5 月 22 日,Tri Dao 在社交媒体上转发了 Han Guo 的一条推文,并评论道:「经过一些数学重写,结果发现 Transformer 的所有内容都是一系列 GEMM + epilogue(矩阵乘法加尾声)。给定一些优化的原语,LLM(以及新手)就可以为所有 Transformer 操作编写光速内核!」

Tri Dao 是 FlashAttention 系列的核心作者之一,而这条推文指向了他们当天发布的一篇论文:CODA。

这个名字,读起来像「终曲」,念起来像「CUDA」。来自 MIT、普林斯顿、Together AI 和 Meta 的研究者,试图用一套新的编程抽象,把 Transformer 训练里那些鲜少被人关注、却持续消耗时间的「散碎计算」,系统性地消化掉。
背景:训练大模型的「偷懒税」
要理解 CODA 在解决什么问题,先要明白大模型训练的时间都去哪了。
在一块英伟达 H100 上训练一个 LLaMA-3 风格的 1B 参数模型,大部分人会直觉地认为:时间都花在矩阵乘法和注意力计算上,毕竟那才是「真正的计算」。这个直觉大体没错:矩阵乘法(GEMM)和注意力确实占据了主要算力。
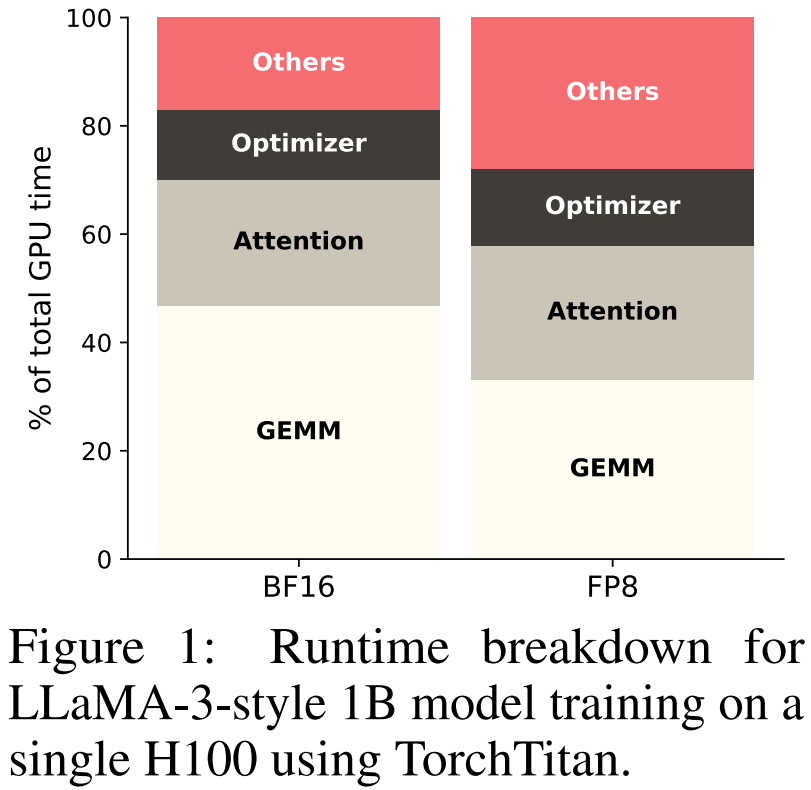
但如果你打开性能分析器仔细看,会发现还有一批「小算子」在安静地消耗着时间:归一化(RMSNorm)、激活函数(SwiGLU、RoPE)、残差加法、跨层规约…… 它们单个计算量不大,却频繁地把大型中间张量从显存里搬进搬出。
这就是所谓的「内存带宽瓶颈」:好比一个厨艺绝顶的厨师,但每做一道菜都要把食材从远处的仓库搬来、用完再送回去,而不是放在手边的台面上。厨师的手速再快,等待搬运的时间也是真实的浪费。
更糟糕的是,随着英伟达的 FP8、FP4 等低精度格式让矩阵计算越来越快,这些「搬运」操作的相对成本反而在上升:矩阵乘法加速了,但张量搬进搬出的成本并没有同比缩短。
论文中有一组数据很直观:在 H100 上用 TorchTitan 训练 1B 参数模型时,非矩阵乘法操作占据了相当一部分的端到端运行时间,且随着 FP8 精度的引入,这一比例还会进一步凸显。
现有的编程框架对此几乎无能为力。PyTorch 把 Transformer 的计算表达成一串算子序列,算子之间有清晰的边界。这种边界对于自动微分(autograd)非常友好,却恰好阻止了跨算子的融合优化:每一个算子边界,往往就是一次不必要的显存写回。
CODA:「尾声」里藏着宝藏
CODA 的出发点是一个朴素的观察。
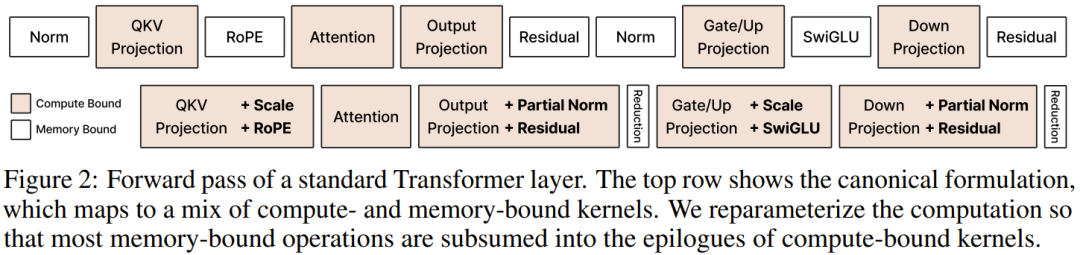
在 GPU 上,一个高性能的矩阵乘法(GEMM)内核在结构上分为两个部分:主循环(mainloop)负责核心的矩阵分块乘加计算,尾声(epilogue)负责在结果写回显存之前做一些收尾处理,比如加偏置、类型转换、简单缩放。
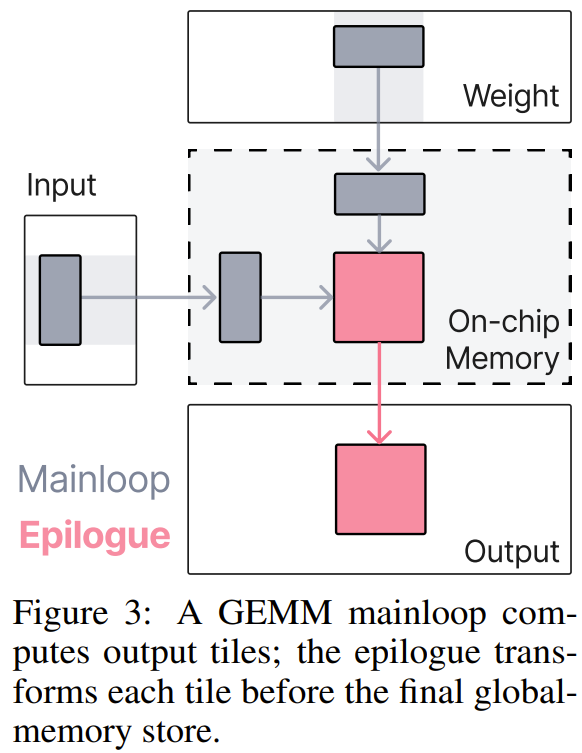
尾声存在的意义,在于此时矩阵乘法的输出还「活在」片上寄存器里,还没有落地到全局显存。这是一个短暂的黄金窗口:如果能在这个时刻多做一些计算,就可以完全省掉一次显存写入再读出的往返。
CODA 的核心洞察是:Transformer 里那些内存密集型操作,其实很多可以被代数地重新参数化,塞进这个「尾声」窗口里执行。
这需要一点数学技巧。以最常见的 GEMM-RMSNorm-GEMM 模式为例:一个矩阵乘法的结果,经过残差加法、RMS 归一化,然后再做另一个矩阵乘法。传统做法是三个独立算子串行执行,中间结果两次落地显存。
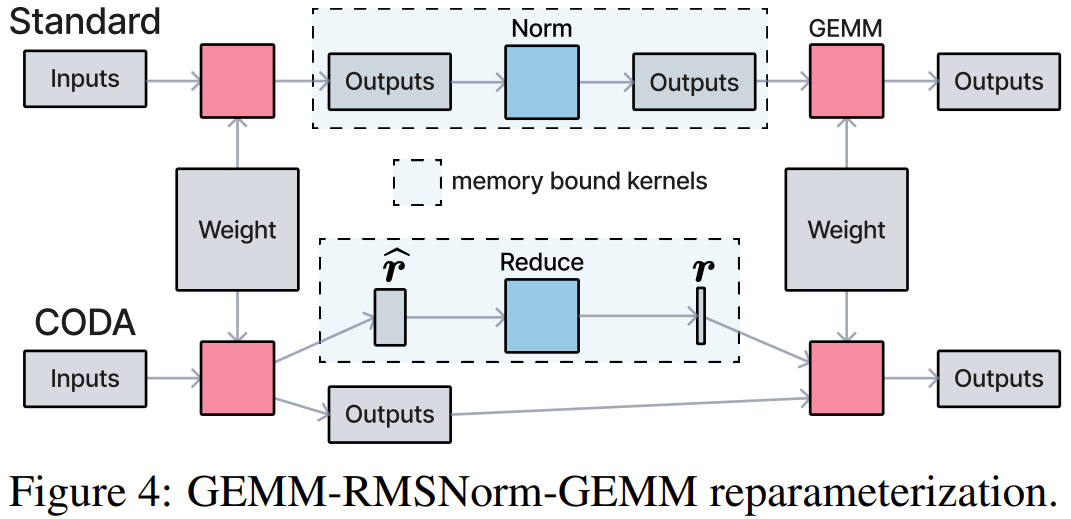
CODA 团队发现,RMS 归一化中的行缩放因子 r,因为是每行共享的标量,它和后面的矩阵乘法满足交换律:可以把 r 的应用从「第二个 GEMM 之前」推迟到「第二个 GEMM 的尾声」。推迟之后,第一个 GEMM 的尾声只需要计算局部的「分块均方根」(partial RMS),由一个极轻量的辅助规约内核合并,而完整的 RMSNorm 计算消失了。
类似的重新参数化,对 SwiGLU、RoPE(旋转位置编码)、交叉熵损失等操作同样适用,甚至对反向传播也成立。论文中有一个定理证明:只要前向尾声是「分块局部」的,反向传播就自动继承相同的结构。具体请访问原论文查看。
五种「积木」和一套「乐高语言」
CODA 不是一个具体的融合内核,而是一套编程抽象。
它固定住经过专家优化的 GEMM 主循环,然后在尾声位置暴露五类可组合的基本原语:
- 逐元素变换:residual 加法、激活函数、RoPE
- 向量加载与存储:广播 RMSNorm 权重
- 矩阵分块加载与存储:保存中间激活供反向传播使用
- 分块规约:局部均方根、分块 log-sum-exp
- 有状态变换:在线归一化所需的 max 和 sum-exp 统计
用这五类积木,一个标准 Transformer 的前向和反向传播中、除注意力之外的几乎全部操作都可以被覆盖。
更有意思的是这套抽象对「谁来写代码」的宽容度。论文在实验中评估了两种实现模式:一种是人工程序员撰写,另一种是用 Claude Code 来生成 —— 给定 CODA 的原语说明、若干示例和实现日志,由 AI 完成大部分内核代码,人工轻度监督。
两种模式的性能表现均达到了较高水平。Tri Dao 在推文中说「LLM 以及新手就可以编写光速内核」,这正是论文实验结果在现实层面的映射。
实验结果
CODA 的基准测试选择的是较为苛刻的对手:cuBLAS 加上 torch.compile,以及专为 LLM 优化的 Liger Kernel 和 FlashInfer。
论文对每个内核评估了两种实现:
- CODA (LLM):由 Claude Code 生成,研究者提供原语说明、若干示例和一份持续更新的实现技巧日志,AI 完成主体代码,人工做轻度监督。
- CODA (Human):由人工程序员独立编写,使用同样的高层重参数化思路,但不依赖 CODA 原语集本身。
两组结果都与 cuBLAS + torch.compile、Liger Kernel、FlashInfer 等优化库进行对比。
在单算子层面,以 GEMM-RMSNorm-GEMM 这一典型模式为例,CODA 在对应 1B、7B、70B 三个模型规模的隐藏维度下均实现了对 cuBLAS + PyTorch 基线的超越。
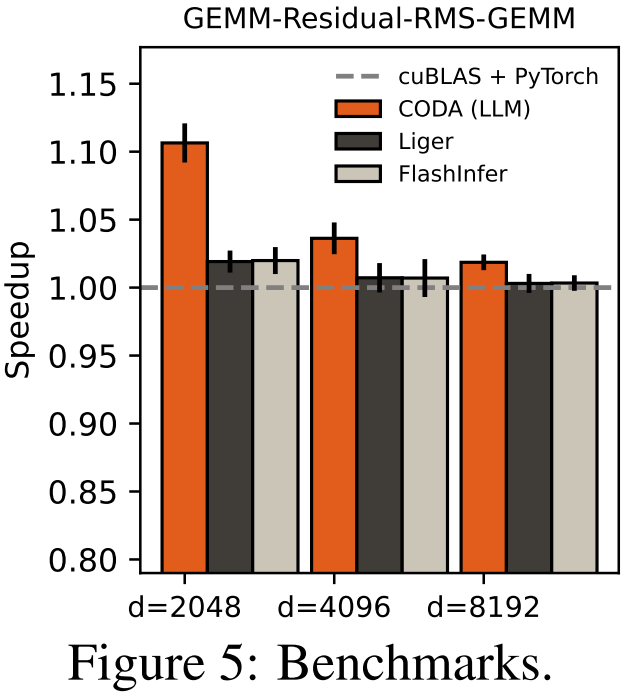
SwiGLU、RoPE、交叉熵等尾声组合也有类似表现。
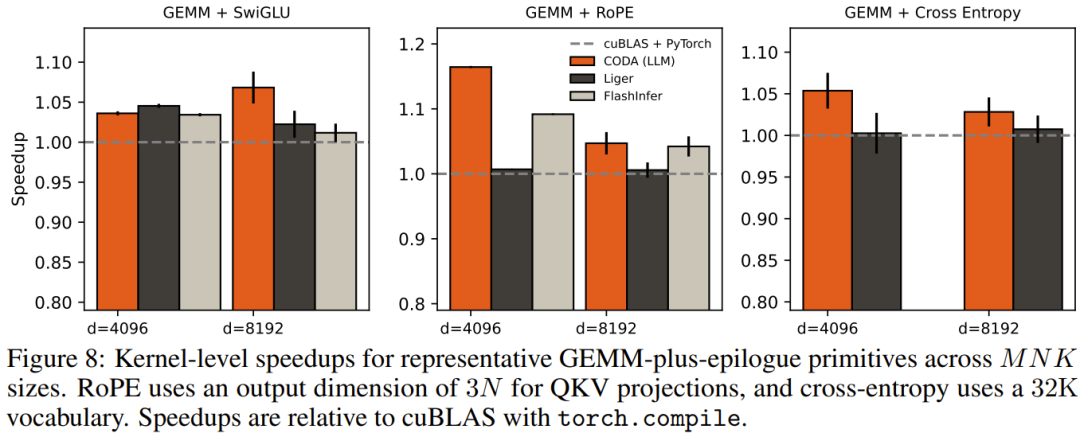
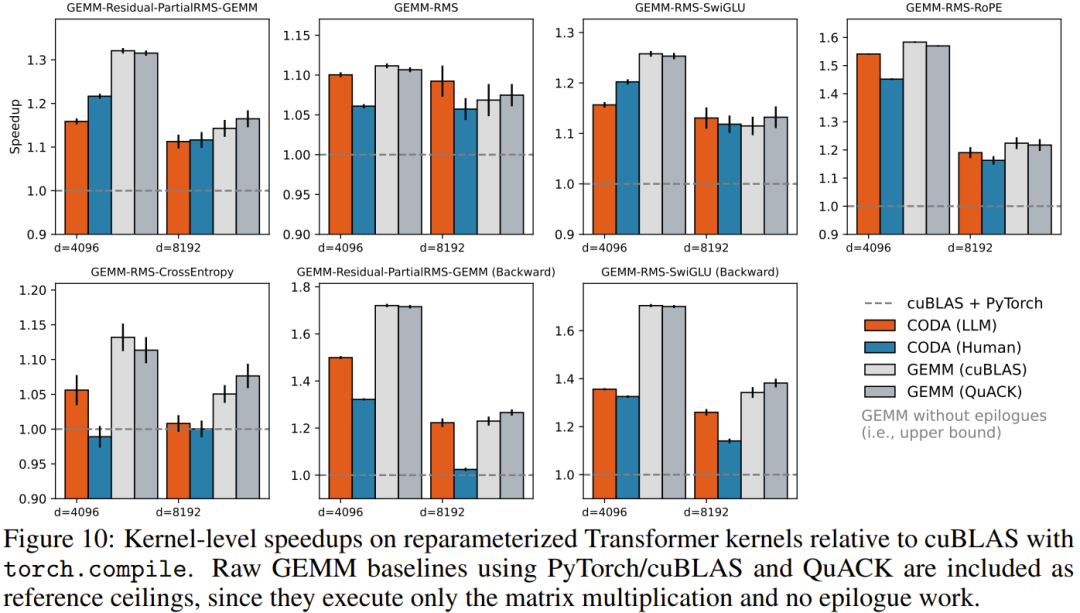
LLM 生成的内核在大多数基准上与人工手写版本不相上下,个别配置下甚至略有超越。这在 GPU 内核优化这个历来门槛极高的领域,是一个颇为罕见的结论。
反向传播的收益尤为突出:GEMM-Residual-PartialRMS-GEMM 的反向内核相比基线加速幅度可达 1.6 至 1.8 倍,SwiGLU 反向也有约 1.4 至 1.6 倍的提升。这个方向上,LLM 与人工实现的差距同样微小。这并不奇怪:反向传播天然涉及更多中间张量的存取,尾声融合的收益就更大;而 CODA 的原语设计足够清晰,使得 AI 模型能够正确地完成组合。
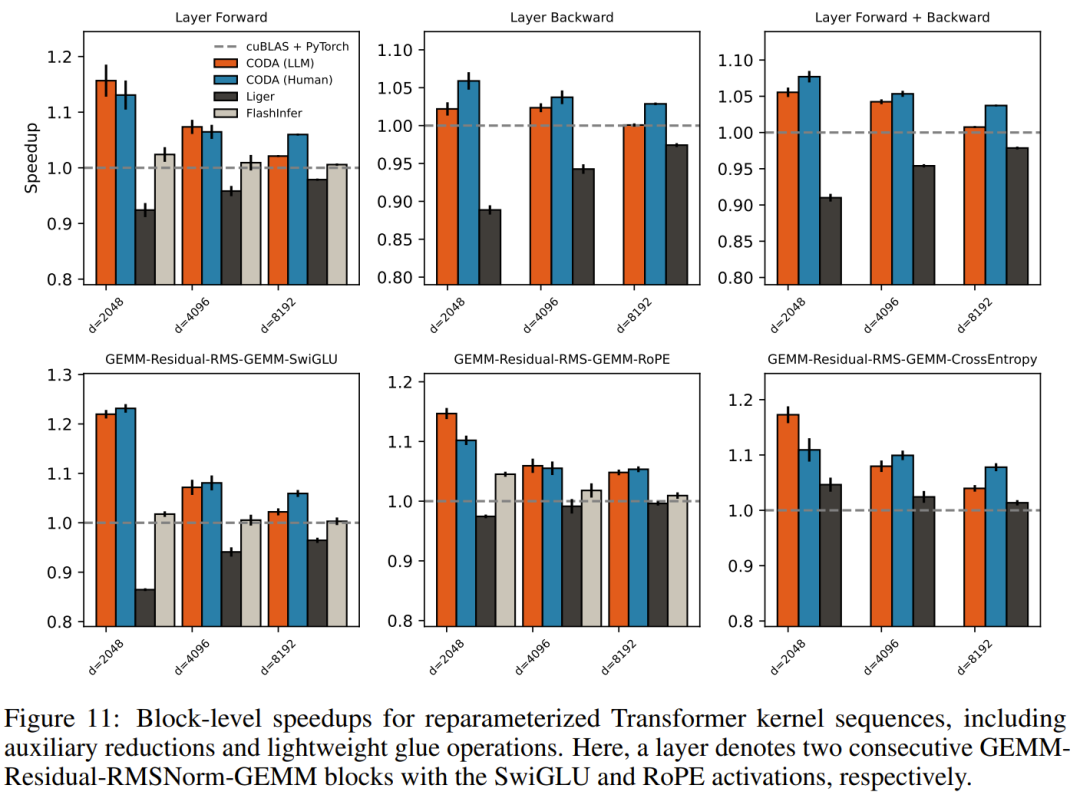
在完整 Transformer 层的端到端基准中,CODA 的前向加速在不同规模下约为 5% 至 20%,在较大模型尺寸(对应 70B 规模的隐藏维度)下效果更为显著。
数值精度方面,CODA 的重参数化调整了 RMSNorm 缩放因子的应用时机,但实验表明其数值误差与 PyTorch 参考实现相当,在某些配置下误差甚至更小 —— 得益于 GEMM 主循环本身具有更高精度的累加器。
CODA 能做什么:一张速查单
在进入更大的视角之前,先把 CODA 的能力边界说清楚。
- 覆盖范围:标准 Transformer(如 LLaMA 架构)的前向和反向传播中,除注意力和词嵌入之外的几乎全部计算,包括 RMSNorm、残差加法、SwiGLU 激活、RoPE 旋转位置编码、交叉熵损失,以及上述操作的反向梯度计算。
- 加速效果:在对应 1B 至 70B 规模的隐藏维度下,单算子层面相比 cuBLAS +
torch.compile 基线有不同程度的提升,其中反向传播收益最为显著(部分内核可达 1.6 倍以上);完整 Transformer 层的端到端前向加速约为 5% 至 20%,在较大模型尺寸下效果更突出。
- 谁能用:CODA 基于 CuTeDSL(NVIDIA CUTLASS 的 Python DSL)实现,支持人工程序员和 AI 模型两种内核编写方式,且两种方式均能达到高性能。
- 当前限制:目前仅支持单 GPU 场景,不涉及分布式训练;重参数化主要针对标准 Transformer 架构,其他架构的适用性有待验证。
结语
CODA 并非孤立的工作。它是一类思想的具体实现:在 GPU 上,真正的优化空间往往不在「算什么」,而在「怎么搬」。
FlashAttention 让注意力计算「住进」了片上内存,CODA 试图让归一化和激活函数也「住进去」。Triton 降低了写自定义内核的门槛,ThunderKittens、TileLang 等进一步在不同层次上探索这一空间。这些工作共同指向同一个方向:把 PyTorch 算子图的表达便利性,与接近手写 CUDA 的执行效率,真正统一在一套可编程的框架里。
Tri Dao 推文的最后一句话值得再回味:「LLM 以及新手就可以为所有 Transformer 操作编写光速内核。」这背后有一个更深的逻辑:当编程抽象设计得足够好,AI 模型本身就可以参与到自身训练基础设施的优化中。这个循环,才是 CODA 最耐人寻味的地方。
从这个角度看,「CODA」这个名字或许另有深意。在古典音乐中,Coda 是乐曲末尾收束全篇的段落。在这里,它是 GEMM 内核的「尾声」—— 而写好这段尾声,或许正是 Transformer 训练系统效率提升的下一个重要章节。
对前沿技术的探索与讨论,总能激发更多灵感。在云栈社区,我们同样关注并交流这些推动行业进步的关键技术,欢迎你一同来聊聊。
 发表于 2026-5-25 03:35:07
|
查看: 134|
回复: 0
发表于 2026-5-25 03:35:07
|
查看: 134|
回复: 0
