随着多模态大模型能力的不断拓展,语音大模型(SpeechLLMs)已从基础的语音识别走向更为复杂的语音交互。
然而,当模型逐渐进入真实的口语交互场景时,一个更基础的问题浮现出来:我们是否真正定义清楚了「语音理解」的能力边界?
在自然口语交流中,“理解”远不止于将声音转写成文字。语言意义的构建,不仅依赖于“说了什么”(what was said),更依赖于“怎么说”(how it was said),以及说话人在特定语境下“真正想表达什么”(what was truly meant)。语调、重音、停顿、语速变化、情绪表达等副语言现象,往往是决定说话者真实意图的关键。
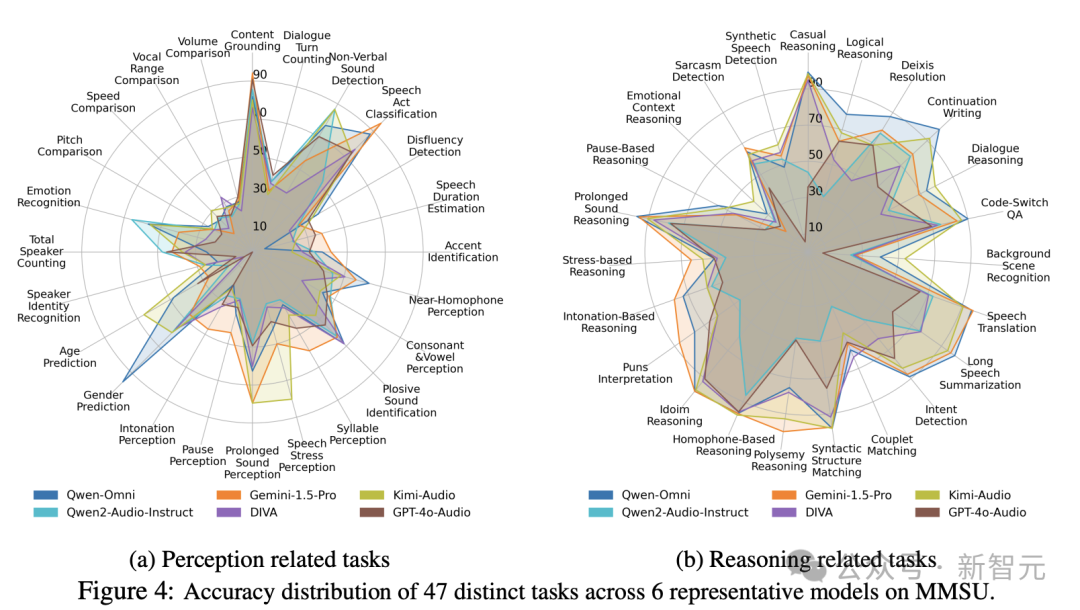
为此,来自香港中文大学的研究团队提出了MMSU(Massive Multi-task Spoken Language Understanding and Reasoning Benchmark)。这是一个覆盖47个子任务、包含5000道选择题的综合性语音理解评测基准。它旨在从语言学结构出发,系统刻画SpeechLLMs在多层次语言现象下的感知与推理能力,为语音理解能力建立一个可分析、可诊断、可比较的统一坐标体系。

论文链接:https://arxiv.org/pdf/2506.04779
数据链接:https://huggingface.co/datasets/ddwang2000/MMSU
项目主页:https://github.com/dingdongwang/MMSU
重新审视语音理解的评测边界
与其问「模型准确率多少」,不如先问:我们是否测对了能力?
MMSU指出,当前语音评测主要存在三类关键缺口:
- 覆盖不足:大量真实口语现象尚未被系统纳入评估,包括自发性不流畅、反讽、非语言声音(如咳嗽、笑声)、重音转移、停顿结构、语调变化、拉长音以及语码转换等。这些看似细微的声学特征,往往承载着决定性的语用信息,是推断“言外之意”的关键线索。
- 数据真实性有限:许多现有基准依赖TTS合成语音,虽然便于控制变量,却难以还原真实交流中自然的表达波动与风格差异。
- 缺乏语言学理论支撑:语音理解的能力边界根植于语言学理论本身。音系学决定声音如何组织,语义学决定意义如何编码,而修辞与语用学则决定表达如何产生隐含含义。现有基准多以任务现象为单位,缺乏以语言学为根源的系统划分。MMSU尝试在理论层面定义语音理解的能力结构。
这些问题共同导致了评测结果与模型真实理解能力之间的结构性偏差。
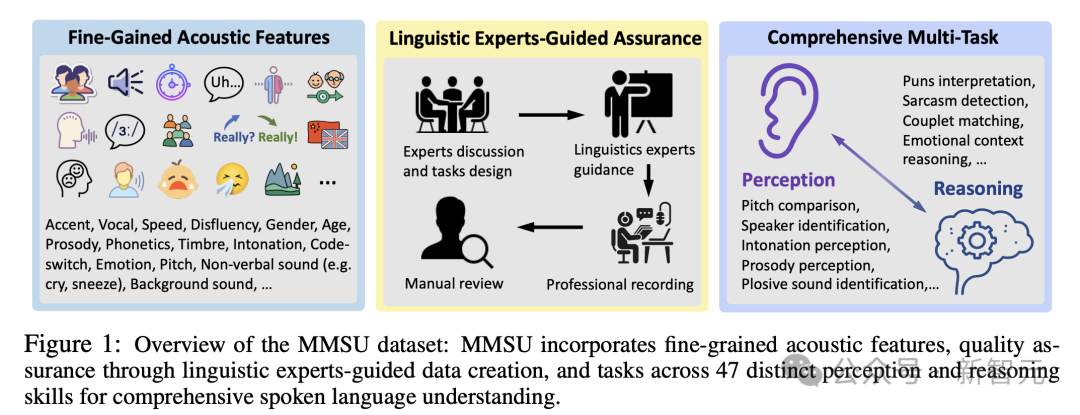
从「听见声音」到「理解语言」:语言学驱动的能力体系
在数据构建阶段,MMSU由语言学专家参与设计与审核,题目经过多轮严格筛选与一致性校验。除了收集真实音频,还结合了专业录音,使得关键语音现象(如重音转移、语调变化)能得到清晰呈现与可控对比。
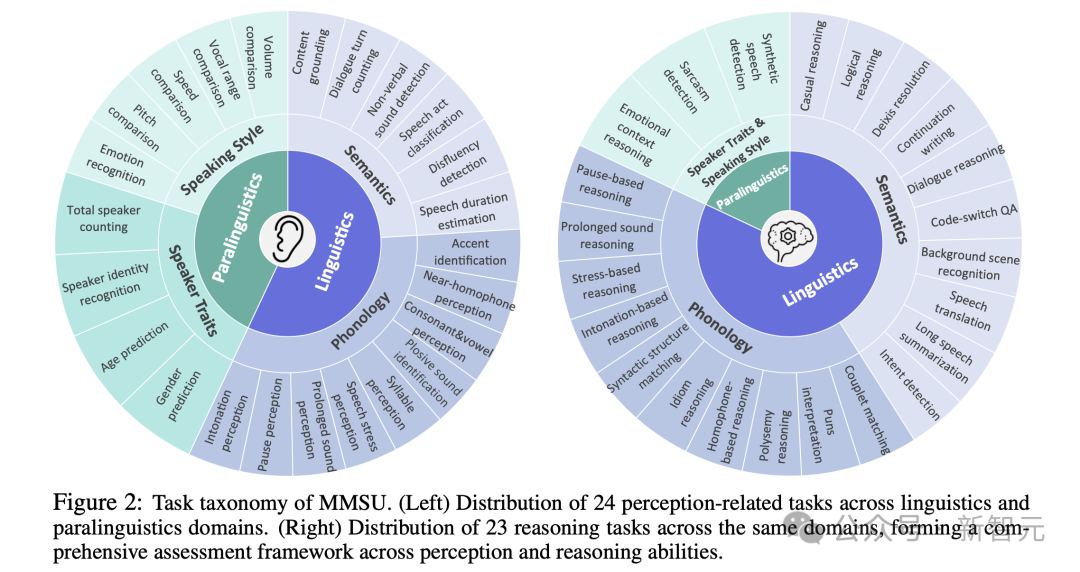
MMSU将语音理解拆解为三个层级,形成了一个结构化的能力框架:
第一层:感知 vs. 推理
- 感知:聚焦基础声学与语音特征识别,不依赖复杂推理。
- 推理:在感知基础上整合语义与语境信息,完成多步推断。
第二层:语言学 vs. 副语言学
- 语言学:涉及语言系统本身的结构与意义,包括语义、句法、音系与修辞现象。
- 副语言学:关注语言之外但影响理解的声学特征,如音高、音量、语速、情绪、停顿等。
第三层:理论分支
在前两层基础上,任务进一步细分为语义学、音系学、说话人特征和表达风格四个核心分支,系统覆盖了从“说了什么”、“怎么说”到“真正想表达什么”的完整评估链条。
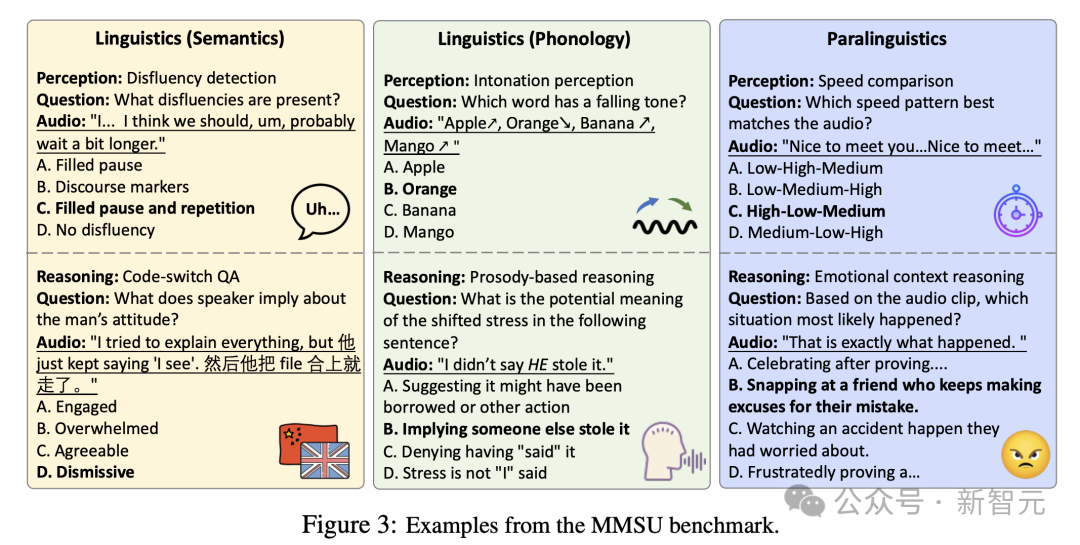
实验结果:模型离「真正听懂」还有多远?
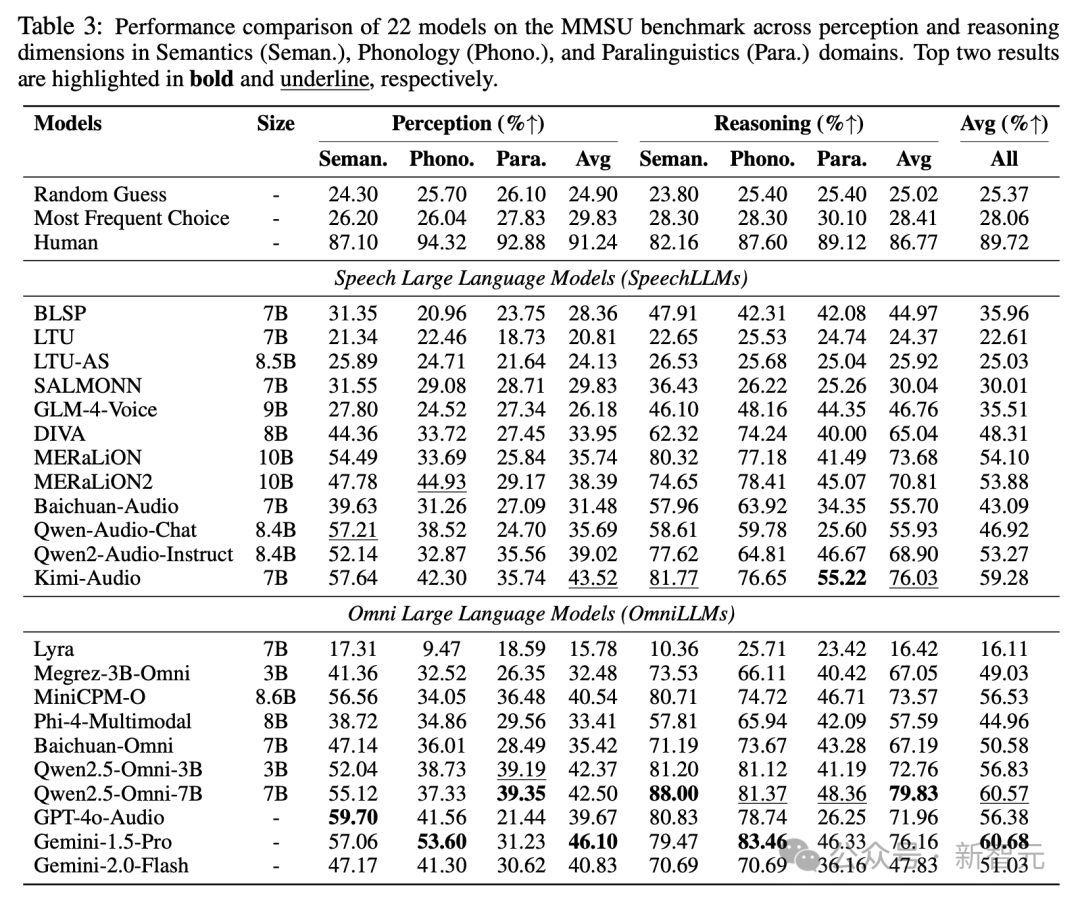
研究团队对22个先进的SpeechLLMs与OmniLLMs进行了系统评测。结果显示,人类参考水平为89.72%,而最佳模型(Gemini-1.5-Pro)得分仅为60.68%,差距接近30个百分点。
一个反直觉的现象是:对人类而言,推理任务通常更具挑战性;但对模型而言,基础的感知能力反而成了瓶颈,尤其是在音系相关能力上,模型存在系统性短板。这意味着,许多所谓的“推理错误”可能并非源于模型缺乏逻辑能力,而是在输入阶段就未能准确捕捉关键的声学线索。换言之,模型的“思考能力”或许被高估,而“听清能力”却被低估了。
结语:从「能听」到「听懂」
语音理解的难点,从来不在于识别字词,而在于理解完整的表达结构。意义并非仅由语义内容决定,还由声音形式与表达方式共同塑造。忽略语调、重音、停顿等声学线索,模型就无法完成真正的语用推断。
实验结果进一步表明,推理能力的上限取决于感知能力的下限。当模型在音系与细粒度声学特征上存在系统性短板时,再强的语言建模能力也难以弥补输入层的缺失。因此,语音理解是一个多层结构问题,要求模型同时解析语言内容、声音组织与表达风格。
MMSU所尝试构建的,正是一套结构化的能力标尺。它提醒我们,在追求更强大的深度学习模型时,必须正视并夯实其基础感知能力。在多模态模型走向真实交互的进程中,如何让AI真正“听懂”人话,仍是一个充满挑战的核心课题。
参考资料:https://arxiv.org/abs/2506.04779
 发表于 2026-3-3 05:03:25
|
查看: 119|
回复: 0
发表于 2026-3-3 05:03:25
|
查看: 119|
回复: 0
