
在过去的十多年里,机器学习领域有一个默认的“前提”:模型一旦训练完成,其参数基本就固定了。无论输入什么样的数据,模型都会依赖同一套参数完成推理。这种范式固然取得了巨大成功,但当人工智能逐渐进入更加复杂、多变的现实应用环境时,它的局限性也开始显现。
现实中的任务往往是高度多样化的。不同用户的需求、不同的任务目标,有时甚至是相互冲突的。以图像编辑为例,面对同一张图片,用户可能提出截然相反的要求:有的需要增强细节(如去模糊或修复),而另一些则要求弱化细节(如添加模糊或模拟老化效果)。如果模型始终依赖同一套固定参数,它往往只能在不同的目标之间做出折中,最终影响编辑效果。
传统的解决方案是通过领域适应或模型微调来让模型适应新数据。但这通常意味着额外的训练成本和更复杂的系统维护。一个自然的问题是:能否让模型在推理阶段实时地适应不同任务?
为此,腾讯混元团队提出了一项全新的研究。在这篇题为《HY-WU (Part I): An Extensible Functional Neural Memory Framework and An Instantiation in Text-Guided Image Editing》的论文中,他们尝试改变模型的适应方式——让模型在推理阶段,根据当前的输入动态生成适配该任务的参数,而不是始终依赖一套固定参数。

论文地址:https://arxiv.org/pdf/2603.07236
一个模型,多种行为:实验结果验证
为了验证“动态参数生成”是否真的比“固定参数”更优,研究团队设计了四类实验。
1. 人类评测实验
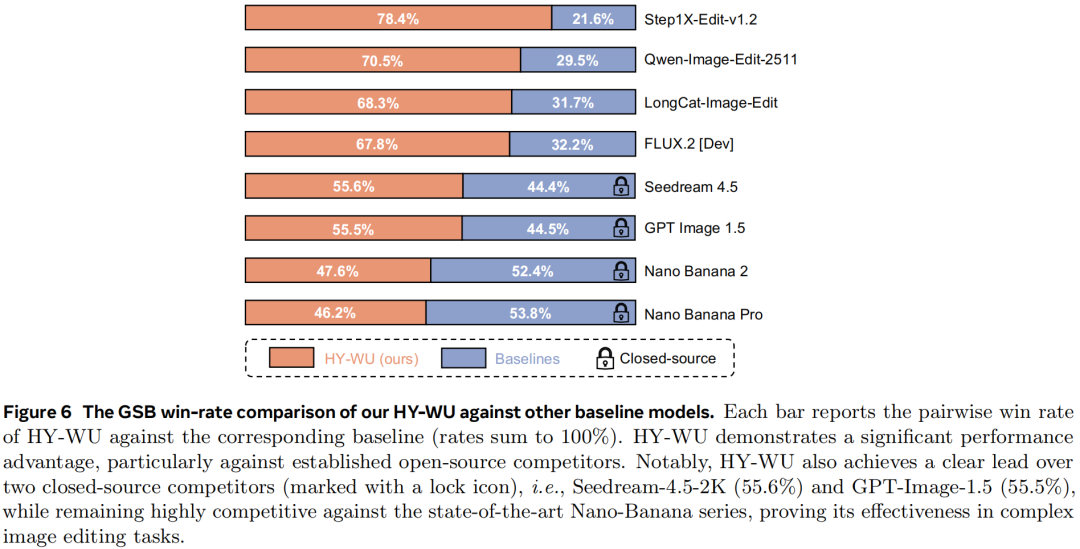
研究进行了大规模的人工评测。评委在给定相同输入图片和编辑指令的条件下,对不同模型生成的编辑结果进行两两比较,选择效果更好的一个,并统计最终胜率。
结果显示,HY-WU 模型在多项对比中优势明显:
- 对开源模型 Step1X-Edit 胜率约为 78.4%
- 对 Qwen-Image-Edit 胜率约为 70.5%
- 对闭源模型 Seedream 4.5 和 GPT Image 1.5 的胜率也分别达到 55.6% 和 55.5%
在与当前最先进的商业系统 Nano Banana 系列比较时,HY-WU 的表现略有差距,但整体保持了竞争力。这些数据表明,通过动态生成参数,模型在视觉编辑效果上取得了显著提升。
2. 自动评测实验
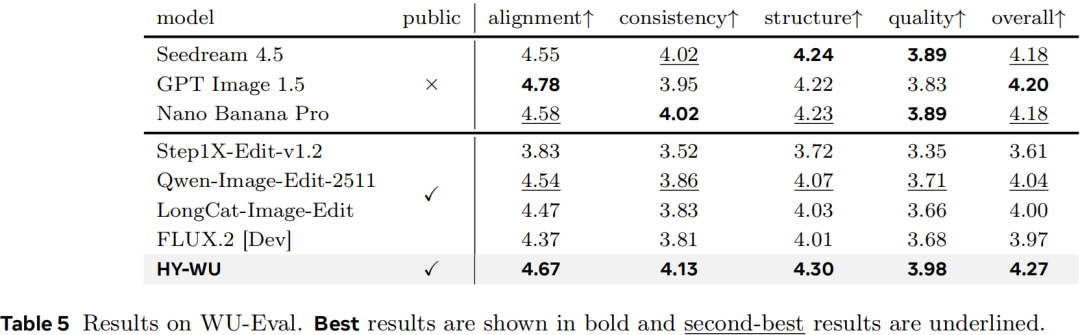
除了人工评测,研究人员还设计了名为 WU-Eval 的自动评估系统,从指令对齐(alignment)、内容一致性(consistency)、结构合理性(structure)和图像质量(quality)四个维度进行评估。
结果显示,HY-WU 在总体得分(4.27) 和各个子维度上均取得了最高或接近最高的分数。与最强的开源基线模型相比,HY-WU 在一致性指标上提升了约 0.27,在结构保持上提升了约 0.23。这证明了动态参数生成机制能有效提升编辑的稳定性和结构的保持能力。
3. 公开基准测试
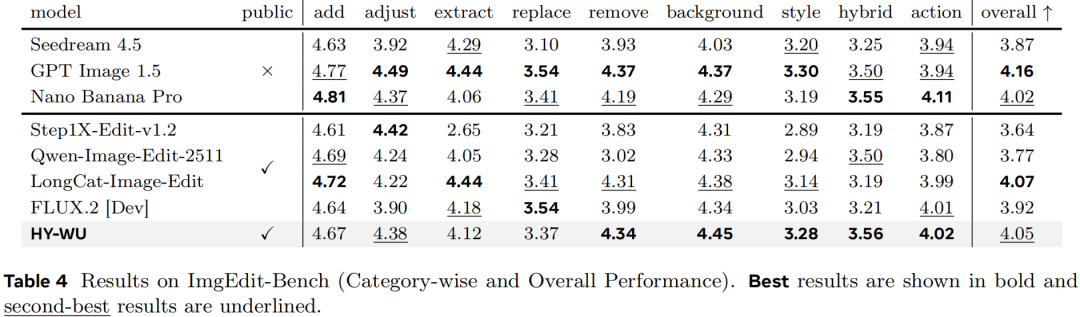
在公开的图像编辑评测数据集上,HY-WU 也表现不俗。在 GEdit-Bench 上,它在所有开源模型中排名第一;在 ImgEdit-Bench 上,总体得分 4.05,在开源模型中排名第二。这说明该方法不仅在内部实验有效,在公开、标准的环境中同样具有竞争力。
4. 冲突任务实验
这是最能体现动态参数生成价值的实验。研究团队设计了一组相互矛盾的编辑任务对,例如“图像去模糊 vs 图像模糊”、“图像修复 vs 图像老化”,来测试模型在目标冲突下的表现。
他们对比了三种策略:
- Single LoRA:为每个任务分别训练独立的适配器。结果发现,它们虽在各自任务上表现优秀,但完全无法处理对立任务,过度专门化。
- Shared LoRA:让多个冲突任务共享一个适配器。结果是所有任务的输出效果都被明显折中,比如去模糊和模糊都变成了“半模糊”。
- HY-WU:根据每个输入实时生成适配参数。结果显示,模型能够正确执行所有冲突任务,且互不干扰。
这个实验清晰地表明,动态参数生成能有效避免因参数固化导致的任务冲突和效果妥协。

一个模型,多套参数:HY-WU 系统架构解析
那么,HY-WU 是如何实现“一个模型,多套参数”的呢?
核心思想是:让一个额外的参数生成网络,在推理时根据当前输入(图像+指令)实时生成适配该任务的模型参数,并以 LoRA 适配器的形式动态注入到冻结的基础模型中。这样,同一个基础模型面对不同输入时,实际上是在用不同的参数配置进行推理。
其整体流程如图3所示,主要分为三个阶段:

1. 条件提取
系统分别从输入图像和文本指令中提取特征,并将其融合为一个统一的“条件”表示。这个表示编码了当前的视觉内容以及用户的编辑意图,是后续参数生成的关键依据。
2. 参数生成
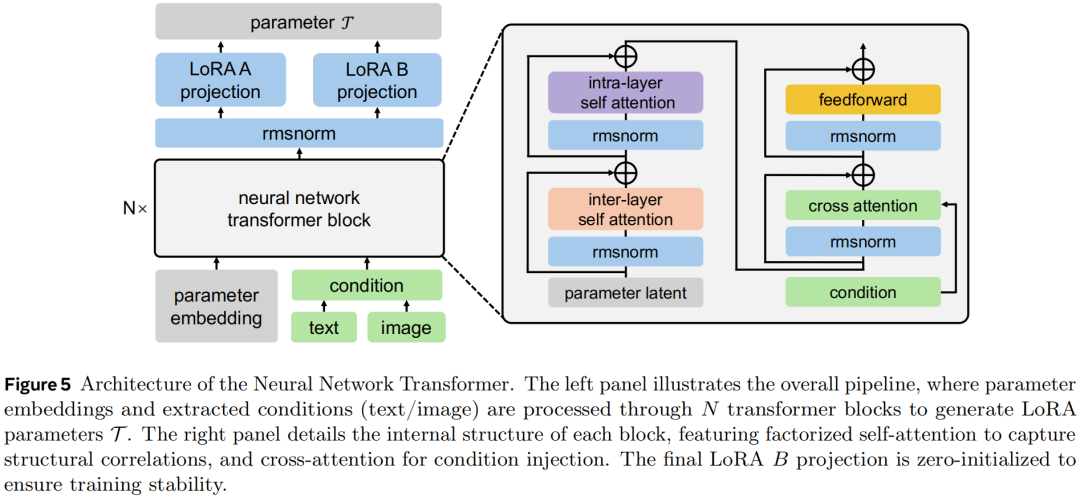
提取到的条件信息被送入一个基于 Transformer 架构的参数生成网络。这个网络不生成图像,而是输出一组 LoRA 适配器参数。LoRA 是一种参数高效的微调方法,能在不改动原始模型主体权重的情况下,调整模型的行为。该生成网络的详细架构如图5所示,内部采用了因子化自注意力等设计来捕获参数间的结构关联。
3. 图像编辑执行
生成的 LoRA 适配器被动态插入冻结的基础模型中。随后,基础模型在“专属参数”的引导下完成图像编辑,并输出最终结果。由于每个输入都会触发生成一套新参数,因此模型在面对不同任务时能展现出不同的行为模式。
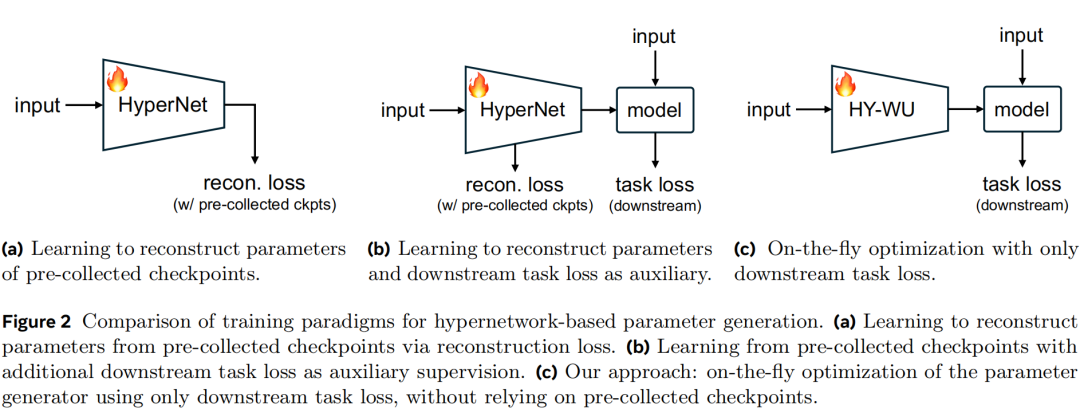
训练方式上,HY-WU 摒弃了传统“超网络”方法需要预收集大量模型检查点的繁琐流程。它采用了一种更直接的端到端训练策略(如图2-c所示):
- 输入(图像,指令)
- 参数生成网络根据输入生成 LoRA 参数
- 基础模型结合 LoRA 参数生成编辑后图像
- 计算生成图像与目标之间的扩散损失
- 用该损失直接反向传播更新参数生成网络
这种方式绕过了存储和管理海量预训练模型的需求,让系统能直接围绕最终的编辑任务目标进行优化。
一个模型,应对无限变化的任务:从技术到范式
从更宏观的视角看,HY-WU 的研究意义远不止于提升图像编辑的效果。它实际上提出了一种新的模型适应范式。
传统范式是“一套固定参数应对所有任务”,而现实世界是多样、动态且充满未知的。过去我们依靠重新训练或微调来适应新领域,成本高昂且不灵活。HY-WU 的启示在于:我们或许可以训练一个模型,让它学会如何实时地为自己生成合适的参数。

一个真正强大、智能的系统需要具备两种关键能力:一是适应不同任务的能力,二是这种适应必须是实时发生的。HY-WU 正是在推理阶段实现了 实时适配。模型在每一次处理输入时,都像完成一次“微小的、针对性的微调”,从而灵活切换行为模式。

这为未来人工智能的发展提供了一个新思路:未来的 AI 系统可能不再是单一的、固化的模型,而是一个能根据环境、任务实时调整自身“内在配置”的自适应系统。从固定模型走向实时适配系统,这或许是 AI 应对无限复杂现实世界的一条必经之路。
对这类前沿的人工智能与模型动态参数生成技术感兴趣的朋友,欢迎在云栈社区交流讨论,获取更多深度技术解读。
 发表于 2026-3-12 01:39:45
|
查看: 147|
回复: 0
发表于 2026-3-12 01:39:45
|
查看: 147|
回复: 0
