早在2024年,便有学者(https://arxiv.org/abs/2406.11717)发现LLMs的拒绝回答往往由单一梯度方向介导。
作为一篇社区博客,本文将谈论如何让Qwen3-4B-Instruct-2507 拒绝回答 所有问题,而不是如何让它回答所有问题,无论合法与否,以避免不必要的负面影响(拒绝回答一个问题几乎总是没有负面影响的)。请勿恶意修改梯度方向,避免模型输出不恰当的内容。
模型的结构
在开始分析拒绝向量的内容前,我们必须先明确拒绝向量的位置。
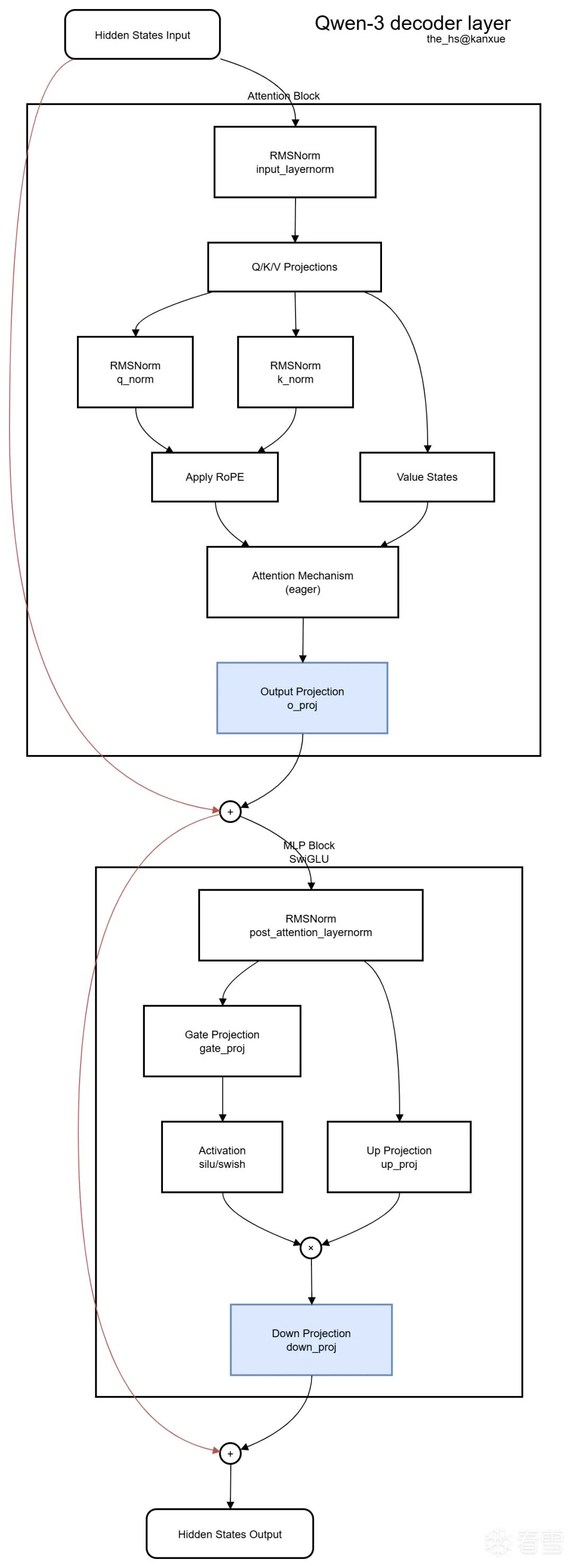
Qwen3-4B-Instruct-2507的模型架构相对简单,主体(去掉嵌入等)由36层Qwen-3 decoder layer组成;每个Decoder layer的结构都由一个注意力块(Attention Block)和一个MLP块组成,总体如上图所示。其中,红线代表残差(Residual),蓝块为最后的权重块。
那么,在此即可讨论可行的干预点。首先,对于此模型而言,干预注意力是 几乎不可行 的,原因有二:
其一,模型采用了块间残差而非层间残差。这意味着残差流对MLP产生的影响增强了:传统的MLP块的输入为注意力的输出,意味着MLP看不到没有被注意到的内容;因此只要让MLP看不到内容的应拒绝性,MLP就无从产生拒绝的意向。但是在这里,MLP可以绕过注意力机制看到输入隐状态(Input Hidden States)的残差,导致哪怕干预了注意力,MLP也会产生拒绝方向。
其二,其MLP块本身也类似于朴素注意力。虽然经过了激活而不是softmax,门投影仍然可以被视为某种意义上的注意力;至少它也会产生类似于Gate的效果。因此,其内部权重也不会完全依赖传统注意力。
类似地,会有两种可行的编辑思路。其中一种是干预残差;最著名的使用者为(huihui_ai);另一种思路为利用对块的补偿;最著名的使用者为(p-e-w)。这里,我们为了修订后的模型可以被转为gguf等,选择第二种思路。除此之外,与heretic不同,为了更完整地展示LoRA的原理,我们不使用peft库,而是直接计算r=1时LoRA的每个权重并进行合并。
这不是规范操作,但是我认为这样对展示方法有帮助。我们将从输出状态叠加残差前,也就是第二个块的下投影的输出中(图中蓝色的Down Projection块)分析拒绝向量并进行编辑;亦因此,我们将其定义为拒绝向量的位置。
梯度的拆分
在确定了拒绝向量的位置后,我们需要开始观测拒绝向量的方向。利用pytorch的hook机制,我们可以轻易地获取其下投影(Down Projection,代码中记dp)和残差(Residual,代码中记res)。
dp_outputs = {j: None for j in range(36)}
def get_hook(layer_idx):
# noinspection PyUnusedLocal,PyShadowingBuiltins
def hook(module, input, output):
dp_outputs[layer_idx] = output.detach().squeeze(0).cpu()
return hook
handles = []
for j in range(36):
handles.append(model.model.layers[j].mlp.down_proj.register_forward_hook(get_hook(j)))
def process_dataset(data_list):
res_t = {j: [] for j in range(36)}
dp_t = {j: [] for j in range(36)}
for tmp in data_list:
for j in range(36):
dp_outputs[j] = None
tmp_out = model.generate(tmp.to(model.device),
attention_mask=torch.ones_like(tmp),
use_cache=False,
max_new_tokens=3,
return_dict_in_generate=True,
output_hidden_states=True,
do_sample=False)
for i in range(3):
for j in range(36):
res_val = tmp_out.hidden_states[2][j + 1][0][-i - 1] - tmp_out.hidden_states[2][j][0][-i - 1]
dp_val = dp_outputs[j][-i - 1]
res_t[j].append(res_val.cpu())
dp_t[j].append(dp_val.cpu())
return res_t, dp_t
我准备了一个非常小的应拒绝提问与不应拒绝的提问列表,并计算了它们的dp_t的平均数。
不过,一个有成百上千个维度的向量难以可视化,让我们使用PCA:
def plot_pca_distribution(layer_idx, layer_name):
pca = PCA(n_components=2)
s_feat = src_hiddens[layer_idx]
d_feat = dst_hiddens[layer_idx]
combined_feat = np.vstack((s_feat, d_feat))
pca_result = pca.fit_transform(combined_feat)
s_pca = pca_result[:len(s_feat)]
d_pca = pca_result[len(s_feat):]
plt.figure(figsize=(8, 6))
plt.scatter(s_pca[:, 0], s_pca[:, 1], alpha=0.7, label='SRC (Reject)', c='#e74c3c', edgecolors='w', s=50)
plt.scatter(d_pca[:, 0], d_pca[:, 1], alpha=0.7, label='DST (Normal)', c='#3498db', edgecolors='w', s=50)
plt.title(f'PCA of Hidden States: {layer_name}')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
plt.savefig(os.path.join(vis_dir, f'pca_distribution_{layer_name.replace(" ", "_")}.png'), dpi=300)
plt.close()
plot_pca_distribution(0, "Embedding Layer")
plot_pca_distribution(18, "Layer 18") # 你的干预区间内的主要层
plot_pca_distribution(36, "Final Layer")
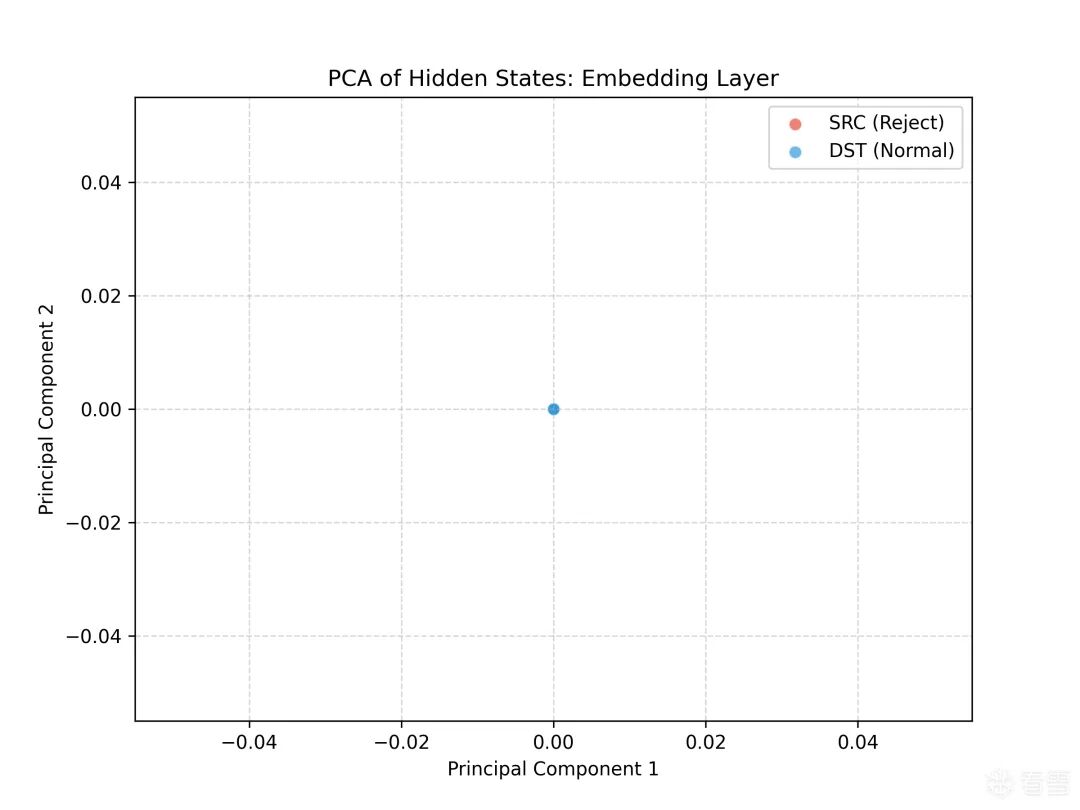
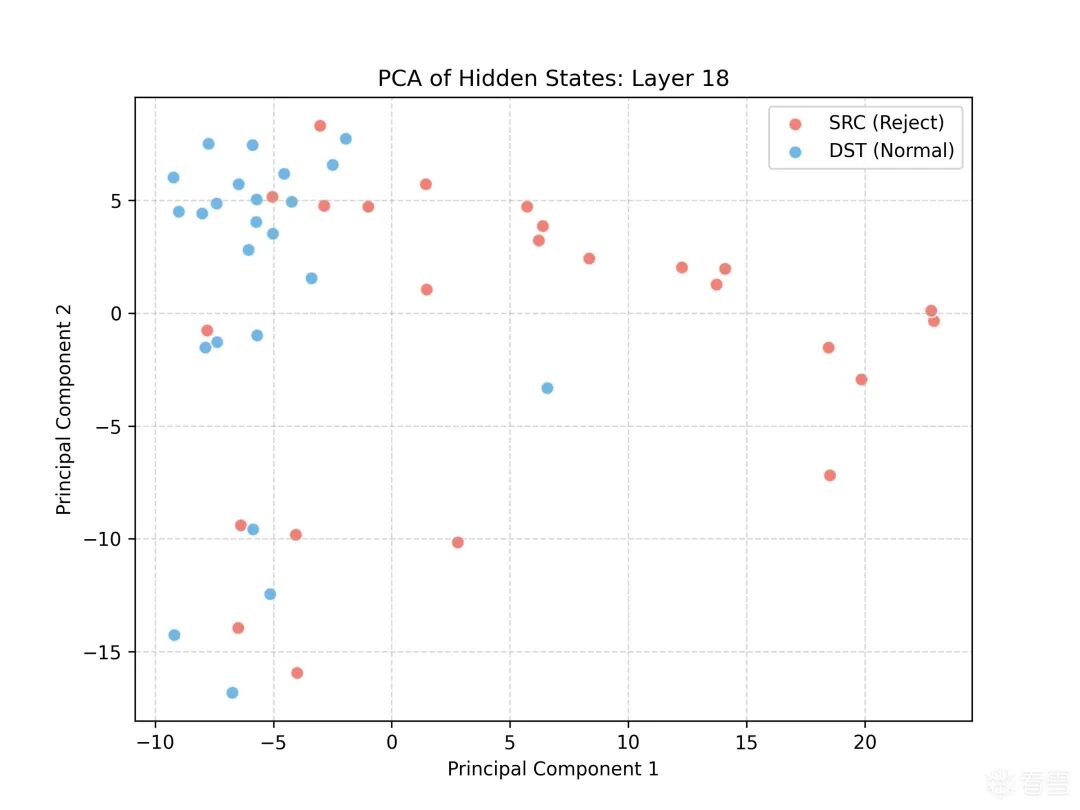
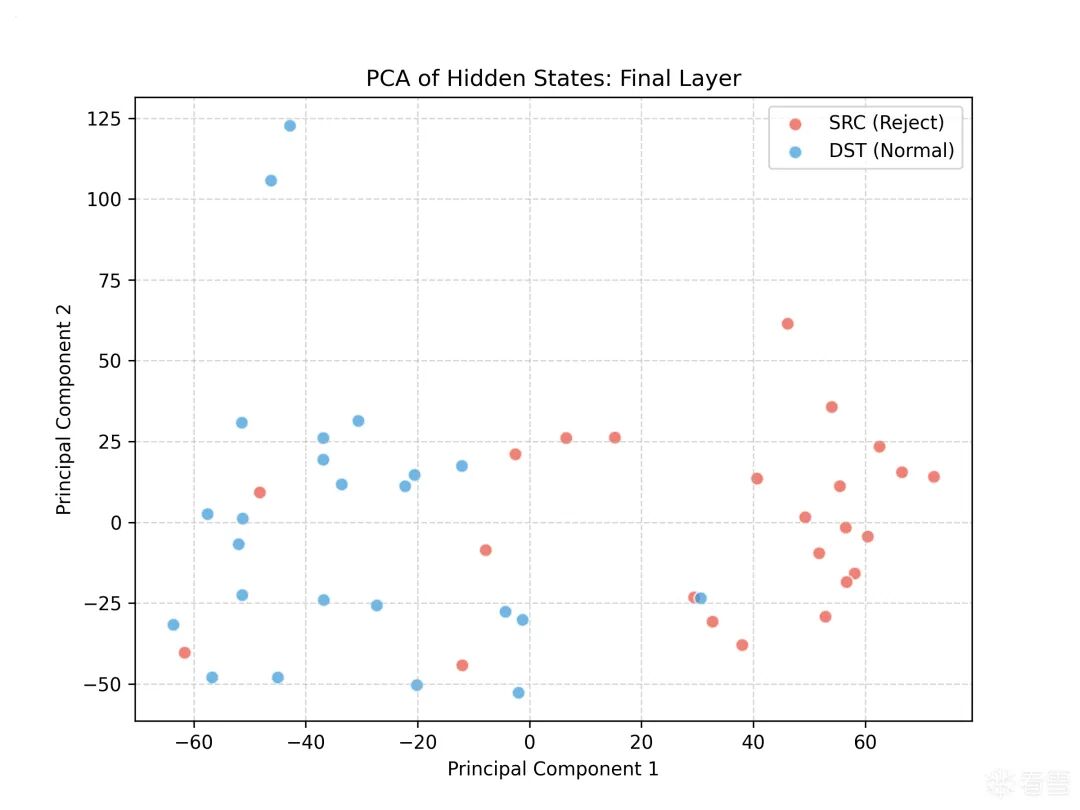
从图中可以看出:
- 相比于内部层,嵌入层对问题的应拒绝性的提取可以忽略不计。至少,在PCA到二维后可以忽略不计(不是说嵌入不能做文本内容安全分析,但是不优,并且至少要用余弦相似度或者支持向量机,而不是PCA到二维;这里不深入讨论此问题)
- 中间层拒绝方向已经成型,反对角线为拒绝向量的较好分割线。
- 输出层的拒绝方向未必就比中间层的强烈多少。
- 除此之外,我们确认了,确实可以找到一个单一的线性方向,使得这些样本被合并。
权重的编辑
我们知道,LoRA的公式是:

s_dp = src_dp_avg[i].to(torch.float32)
d_dp = dst_dp_avg[i].to(torch.float32)
s_res = src_res_avg[i].to(torch.float32)
d_res = dst_res_avg[i].to(torch.float32)
S_ss = torch.dot(s_dp, s_dp)
S_dd = torch.dot(d_dp, d_dp)
S_sd = torch.dot(s_dp, d_dp)
denorm = S_ss * S_dd - S_sd ** 2
if S_ss * S_dd > 1e-12:
cos_sim_sq = (S_sd ** 2) / (S_ss * S_dd)
else:
cos_sim_sq = torch.tensor(1.0)
if denorm.abs() > 1e-8 and cos_sim_sq < 0.99:
u = (S_dd * s_dp - S_sd * d_dp) / denorm
else:
# 进这个if就说明出问题辽
v = d_res - s_res
weight = model.model.layers[i].mlp.down_proj.weight
dtype = weight.dtype
u_W = torch.matmul(u, weight.float())
delta_W = torch.outer(v, u_W) * scaling_factor
model.model.layers[i].mlp.down_proj.weight.data = (weight.float() + delta_W).to(dtype)
(嗯,我也想过怎么避开公式说明这些...可能是不太行的)
那么,就完成了吗...?
编辑点的选择
刚开始我们提到,Qwen3-4B-Instruct-2507有36层。
一个很细微但是重要的问题是:我们要编辑哪个/哪些层呢?
事实上我们在2中便提到过,仅需编辑那些“能把输入和输出分开的层”。什么叫做分开呢?一个很简单的想法是余弦相似度低就叫分开:
cos_sims = []
for i in range(36):
s = src_dp_avg[i].float()
d = dst_dp_avg[i].float()
sim = torch.nn.functional.cosine_similarity(s, d, dim=0).item()
cos_sims.append(sim)
fig, ax1 = plt.subplots(figsize=(10, 5))
color = 'tab:blue'
ax1.set_xlabel('Layer Index')
ax1.set_ylabel('Cosine Similarity (SRC vs DST)', color=color)
ax1.plot(range(36), cos_sims, marker='o', color=color)
ax1.tick_params(axis='y', labelcolor=color)
ax1.axvspan(15, 24, color='gray', alpha=0.2, label='Patched Layers (15-24)')
ax1.legend(loc='upper left')
plt.title('SRC vs DST Representation Similarity & Intervention Zone')
plt.grid(True, linestyle='--', alpha=0.5)
fig.tight_layout()
plt.savefig(os.path.join(vis_dir, 'layer_similarity_and_patch_zone.png'), dpi=300)
plt.close()
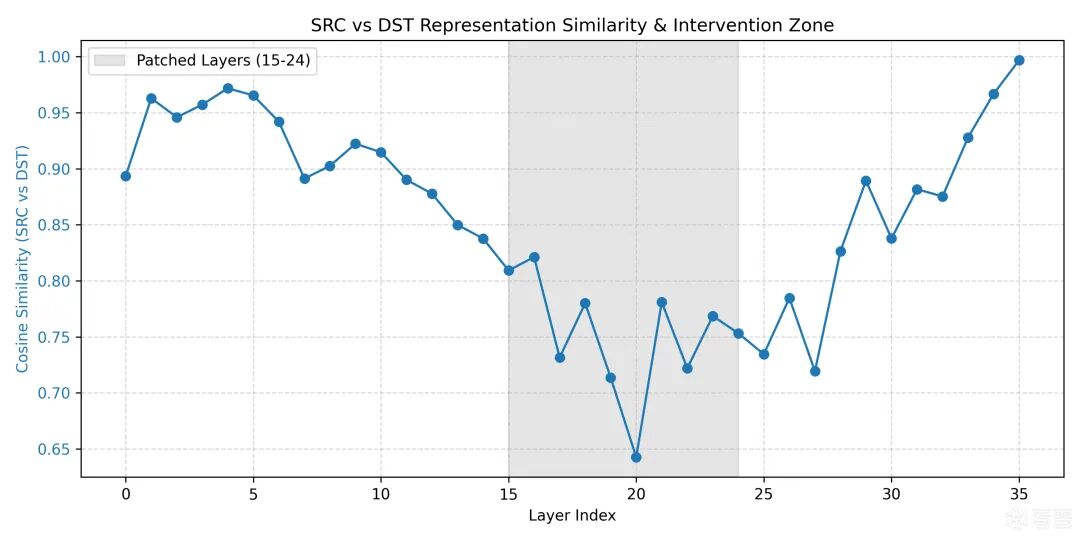
那么我们可以编辑第20层附近的层,比如说我选15-24。
在确定了这些后,具体的编辑是非常简单的,在此便一笔带过。
效果测试

如此,编辑后的模型能够拒绝回答任何问题,说明编辑方法是正确的。
总结
本文所讨论的技术手段,其唯一目的是展示如何通过权重编辑增强模型的特定行为(如:全面拒绝),以辅助 AI 安全对齐(Safety Alignment)研究。本文提供的公式与代码逻辑是基于增加模型拒绝概率设计的。严禁任何个人或组织通过修改算子符号
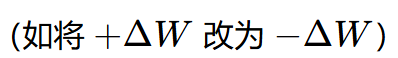
污染数据集或其他逆向手段试图移除原模型的安全护栏。 这种行为会导致模型输出不可预测、有害或违法的有害信息。
作者不对任何因恶意修改、误用或不当复制本文代码而导致的法律后果、名誉损失或技术风险负责。请确保在符合《生成式人工智能服务管理暂行办法》及相关法律法规的前提下进行学术研究。
 发表于 2026-4-22 18:44:54
|
查看: 249|
回复: 0
发表于 2026-4-22 18:44:54
|
查看: 249|
回复: 0
