深度学习已经进入了 后注意力时代。当模型生成的精度逐渐令人满意后,研究的焦点开始转向上下文长度的扩展与生成效率的提升。
设想一下,当我们需要从一本百科全书中寻找答案时,会逐字逐句通读吗?欣赏一幅细节无限的画作时,会逐个像素观察吗?显然不会。人脑的注意力资源有限,面对海量信息涌入时,会选择性地聚焦。
我们的策略通常是先概览全局,定位关键区域,再进行细致的分析与检索。这正是后注意力时代处理长序列场景所面临的挑战:传统注意力机制需要对整个序列进行Softmax计算,带来了巨大的计算开销和KV Cache存储负担,我们遇到了“注意力不够用”的难题。
模仿人脑处理方式的稀疏化技术 应运而生。无论是大语言模型(LLM)还是扩散Transformer(DiT),稀疏化几乎是当前最合理且最具前景的加速方案。本文将梳理2025年以来蓬勃发展的稀疏注意力生态,涵盖LLM领域的NSA、FSA、MoBA、FlashMoBA、DSA,DiT领域的DSV、SVG、VSA、SLA,以及通用的训练后稀疏策略SpargeAttn。
1. 背景知识:MHA、MQA、GQA与MLA
- MHA:传统的多头注意力。每个注意力头代表一种关注的特征,在解码阶段每个头都有自己的KV Cache。
- MQA:2019年提出,旨在减轻KV Cache负担。其核心是多头Query共享同一组KV,减少了近一半的注意力参数,但可能牺牲一些精度。
- GQA:折中方案,一组Query共享一个KV。例如Llama2/3中设置组大小为8,这个数字是软硬件协同设计的结果,能较好地满足分布式部署时的张量并行效率。
- MLA:DeepSeek-v2中采用的架构。它从投影角度压缩KV表示,提供了更灵活的显存-精度权衡,并通过低秩分解进一步压缩KV Cache。
稀疏注意力 的定义非常直观:在计算注意力权重时,不再让每个Token都与序列中所有Token交互,而是根据某种规则,只选择一小部分“重要”的Token进行计算。
实现稀疏化的核心挑战在于:我们如何预先知道哪些Token之间是重要的? 理想情况下,我们只想计算那些权重大的位置,但在进行全量计算之前,这很难精确知晓。目前主要有三种方案:
- 先验固定模式:基于对数据特性(如局部相关性)的观察,预设固定的计算规则。
- 在线动态预测:在推理过程中,使用轻量级算法实时预测重要的Token。
- 后训练学习:在模型训练(或微调)完成后,通过分析其注意力分布来学习稀疏模式。
| 方案类型 |
开发工作量 |
理论效果 |
硬件友好度 |
适用场景 |
| 先验固定 |
低 |
中 |
高 |
预训练长文本模型、端侧轻量化 |
| 在线预测 |
中 |
中上 |
中 |
动态长度变化大的序列处理 |
| 训练后预测 |
高 |
极高 |
中下 |
大模型推理加速、KV Cache压缩 |
一个优秀的稀疏策略应力求平衡:既要实现简单,又要保证算法的高一致性,同时还需对硬件友好。
2. NSA:硬件对齐且原生可训练的稀疏注意力
2025年2月,由北京大学和DeepSeek团队提出的NSA获得了ACL 2025最佳论文。有趣的是,DeepSeek V3.2最终并未采用此架构。
1. NSA概述
对于每个输入的查询(Query),NSA首先对完整的键值(KV)序列进行Token压缩,通过一个粗粒度的压缩注意力(Compressed Attention)进行稀疏筛选,再进行细粒度的稀疏注意力运算。对于靠近当前Query Token的上下文,则采用滑动窗口注意力(Sliding Window Attention),即默认被选中,无需压缩。
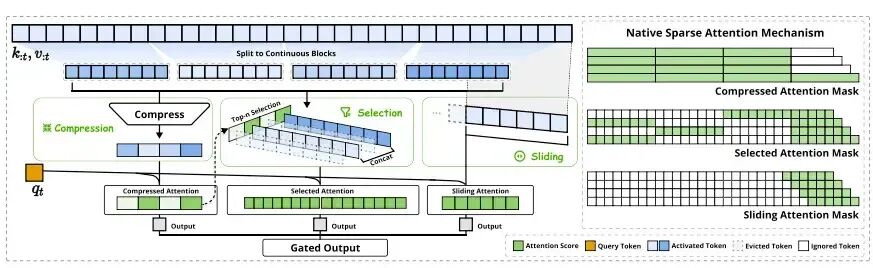
这种选择性注意力方案能显著减少计算开销。更妙的是,它通过减少无关“噪声”的干扰,使模型更“集中注意力”,从而可能提升性能。
2. 现有稀疏方法的局限
许多方法虽声称降低了计算复杂度,但实际推理延迟并未同比减少,主要受限于:
- 阶段限制:有些方法只能在预填充(Prefill)或解码(Decode)阶段实现稀疏。
- 与现代架构不兼容:与MQA、GQA等高效架构的内存访问模式冲突。
此外,训练时的稀疏化面临挑战:
- 训练后应用的稀疏化可能使模型偏离预训练轨迹,导致性能下降。
- 稀疏的离散操作会阻断梯度传播,而不连续的内存访问又难以利用Flash Attention等高效算子。
3. 算子设计
NSA的目标是设计一个支持训练、支持Prefill/Decode、兼容GQA/MQA且性能媲美Flash Attention的算子。因此,必须在硬件层面进行对齐,在Triton级别进行设计。
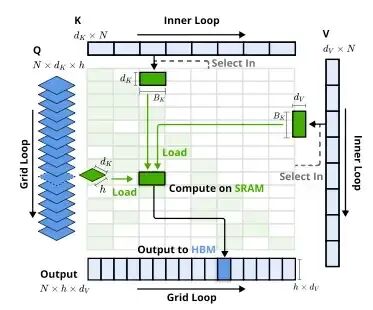
其核心思想是:加载固定块大小(Block Size)的、经过索引的KV对,尽量填满SRAM和Tensor Core。外层循环(Outer Loop)遍历每个Query生成输出,内层循环(Inner Loop)则处理索引后的KV块。
3. FSA:NSA稀疏注意力内核的另一种高效实现
2025年8月,由Relaxed System Lab(港科大、CMU)提出,旨在解决NSA实现中的潜在效率问题。
1. 动机:NSA的问题
高效的稀疏意味着将理论减少的FLOPS切实转化为访存和计算的降低。NSA采用分批处理查询头(Query Head)的方式,但如果查询头数量不足,就需要填充(Padding)以满足Tensor Core矩阵乘的形状要求,这会带来额外的访存和计算浪费。
FSA改变了循环策略:内层循环遍历Query,而KV放在外层循环。在解码阶段,KV数量通常足够多,因此能保证以KV为单位的运算是满载的。
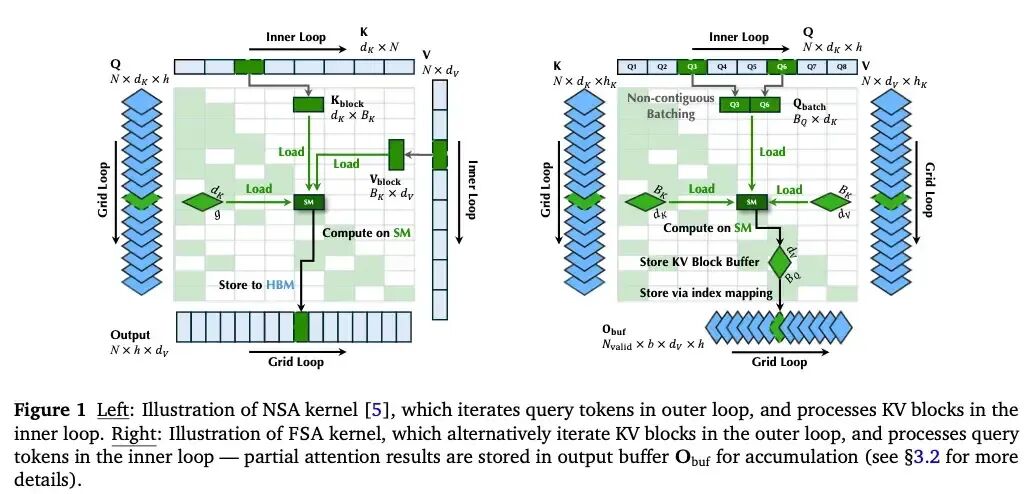
2. 挑战与方法
- 挑战:访存不连续。对Query Token的访问取决于KV索引,可能导致不连续的访存开销。
- 方法:使用索引张量来调控数据搬移。输入索引
Ii 记录每个KV块需要处理的Query索引,输出索引 Oi 管理中间结果的连续存储。理论上,NSA(固定Q访存KV)和FSA(固定KV访存Q)所需的访存量相同。
- 挑战:结果分散。一个Query的在线Softmax结果可能分散在不同的KV块对应的线程块中。
- 方法:设计一个专用的归约(Reduction)内核,在缓冲区中对分散的在线Softmax结果进行聚合。虽然引入了额外开销,但论文显示其影响很小。
3. 实验解读
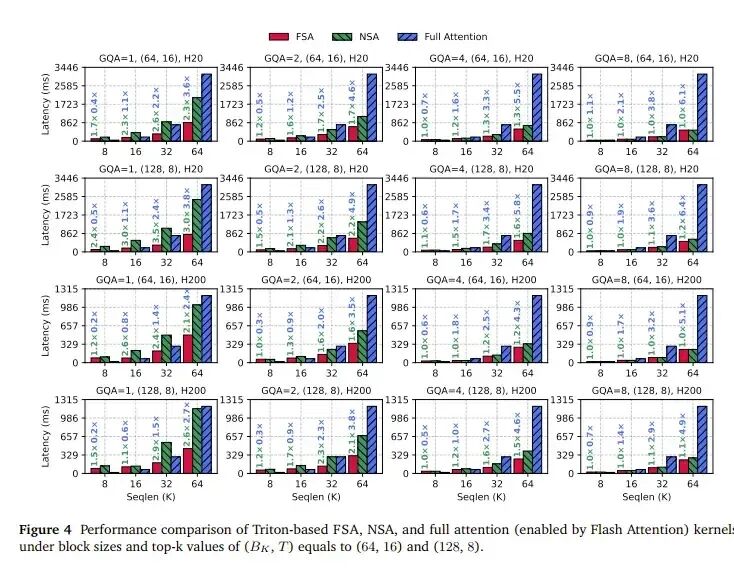
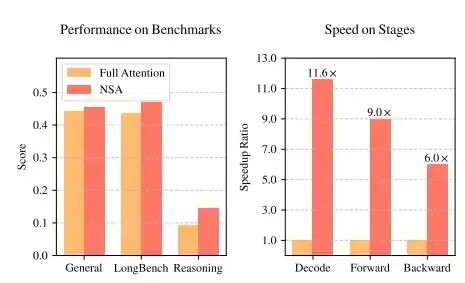
- 序列长度:序列越长,各类注意力计算的延迟都增加,但全注意力是 $O(N^2)$ 增长,稀疏注意力因只关注Top-K个KV而近似 $O(N)$ 增长,优势随长度增加而愈发明显。
- 短序列劣势:当序列长度=8K时,全注意力反而最快。因为此时稀疏注意力需要选择的KV数量(64×16=8192)已接近全量,计算量未减少,还多了选择开销。
- GQA的影响:当GQA=1(查询头组数少)时,FSA在部分配置下优于全注意力,而NSA则因Query组太少导致填充开销大,性能较差。随着GQA增大(如GQA=4, 8),NSA因填充减少性能提升,逐渐与FSA持平。
4. MoBA:面向长上下文LLM的混合块注意力
2025年2月18日,与NSA同日发布的Kimi AI工作,思路高度相似。
MoBA认为现有主流方案(如线性注意力、滑动窗口注意力)或多或少加入了启发式先验。它借鉴混合专家(MoE)的思想,将“如何使用注意力”的决定权交给模型通过梯度下降来学习,理论上更接近最优。
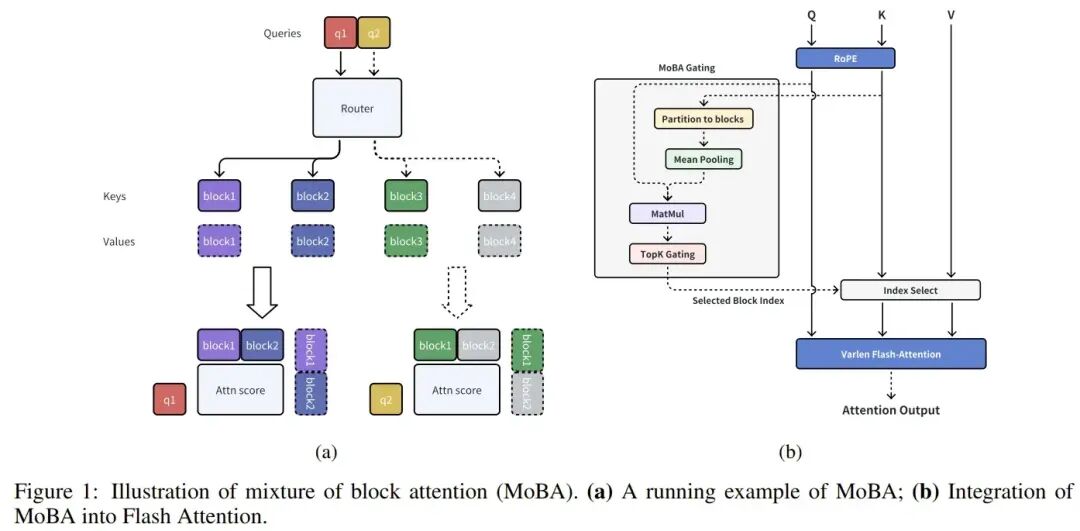
核心思想仍是选择KV。将KV按块(Block)分组,每个Query通过一个路由器(Router)选择它感兴趣的KV块。选择机制是:将每个KV块压缩为一个代表向量,然后通过Query与这些压缩后K的矩阵相乘结果来选择Top-K个块。
除了没有像NSA那样显式设置局部滑动窗口先验,MoBA与NSA的核心思路非常相似。两者的主要区别可能在于实现层级(NSA用Triton重写算子,MoBA起初是较高级的Python代码)和后续的生态发展。
5. FlashMoBA
紧随MoBA之后,2025年11月MIT与NVIDIA合作推出了FlashMoBA,旨在解决MoBA的算子效率问题。
1. 动机
- MoBA的简化结构在可理解性上有所欠缺。
- MoBA缺乏高效的底层算子支持。
因此需要进行算法-硬件协同设计,以找到高精度且硬件友好的参数配置。
2. 算法建模
论文对MoBA进行了数学建模,旨在提高路由器预测的准确性。分析得出了两个启发式结论:
- 优化头维度(Head Dimension)与块大小(Block Size)的比值,这直接影响路由器选择的信噪比。
- 对Key进行卷积操作,以更好地聚合信息。
3. 算子优化
MoBA在块大小较小时会遇到密集的访存问题,此时Top-K选择和门控(Gating)计算反而成为瓶颈。FlashMoBA采用了稀疏计算中常见的高效策略:稀疏重排后设计专用的稠密算子。
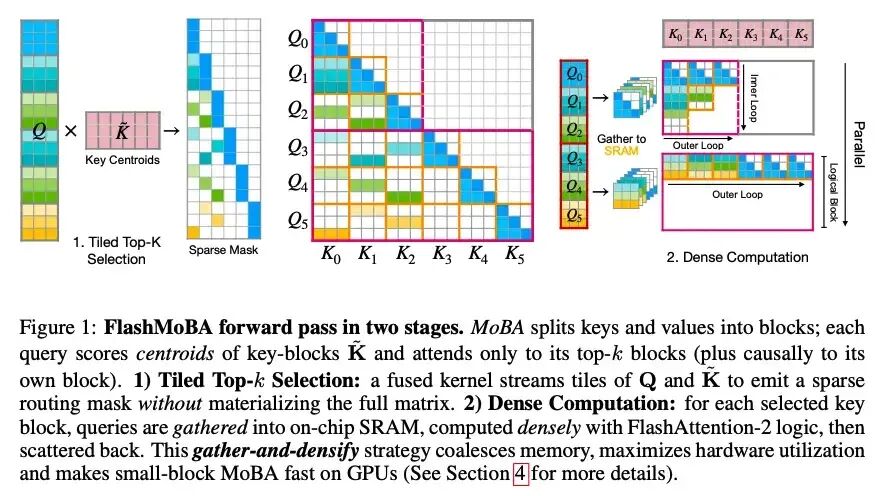
该方案识别出稀疏掩码中的两种数据模式,并进行了高效的重排,最终集成为三个高效的内核。
4. 实验结果
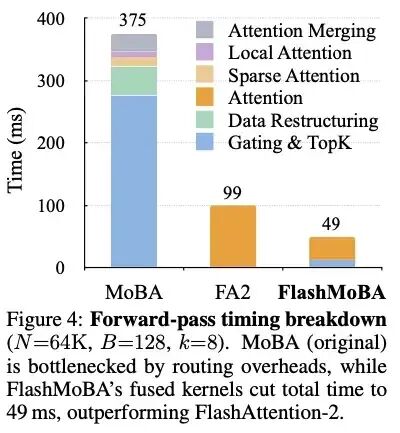
在效率方面,FlashMoBA通过调整超参数(如将块大小从512细化到128,Top-K从3增加到8)并优化算子,实现了显著的性能提升。
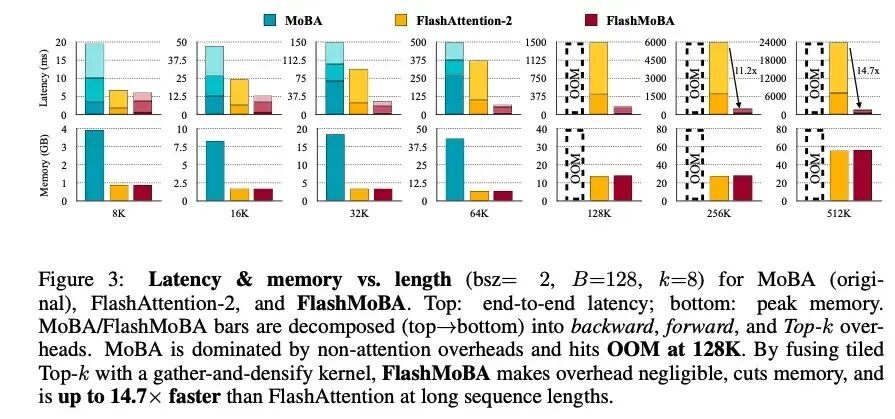
从耗时分解图可以清晰看到,原始MoBA中,Top-K和门控操作的开销占据了相当大比例,而FlashMoBA通过融合内核极大降低了这部分开销。
6. DSA:DeepSeek稀疏注意力
这是DeepSeek V3.2实际采用的注意力架构。命名为DSA,彰显了DeepSeek对此架构的信心。
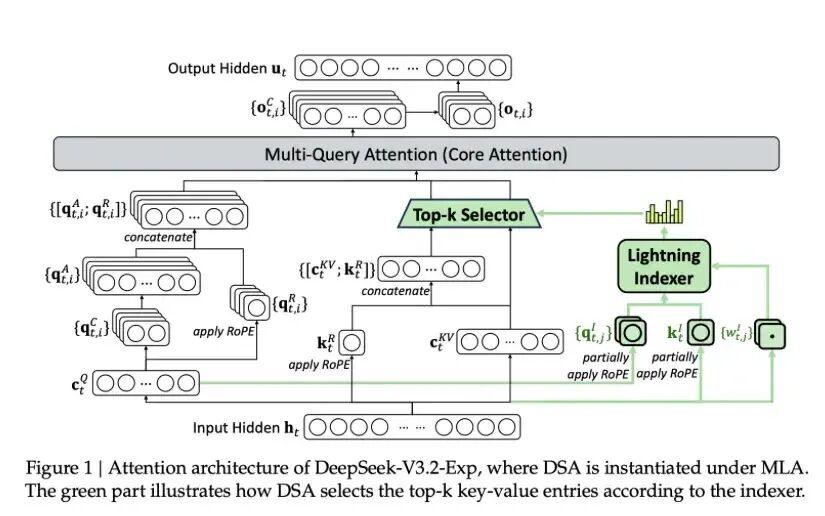
DSA延续了NSA选择KV的思路,并结合了V2中MLA压缩KV表示的思想。上图中绿色部分即为在V3.1的MLA基础上新增的稀疏注意力组件。其中,Lightning Indexer(类似于NSA中的小块注意力)负责对压缩后的KV表示进行Top-K选择。
1. 后训练流程
V3.2是在V3.1的MLA基础上继续进行训练的,分为两个阶段:
- 稠密热启动阶段:冻结其他参数,仅训练Lightning Indexer,使其学会模仿稠密注意力中的KV选择策略。
- 稀疏训练阶段:在Indexer能够有效工作后,解冻并进行全局参数的微调。
2. 结果
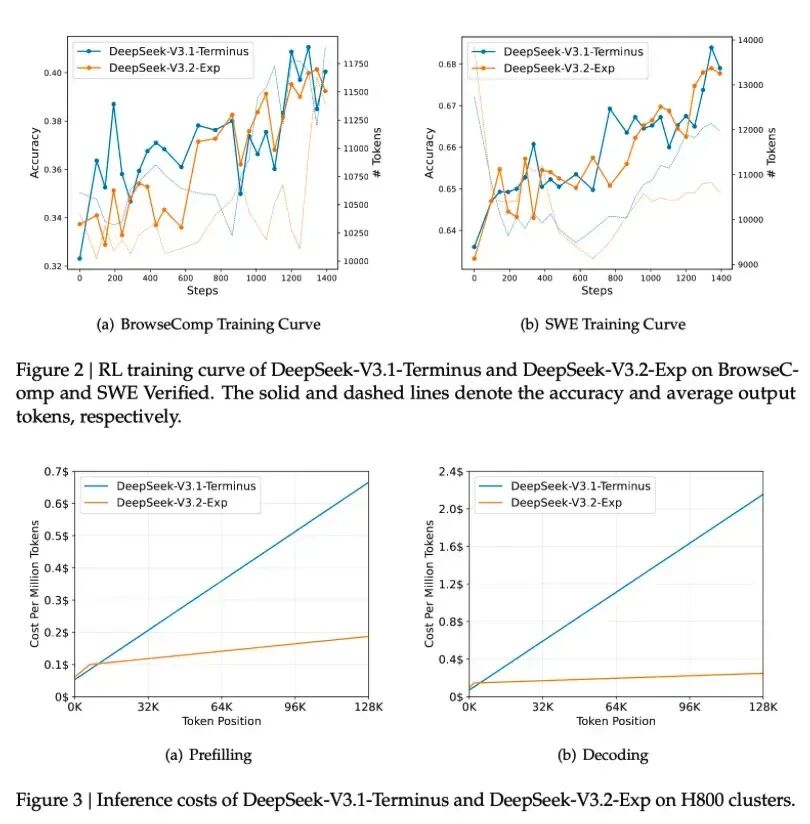
实验表明,在保持相同训练精度的前提下,DSA能显著降低每个Token的生成成本,且随着序列长度增长,稀疏带来的收益越明显。
7. DSV:面向视频DiT训练的动态稀疏注意力
2025年2月由港中文和StepFun提出的工作,将稀疏注意力应用于视频DiT的训练阶段。
1. 核心观察
在视频DiT中,注意力矩阵的稀疏度很高,且稀疏模式并非固定不变。
2. 算法与系统设计
DSV采用两阶段训练:
- 训练一个低秩近似预测器来估算注意力分数,从而捕捉关键KV。
- 利用预测出的关键KV训练模型全局参数。
在此基础上,DSV设计了专用的预测器和稀疏注意力算子,并支持了面向稀疏的序列并行训练。
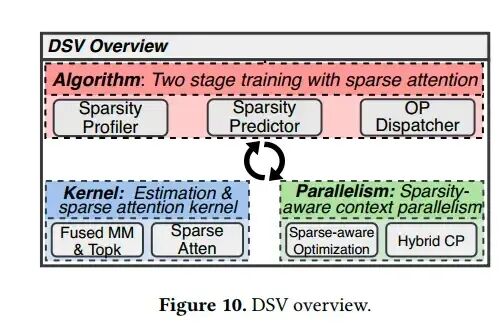
3. 算子优化
下图表明,低秩注意力本身开销不大,但Top-K操作是访存密集型的低效排序操作,稀疏注意力计算也有硬件优化空间。
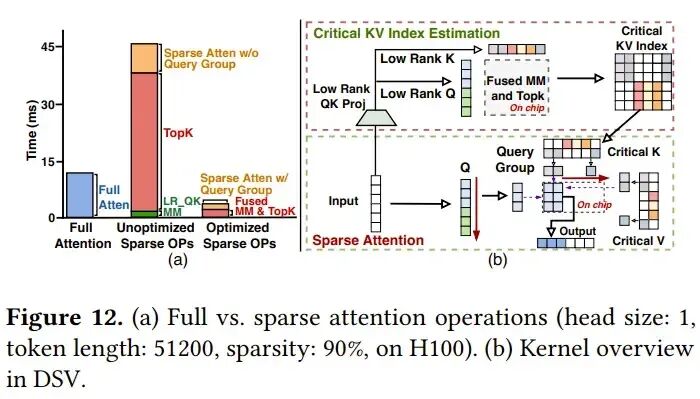
4. 并行设计
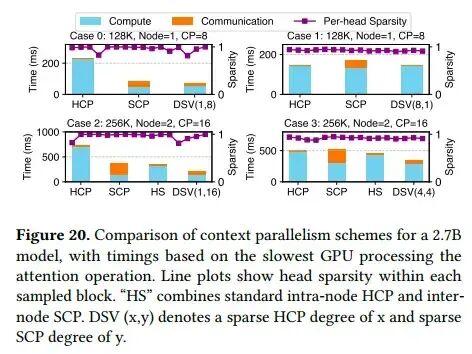
DSV在选择性KV的基础上,实现了头间上下文并行(Head-wise CP)和序列间上下文并行(Sequence-wise CP)。结合策略取决于头数量、通信开销等因素。实验表明,在稀疏度不均衡的情况下,DSV的并行方案能有效提升效率。
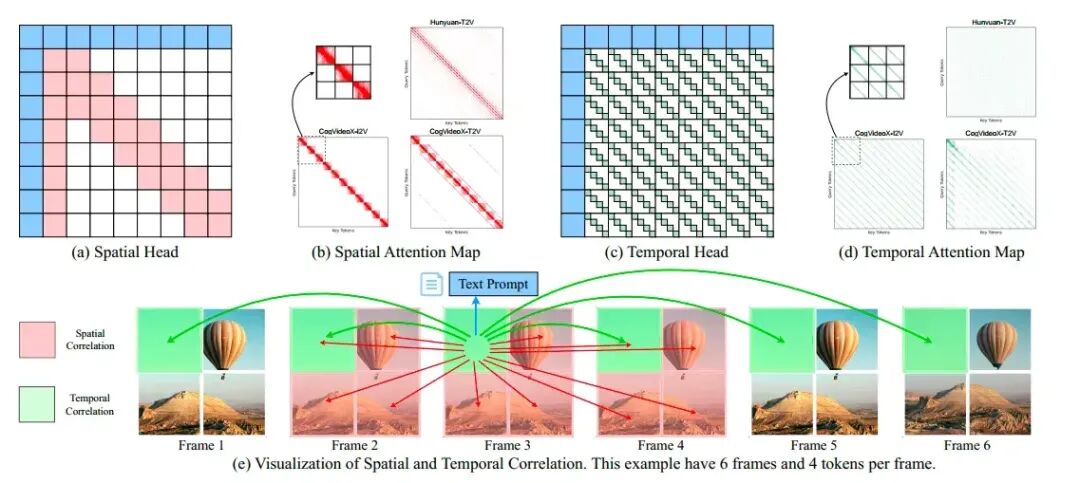
8. SVG:面向视频推理的时空稀疏注意力
2025年4月MIT Han Lab的工作,是较早将稀疏注意力应用于视频生成推理的工作。
SVG采用的稀疏模式是固定的。其核心观察是:视频生成DiT中的注意力头可以大致分为空间头和时间头。基于此固定模式,SVG设计了特定的数据布局转换和稀疏内核。后续的SVG2虽然仍无需训练,但承认了稀疏模式并非完全固定,采用了更灵活的预测方法。
9. VSA:可训练的视频稀疏注意力
2025年10月UCSD Hao Lab的工作,旨在通过训练引入稀疏性。
1. 动机
在视频DiT推理中,全注意力是主要的计算瓶颈。视频数据的时空局部性比文本更明显,因此对稀疏化和高效化的需求更迫切。
2. 方法
与MoBA类似,VSA也采用“先粗选,后细算”的两级策略:压缩QKV进行粗粒度注意力以选择Top-K,然后在细粒度的KV立方体上进行稀疏注意力计算。立方体大小的选择是精度与效率的权衡。与MoBA不同的是,VSA通过一个门控(Gate)合并了粗粒度和细粒度的输出,作为全局信息的补充。
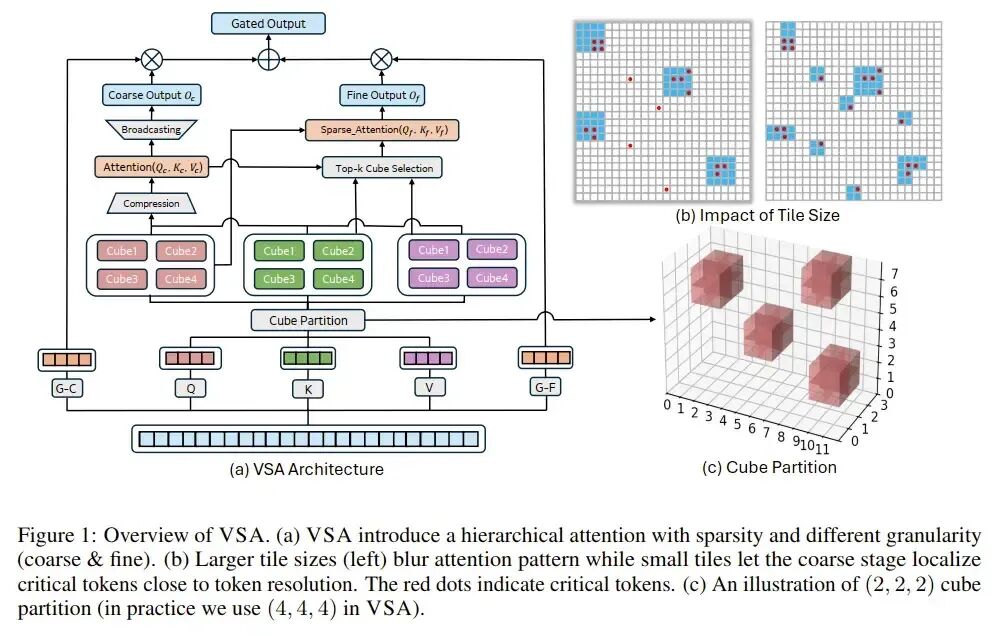
3. 实验观察
- 质量优势:VSA在加速的同时,保持了甚至略微提升了生成质量,推动了延迟-质量权衡的边界。
- 动态模式:文章通过可视化指出,注意力头的稀疏模式会随着生成内容高度变化,这与SVG的固定模式假设形成了对比。
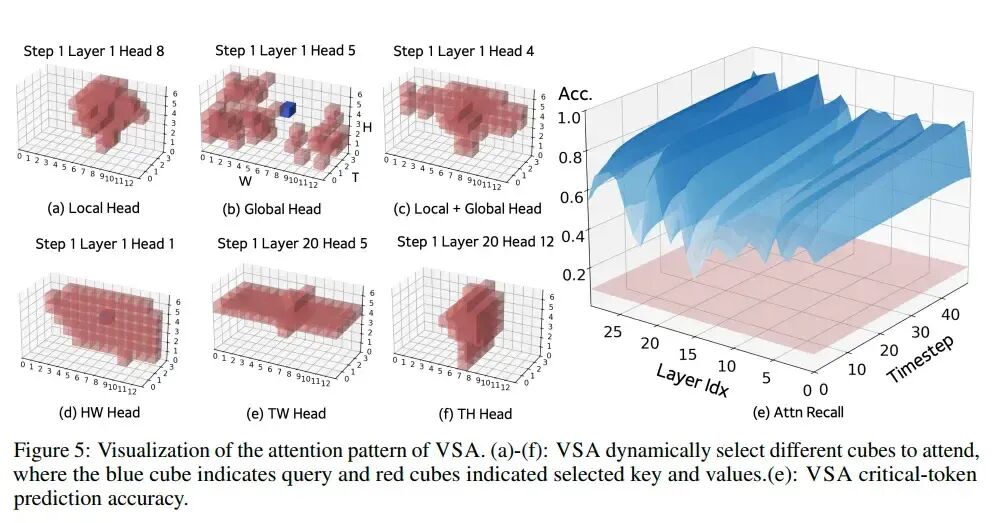
10. SLA:稀疏线性注意力
2025年11月清华朱军组的工作,专注于优化DiT的注意力计算。
1. 核心观察
注意力权重可以解耦为两部分:一小部分大权重(高秩)和剩余的大量小权重(低秩)。
2. 核心思想
对高秩部分(关键权重)使用稀疏注意力精确计算,对低秩部分(边缘权重)使用线性注意力近似计算,对可忽略的权重直接跳过。
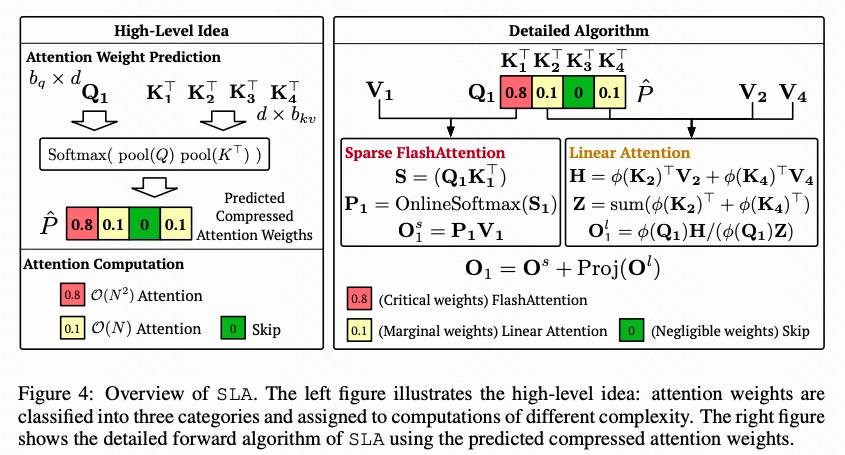
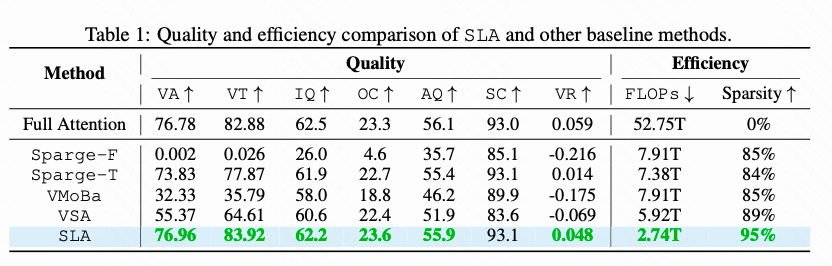
3. 与SpargeAttn的对比
SLA在实验中与SpargeAttn进行了比较。需要注意的是,标准的(无需训练的)SpargeAttn在某些小模型上效果不佳,但可训练的SpargeAttn-T版本则表现优异。SLA的优势在于引入了线性注意力来处理低秩部分,但需要微调这一点可能限制其应用。
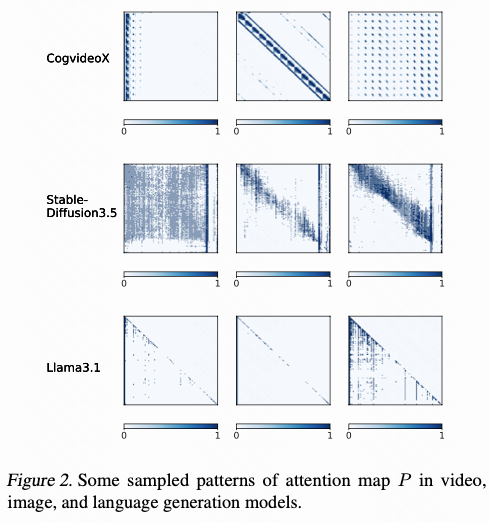
11. SpargeAttn:精准且无需训练的通用稀疏注意力
ICML 2025,同样来自清华朱军组的工作。Sparge是Sparse + Sage(一种量化方法)的结合,旨在利用稀疏性在量化的基础上进一步提升性能。
文章目标是实现一种通用的稀疏注意力,保证对多样化模型都能实现加速且不损失端到端性能。
1. 预测算法
SpargeAttn提供了一种通用预测算法:首先通过余弦相似度将Token划分为相似块,然后通过均值池化将块压缩为代表性Token,最后在这些压缩后的Token上计算稀疏模式。
q = {q_i} = {mean(Q_i, axis = 0)}
k = {k_j} = {mean(K_j, axis = 0)}
s_qi = CosSim(Q_i), s_kj = CosSim(K_j)
Ŝ[i] = q_i k^T, Ŝ[i,j] = -∞, If s_kj < θ
P̂[i] = Softmax(Ŝ[i])
2. 算子实现
SpargeAttn将稀疏方法与8-bit量化框架Sage-Attention相结合。Sage对QK进行量化但不跳过计算,而Sparse策略则决定是否跳过计算,两者在性能提升上是正交且可叠加的。
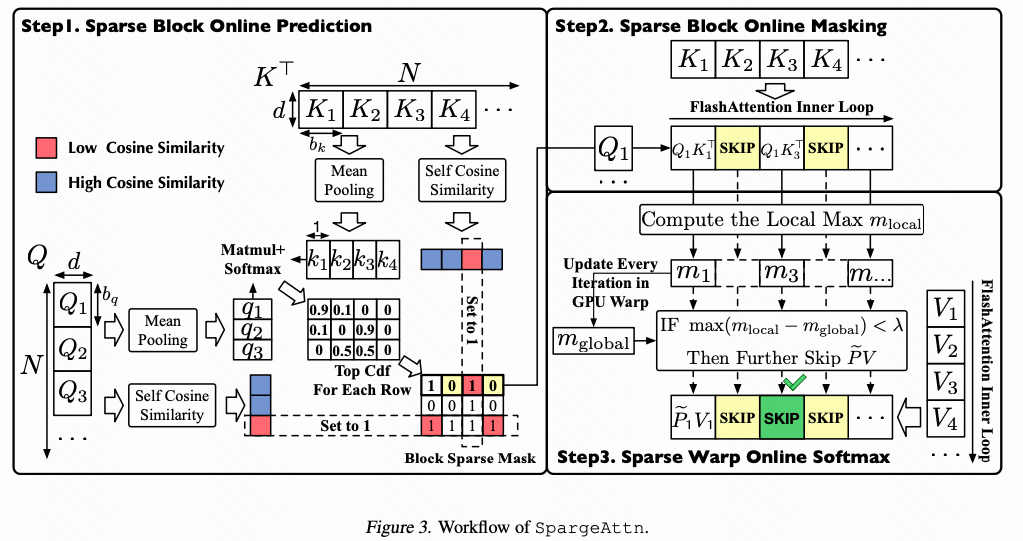
3. 小巧思:Token重排
通过希尔伯特曲线等顺序对Token进行重排,可以增强同一块内Token的相似性,从而提高预测的稀疏度。

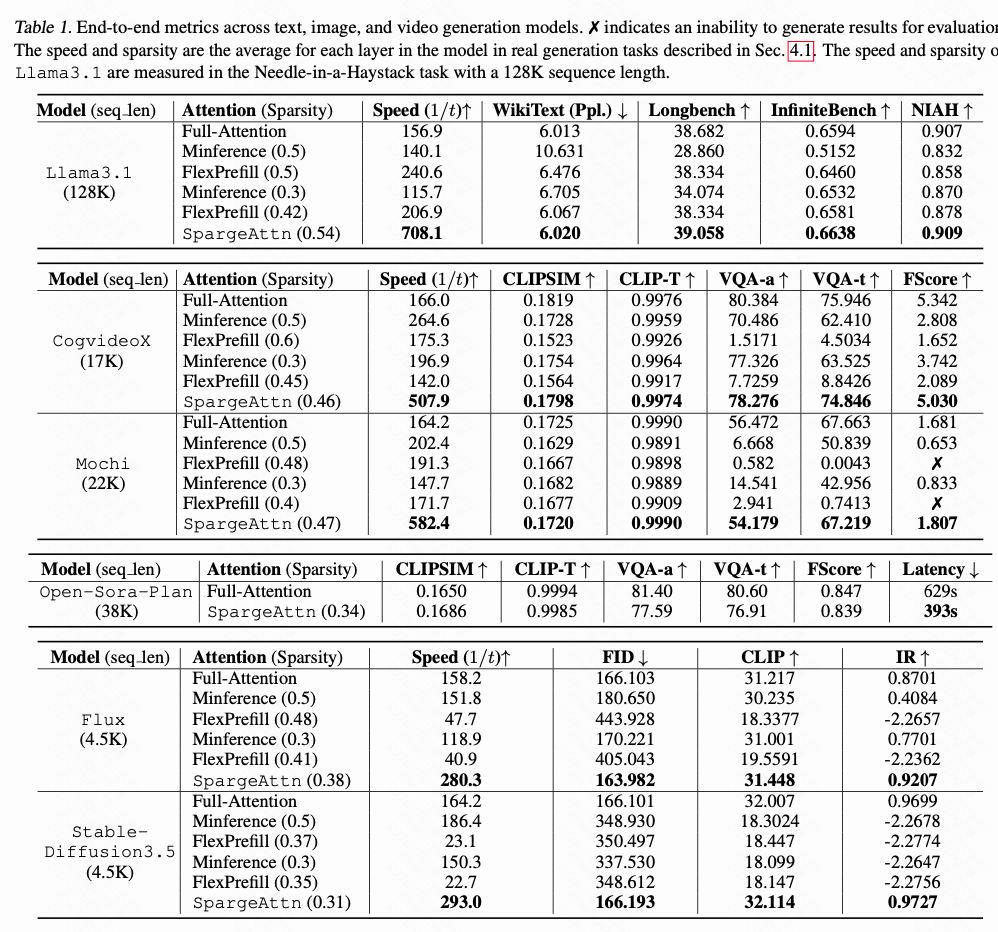
4. 实验结果
SpargeAttn在文本、图像、视频等多种生成模型上进行了广泛的端到端评估,实验较为完善。其“无需训练”的特性使其具有很好的易用性。
12. 总结
稀疏化已成为“后注意力时代”的关键技术方向。模仿人脑“先粗选,后细察”的处理范式,在LLM和DiT领域都得到了广泛拥抱。
从系统视角看,在LLM上应用稀疏主要加速解码,但仍受KV Cache显存限制;在DiT上应用则能直接且显著地降低计算负载。稀疏性的实现与软硬件协同设计紧密绑定,算法、算子与并行设计日益耦合,这或许是未来计算架构设计的新趋势。
技术的发展日新月异,对于开发者而言,关注云栈社区等技术论坛,能及时获取最新的开源实战项目信息与深度技术解析,保持在人工智能浪潮中的竞争力。
 发表于 2026-4-21 20:49:30
|
查看: 242|
回复: 0
发表于 2026-4-21 20:49:30
|
查看: 242|
回复: 0
