明明是精心拍摄的照片,回看却发现被烦人的明暗条纹毁了?这种在人造光源下常见的“频闪”伪影,现在终于有了更彻底的解决方案。
论文: It Takes Two: A Duet of Periodicity and Directionality for Burst Flicker Removal
核心创新点
- 提出 Flickerformer 框架,首次将频闪的 物理先验(周期性与方向性)融入 Transformer,实现高质量去频闪,同时避免引入鬼影。
- 设计 周期性建模 二重奏:相位融合模块 (PFM) 利用帧间相位相关性对齐并融合特征;自相关前馈网络 (AFFN) 则增强帧内的重复结构。
- 首创 方向性建模 利器:小波方向注意力 (WDAM),巧妙借助小波高频分量指导低频区域的修复,精准定位并消除条纹伪影。
- 实现 SOTA 性能,在公开基准测试中,PSNR 指标超越第二名 0.58 dB,且模型参数量仅为其 19.7%。

方法详解
整体结构概述
Flickerformer 的整体流程非常清晰。它接收一个包含三帧(一张基础帧,两张参考帧)的连拍序列作为输入。首先,相位融合模块 (PFM) 在频域中对齐并融合这三帧的特征。接着,融合后的特征被送入一个 U 型的编解码器主干网络。在编码阶段,自相关前馈网络 (AFFN) 负责提炼和增强特征中的周期性规律。在解码阶段,小波方向注意力模块 (WDAM) 则利用频闪的方向性特征,精准地修复受影响的区域。最终,网络预测出一个残差图,与原始基础帧相加,得到最终的无频闪图像。
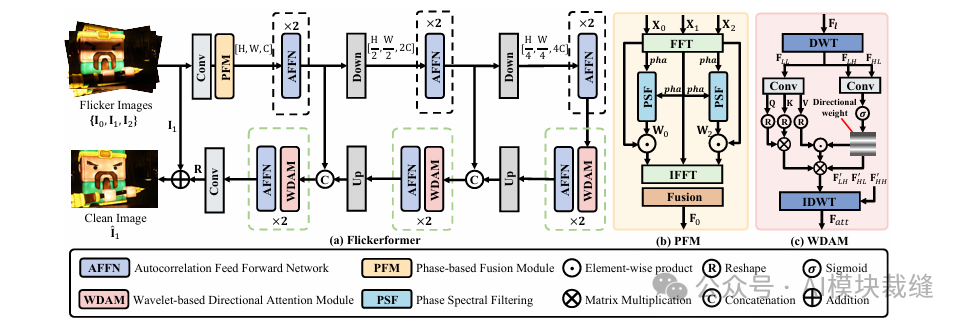
Figure 2 - Flickerformer 整体架构图
步骤分解
-
相位融合模块 (Phase-based Fusion Module, PFM) - 解决帧间对齐
-
自相关前馈网络 (Autocorrelation Feed-Forward Network, AFFN) - 增强帧内周期性
-
小波方向注意力 (Wavelet-based Directional Attention Module, WDAM) - 精准定位方向性条纹
- 功能说明: 频闪条纹通常是水平或垂直的,具有强烈的方向性。WDAM 巧妙地利用了 哈尔小波变换,将特征图分解为低频(内容)和高频(细节、边缘)部分。其中,高频部分(特别是水平和垂直分量)能天然地捕捉到频闪条纹。WDAM 利用这些高频信息生成一个“方向性权重”,指导注意力机制更关注低频图中受频闪影响的暗带区域,实现精准打击。
- 关键公式: 将水平(
$F_{LH}$)和垂直($F_{HL}$)高频分量融合,生成方向性权重图 $M$,并用它来调制注意力机制中的 Value 矩阵。
- 代码片段:
# WDAM 核心逻辑示意
from pytorch_wavelets import DWTForward
dwt = DWTForward(J=1, wave='haar', mode='zero')
# 1. 小波分解
F_LL, (F_LH, F_HL, F_HH) = dwt(feature)
# 2. 从高频分量生成方向性权重
directional_weight = self.conv(torch.cat([F_LH, F_HL], dim=1)).sigmoid()
# 3. 将权重应用到注意力计算中
attention_output = attention(query, key, value * directional_weight)
实验验证
主实验结果
| 方法 |
PSNR (↑) |
SSIM (↑) |
LPIPS (↓) |
参数量 (M) |
| Uformer |
30.544 |
0.910 |
0.056 |
18.12 |
| Restormer |
30.630 |
0.917 |
0.055 |
26.10 |
| AST |
30.646 |
0.918 |
0.050 |
19.90 |
| Flickerformer (Ours) |
31.226 |
0.920 |
0.045 |
3.92 |
Table 1 - 在BurstDeflicker数据集上的量化对比
关键发现:
- 性能全面领先:Flickerformer 在所有三项关键指标(PSNR, SSIM, LPIPS)上均取得了最佳成绩。
- 轻量高效:PSNR 值比当时最先进的 AST 模型高出 0.58 dB,但参数量仅有 3.92M,远低于其他动辄上千万参数的模型,展示了其卓越的效率。
消融实验
| 配置 |
CNN |
PFM |
FRFNN |
AFFN |
ASSA |
MDAM |
PSNR ↑ |
SSIM ↑ |
| (a) |
✓ |
|
✓ |
|
|
|
30.449 |
0.912 |
| (b) |
✓ |
✓ |
|
|
|
|
30.728 |
0.914 |
| (c) |
✓ |
|
|
✓ |
|
|
30.831 |
0.915 |
| (d) |
✓ |
|
|
|
✓ |
|
30.822 |
0.915 |
| (e) |
✓ |
✓ |
|
✓ |
|
✓ |
31.226 |
0.920 |
Table 4 - 核心模块消融实验结果
关键发现: 实验证明,PFM、AFFN 和 WDAM 三个创新模块都对最终性能有显著贡献。单独替换掉基线模型中的任何一个对应模块,都能带来 0.2 dB 到 0.3 dB 以上的提升,证明了这种基于物理先验的设计的有效性。
即插即用模块作用
适用场景
- 具体任务: 连拍图像去频闪、视频去频闪、高动态范围(HDR)成像中的伪影去除。
- 行业场景: 智能手机摄影(尤其在室内、夜景等人工照明环境下)、专业影视制作、安防监控、自动驾驶(摄像头在 LED 交通灯下的数据清洗)。
- 使用门槛: 作为一个完整的网络,可以直接用于端到端的去频闪任务。其核心模块设计思想也可被借鉴,用于改进其他图像/视频复原网络。
主要作用
- 更彻底的频闪去除: 通过对频闪物理特性的精准建模,Flickerformer 能够去除以往方法难以处理的顽固和微弱频闪,图像更干净。PSNR 达到 31.226 dB。
- 动态场景无鬼影: PFM 模块的相位融合机制,确保了即使在物体运动的场景下,多帧融合也不会产生模糊或重影,细节保留完好。
- 轻量化与高效率: 模型参数仅 3.92M,计算量(128.76 GFLOPs)也远低于同类 SOTA 模型,更易于部署到手机等移动设备上。
接入示例(重要)
# 假设你已经有了预训练好的Flickerformer模型
import torch
# 初始化模型
model = Flickerformer()
model.load_state_dict(torch.load('flickerformer.pth'))
model.eval()
# 准备输入数据:一个包含三帧的burst,shape为(1, 3, 3, H, W)
# burst_images: [frame0, frame1, frame2], frame1是需要被修复的基础帧
input_tensor = preprocess(burst_images)
# 推理
with torch.no_grad():
output_tensor = model(input_tensor)
# 后处理得到无频闪图像
flicker_free_image = postprocess(output_tensor)
对于追求极致画质和高效计算的研究者而言,这种将物理先验融入 Transformer 架构的设计思路,无疑为低层视觉任务开辟了新的方向。 |  发表于 2026-4-25 08:41:00
|
查看: 113|
回复: 0
发表于 2026-4-25 08:41:00
|
查看: 113|
回复: 0
