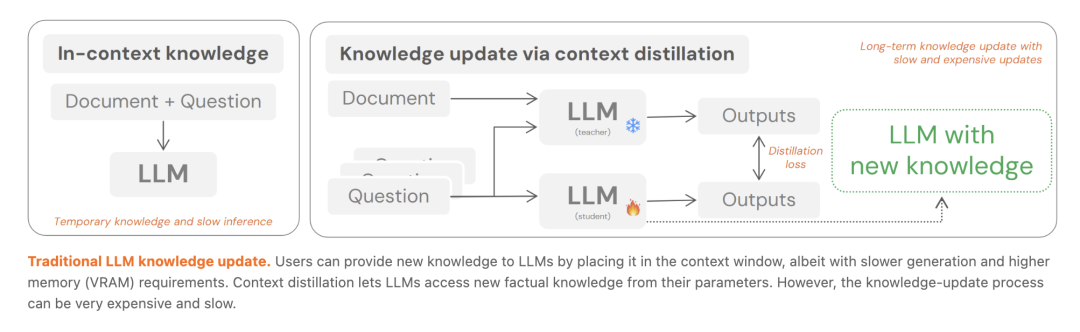
面对十万乃至百万级别的超长序列输入,Transformer 架构中呈二次方增长的注意力计算与 KV-Cache 显存占用,始终是大规模部署中难以逾越的系统瓶颈。与此同时,为了使基础模型在未见的垂直领域任务中表现优异,构建包含数据清洗、超参数搜索与梯度迭代的监督微调流水线,同样带来了极其高昂的算力消耗与时间延迟。
为了打破长上下文与任务微调的双重壁垒, Sakana AI 近期在两篇核心论文中,提出了一种全新的工程范式——更新成本摊销(Cost Amortization)。该框架的核心思想,是将昂贵的权重更新与上下文处理开销,前置转移至元训练阶段的超网络中。如此一来,模型在最终的推理部署阶段彻底告别了缓慢的梯度反向传播,仅需通过一次极低延迟的单次前向传播,即可动态生成完全适配目标任务或长篇文档的 LoRA 权重。
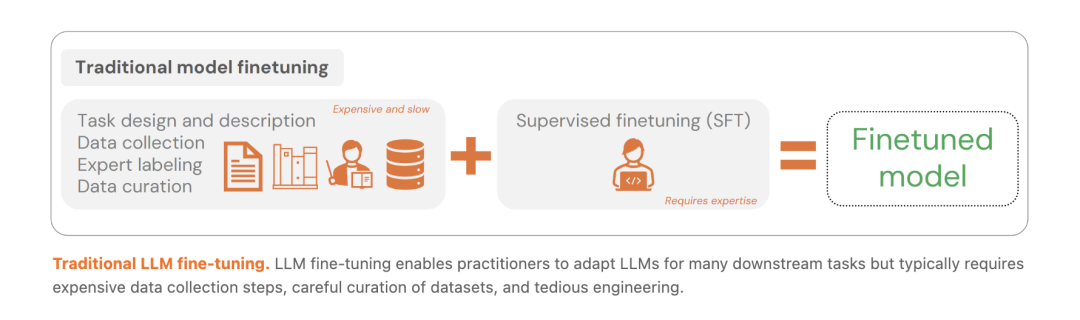
01. Doc-to-LoRA:突破原生窗口的显存控制

论文标题:Doc-to-LoRA: Learning to Instantly Internalize Contexts
论文链接:https://arxiv.org/abs/2602.15902
代码链接:https://github.com/SakanaAI/doc-to-lora
传统上下文蒸馏能够将文档知识内化为模型参数,其核心优化目标是通过最小化 KL 散度来实现知识转移:
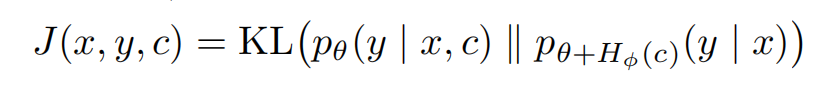
公式:$J(x, y, c) = KL(p_\theta(y | x, c) || p_{\theta+H_\phi(c)}(y | x))$
但每次处理新文档都需重新计算梯度,不仅耗时,在并发处理时更会吞噬海量显存。Doc-to-LoRA 采用基于 Perceiver 架构的超网络,直接接收变长文档的 token 激活值,将其映射为固定维度的隐状态,最终解码为大语言模型所需的 LoRA 矩阵。
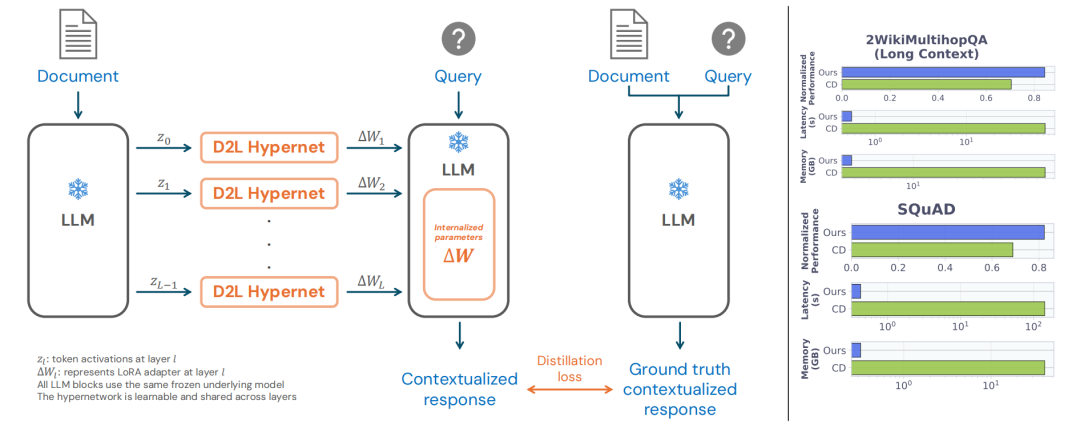
面对超出原生窗口的超长文档,Doc-to-LoRA 引入了分块组合机制。系统将超长文档序列切分为 K 个固定长度的独立文本块。超网络分别为每个文本块独立生成对应的低秩矩阵 $A_k$ 与 $B_k$。
原论文中标准的 LoRA 权重更新公式定义为:
$W' = W + \Delta W = W + BA$,其中 $B \in \mathbb{R}^{d \times r}$,$A \in \mathbb{R}^{r \times k}$,r 为设定的秩。
在分块机制下,生成的多个适配器在秩维度(Rank dimension)进行水平与垂直拼接。最终注入大模型的组合权重等效为:
$W' = W + [B_1, B_2, ..., B_K] \begin{bmatrix} A_1 \\ A_2 \\ ... \\ A_K \end{bmatrix}$
拼接后的有效秩规模线性扩展为 $r_{total} = K \times r$。该机制在不改变超网络输出张量形状的前提下,实现了对极长文本的无限拓展内化。

实测数据对比显著:处理 128K token 级别长文本时,原生大模型需额外占用超 12GB 的 KV-Cache 推理显存,而 Doc-to-LoRA 内化后的推理显存增量稳定在 50MB 以内。
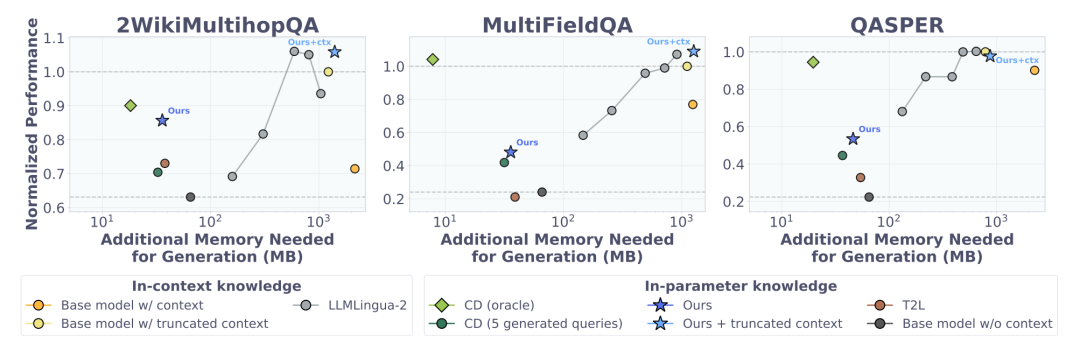
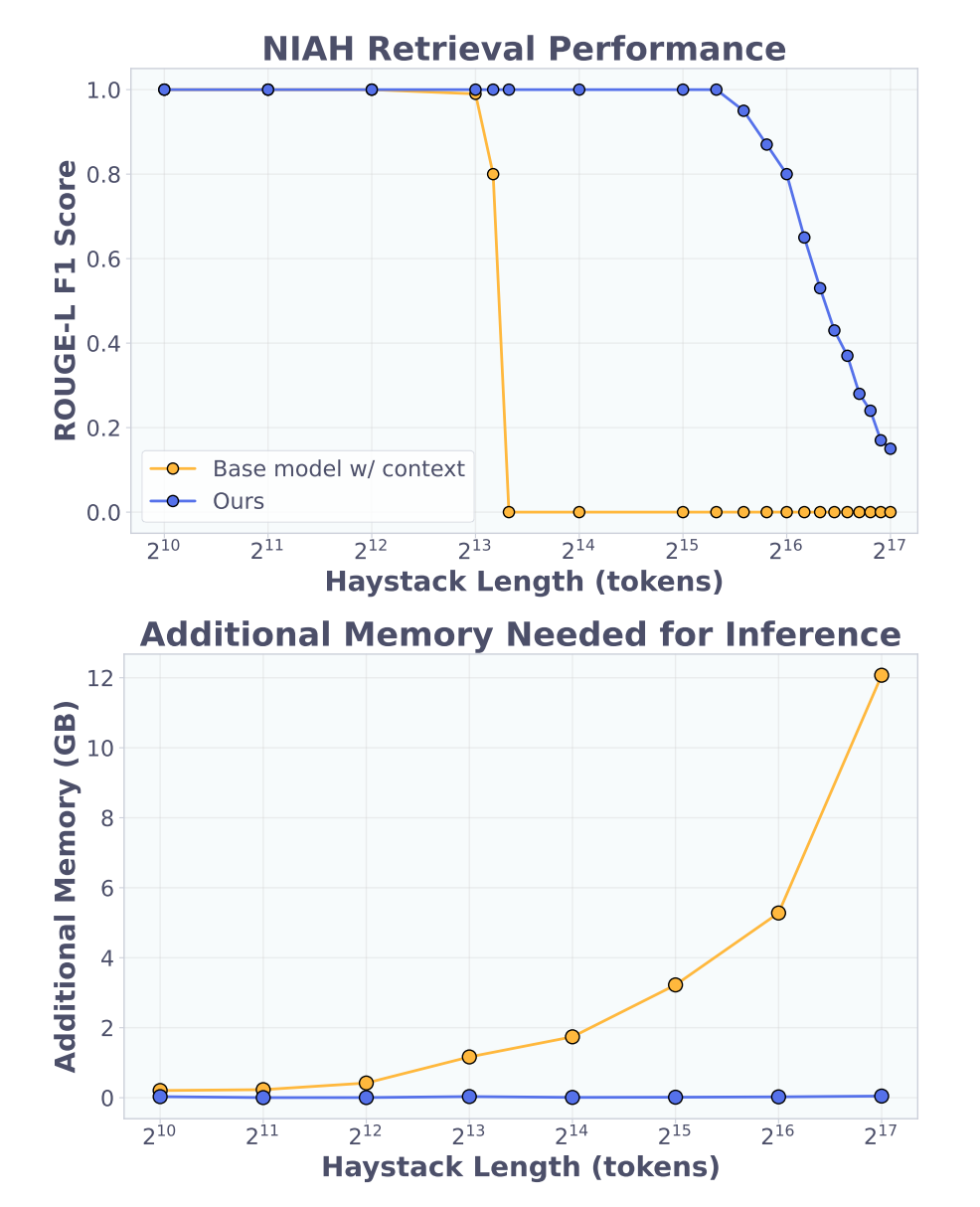
Doc-to-LoRA 论文的量化数据表明,在 2WikiMultihopQA 长文档问答任务中,相比传统上下文蒸馏生成 5 个 Query 所需的高达 79.3GB 的更新期显存,D2L(Iterative)将其大幅压缩至 3.79GB,并实现了亚秒级的更新延迟。
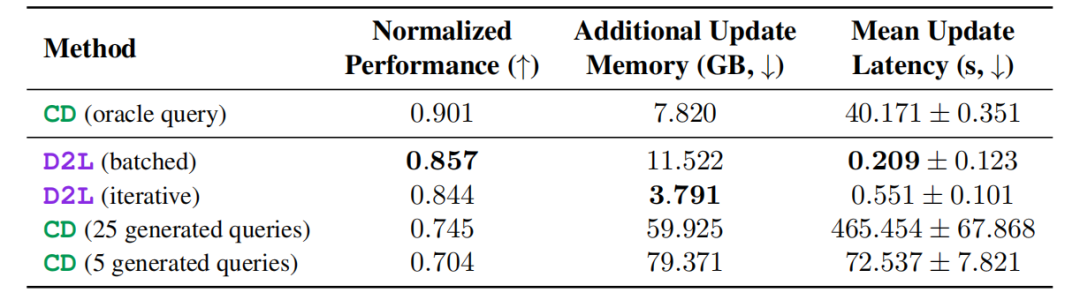
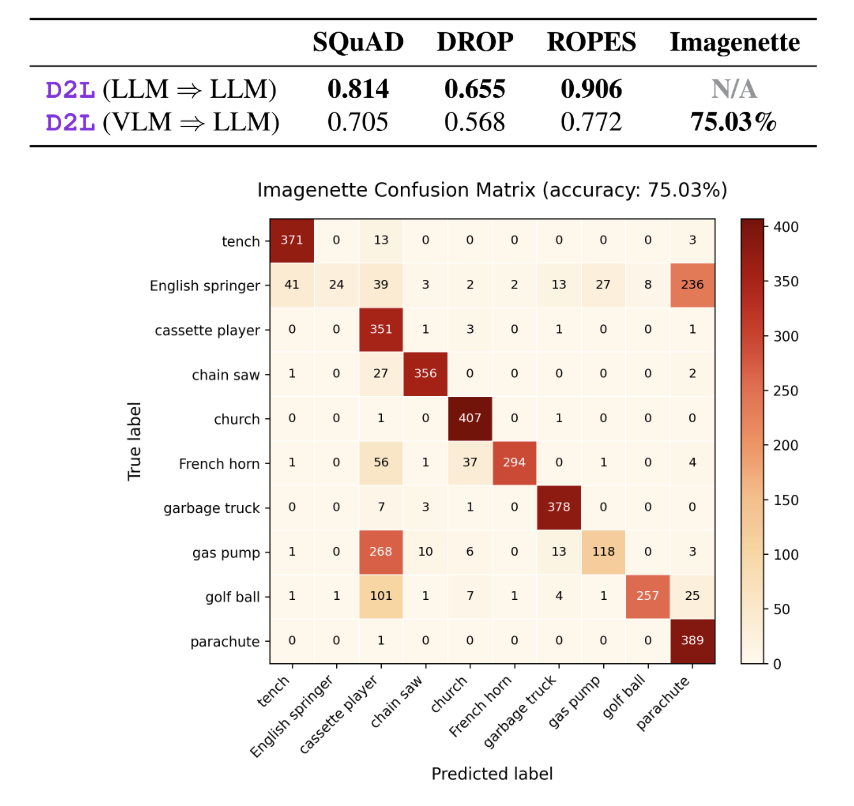
在 SQuAD 短文本问答评测中,Doc-to-LoRA 成功实现了知识内化,达到了上下文学习性能上界的 82.5% 相对性能。
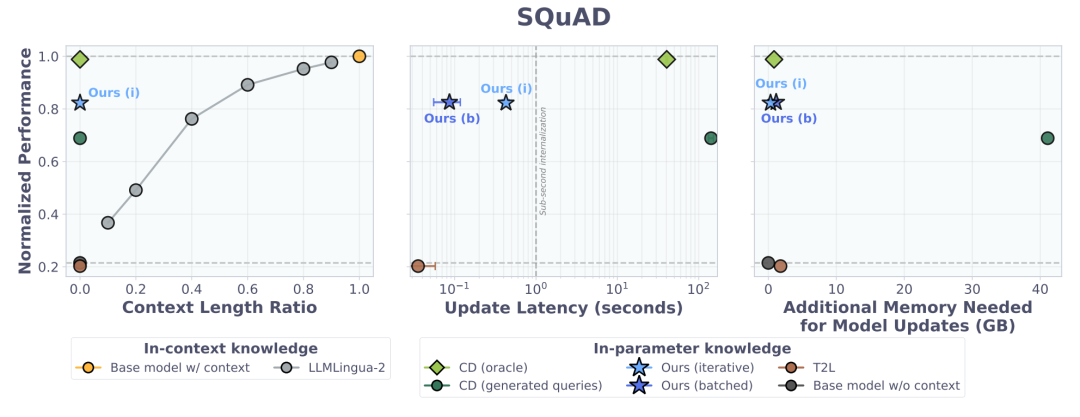
大海捞针极限泛化测试进一步验证了其架构能力。仅使用最大长度 256 tokens 的短文本片段训练出的超网络,能够在测试阶段零样本泛化至超40K tokens 长度的长文本,保持极高的检索准确率。
更为极端的零样本 Query 内化测试反转了内化对象,将 Document 留在上下文中,让超网络去内化未见过的 Query。结果表明,即便在训练期仅见过文档内化,D2L 依然能够成功内化 Query 特征并展现出优于基线的召回率,证明了其底层的泛化鲁棒性。
跨模态零样本迁移展现了该架构作为模态桥梁的潜力。在预训练阶段,超网络与纯文本大模型均未接收过图像数据。推理时,仅凭接收视觉语言模型提取的视觉激活值,超网络便直接为纯文本模型生成了具备视觉分类能力的 LoRA 权重,在 ImageNette 数据集上取得了 75.03% 的分类准确率。
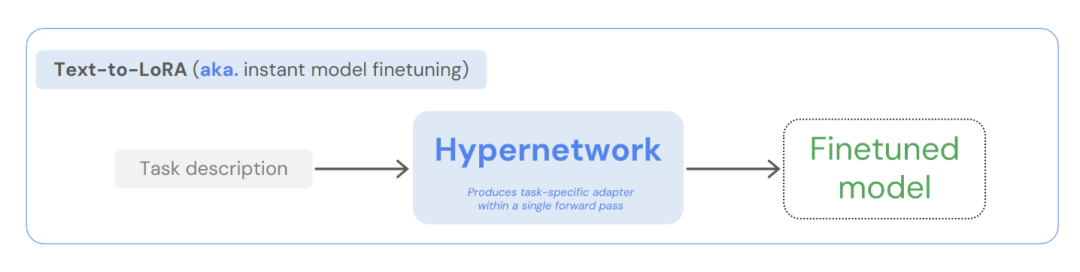
02. Text-to-LoRA:意图直达的零样本任务适配

论文标题:Text-to-LoRA: Instant Transformer Adaption
论文链接:http://arxiv.org/abs/2506.06105
代码链接:https://github.com/SakanaAI/text-to-lora
Text-to-LoRA 彻底颠覆了传统的任务自适应微调流水线。仅需输入一段关于目标任务的自然语言描述,提取其 embedding 特征后,超网络即可在单次前向传播中,直接输出大模型 attention 层所需的低秩矩阵参数。
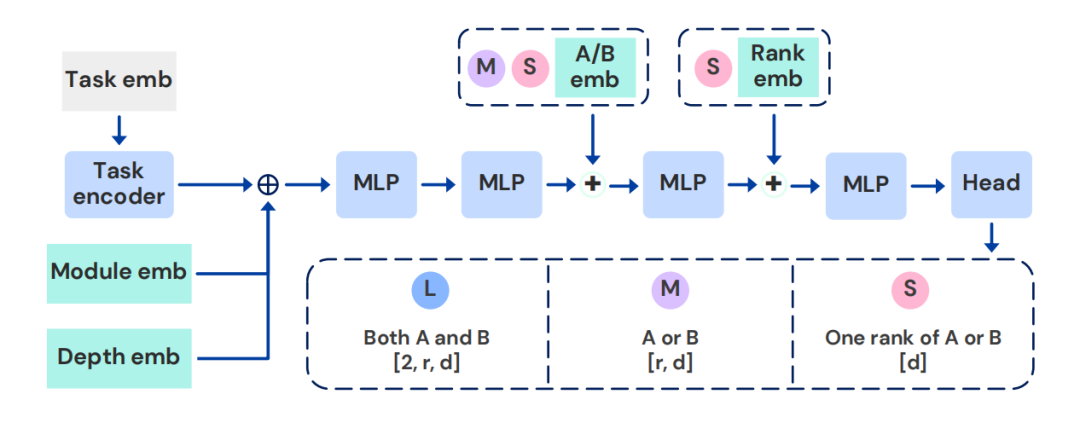
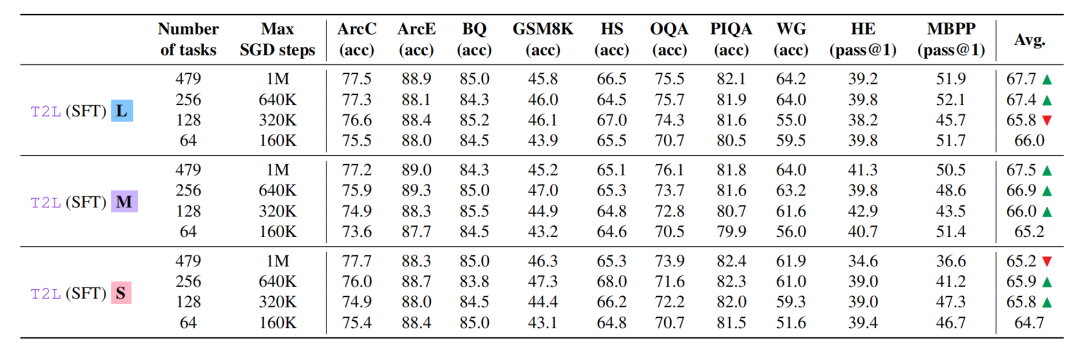
为适配不同的算力预算,Text-to-LoRA 构建了三种复杂度的超网络变体:生成完整 A 与 B 矩阵的大型架构(L)、使用共享特征投影的中型架构(M),以及高度压缩输出头的小型架构(S)。
该系统提供两种训练范式。第一种为重构模式。超网络充当有损压缩器,拟合已有的任务特定 LoRA 库。优化目标为最小化超网络输出 $h_\theta(\phi^i)$ 与目标适配器权重 $\Delta W^i$ 之间的 L1 绝对值误差:
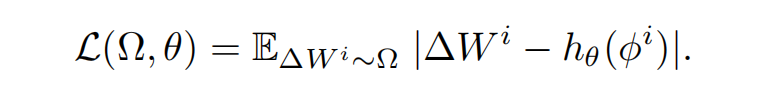
公式:$\mathcal{L}(\Omega, \theta) = \mathbb{E}_{\Delta W^i \sim \Omega} |\Delta W^i - h_\theta(\phi^i)|.$
有损压缩自带的正则化效应,使得生成的参数在部分评测基准上甚至反超原版特定任务 LoRA。当强制将越来越多的任务压缩进同一超网络时,平均训练 L1 误差必然上升,目标 LoRA 的相对性能保留度也随之下降。
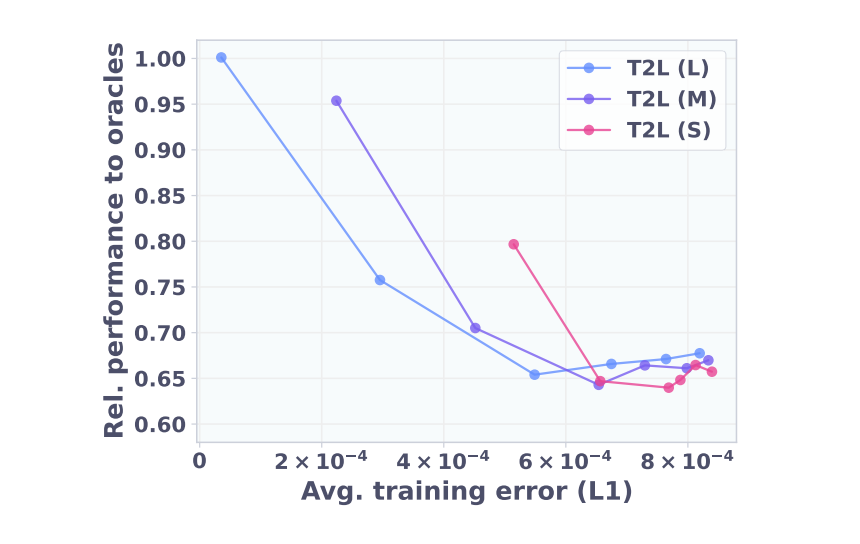
重构模式为何难以实现零样本泛化?论文附录的参数空间余弦相似度揭示了底层机制,尽管某些 LoRA 适配器在功能上高度相似,但它们在底层的参数空间中并不相邻。由于目标适配器缺乏良好的聚类特性,导致重构模式下的有损压缩无法直接泛化到未见任务。
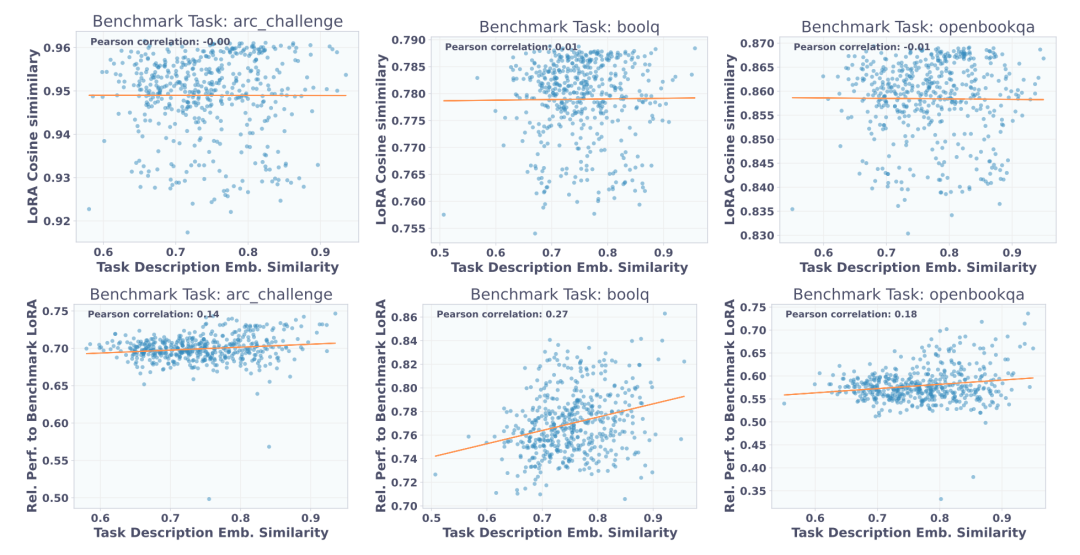
第二种 SFT 端到端模式打破了这一局限。该模式不依赖中间目标参数,直接基于 479 个多任务数据集进行优化。其正式的数学优化目标为:
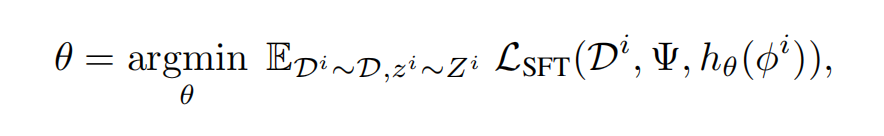
公式:$\theta = \arg\min_\theta \mathbb{E}_{D^i \sim \mathcal{D}, z^i \sim Z^i} \mathcal{L}_{\text{SFT}}(D^i, \Psi, h_\theta(\phi^i))$
模型在训练中隐式学习了任务簇分布特征。依据论文的核心数据,Text-to-LoRA 在零样本任务自适应性能上以显著优势击败了 Multi-task LoRA 等基线方法。
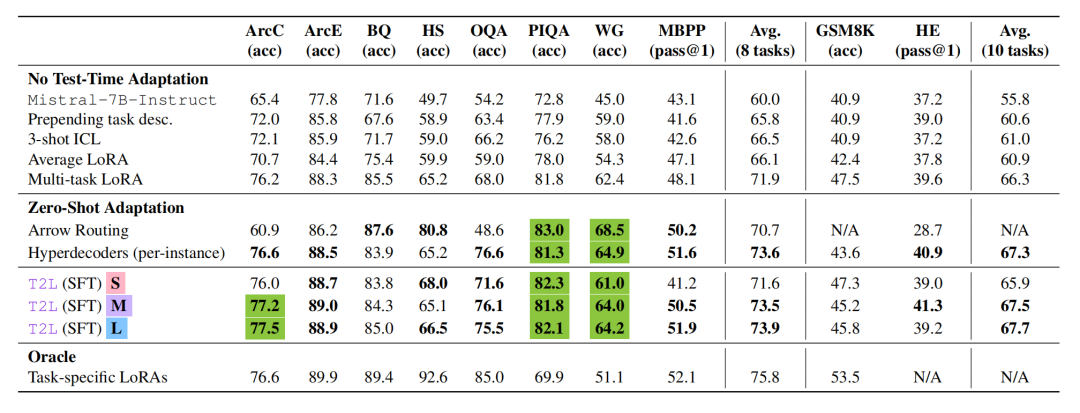
消融实验证实了该架构完美契合 Scaling Laws——增加训练任务数量与计算预算,其泛化性能稳定攀升。
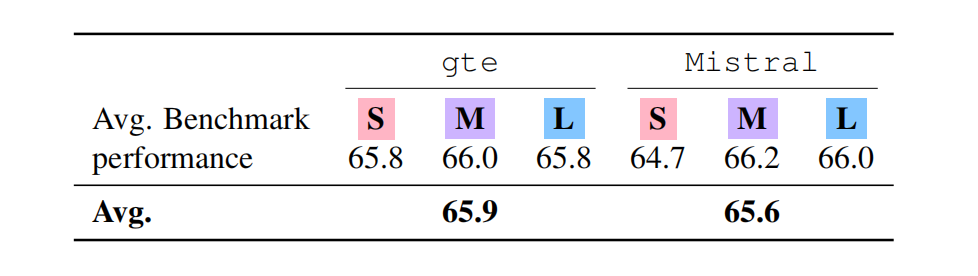
此外,消融实验表明,即使更换底层的文本 embedding 模型,Text-to-LoRA 依然维持着稳定的自适应性能。
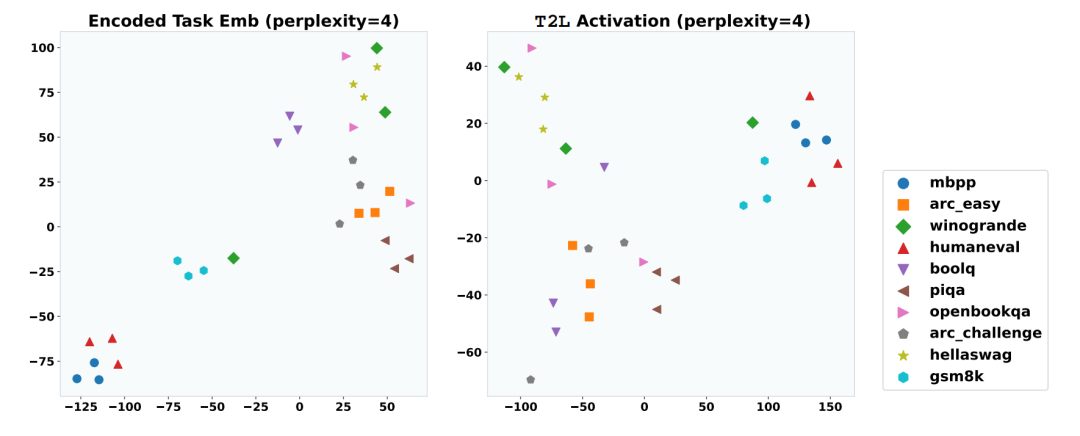
需要注意的是,系统高度依赖对齐且高质量的任务描述,输入未对齐描述会导致生成的 LoRA 适配器性能大幅衰减。
强大的内部表示能力直接赋予了模型极高的指令可控性。面对同一道 GSM8K 数学题,只需在 prompt 中稍微改变侧重点,超网络就会实时输出不同的 LoRA 权重,精准引导基础模型改变底层的解题推理路径。

03. 结语
无论是突破窗口限制的 Doc-to-LoRA,还是实现零样本自适应的 Text-to-LoRA,其底层逻辑高度一致:将沉重的梯度微调与海量上下文加载,降维成单次亚秒级的前向推理。这一工程范式的确立,不仅是一次显存与算力的释放,更为下一代 AI Agent 铺平了道路。未来的智能体完全有能力在后台瞬时生成、挂载专属的记忆适配器,实现真正意义上的零延迟知识内化与跨任务持续学习。对于关注此类前沿工程实践的开发者,欢迎在云栈社区 的人工智能与开源实战板块交流更多想法。
参考文献
[1] Nguyen, T. T., Ryoo, M. S., & Ha, D. (2026). Doc-to-LoRA: Instant Internalization of Long Documents into LoRA Adapters. arXiv preprint arXiv:2602.15902v1.
[2] Ryoo, M. S., Nguyen, T. T., & Ha, D. (2025). Text-to-LoRA: Zero-Shot Task Adaptation of Large Language Models via Hypernetworks. arXiv preprint arXiv:2506.06105v2.
[3] Instant LLM Updates with Doc-to-LoRA and Text-to-LoRA. https://sakana.ai/instant-llm-updates/
 发表于 2026-3-10 11:53:46
|
查看: 129|
回复: 0
发表于 2026-3-10 11:53:46
|
查看: 129|
回复: 0
