今年四月,具身智能领域发生了一件看似不大但意味深长的事。明星公司 Generalist AI 发布了 GEN-1,其在成功率、速度和数据效率三个核心维度上都实现了跨越式提升。
几乎在同一时间,该公司的 CEO Pete Florence 发布了一篇博客,明确指出他们不再将自己的模型归类为 VLA(视觉-语言-动作模型)。
这件事之所以值得关注,是因为 Florence 本人正是 VLA 概念的共同开创者之一。他在文中直言,如果目标是物理 AGI,那么“目标远比你手里‘工具的标签’更重要”。他更点破了一个行业长期回避的事实:将视觉语言训练引入机器人,很大程度上是因为机器人自身的交互数据不足,VLM 只是一根过渡期的“拐杖”。
一旦物理交互数据规模起来,这根拐杖就该被拿掉。这引导我们思考一个更本质的问题:当超越 VLA 之后,下一代 具身模型 应该是什么样,才能真正支撑机器人在真实世界中稳定、可扩展地运行?
当下,许多被称为“世界模型”的工作,实质上属于视频生成范式——它们在像素或低层视觉隐空间里预测未来帧。这类模型回答的是“下一帧是否符合真实视频的视觉逻辑”,而非“世界进入了什么对行动有意义的状态”。在机器人任务中,这通常会暴露四大系统性瓶颈:
- 表示瓶颈:模型容量被消耗在与任务弱相关的纹理、光照等视觉噪声上。
- 记忆瓶颈:因果自回归配合 KV 缓存,导致内存占用随轨迹长度线性增长。
- 推理瓶颈:感知、推理、执行严格串行,部署延迟高,闭环频率上不去。
- 数据瓶颈:依赖固定的离线数据集,缺少持续、新鲜、物理可信的在线数据流。
评价标准的重新审视:许多榜单与机器人任务脱节
范式切换后,一个关键问题是:世界模型究竟该如何评价?目前被频繁引用的,多是面向视频生成的榜单,考察画质、时序一致性等指标。但这些对于“生成式视频模型”合理,在具身语境下则可能产生错位。
2026年2月,清华等机构发布的 WorldArena 基准对此进行了系统验证。他们测试了14个代表性世界模型后得出了一个直接结论:高视觉质量并不一定能转化为强大的具身任务能力。论文数据显示,综合视觉质量指标与人类主观打分的相关性很高(Pearson r = 0.825),但与作为动作规划器的任务成功率之间,相关性仅为弱相关区间(r = 0.360)。
一个模型完全可以生成极其逼真的未来视频,却在真实机器人上因为几何不准、动力学不稳而失败。因此,跨维智能的观点很明确:具身世界模型的唯一合理评价指标,是下游机器人任务的成功率。
在这个意义上,像 RoboTwin 这类以机器人任务成功率为核心评价维度的榜单,才是具身世界模型真正应该被检验的“考场”。
DexWorldModel 技术栈:四层协同,推动真机闭环

DexWorldModel 的系统设计可以概括为一条总线:因果潜空间世界模型 (CLWM) + 双状态测试时记忆 (Dual-State TTT Memory) + 推测式异步推理 (SAI) + 具身数据链与在线数据流 (EmbodiChain / ODS)。
这四部分并非独立模块,而是围绕“真机闭环部署”这一主线,从表示、记忆、推理到数据供给做出的协同升级,逐一回应前述瓶颈。
1. 表示层:从像素重建转向语义状态预测
许多世界模型直接在像素空间或低层视觉隐空间中预测未来。这在研究中可行,但在真实机器人任务中,模型会因处理大量无关视觉细节而效率低下。对机器人而言,关键不是下一帧是否逼真,而是 世界是否进入了一个可操作、可执行下一步动作的状态。
CLWM 将生成目标切换到了更高层的语义特征。它利用冻结的 DINOv3 模型提取观察图像的语义特征,并以此作为生成目标。这从根本上改变了模型回答的问题:不再是“下一帧好不好看”,而是 “世界是否进入了对下一步行动有意义的状态”。
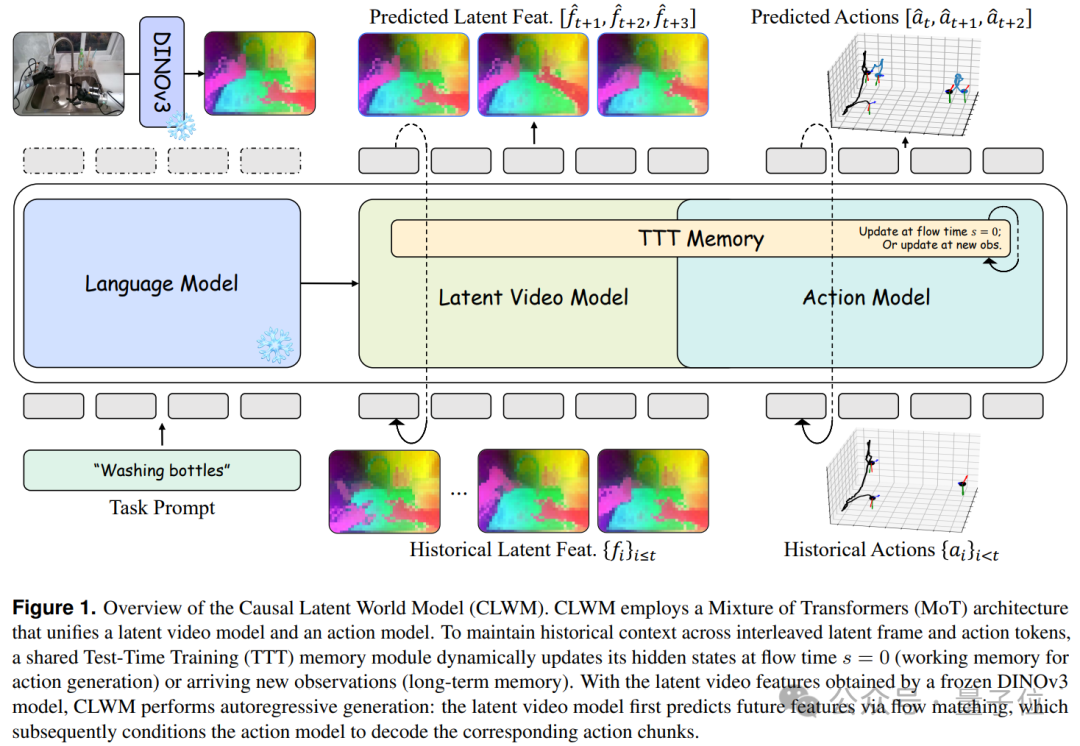
该模型采用混合 Transformer (MoT) 架构,将潜视频模型与动作模型统一起来。在流匹配框架下,它先将历史观测和动作作为条件,预测未来的潜语义特征,再基于此条件生成对应的动作块。这种设计让模型更容易跨越视觉噪声的干扰,为后续的鲁棒泛化和仿真到真实迁移奠定了基础。
2. 记忆层:常数级内存应对长时任务
传统自回归世界模型依赖 KV 缓存记录历史,空间复杂度为 O(T)。在长时连续任务中,显存占用会线性膨胀,成为系统瓶颈。
CLWM 引入了 TTT-MLP(Test-Time Training Memory)模块,将历史观测和动作压缩进记忆模块的权重中。其核心是双状态机制:
- 长时记忆:仅由真实观测和已执行动作更新,锚定真实的因果历史。
- 工作记忆:从长时记忆中派生,作为当前预测步骤的临时上下文。在流匹配去噪过程中,工作记忆保持冻结,仅在去噪完成后才更新。
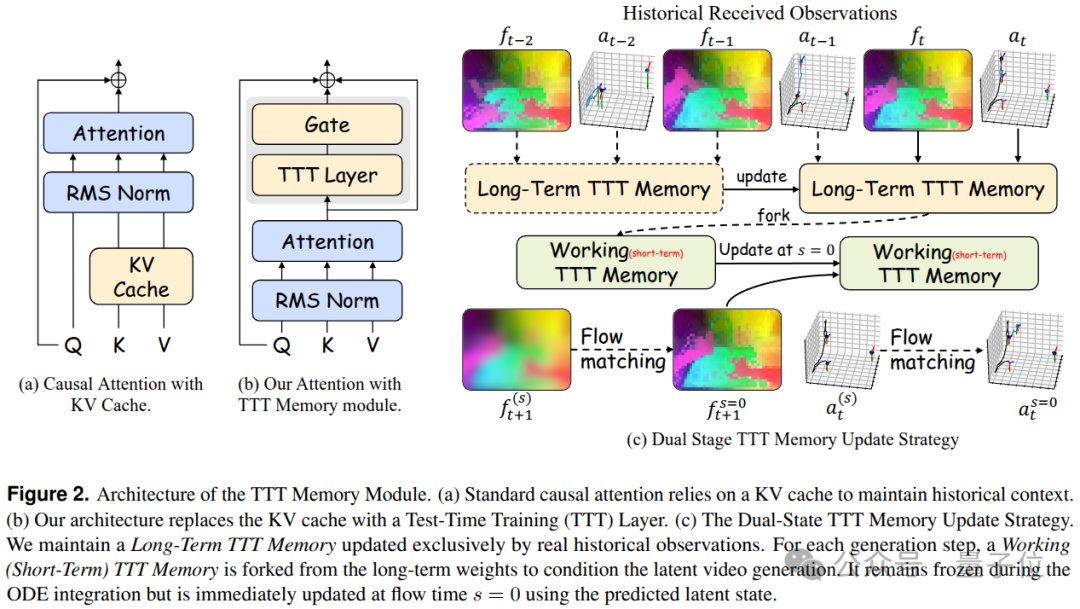
这套机制的关键在于严格隔离真实历史与推测历史,避免推测的未来污染真实的因果链。同时,它将长时序任务的内存占用压至常数级 O(1),使得系统在持续运行中不会“越积越重”,为稳定部署长时操作提供了可能。
3. 推理层:SAI 将一半推理时间隐藏在动作执行中
即使模型能力强大,只要“感知→推理→执行”保持串行,真机闭环频率就会被阻塞延迟所限制。SAI 正是为了将模型的前瞻能力兑换成系统时间而设计:
- 机械臂执行当前动作时,GPU 不空转。
- 利用上一轮预测得到的未来语义作为代理条件,在后台预先进行下一阶段未来语义与动作的前半段去噪。
- 真实观测到达后,快速更新长时记忆,再完成后半段精细去噪。
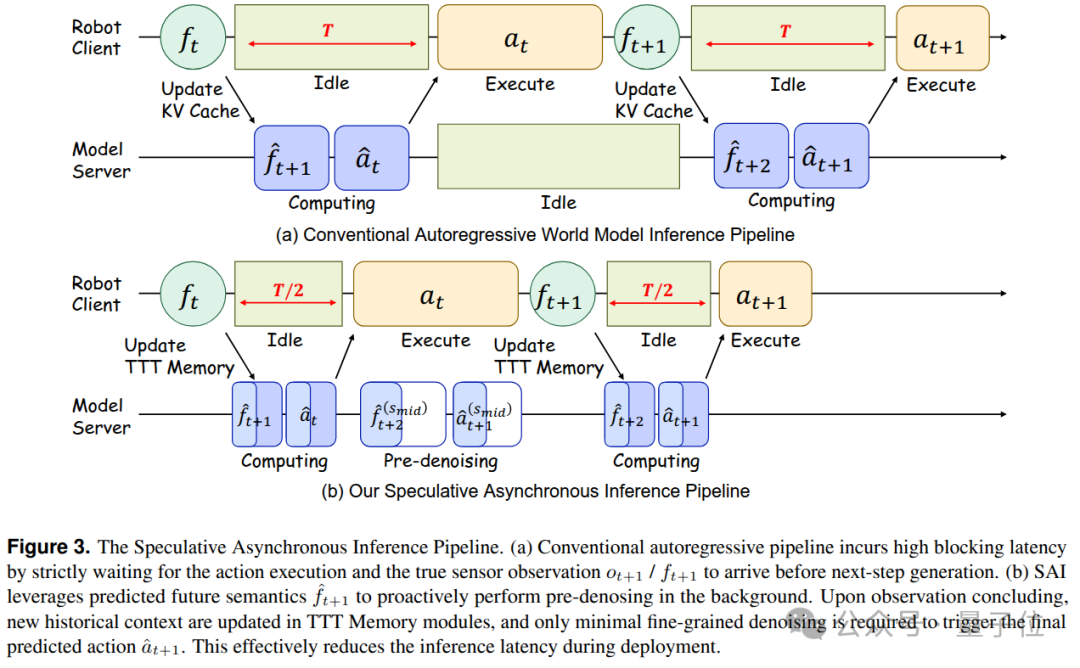
在 RoboTwin 仿真环境中,这一设计使端到端阻塞延迟下降了约 50%。世界模型带来的不仅是“更准确的预测”,还包括 “更少的等待”和“更高的闭环频率”,这对于真实机器人系统而言至关重要。
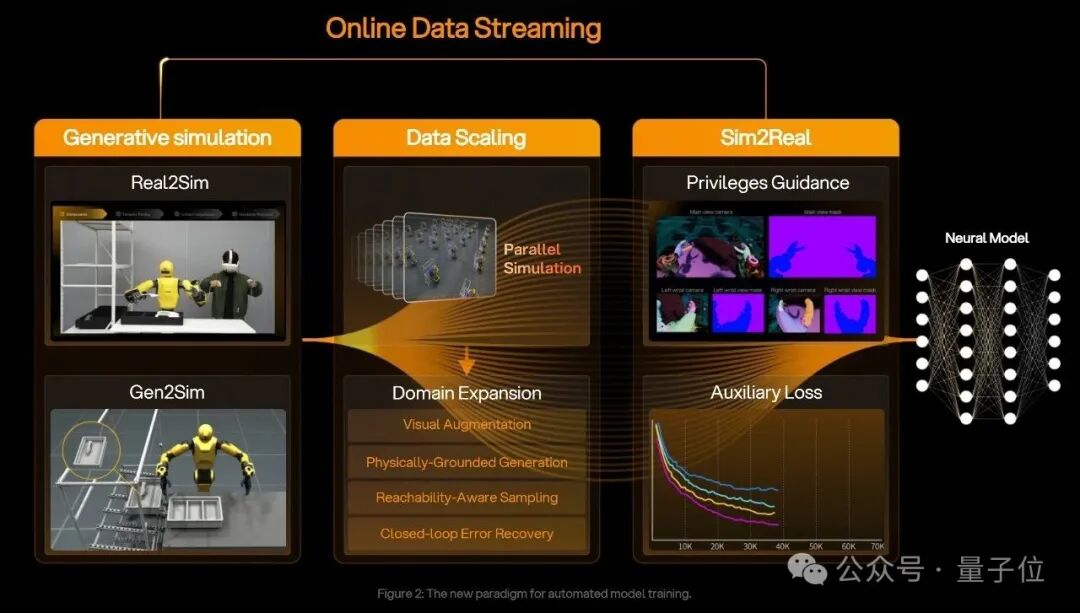
4. 数据层:EmbodiChain 将数据效率变为系统能力
世界模型能否持续进化,取决于能否接触到足够新鲜、多样且物理可信的经验。机器人数据获取成本高、生产慢,这恰恰是具身智能与互联网数据范式最大的不同。瓶颈往往不在于网络结构,而在于 高质量交互数据的吞吐率。
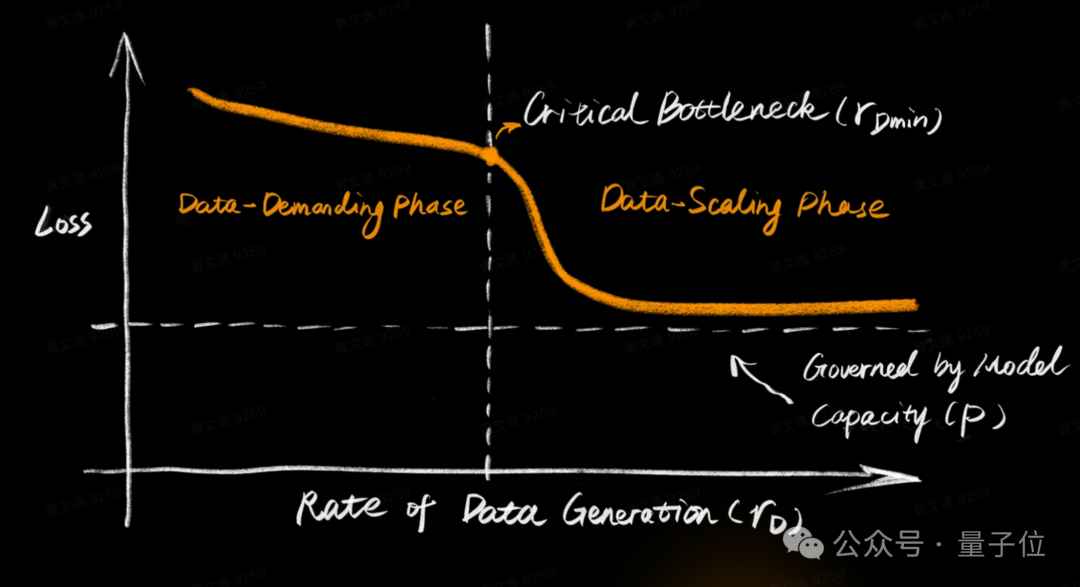
EmbodiChain 构建了一条从数据生产到训练更新的在线闭环:
- 物理一致的资产与场景快速生成。
- 考虑可达性的轨迹采样,提升功能多样性。
- 失败恢复轨迹回流训练,补齐错误状态下的监督信号。
- 在线数据流:持续流式注入新的批量数据,替代对静态数据集的反复训练。
消融实验表明,当 在线数据流 中新鲜经验的吞吐更高、单条轨迹被重复使用的次数更低时,任务成功率显著提升。因此,EmbodiChain 并非外围工具,而是 DexWorldModel 能够不断逼近真实世界能力边界的 核心经验引擎。
实验结果:RoboTwin 榜单第一与真机零样本迁移
评价标准回归到机器人任务成功率后,我们来看 DexWorldModel 在相关榜单上的表现。
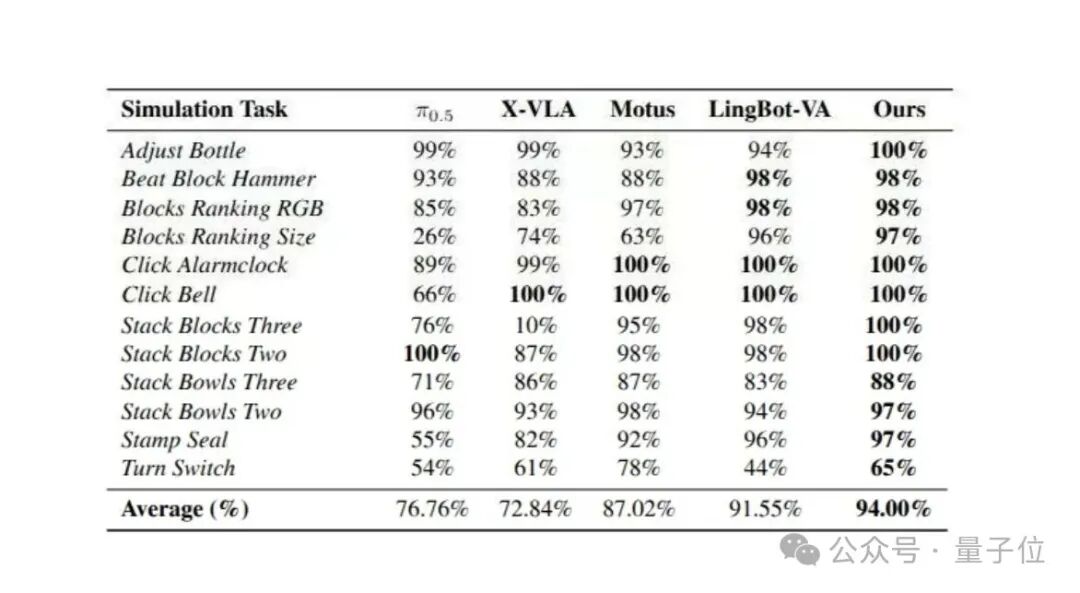
在 RoboTwin 仿真基准上,DexWorldModel 取得了 94.00% 的平均成功率,超越了多项主流基线模型。在系统效率方面,双状态 TTT 记忆在长时任务中维持了常数级内存占用,SAI 则将部署阻塞延迟降低了约 50%。
更值得关注的是仿真到真实的迁移能力。DexWorldModel 在四个真实机器人任务上报告了 零样本迁移 结果:模型仅在仿真环境中训练,其表现就优于 π0、GR00T N1.5 与 Sim2Real-VLA,而后两者中的部分基线还使用了真实示范数据进行微调。

这组结果有几个关键点:
- 系统性改进:这不是单点突破,而是表示、记忆、推理、数据供给四层收益叠加的结果。
- 数据引擎不可或缺:关闭在线数据流后,成功率显著下滑,印证了持续经验流本身就是一种核心系统能力。
- 零样本迁移的突破:仅在仿真中训练,就能在真机上超越部分经过真机微调的基线,这标志着“具身世界模型”在通往实用的道路上迈出了关键一步。
开源 EmbodiChain:重构具身智能的 Scaling Law
如果说 DexWorldModel 是模型侧的答卷,那么 EmbodiChain 则是跨维智能希望贡献给整个行业的基础设施。过去常被引用的 Scaling Law 在机器人领域面临挑战:真正稀缺的不是参数或存量数据,而是持续、物理可信、可交互的在线数据流。
为此,跨维智能选择将 EmbodiChain 作为仿真数据基础设施开源。它并非一次性数据集,而是一套可被社区复用、扩展和共建的经验生产链路,涵盖了资产生成、场景布局、可达性感知采样、失败恢复、视觉域扩展和在线数据流等模块化组件。

这一举措旨在帮助行业将注意力从“追求更大的模型”拉回到“构建更持续、更新鲜、更物理可信的数据基建” 这条真正决定具身智能发展斜率的主轴上。开源是起点,目标是与社区共同推动这条曲线变得更为陡峭。
结语
总结而言,跨维智能在这一阶段的核心观点是:世界模型的胜负手,不在于视频生成得是否逼真,而在于机器人能否稳定地在真实世界中完成任务。
当 VLA 的开创者都已决定转向,剩下的核心问题便是:谁能先将具身模型从概念推向真机部署。DexWorldModel 尝试在表示、记忆、推理和数据引擎四个层面协同发力,一步步缩小仿真与真实世界间的鸿沟;EmbodiChain 则致力于让这种进化能够持续发生。

这项工作的意义,不仅在于世界模型本身,更在于选择直面那些决定真实落地的系统性问题。它没有宣称所有问题都已解决,但确实将几段最关键的间隙显著缩小了。这也反映了跨维智能一贯的态度:不与概念赛跑,而是与真实世界赛跑。对这类前沿 人工智能 技术的深度探讨与实践分享,欢迎持续关注 云栈社区 的相关板块。
 发表于 2026-4-21 20:39:36
|
查看: 156|
回复: 0
发表于 2026-4-21 20:39:36
|
查看: 156|
回复: 0
