将记忆变成了一个可训练的策略变量,与模型的思考(Think)和行动(Action)进行联合优化。
通过把“书写记忆”这一行为纳入强化学习的信用分配链路,MemPO解决了长程交互中的一个关键难点——让模型能够判断哪些中间信息值得占用宝贵的上下文预算,而哪些噪声信息应该被主动丢弃。
最终,这使得Agent的上下文更短但信息密度更高,工具调用与最终回答更不容易偏离正轨,同时实现了成本下降与性能提升的双重收益。
这也意味着,未来对于长程Agent记忆的研究,关注点可能会从“如何更好地检索历史”逐渐转向“能否利用学习机制持续产出高质量、可控的内生记忆”。对这类前沿人工智能技术感兴趣的开发者,欢迎在云栈社区交流探讨。
 发表于 2026-4-22 19:31:50
|
查看: 232|
回复: 0
发表于 2026-4-22 19:31:50
|
查看: 232|
回复: 0
