最近面壁智能联合 OpenBMB 开源社区、清华大学 THUNLP 实验室和 THUMAI 实验室,正式发布了 MiniCPM-o 4.5 技术报告,首次公开其核心——Omni-Flow 流式全模态框架。
Model 用例展示:
https://openbmb.github.io/minicpm-o-4_5-omni/
在线体验(无需注册/下载):
https://minicpmo45.modelbest.cn/
技术报告:
https://github.com/OpenBMB/MiniCPM-o/blob/main/docs/MiniCPM_o_45_technical_report.pdf
在报告发布的同时,MiniCPM-o 4.5 同步推出在线体验 Demo、全模态全双工 API、端侧安装包 Comni 和 Demo 仓库。
在线体验 Demo
在线 Demo 是 MiniCPM-o 4.5 的原型示例网页应用,展现传统轮次、语音双工、视频双工三类交互原型,完整开放模型全量配置(含 prompt 与参考音频)。Demo 支持手机/电脑端访问,并提供排队、录制、保存、分享、回看等功能,体验很流畅。
在线体验(手机端推荐):
https://minicpmo45.modelbest.cn/mobile/
在线体验(电脑端推荐):
https://minicpmo45.modelbest.cn/
全模态全双工 API
同步开放的 API 支持全模态全双工实时交互,全双工下无需 VAD 控制轮次,方便开发者基于 MiniCPM-o 4.5 快速构建应用。API 使用 https://api.modelbest.cn/minicpmo45/v1/ 端点,目前免费开放。
API 文档:
https://api.modelbest.cn/minicpmo45/docs
Windows / macOS 端侧安装包 Comni
MiniCPM-o 4.5 已基于 llama.cpp 完成量化与推理优化,实测 12GB 显存的 RTX 5070 即可流畅运行全双工模式(RTF 0.4),极大拉低了本地部署门槛。桌面软件 Comni 集成了模型下载、环境安装与 Demo 运行,提供 Windows / macOS 版本。在电脑启动本地服务后,除了在浏览器中使用,强烈建议用手机通过局域网连接进行全双工视频通话。
| 平台 |
下载链接 |
硬件要求 |
| Windows |
GitHub:Comni-Setup-win64.exe
ModelScope:Comni-Windows-x64.exe |
12GB+ 显存 GPU,如 RTX 5070 / RTX 5080 / RTX 5090 / RTX 4090 |
| macOS |
GitHub:Comni-macOS-arm64.dmg
ModelScope:Comni-macOS-arm64.dmg |
M1-M5 Max / M5 Pro,建议内存 16GB 以上 |
(上方视频展示了 MiniCPM-o 4.5 在个人笔记本上的完整部署与运行过程,包括全双工语音对话、实时视觉理解、主动提醒等能力演示)
Demo 仓库开源与 Linux 部署
Demo 全栈代码已开源,Linux 用户可克隆仓库并部署完整 Demo 服务,这也是首批可本地部署的全双工全模态交互演示项目之一。
Demo GitHub 仓库:
https://github.com/OpenBMB/MiniCPM-o-Demo
为什么「全双工」是 AI 交互的下一站?
人类的交流是流畅、并行的——我们边听边想,甚至可以随时打断对方。
但在此之前,AI 的交互模式本质上是「半双工」,像对讲机:你说完它才处理,它说话时又听不到你的新指令。这种不同频让大部分用户难以获得良好体验,甚至因为「时空割裂」逐渐失去耐心。长此以往,多模态场景的落地必然受阻。
MiniCPM-o 4.5 在全球范围内首创「全双工全模态」:模型在持续感知环境(看视频、听声音)的同时进行思考与响应,让 AI 从被动工具进化为能主动帮助人类的真正助手。
这背后离不开面壁智能与清华共同研发的 Omni-Flow 流式全模态框架。其核心思路是创建一个共享「时间轴」——把视觉、音频、语言等信息流对齐到毫秒级时间片上,模型在每个极短的时间片内完成一次「感知-思考-响应」循环。这套机制从底层赋予了模型持续感知与即时反应的能力,是实现全双工的基石。
此外,MiniCPM-o 4.5 坚持开源且可本地部署的 Web Demo,对开发者与用户意味着:
- 绝对的隐私安全:全天候陪伴式 AI 会接触大量敏感信息,数据不出本地就是最好的隐私保护。
- 断网也能跑的可靠性:即使隧道、野外也无妨,你的 AI 助手不会「掉线」。
- 开发者的游乐场:完整的前后端代码已开源。你可以基于此快速构建自己的全双工多模态应用——无论是智能座舱、无障碍辅助还是具身智能,MiniCPM-o 4.5 都能成为把想象变成现实的助推器。
技术报告深度解读:揭秘 MiniCPM-o 4.5 的实现之道
MiniCPM-o 4.5 采用端到端全模态架构,总参数 9B,核心设计包括:
- 全模态端到端架构:多模态编码器/语音解码器与 LLM 通过隐藏状态紧密连接,在高压缩率下实现通用视觉、听觉感知与语音对话。
- 时分复用机制:将并行多模态流划分为周期性时间片内的顺序信息组,实现高效流式处理。
- 可配置语音建模:支持文本+音频双系统提示,通过参考音频和角色提示词即可实现声音克隆与角色扮演。
- 双模式支持:同一模型同时兼容传统轮次交互与 Omni-Flow 全模态全双工模式。
实时交互:Omni-Flow 流式全模态框架
传统多模态模型把交互视为孤立回合,Omni-Flow 则将其重塑为一个连续过程。
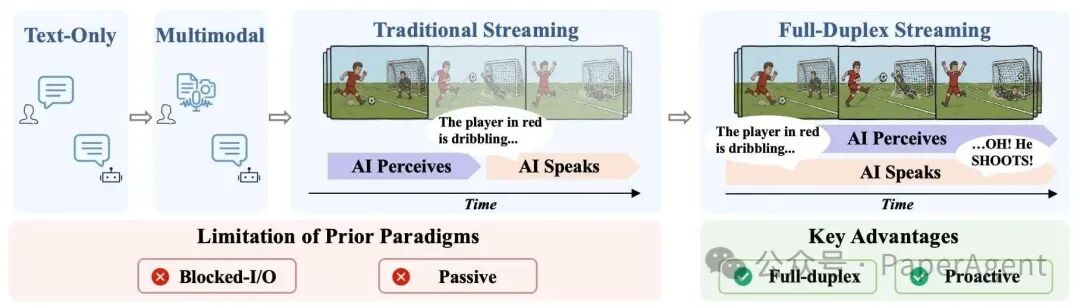
图1:交互范式的演进,MiniCPM-o 4.5 实现了最右侧的全双工流式交互
如图所示,Omni-Flow 将视觉、音频输入流与文本、语音输出流在时间上精确切片并对齐。模型不再被动等待用户输入完成,而是以极高频率(例如每秒一次)持续刷新「世界观」,自主决定何时介入(说话或提醒)。这套机制原生支持打断、插话等高级行为,彻底摆脱对外部 VAD 的依赖。
端到端架构:9B 模型如何协同工作?
为实现 Omni-Flow,团队设计了一套高效的端到端全模态架构,总参数 9B。
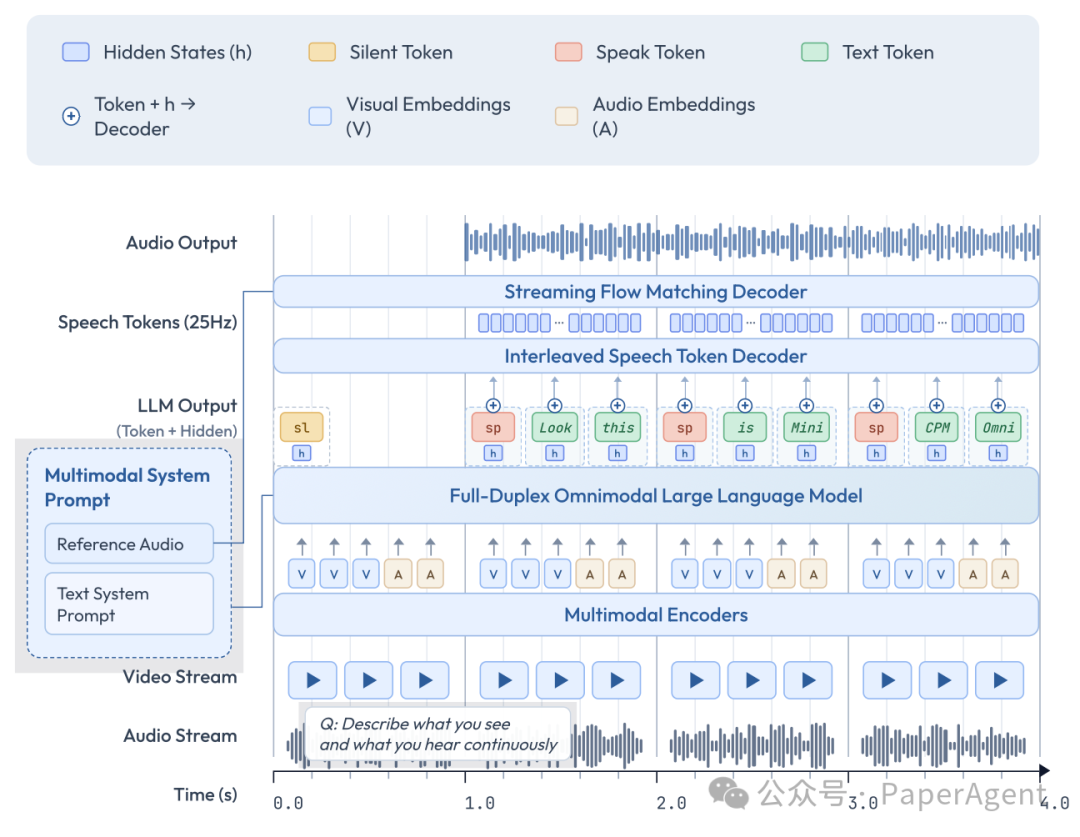
图2:MiniCPM-o 4.5 的端到端全模态架构
核心组件:
- 视觉编码器(0.4B):SigLIP-ViT,负责「看」。
- 音频编码器(0.3B):Whisper-Medium,负责「听」。
- LLM 基座(8B):Qwen3-8B,负责「思考」与理解。
- 语音 Token 解码器(0.3B):轻量级 Llama 架构,负责将 LLM 的「想法」(文本)转化为语音单元。
- 声码器:将语音单元合成为最终波形。
设计上最巧妙的一点是:LLM 基座只生成文本 Token,而把专业语音合成任务「外包」给更小更专业的语音解码器。这样既避免让大模型直接处理复杂声学任务,又保证了核心语言推理能力不受损害。各模块通过 token 级稠密连接,确保了模型能力的上限。
为实时而生:TAIL 语音生成方案
流式语音的一大难题是延迟。为了让语音听起来自然,模型通常需要「预读」一大段文本,但这会导致语音输出远远滞后于用户输入——在全双工场景里这是致命缺陷。
为此团队提出了 TAIL(Time-Aligned Interleaving)方案,让每个语音块的生成都紧跟对应文本块,而不是让文本「抢跑」太多。同时通过轻量级「预读」(pre-look) 机制解决跨词发音连贯性问题。最终 TAIL 在保证音频流畅悦耳的同时,将语音输出与交互发生的延迟降到最低。
云栈社区的技术文档板块中也有大量关于模型架构与工程实践的深度解析,对这类端侧部署方案感兴趣的可以进一步查阅。
性能表现:9B 模型硬刚业界顶尖
参数小不等于性能弱。MiniCPM-o 4.5 在多维度评测中展现了与 SOTA 掰手腕的实力。
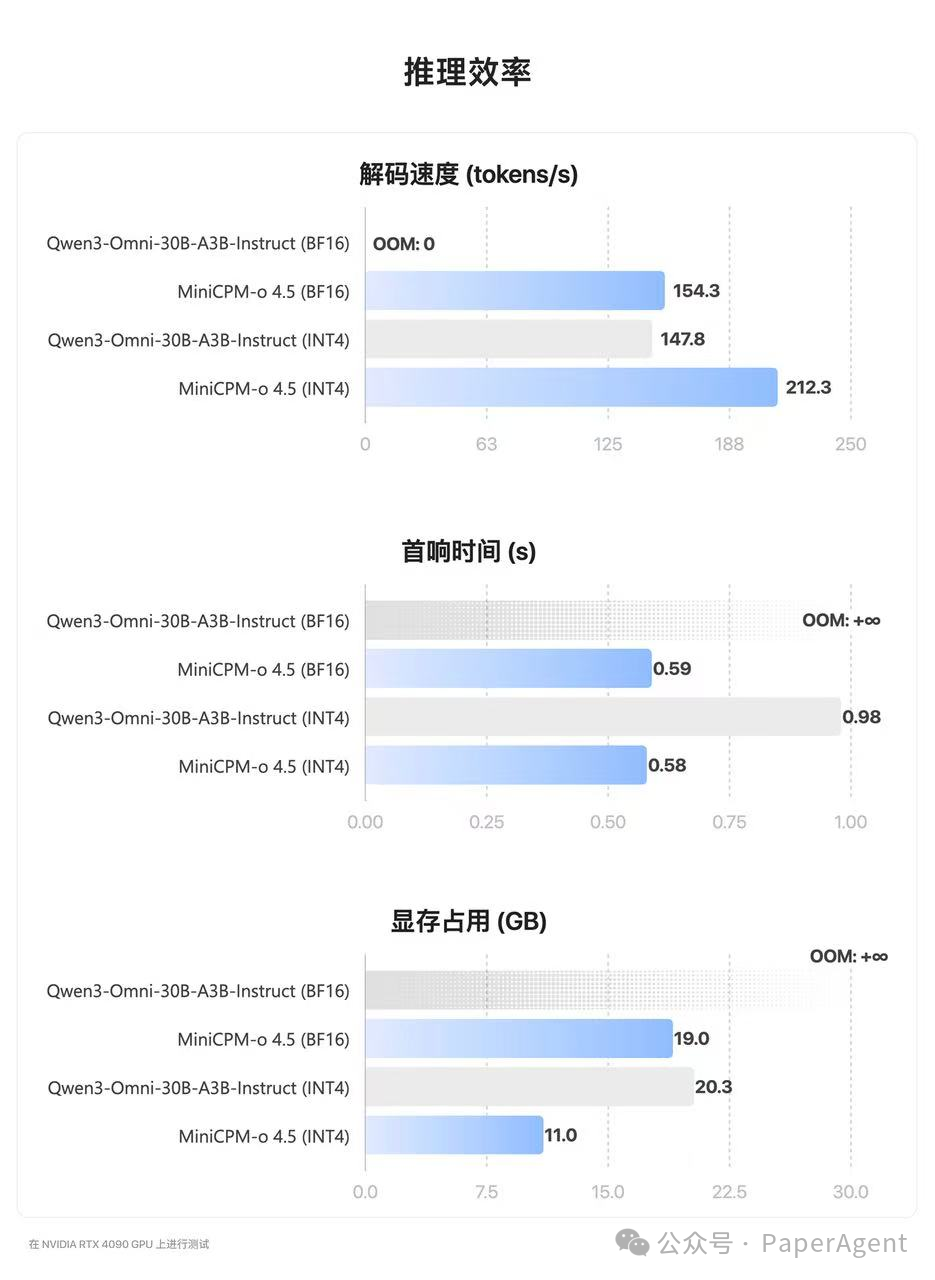
推理效率:INT4 量化版仅需 11GB 显存,几乎是 Qwen3-Omni INT4 版本的一半,消费级显卡本地部署成为可能。解码速度方面,INT4 版本达到 212 tokens/s,比 Qwen3 快 40% 以上,响应延迟更低。
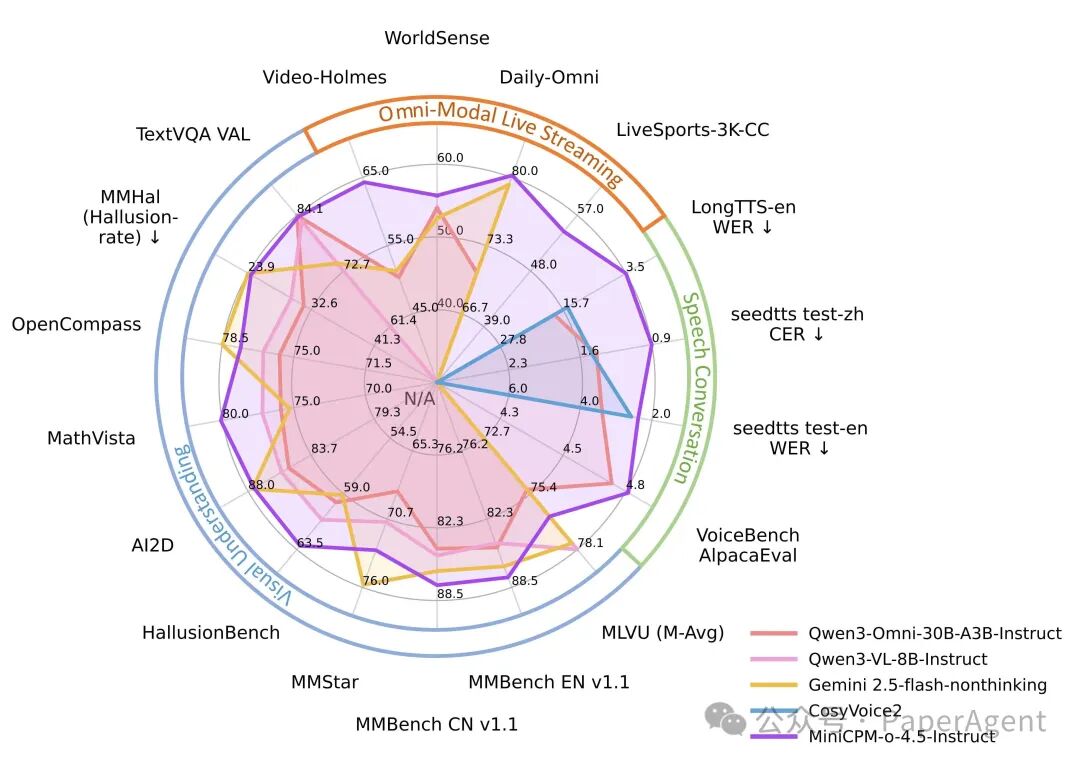
综合视觉能力:在 OpenCompass、MMBench 等多个视觉基准上,9B 的 MiniCPM-o 4.5 与 Gemini 2.5 Flash 表现相当。
| Benchmark |
MiniCPM-o 4.5 (9B) |
Gemini 2.5 Flash |
Qwen3-Omni-30B-A3B |
| OpenCompass |
77.6 |
78.5 |
75.7 |
| MMBench EN v1.1 |
87.6 |
86.6 |
84.9 |
| MathVista |
80.1 |
75.3 |
75.9 |
| HallusionBench |
63.2 |
59.1 |
59.7 |
全模态与全双工交互:在需要联合音视频理解的基准上,MiniCPM-o 4.5 全面超越 Gemini 2.5 Flash 和 Qwen3-Omni。在全双工视频理解基准 LiveSports-3K-CC 上,胜率(54.4%)更大幅领先专用流式视频模型。
| Benchmark |
MiniCPM-o 4.5 |
Gemini-2.5-Flash |
Qwen3-Omni-30B |
| Daily-Omni |
80.2 |
79.3 |
70.7 |
| Video-Holmes |
64.29 |
51.3 |
50.4 |
| LiveSports-3K-CC (Win Rate) |
54.4% |
– |
– |
语音生成:无论中英文,MiniCPM-o 4.5 的语音生成质量(字符/单词错误率更低)和情感表现力都优于 Qwen3-Omni 和业界领先的 CosyVoice2。
| Benchmark |
MiniCPM-o 4.5 |
CosyVoice2 |
Qwen3-Omni-30B |
| SeedTTS Test-ZH (CER↓) |
0.86 |
1.45 |
1.41 |
| SeedTTS Test-EN (WER↓) |
2.38 |
2.57 |
3.39 |
| Expresso (Emotion↑) |
29.8 |
17.9 |
– |
真·全双工,潜力无限
全双工全模态不是遥远概念,而是会催生一系列全新应用:
- 主动式伴侣:烹饪、修理、运动时,给你实时指导与提醒。
- 无障碍辅助:成为视障人士的「眼睛」,持续观察环境,主动播报绿灯亮起、水杯将满等关键信息。
- 智能座舱:持续监控路况与驾驶员状态,主动提示「左侧有可用车位」并引导泊车。
- 具身智能:作为机器人的「大脑」,持续感知动态环境并自主决策交互时机。
这些场景的共同点是:需求并非一次性问答,而是需要 AI 作为「沉默的观察者」和「及时的提醒者」融入动态生活流——这正是传统轮次对话模型无法胜任的。
MiniCPM-o 4.5 是原生全双工模型,摆脱了对 VAD 的依赖。这意味着:支持 general 声音感知(环境噪音、音乐等,不仅是语音);画面变化跟进更快(原生全双工,无需等上句说完);AI 说话时可被实时引导改变内容。
当然,MiniCPM-o 4.5 目前还存在提升空间,如长时交互稳定性、主动行为丰富性等。多模态智能的下一个前沿,不仅在于能力的扩展,更在于重新思考智能表达的交互范式。Omni-Flow 和 MiniCPM-o 4.5 是面壁智能在这一方向上的重要探索。
开放与协作将持续推动人机交互演进。欢迎所有开发者试用模型、参与讨论、贡献代码,共同探索人机交互的未来。想了解最新的模型部署实践与评测分析,可以留意云栈社区上的相关讨论。
➤ 技术报告 PDF:
https://github.com/OpenBMB/MiniCPM-o/blob/main/docs/MiniCPM_o_45_technical_report.pdf
➤ 在线体验:
https://minicpmo45.modelbest.cn/
➤ 在线体验(手机端推荐):
https://minicpmo45.modelbest.cn/mobile/
➤ GitHub Demo(含本地安装包):
https://github.com/OpenBMB/MiniCPM-o-Demo
➤ Hugging Face 下载链接:
https://huggingface.co/openbmb/MiniCPM-o-4_5
➤ ModelScope 下载链接:
https://www.modelscope.cn/models/OpenBMB/MiniCPM-o-4_5
 发表于 2026-4-29 03:59:02
|
查看: 424|
回复: 0
发表于 2026-4-29 03:59:02
|
查看: 424|
回复: 0
