看了很多文章和视频,我以为我搞懂了大模型是怎么工作的了,直到我翻开了 vLLM 的源码。才发现,不少地方之前理解得实在太浅了。于是,我花了大约两个月的业余时间来研读 vLLM 源码,这篇文章算是我对这段学习经历的一个梳理和总结。另外,考虑到当前主流 LLM 大多采用 Decoder-Only 架构,本文会聚焦于此,不再像很多介绍 Transformer 的文章那样,从原论文的 Encoder-Decoder 架构讲起。
在阅读 vLLM 源码时,我发现追踪推理过程中每一步的张量(Tensor)维度变化,对理解大模型原理帮助极大。所以,本文将以 Llama 3 为例,一步步拆解推理过程中的每个计算环节,并会在每个环节都标出张量的维度变化。
我们知道,通过批处理,GPU 的利用率能得到有效提升。其本质在于提升计算强度,也就是通过复用权重数据来摊薄访问内存的开销;至于减少 Kernel 启动次数、利用海量 warp 隐藏延迟等优化,更多的是随之而来的“副产物”。但批处理有个前提,就是所有请求必须步调一致地开始,也步调一致地结束。可对 LLM 这类生成式任务来说,一个根本矛盾在于:每个请求的输出序列长度是完全不可预测的,差异巨大。这该怎么解决呢?
我们能不能把调度的粒度,从请求(request)级别下沉到 Token 级别呢?如果能,你就发明了连续批处理。
相应地,每个请求的 KV Cache 显存申请,是不是也该变成 Token 级别的,而不是一次性申请所有显存?搞一个地址数组(Block Table)来维护每个请求的 KV Cache 地址,怎么样?恭喜你,你又发明了Paged Attention。
没错,以上这两个概念,正是当代大模型能实现高性能运行的关键。
连续批处理
在 vLLM 调度器的视角里,其实并没有所谓“Prefill 阶段”和“Decode 阶段”的严格区分。它只关心每个请求的两个核心指标:
num_computed_tokens:已经计算过的 token 数(这包括了通过 Prefix Cache 命中的部分)num_tokens:该请求当前总共拥有的 token 数(prompt + 已经生成的 output)
每一步调度的目标都非常明确:就是让 num_computed_tokens 尽可能追上 num_tokens。差多少,就调度多少——当然,这一切都要在 token 预算之内。
调度会受 4 个硬性约束的限制:
- 最大并发请求数
self.max_num_running_reqs = scheduler_config.max_num_seqs
- token budget 单步最多计算多少 token(所有请求之和),这控制了 GPU 的计算量上限。
self.max_num_scheduled_tokens = (
self.scheduler_config.max_num_scheduled_tokens # 优先用这个
if self.scheduler_config.max_num_scheduled_tokens
else self.scheduler_config.max_num_batched_tokens # fallback
)
- 模型最大序列长度
self.max_model_len = model_config.max_model_len
- 是否还有空闲的 KV Cache blocks
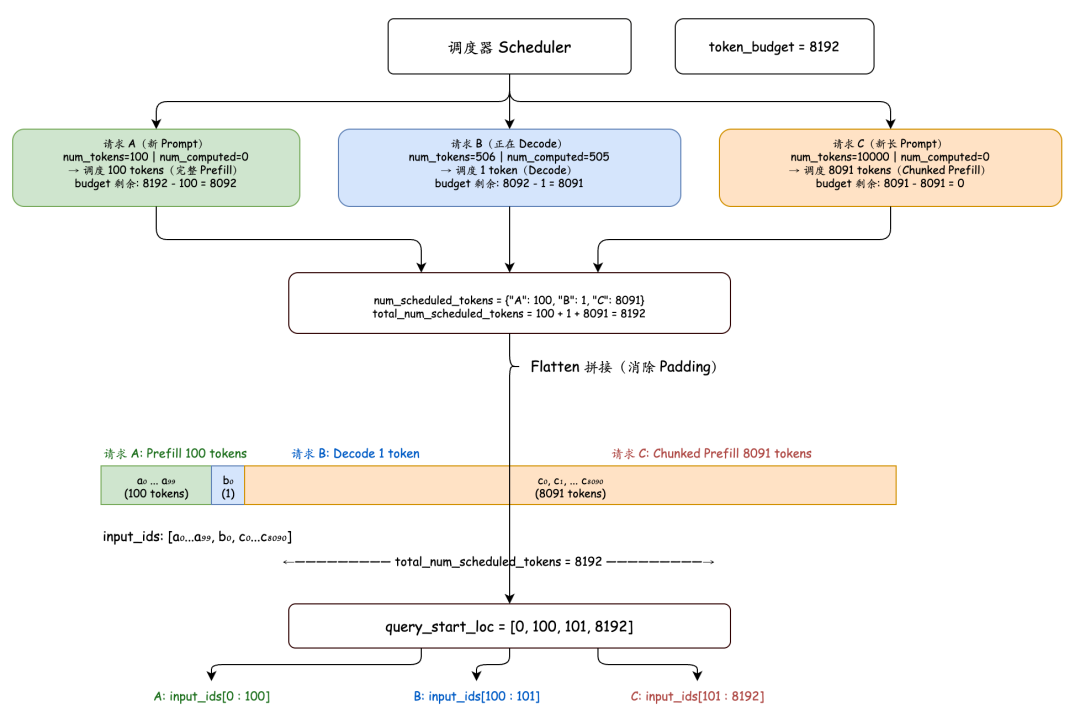
如上图所示,vLLM 的每一轮推理都是基于 token 级别来调度的。后续的计算输入,都是类似 input_ids 这种被打平的 token 数组(Flattened)。本文后文中提到的 num_sched_tokens,对应的其实就是图中的 total_num_scheduled_tokens。
Paged Attention
vLLM 在启动时,会预先申请一块显存,其 KV Cache 的形状(shape)为:[num_layers, 2, num_blocks, block_size, num_kv_heads, head_dim]。这意味着,对于每一层,key_cache 和 value_cache 的形状都是 [num_blocks, block_size, num_kv_heads, head_dim]。
而 block_table 则记录了每个请求被分配到的物理块 ID,它的形状是 [max_num_reqs, max_num_blocks_per_req]。比如,请求 0 可能被分配了块 [5, 8, 12],请求 1 分配了 [3, 7]。
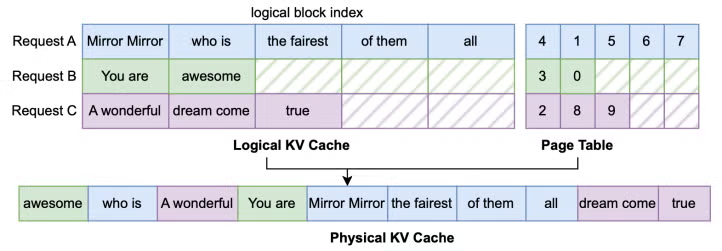
为什么 slot_mapping 和 block_table 都不需要 num_layers 这个维度?
这是因为,如果一个请求的第 25 个 Token 被分配到了物理块 ID 为 8 的位置,那么在模型的第 0 层到第 31 层,这个 Token 的 KV 值都会被存储在这个物理块 8 的相同位置上。
在推理过程中,slot_mapping 负责告诉 kernel,新产生的 KV 数据应该写到哪个 slot 里去;而 block_table 则告诉 kernel,需要去哪些物理 block 里读取历史的 KV Cache。
// slot_idx对应token最终存储位置: slot_idx = block_idx * block_size + block_offset
const int64_t slot_idx = slot_mapping[token_idx];
const int64_t block_idx = slot_idx / block_size; // 计算块索引
const int64_t block_offset = slot_idx % block_size; // 计算块内偏移
举个例子,假设 block_size = 16(每个块存储 16 个 token),请求 0 的 block_table 是 [5, 8, 12],我们要找第 25 个 token 的位置:
block_idx = 25 // 16 = 1(它属于第 1 个虚拟块)block_idx = block_table[0, 1] = 8(从页表里查到对应的物理块 ID)block_offset = 25 % 16 = 9slot_idx = 8 * 16 + 9 = 137
PagedAttention 的这套虚拟页表机制,很好地解决了显存碎片的问题,把 GPU 的显存利用率大大提高,是支撑 Continuous Batching 高性能推理的基石。
不过,PagedAttention 引入的 block_table 间接寻址,也打破了一个请求在物理显存上的绝对连续性。当 Attention Kernel 需要跨 block 去读取历史 KVCache 时,就会触发离散访存(Uncoalesced Access)。这在底层对 Memory Controller 不太友好,也会导致 L2 Cache 的命中率下降,带来一定的带宽损耗。当然,系统设计说到底就是一个权衡(Trade-off)的过程。
vLLM 通过设置一个合理的 block_size(默认通常是 16)来缓解这个问题。在一个 block 内部的 16 个 Token,它们的物理显存依然是连续的,保证了高效率的合并访存。相比于因为显存碎片直接 OOM,牺牲一小部分访存带宽来换取整个系统吞吐量的大幅提升,在 LLM 推理的大局观下,这笔账是划算的。
LLM推理流程
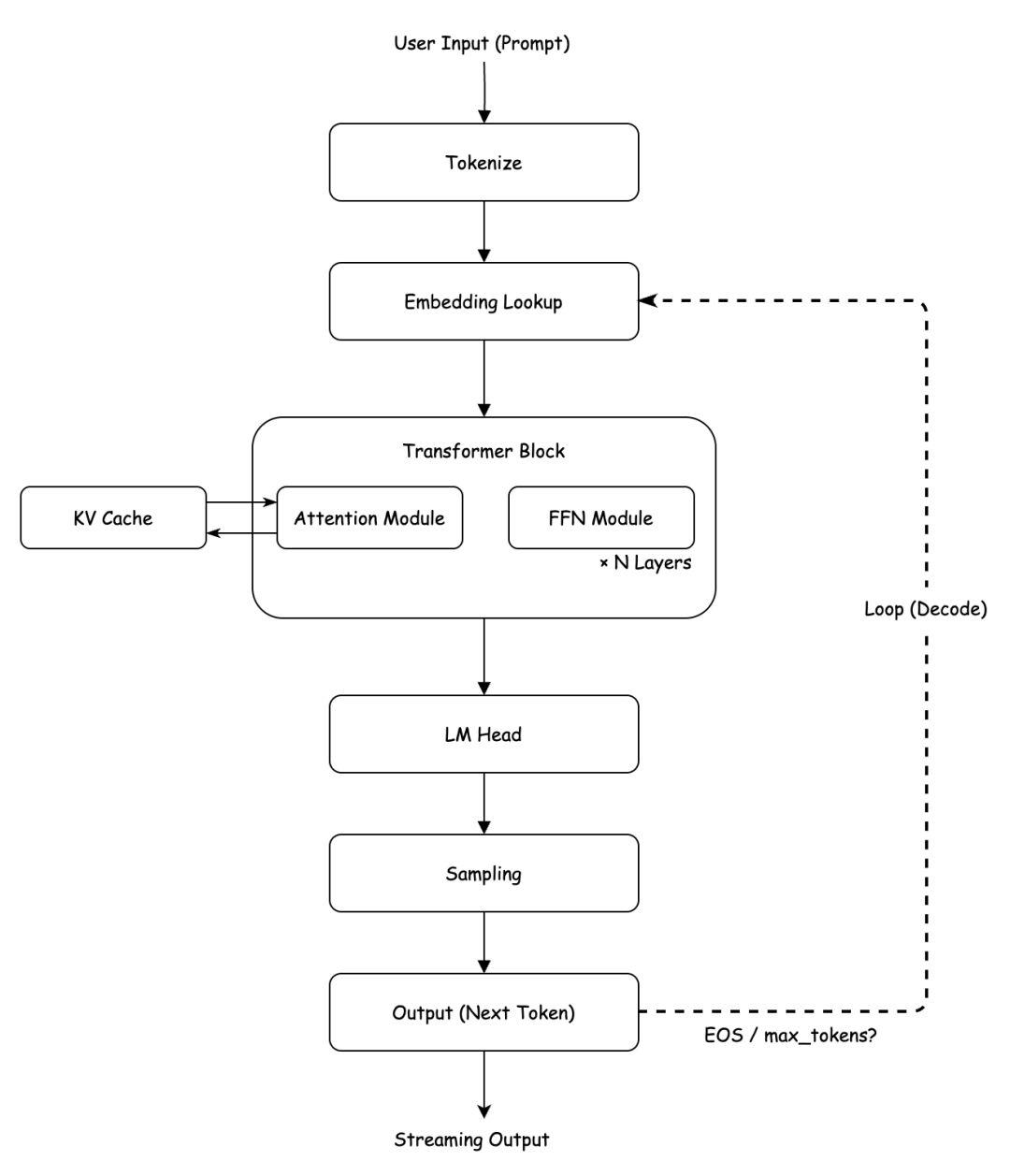
Tokenize
分词这一步,主要负责把用户输入的提示词,转换成模型认识的数字序列。当前主流的 LLM,几乎无一例外都采用 BPE(Byte Pair Encoding,字节对编码)。
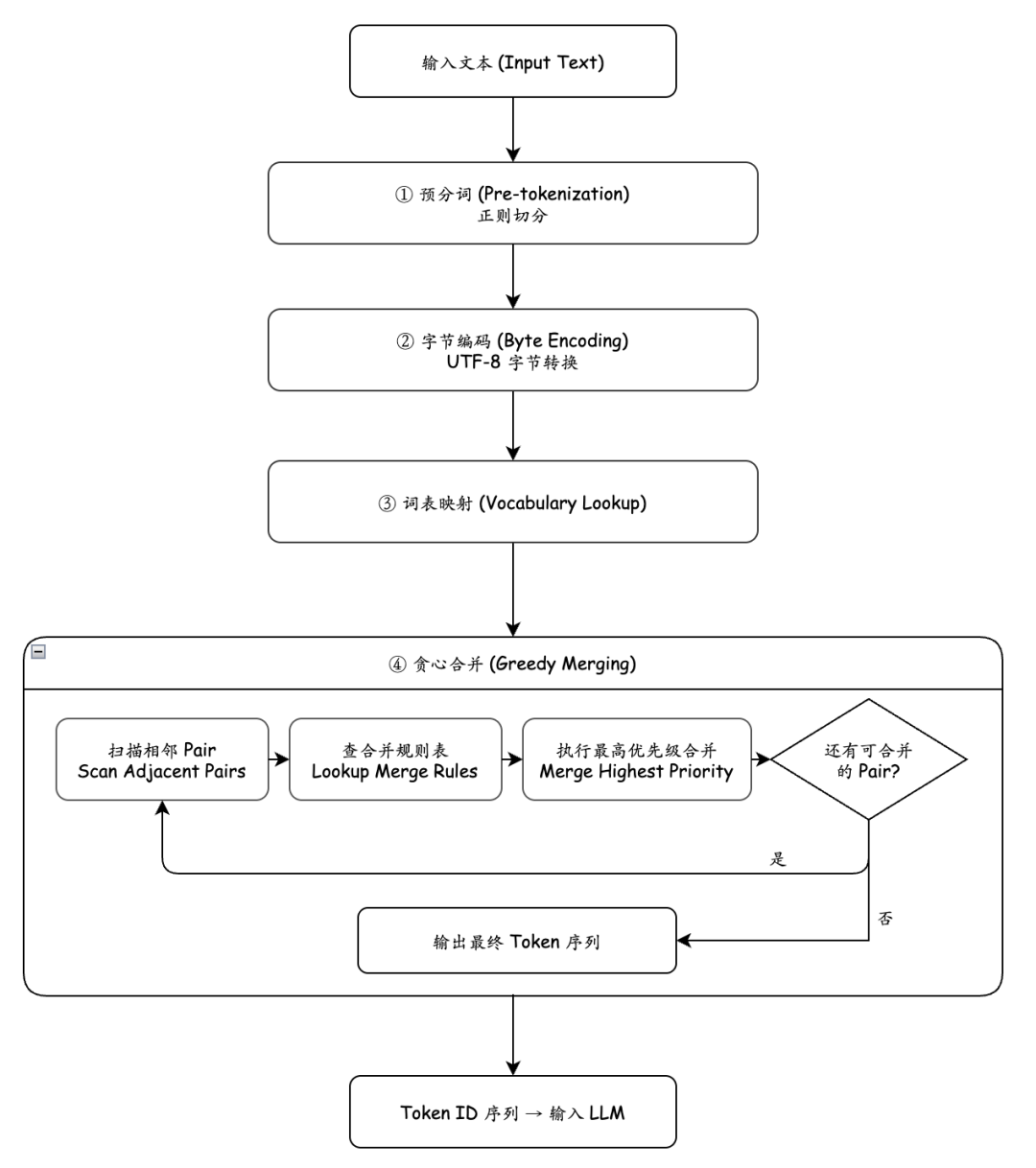
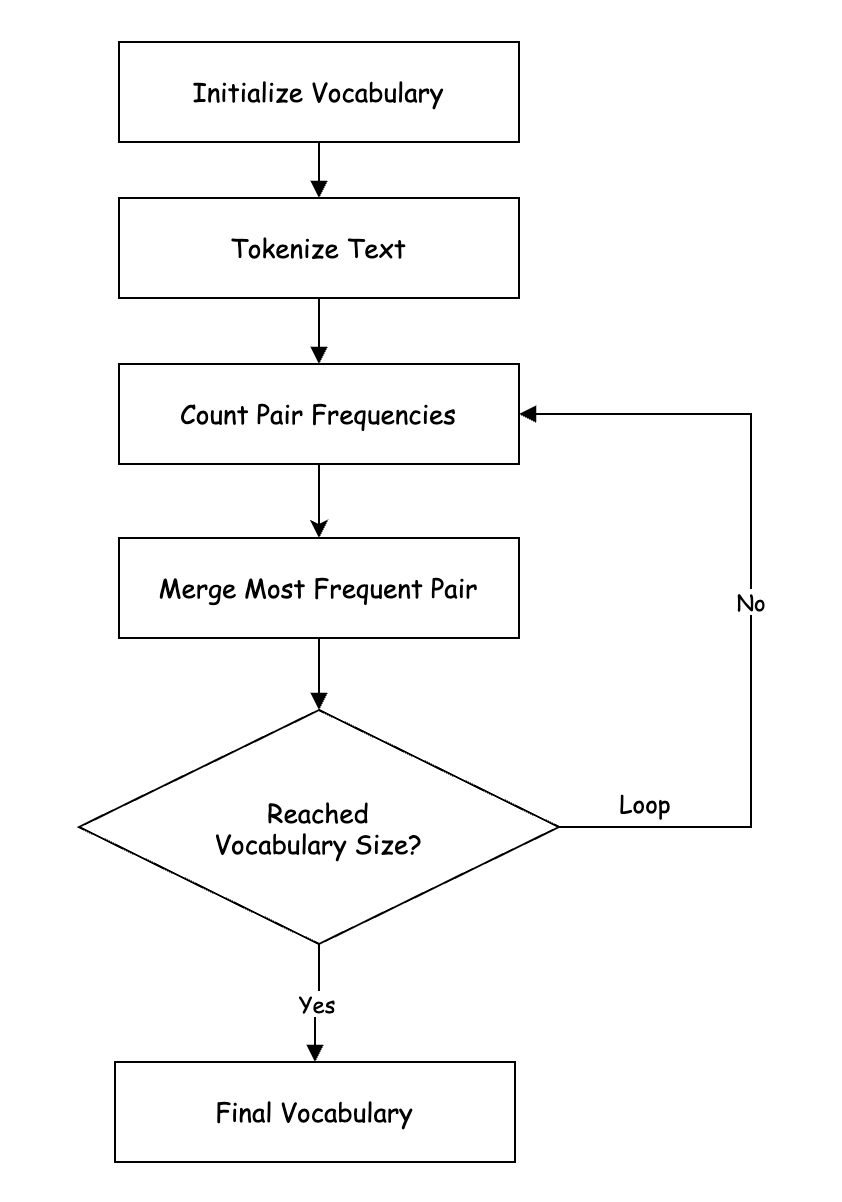
BPE 的词表训练方式如下:
Embedding Lookup
Embedding Lookup 在本质上就是个查表操作。它将一个一维的 Token ID 数组 [num_sched_tokens],转化为一个 [num_sched_tokens, hidden_size] 的特征矩阵,这才是真正意义上,进入大模型的第一份数学输入。
vLLM中的实现
| 目标矩阵 |
计算公式 |
输入维度 |
权重矩阵维度 |
输出结果维度 |
备注 |
| Embedding |
|
[num_sched_tokens] |
[V, hidden_size] |
[num_sched_tokens, hidden_size] |
Flattened 布局 |
将 Batch 里所有请求的有效 Token 拼接成一个一维的长向量,彻底消除了 Padding。
Attention Module (以标准GQA + RoPE为例)
RMSNorm
为了保证模型在神经网络计算中的数值稳定性,特征归一化机制是必不可少的。和传统的 LayerNorm 既要缩放又需平移不同,为了追求极致效率,现代大模型普遍采用 RMSNorm:它砍掉了平移操作,仅沿着特征维度对数据进行尺度缩放。这就能有效防止前向传播中的方差膨胀和硬件数值溢出,从而大大缓解反向传播时梯度异常(消失或爆炸)的问题,为深层网络的稳定训练打下基础。
| 目标矩阵 |
计算公式 |
输入维度 |
权重维度 |
输出结果维度 |
备注 |
| RMSNorm |
|
[num_sched_tokens, hidden_size] |
[hidden_size] |
[num_sched_tokens, hidden_size] |
是一维向量而非矩阵,做的是逐通道缩放而非 GEMM |
Q/K/V Linear Proj - Fused QKV
| 目标矩阵 |
计算公式 |
输入 X 维度 |
权重矩阵维度 |
输出结果维度 |
备注 |
| Fused QKV |
|
[num_sched_tokens, hidden_size] |
[hidden_size,qkv_proj_size] |
[num_sched_tokens, qkv_proj_size] |
权重按列拼接,执行单次宽矩阵 GEMM
4096 (Q) + 1024 (K) + 1024 (V) = 6144 |
Reshape & Cache
| 目标矩阵 |
Q, K, V Slice |
RoPE(维度不变) |
Multi-Head Reshape |
备注 |
| Query ($Q$) |
[num_sched_tokens, hidden_size] |
|
[num_sched_tokens,num_heads,head_dim] |
前 4096 列 |
| Key ($K$) |
[num_sched_tokens, kv_channels] |
|
[num_sched_tokens,num_kv_heads,head_dim] |
中间 1024 列 |
| Value ($V$) |
[num_sched_tokens, kv_channels] |
|
[num_sched_tokens,num_kv_heads,head_dim] |
最后 1024 列 |
注:$R$ 是一个块对角旋转矩阵,但在实际实现中,是通过元素级的 sin/cos 运算来完成的,避免了矩阵乘法。
这个阶段的大致流程是:QKV 按列拆分 -> 对 Q、K 进行 RoPE 计算 -> Q、K、V Reshape 成多头视角 -> 然后 reshape_and_cache 按照 slot_mapping 将数据 Scatter 写入 Paged KVCache 中。
RoPE 的核心思想,就是用旋转的角度来代表 Token 的位置。虽然 sin/cos 本身不是矩阵乘法,但作为超越函数,它们在 GPU 上是由 SM 内的特殊函数单元(SFU,Special Function Unit)来执行的。SFU 的吞吐量通常只有 FP32 ALU 的 1/4。所以,vLLM 并不会在 RoPE kernel 里实时计算 sin/cos,而是在引擎初始化时,就按模型配置预计算好 cos_sin_cache,它的形状是 [max_position_embeddings, rotary_dim]。等 RoPE kernel 运行时,直接按 positions 索引出对应的 cos/sin 行,跟 Q/K 做逐元素乘加就行了。这本质上是用一份小表(典型大小几 MB 到几十 MB)来换掉每次前向传播中几百万次的 sin/cos 调用——经典的空间换时间,或者说用访存来换算力。
Attention (FlashAttention, Scaled Dot-Product Attention)
这里,会读取请求对应的 KV Cache 进行 FlashAttention 计算。
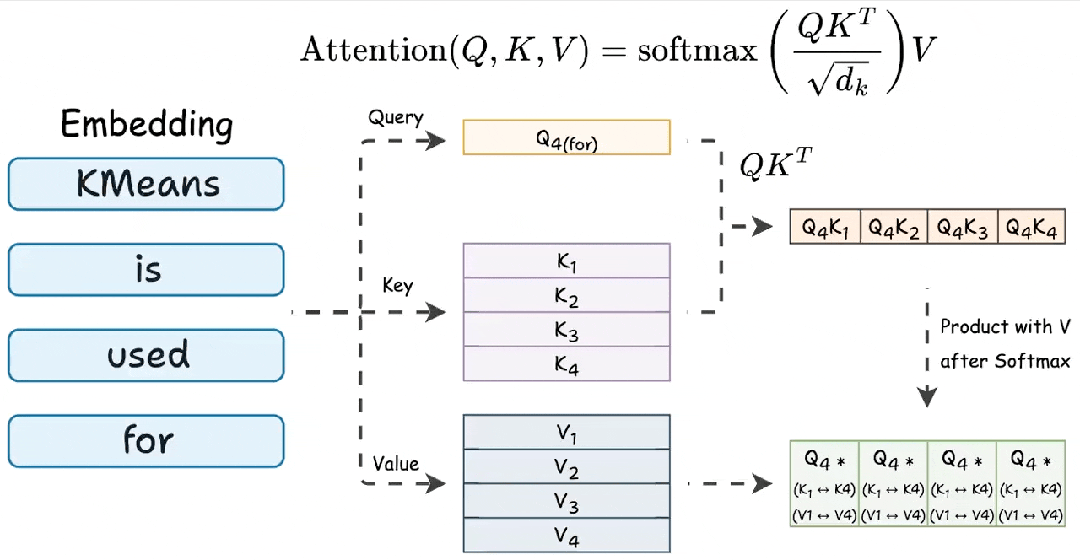
Softmax 的核心原理,可以一句话概括:把一组任意的实数(通常叫 Logits),转化为一套总和为 1 的概率分布,并在过程中放大数值间的差异。ps: 这里的 $d_k$ 就是 head_dim。
我觉得 Attention 的逻辑,是整个 LLM 推理里最复杂的地方了:
- Attention 的数学逻辑本身并不复杂,但为了提升计算强度、打破内存墙,业界在这里做了海量的优化,比如 FlashAttention;
- 推理的其他阶段,基本都是在 Token 维度上打平处理的,而 Attention 计算却必须在请求(request)维度上进行。
特别注意:在进入 Attention kernel 之前,需要从全局 Flattened 视角的 [num_sched_tokens, ...] 切换到请求维度的视角 [batch_size, ...]。这是因为 Attention 计算本质上是请求内部的运算,不同请求间的 KV Cache 绝不能交叉。vLLM/FlashAttention 通过 cu_seqlens(累积序列长度)数组来实现这种变长序列的请求级隔离,并不需要真的把张量 Reshape 成 [batch_size, ...] 这种规整格式。这里的 K 和 V 算子在逻辑上,形状是 [batch_size, num_kv_heads, seq_len, head_dim],而不同请求的 seq_len 肯定不一样。实际上,在 CUDA 算子层面就已经确保了,不同请求不会被分到同一个 thread block 里去,也就是说,这里的计算是请求维度隔离的。
K 的形状是 [seq_lens, num_kv_heads, head_dim],包含了当前请求所有历史的 KCache。seq_lens 是所有历史 KV 对应的 Token 长度,但物理上,由于 Paged Attention 机制,这些历史的 K Cache 并非连续存储,而是离散分布在 HBM 的物理块中(底层的实际形状是 [num_blocks, block_size, num_kv_heads, head_dim])。Kernel 在执行时,会通过 block_table 动态间接寻址,在片上 SRAM 里把它们“拼凑”成逻辑上连续的序列,再参与计算。
V 的形状是 [seq_lens, num_kv_heads, head_dim],包含了当前请求所有历史的 VCache。
Q 的形状是 [query_lens, num_heads, head_dim],query_lens 是本次 Q 对应的 Token 长度。
| 操作名称 |
数学公式 |
逻辑说明 / 目的 |
| GQA分组共享 |
1 KV Head 映射给 4 Q Head |
把KV的形状从 [seq_lens, num_kv_heads, head_dim] 变为 [seq_lens, num_heads, head_dim]
逻辑上等价于将1个KV Head的数据广播给4个Q Head;物理实现中会通过索引映射 kv_head_idx = q_head_idx // (num_heads // num_kv_heads) 来避免显存复制。 |
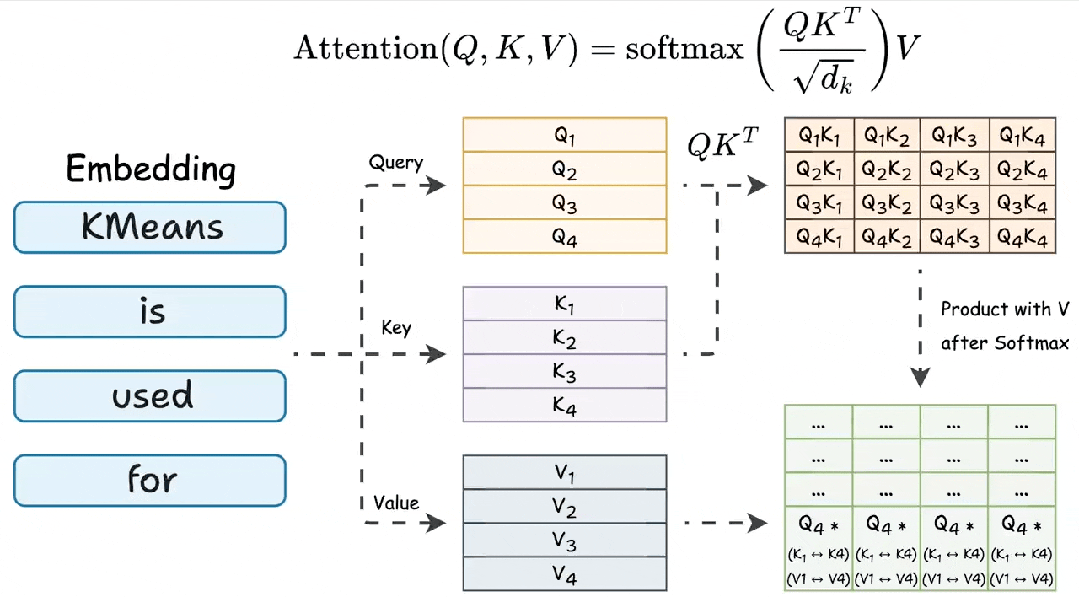
| Q-K Dot Product |
$S = QK^T$ |
查询Query和该请求所有Key的点积,得到注意力原始分数。-> [query_lens, num_heads, seq_lens] |
| Scale |
$\frac{S}{\sqrt{d_k}}$ |
对原始分数进行数值缩放($d_k$ 为向量维度),防止 Softmax 函数进入梯度极小的区域。 |
| Mask |
$S + M$ |
注入因果逻辑,通过加上掩码矩阵 $M$(通常将未来位置设为 $-\infty$),阻止模型“看到”未来的信息。 |
| Softmax |
$P = softmax(S)$ |
将处理后的分数转化为总和为 1 的注意力权重(概率)。-> [query_lens, num_heads, seq_lens] |
| MatMul |
$O = PV$ |
根据注意力权重 $P$ 对值向量(Value)进行加权求和,得到最终的输出特征表示。
V的形状为 [seq_lens, num_heads, head_dim] -> [query_lens, num_heads, head_dim] |
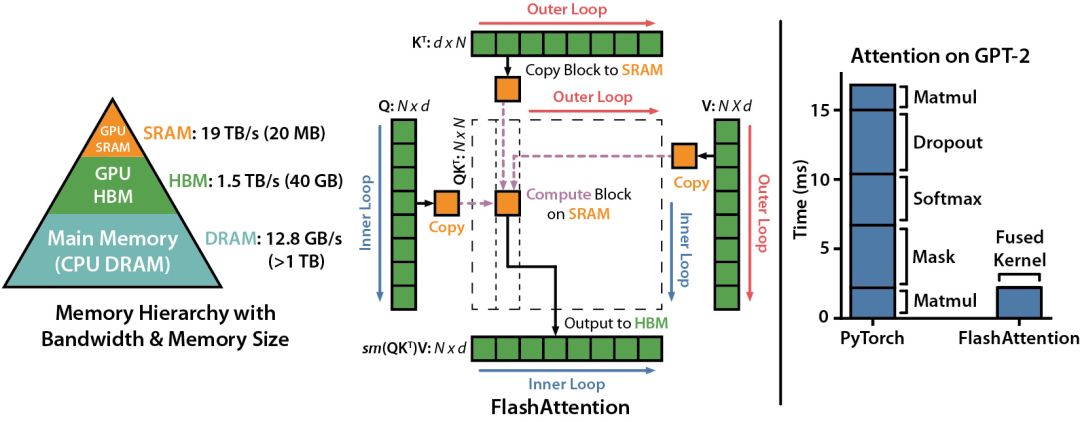
Attention 的数学逻辑非常清晰,但在大模型推理(尤其是长文本 Prefill 阶段)中,如果严格按照数学公式分步执行,会在 GPU 的 HBM(全局显存)中产生庞大的中间矩阵 $S$(注意力分数)和 $P$(Softmax 概率),其 $O(N^2)$ 的内存访问量会严重影响性能,这就是所谓的“内存墙”问题。
为了打破这个瓶颈,vLLM 默认采用 FlashAttention 及其变体(如 Flash-Decoding)。FlashAttention 的核心思想是 Kernel 融合 (Kernel Fusion) 与分块计算 (Tiling)。但分块计算面临一个致命的数学障碍:Softmax 操作需要知道全局的最大值和指数和才能计算,这通常要求完整的中间矩阵驻留在显存中。FlashAttention 巧妙地引入了Online Softmax算法,通过维护局部的当前最大值(Running Max)和当前指数和(Running Sum),并在读入新块时利用动态缩放因子(Rescaling Factor)对旧结果进行修正。
正是凭借 Online Softmax,FlashAttention 成功解除了全局数据依赖,将从 Q-K 点积、Softmax 到乘 V 的整个逻辑步骤,融合成了一个单一的 CUDA Kernel。在物理执行上,它一块一块地在 SRAM 中完成计算,彻底避免了将庞大的中间矩阵 $S$ 和 $P$ 读写 HBM,从而大幅打破了内存墙限制。
在 Prefill 阶段,seq_lens 和 query_lens 都是 num_prompt_tokens。当前 Prompt 计算出的 KV 向量,会先被 reshape_and_cache_flash 按照 slot_mapping 写入 Paged KV Cache,随后 Attention kernel 通过 block_table 从 Cache 中读取 K/V,来完成本层的 Attention 计算。这份写入,同时也作为该序列的 KV Cache,供后续 decode 步骤复用。
vLLM v0 中,prefill 和 decode 走的是两条独立分支:prefill 通过 attn_metadata.is_prompt == True 调用 flash_attn_varlen_func,kernel 直接读临时的、物理上连续的 HBM buffer 里的 K/V,不读 cache;decode 则走 paged_attention_v1/v2,K/V 全部从 cache 读。v1 把这两路统一成一次 flash_attn_varlen_func 调用,K/V 全部走 paged cache + block_table,代价是 prefill 多了一次“写 cache → 读 cache”的间接寻址,换来了对 prefix cache / chunked prefill 的天然支持。
只有 v0 版本的 FlashAttention 不读 KV Cache,因为 v0 没有 prefix cache / chunked prefill。
在 V1 版本中,即便某些 backend(如 FlashInfer、MLA-sparse)把混合 batch 物理拆分成 prefill / decode 两个独立的 kernel 调用,prefill 也仍然会从 paged cache 读 K/V——因为 v1 需要支持 prefix cache 和 chunked prefill。
到了 Decode 阶段,seq_lens 是已计算的历史 token 总数,而 query_lens 则固定为 1。
对比一下 Prefill 和 Decode,可以发现:
- Prefill阶段:QKV_Proj、Attention、O_Proj、MLP,这些操作本质上都是稠密矩阵乘法(GEMM)。其实就是通过请求内 token 级的计算来复用模型权重,所以算术强度极高。这使得 GPU 在 Prefill 阶段主要受限于 Tensor Cores 的物理算力峰值,属于计算密集型。
- Decode阶段:由于自回归的特性,每次只处理一个 Token(
query_lens = 1)。如果没有优化,此时 QKV_Proj、Attention、O_Proj、MLP 全会退化成矩阵向量乘法(GEMV)。虽然计算量不大,但需要把巨大的 KV Cache 和模型权重从 HBM 搬运到 SRAM,非常吃显存带宽,因此 Decode 阶段是典型的访存密集型。
而 Continuous Batching 的价值在于,它在 Prefill 实现请求内复用模型权重的基础上,进一步通过 token 级调度让多个请求也能复用模型权重,将 QKV_Proj、O_Proj、MLP 重新变回矩阵乘法,极大地摊薄了读取权重的显存开销。
但 Attention 就比较特殊了,由于每个请求必须读取自己独占的 KV Cache(无法跨请求共享),而且 Decode 每步只处理一个 Token,Attention 计算始终无法均摊访存开销。此外,由于当前 Query 必须与所有历史 Key/Value 交互,哪怕有 KVCache 的存在,其计算与访存量也会随着上下文长度 $O(N)$ 呈线性膨胀。这里要特别提一下,其实 Prefill 阶段每次处理 num_prompt_tokens 个 Token,Attention 计算是完全可以均摊访存开销的。
ps: 所以,我们日常所说的 Prefill 是 Compute-bound,Decode 是 Memory-bound,主要是基于两点:1. 从 HBM 读取模型权重的访存摊销;2. 从 HBM 读取模型 KV 的访存摊销。
Multi-Head Concatenation
| 操作名称 |
逻辑说明 |
vLLM 输入维度 |
输出结果维度 |
备注 |
| Concat / Flatten |
消除多头维度,恢复隐藏层维度 |
[num_sched_tokens, num_heads, head_dim] |
[num_sched_tokens, hidden_size] |
物理内存通常已连续,本质是改变Tensor View。 (hidden_size = num_heads * head_dim) |
O_Proj - 线性融合
| 目标矩阵 |
计算公式 |
输入维度 |
权重矩阵维度 |
输出结果维度 |
备注 |
| O_Proj |
$y = xW$ |
[num_sched_tokens, hidden_size] |
[hidden_size, hidden_size] |
[num_sched_tokens, hidden_size] |
跨 Head 的信息交互与融合。一次标准的稠密矩阵乘法(GEMM / GEMV)。 |
Residual Connection
不要总想着推翻重来,而是学着在原有的基础上学习“修正值”(Delta)。如果没有 ResNet 证明网络可以堆到 100 层以上还不会梯度消失,后来的 BERT (24层) 和 GPT (96层+) 是绝不敢设计得那么深的。它是“Scaling Law”在架构上的物理基础。
| 目标矩阵 |
计算公式 |
输入维度 |
输入维度 |
输出结果维度 |
备注 |
| Residual Add |
$x = x_{attn\_in} + O_{proj}$ |
[num_sched_tokens, hidden_size] |
[num_sched_tokens, hidden_size] |
[num_sched_tokens, hidden_size] |
$x_{attn\_in}$ 是进入这一层 RMSNorm 之前的原始输入。将注意力机制提取的新特征“加回”主干数据流中。 |
实际上,在 vLLM 里,Residual Add 会和下一步的 RMSNorm 融合成一个 CUDA kernel 来执行。
FFN
RMSNorm
对 $x_{attn\_out}$ 再进行一次归一化。在 vLLM 中,这通常已经和上一层的残差相加(Residual Add)融合在一起了,主要就是为了减少对 HBM 的读写。
Gate_Proj & Up_Proj
通常,intermediate_size 是 hidden_size 的大约 4 倍 (或是 8/3 倍)。
| 目标矩阵 |
计算公式 |
输入 X 维度 |
权重 W 维度 |
输出维度 |
| Gate Proj |
$H_{gate} = xW_{gate}$ |
[num_sched_tokens, hidden_size] |
[hidden_size, intermediate_size] |
[num_sched_tokens, intermediate_size] |
| Up Proj |
$H_{up} = xW_{up}$ |
[num_sched_tokens, hidden_size] |
[hidden_size, intermediate_size] |
[num_sched_tokens, intermediate_size] |
vLLM 工程实现(Fused Gate/Up)
为了减少 GPU 核函数启动的次数,并充分利用内存带宽,vLLM 在加载模型时,就已经把 $W_{gate}$ 和 $W_{up}$ 按列拼接好了。这样一来,原本两次中等规模的矩阵乘法,就变成了一次宽矩阵 GEMM。
| 目标矩阵 |
计算公式 |
输入 X 维度 |
权重 $W_{gate\_up}$ 维度 |
输出维度 |
| Fused Gate/Up |
$[H_{gate}, H_{up}] = x [W_{gate}, W_{up}]$ |
[num_sched_tokens, hidden_size] |
[hidden_size, 2*intermediate_size] |
[num_sched_tokens, 2*intermediate_size] |
Activation
SiLU(Gate) * Up。vLLM 使用 silu_and_mul kernel 在片上(SRAM)直接输出点乘的结果,这极大节省了显存带宽。
| 操作名称 |
数学公式 |
物理实现说明 |
| Slice & Act |
$H_{act} = SiLU(H_{gate}) \odot H_{up}$ |
$H_{gate}$ 为 $H_{fused}$ 前一半,$H_{up}$ 为后一半。 |
Down_Proj
| 目标矩阵 |
计算公式 |
输入维度 |
权重维度 |
输出结果维度 |
| Down Proj |
$y = xW_{down}$ |
[num_sched_tokens, intermediate_size] |
[intermediate_size, hidden_size] |
[num_sched_tokens, hidden_size] |
Residual Connection
x = x + FFN_Output
class LlamaMLP(nn.Module):
def __init__(self, config):
super().__init__()
# 通常 intermediate_size 是 hidden_size 的 4 倍左右 (或 8/3 倍)
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
self.act_fn = nn.SiLU()
def forward(self, x):
# 1. Gate 和 Up 分别进行 Linear 变换
# 2. Gate 经过 SiLU 激活
# 3. 两者相乘 (Element-wise multiplication) -> 这就是 GLU (Gated Linear Unit)
# 4. 最后经过 Down 投影回原维度
return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
LM Head
这一步,会把隐藏层的特征映射到整个词表空间,输出未经归一化的原始得分,也就是Logits。
在前面的 Transformer Block 中,Prefill 阶段的 num_sched_tokens 是所有 Prompt 长度的总和。但实际上,vLLM 的 LM Head 只需要每个请求序列的最后一个 Token 的特征来预测下一个词。所以,在进入 LM Head 前,会执行一次 Gather 操作。(Speculative Decoding、prompt_logprobs 除外)
更进一步说,Prefill 阶段 Transformer Block 的最后一层,Attention 的输出是整个 [num_sched_tokens, hidden_dim],但实际上只需要最后一个 token 的 hidden_state 来做 logits 计算(因为之后没有更多的 layer 需要完整的 hidden_states 了)。所以理论上,最后一层的 MLP(以及 LayerNorm)可以只对需要采样的 token 进行,节省大量计算。
如果只需要最后一个 token 的生成结果,那么在最后一层(Last Layer):
- 必须要算的部分:所有 token 的 $Q_{proj}$ 和 $O_{proj}$(因为这层的 KV cache 要存下来,供后续 Decode 阶段使用)。
- 理论上可以只算最后一个 token:$Q_{proj}$ 的投影、Attention 的计算(其实退化成了 Decode 阶段的 Flash-Decoding 计算)、LayerNorm、以及庞大的 MLP。
但是,vLLM 中最后一层还是老老实实地把所有 query_lens 都算了一遍,这本质上是工程与物理极限的 Trade-off。
RMSNorm
最后再来一次归一化,防止数值过大。
Linear (LM Head)
| 目标矩阵 |
计算公式 |
输入维度 |
权重矩阵维度 |
输出结果维度 |
备注 |
| LM Head |
$logits = xW_{lm}$ |
[num_reqs, hidden_size] |
[hidden_size, vocab_size] |
[num_reqs, vocab_size] |
num_reqs 即当前 Batch 中的请求数量。
以 Llama-3-8B 为例,vocab_size 高达 128256,这是一个极其庞大的矩阵,vLLM 通常会使用张量并行(TP)按列切分该权重以加速计算。 |
Sampling
保存原始 Logprobs
如果用户请求了 logprobs(对数概率),Sampler 会在进行任何处理之前,先对原始 logits 做一次 log_softmax 快照保存下来。这样返回给用户的概率分布,反映的就是模型的真实输出,不会受到后续 penalties / temperature 等采样参数的干扰。
{
"token": "Hello", // 实际被选中的 token
"logprob": -0.01523, // 该 token 的对数概率 (log_softmax 的结果)
"bytes": [72, 101, ...], // token 的 UTF-8 字节表示
"top_logprobs": [ // 概率最高的前 N 个 token (用户通过 logprobs=N 指定)
{
"token": "Hello",
"logprob": -0.01523 // ln(0.985) ≈ -0.015, 即 98.5% 概率
},
{
"token": "Hi",
"logprob": -4.32185 // ln(0.013) ≈ -4.32, 即 1.3% 概率
}
]
}
Logits Process
在得到原始 Logits 之后、进行 Softmax 概率转化之前,会经过一系列后处理,来干预最终的生成结果:
- 白名单过滤
- 结构化输出(JSON schema):配合 grammar bitmask,每一步动态计算当前合法的 token 集合。
- 情感分类:只允许输出
"positive" / "negative" / "neutral" 对应的 token。
- 多选题:只允许输出
A B C D。
- 黑名单过滤
- Non-argmax-invariant Logit Processors
- Repetition Penalty (重复惩罚): 根据历史 Token,对已生成过的词汇扣除分数,防止模型变成“复读机”。
采样
每个请求的采样策略可以是 Greedy 或 Random,这由用户设置的 temperature 决定。
@cached_property
def sampling_type(self) -> SamplingType:
if self.temperature < 1e-5: # < 0.00001 就是 greedy
return SamplingType.GREEDY
return SamplingType.RANDOM
-
Greedy 先行:在 temperature 缩放之前,先对当前 logits 执行一次 argmax,保存为 greedy_sampled。
- 如果整个 batch 全是 greedy(所有请求的 $T \approx 0$),到这里就直接返回,后续步骤全部跳过。
- 这一步必须在 temperature 之前做,否则 greedy 请求的 logits 会被不必要地除以 temperature 导致精度损失。
-
Temperature Scaling:Logits = Logits / Temperature。
$T \in (0, 1)$: 拉大分数差距。高分越明显,低分被压得更低。模型变得保守、确定。
$T > 1$: 缩小分数差距。分布趋向均匀。模型变得随机、有创造力(但也更容易胡说八道)。
对于 $T \approx 0$ 的 greedy 请求,此处会用 T=1.0 跳过除法(避免除零),它们的最终结果由 Step 1 的 greedy_sampled 决定。
-
Argmax-invariant Processors(如 min_p):
min_p 是目前唯一的 argmax-invariant 处理器。它的规则是:概率不到 token 最高概率的 min_p 倍的 token,全部淘汰。公式里的阈值 = $p_{max} \times \text{min\_p}$,低于阈值的 token 得分会被设为 -inf。
示例(min_p = 0.1,$p_{max} = 0.4$,阈值 = 0.04):

minp 的核心价值在于自适应:
最高概率的 token 自身永远不会被砍(因为 $p{max} \ge p_{max} \times 0.1$),所以 argmax 结果不变。
- 模型很确定时($p_{max} = 0.9$):阈值 = 0.09,砍得多,几乎只剩最优解。
- 模型不确定时($p_{max} = 0.08$):阈值 = 0.008,砍得少,保留充分的探索空间。
-
Top-K 截断:只保留分数最高的 $K$ 个 Token,其余得分全部设为 $-\infty$。
-
Top-P Masking:按分数从高到低排序并累加 softmax 概率,保留累积概率刚好超过 $P$ 的前若干 Token,尾部 Token 得分设为 $-\infty$。
-
Softmax + Gumbel-Max 采样 确保结果的随机性。Gumbel-Max 用加噪求最大值的方法,替代了传统的轮盘赌算法。它将原本需要串行计算前缀和的采样过程,转变为完全独立的 element-wise 并行运算,打破了超大词表下的全局数据依赖。
probs = logits.softmax(dim=-1)
q.exponential_()
probs.div_(q).argmax(dim=-1)
-
最终选择:逐请求按 temperature 决定使用哪个结果
final = where(temperature < 1e-5,
greedy_sampled, # 该请求用贪心结果
random_sampled) # 该请求用随机结果
output 得到 Next Token ID,并将其追加到 Input 序列中,进入下一轮循环。
总结
是的,戛然而止。本文主要梳理了经典的大模型推理全流程,想要真正理解,追踪 shape 的变化真的很重要。我有意收住了发散的思绪,专注于整个推理流程,很多原理和概念都没有展开。后续可以围绕这个基础框架继续深入,比如:
- 数学基础:Softmax、RMSNorm 的原理、RoPE
- Attention计算遇到的内存墙问题
- 这催生了 DeepSeek MLA/DSA、线性注意力等,本质是减少 KVCache 的读取;
- 也催生了 FlashAttention,本质是利用 IO Aware、重计算来提升计算强度;
- 为什么要 MoE:沿着 Scaling Law,模型不断增大,计算量随参数线性增大,而参数占比的大头又在 MLP 层,那就把 MLP 层拆分,美其名曰不同专家,每次执行仅激活部分参数。其本质就是将现有 FFN 层拆分成多个,然后增加路由,每次可以激活不同的专家组。
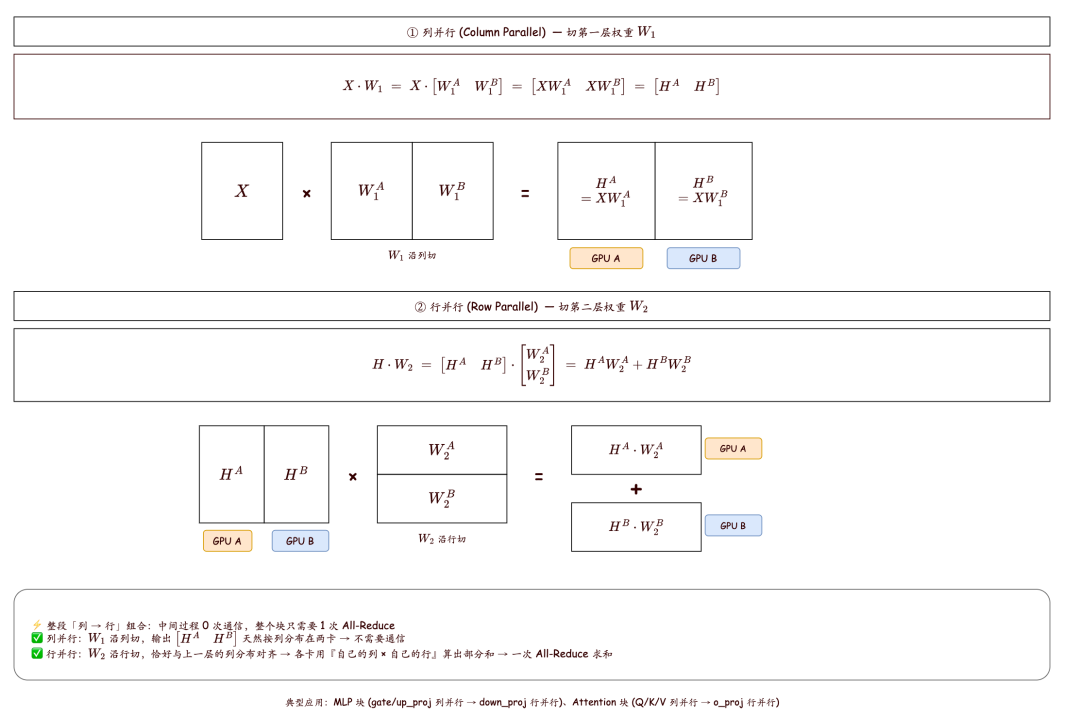
- 模型太大了:TP、PP、DP、EP、SP、CP。了解了本文的数据流 shape 变化,TP 的理解就会变得相当容易。
- Column Parallelism (列切分): Fused QKV 和 FFN 的 Fused Gate/Up 都是列切分。例如 QKV 的权重维度在单卡上会变成
[hidden_size, qkv_proj_size / TP_size],输出也相应变成 [num_sched_tokens, qkv_proj_size / TP_size]。
- Row Parallelism (行切分): O_Proj 和 FFN 的 Down_Proj 是行切分。权重变为
[hidden_size / TP_size, hidden_size]。计算完成后,通过 AllReduce 算子来聚合跨卡结果。
- 长上下文时:从 chunked prefill 到 Flash-Decoding 再到 SP,本质是不同维度的 prompt 拆分,不过是在解决不同的问题。chunked prefill 避免超长 Prompt 的新请求影响其他请求,无论是正在处理的 decode 请求还是待处理的其他 prefill 请求;Flash-Decoding 则通过 KV 维度的切块(Split-K)提升了 Decode 阶段的 SM(流处理器)利用率;SP (Sequence Parallelism) 则是解决单卡显存塞不下超长上下文的问题。(Flash-Decoding,Sequence Parallelism 靠 Log-Sum-Exp 实现跨 SM 或者跨卡的归一化)
再来感叹一句,单从推理来看,大模型的原理其实真没那么高深莫测,最难的数学公式怕是要数 RoPE 了。可 AI Infra 的东西是真多,根本学不完,不像 Agent 方向整天重命名上下文工程。(什么提示词工程、function calling、rag、mcp、memory、agent 开发、skills、openclaw、上下文工程、harness 工程、hermes……)
附1:模型配置参数
| 标准变量名 |
数值 (Llama-3-8B) |
物理含义说明 |
| hidden_size |
4096 |
隐藏层总维度,也是 Q 向量的总宽度。 |
| num_heads/num_q_heads |
32 |
Query 的头数。决定了注意力机制的并行度。 |
| num_kv_heads |
8 |
Key/Value 的头数。GQA 架构中用于压缩缓存。 |
| head_dim/head_size |
128 |
单个头的维度。公式 $S = \frac{QK^T}{\sqrt{d_k}}$ 中的 $d_k$。 |
| kv_channels/kv_dim |
1024 |
单侧(K 或 V)矩阵的总宽度 (num_kv_heads*head_dim)。 |
| qkv_proj_size |
6144 |
Fused QKV 层的输出总宽度 (hidden_size + kv_channels*2)。 |
| intermediate_size |
14336 |
FFN 内部升维后的维度(通常为 $\frac{8}{3} \times \text{hidden\_size}$)。 |
| fused_ffn_size/gate_up_proj_size |
28672 |
Fused Gate/Up 层的输出总宽度 (intermediate_size*2)。 |
| vocab_size |
128256 |
词表大小。决定了 LM Head 的输出矩阵尺寸。 |
| num_hidden_layers |
32 |
Transformer Block 的层数。 |
| rope_theta |
500000.0 |
RoPE 旋转位置编码的 base theta 值。 |
附2:推理运行时变量
| 标准变量名 |
数值 (Llama-3-8B) |
物理含义说明 |
| num_prompt_tokens |
100 |
prompt 长度 |
| num_tokens |
105 |
prompt + 已生成 output |
| num_computed_tokens |
105 |
已计算的历史 token 总数 |
| num_sched_tokens |
1 |
本次要计算 1 个新 token(decode),其实就是flatten的query_lens |
| seq_lens |
106 |
KV Cache 总长度 = 105 + 1 |
| query_lens |
1 |
本次 Q 的长度 |
附3:模型权重组成
LLM 是多层的,以 Llama3 8B 为例,模型的权重组成如下:
| 组件 |
权重名称 |
参数量维度 |
占比 |
本质与说明 |
| Embedding |
embed_tokens.weight |
[128256, 4096] |
~6.5% |
查表矩阵 |
| Attention |
q_proj |
[4096, 4096] (×32层) |
~15.9% |
4 个 Linear 矩阵,无 bias。由于 GQA,K/V 矩阵比 Q 小很多。 |
|
k_proj, v_proj |
[1024, 4096] (×32层) |
|
|
|
o_proj |
[4096, 4096] (×32层) |
|
|
| MLP |
gate_proj, up_proj |
[14336, 4096] (×32层) |
~70.1% |
3 个 Linear 矩阵,无 bias,SwiGLU 激活。这是模型计算和参数量的绝对大头。 |
|
down_proj |
[4096, 14336] (×32层) |
|
|
| Input Norm |
input_layernorm.weight |
[4096] (×32层) |
< 0.01% |
RMSNorm 缩放一维向量。 |
| Post-Attn Norm |
post_attention_layernorm.weight |
[4096] (×32层) |
< 0.01% |
RMSNorm 缩放一维向量。 |
| Final Norm |
norm.weight |
[4096] (×1) |
< 0.01% |
最终进入 LM Head 前的 RMSNorm 向量。 |
| LM Head |
lm_head.weight |
[128256, 4096] |
~6.5% |
与 Embedding 维度一致,但独立存在不共享。 |
- MLP 层:参数占比 70%,FLOPs 占比也约 70%,是绝对的计算大头。
- Attention 层:参数占比仅 16%,但由于需要读取动态生长的 KV Cache,它是访存带宽的绝对大头。
附4:vLLM调度详细流程
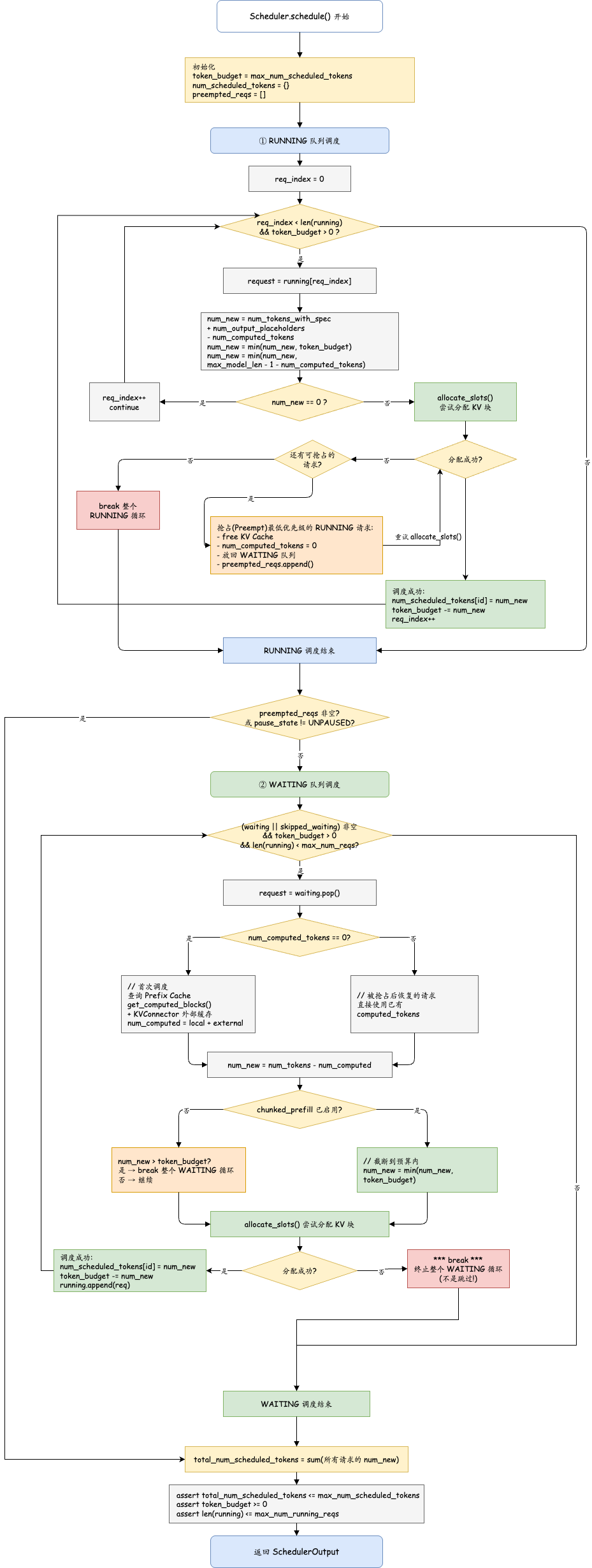
抢占(Preemption)
当 KV Cache blocks 不够分配时,调度器会抢占最低优先级的 RUNNING 请求——释放其全部 KV Cache、将 num_computed_tokens 重置为 0、放回 WAITING 队列。被抢占的请求,下次被调度时需要重新从头 Prefill。
v0 时代,vLLM 有两种 preemption 策略:
- SWAP:把被抢占请求的 KV blocks 从 GPU HBM 搬到 host RAM 暂存,资源宽裕时再 swap in 回 GPU。
- RECOMPUTE:直接释放 GPU blocks,重新加入 waiting 队列走 prefill 重算一遍。
v1 已经把 SWAP 路径完全砍掉(LLM(swap_space=...) 已废弃并 warn),Scheduler._preempt_request 只保留 RECOMPUTE 这一条路。原因是:
- PCIe 双向搬运 + host RAM 占用的开销,在 FA + 大 batch 下常常比重算一次 prefill 还贵
- chunked prefill 让重算可以分多步“追上来”,摊平开销
- 架构上少一条路径,prefix caching / chunked prefill /continuous batching 的交互更干净
def _preempt_request(self, request, ...):
self.kv_cache_manager.free(request) # 释放 KV Cache
request.status = RequestStatus.PREEMPTED
request.num_computed_tokens = 0 # 重置,下次需要重新计算
self.waiting.prepend_request(request) # 放回等待队列
为什么 RUNNING 阶段分配失败会抢占,而 WAITING 阶段直接终止?
这体现了调度器的核心原则:已在运行的请求优先级高于等待中的请求。
- RUNNING 请求:已经占用了 KV Cache、消耗了计算资源。如果因为内存不足无法继续,调度器会牺牲优先级最低的 RUNNING 请求(释放其 KV Cache)来保证其他请求能继续推进。这是值得的,因为放弃一个已运行的请求代价很高。
- WAITING 请求:还没开始计算,没有沉没成本。如果内存不足,直接停止调度即可,下一个 step 再尝试。
为什么抢占后跳过 WAITING 调度?
发生抢占意味着 KV Cache 已经非常紧张。此时不应该再引入新的 WAITING 请求,因为那会进一步加剧内存压力,可能触发更多抢占,形成恶性循环。
Reference
 发表于 2026-5-26 02:39:45
|
查看: 100|
回复: 0
发表于 2026-5-26 02:39:45
|
查看: 100|
回复: 0
