前不久,《自然》主刊上的OpenScholar工作将“用AI做科学文献综述”的热度再次推高。它利用检索增强技术,在4500万篇开放获取论文上实现了引用准确度媲美人类专家的表现,相比之下,通用大模型在引用上的幻觉率往往高达78%–90% [1]。
使用AI大模型进行文献挖掘与综述已成为一个不可忽视的趋势。许多人都曾尝试使用ChatGPT或类似工具进行文献搜索和初步报告生成。但从个人实际体验来看,这些工具距离真正“能用”还有不小的差距。
借由这股讨论热潮,我们想介绍一项更早发表、专注于医学文献挖掘与系统综述的工作:2025年发表在《自然·通讯》上的LEADS(相比之下,OpenScholar更侧重于通用科学文献的问答,而LEADS则聚焦于医学系统综述这条更垂直、流程更固定的技术管线)。
LEADS,全称为Literature Evidence Assistant from Data and Studies,旨在实现人类与AI在医学文献搜索、筛选与研究数据提取中的协作 [2]。

与OpenScholar面向“开放科学文献 + 通用问答”的定位不同,LEADS专注于医学系统综述这条路线。其设计、训练与评估全程围绕专有领域数据和医学场景下固定不变的工作流展开,涵盖了从制定检索策略、进行纳入排除筛选,到关键数据提取的全过程。
本文将重点探讨三个核心问题:专有数据的关键作用、医学领域特定工作流的重要性,以及由此衍生出的研究动机与核心成果。
医学文献挖掘:为什么“通用模型 + 开放数据”不够?
在医学领域,文献挖掘,尤其是系统综述与meta分析,是循证医学的基石。其目的在于发现、整合并解读新的科学证据,用以更新临床指南,并支持制药企业与监管机构的决策制定。
在证据等级金字塔中,系统综述和meta分析位于顶端,代表经过严格筛选和综合的“已过滤信息”;其下方则是单个随机对照试验、队列研究等“未过滤信息”。高质量的文献挖掘与综述,直接关系到临床决策和药物研发的科学性与可靠性(见下图)。
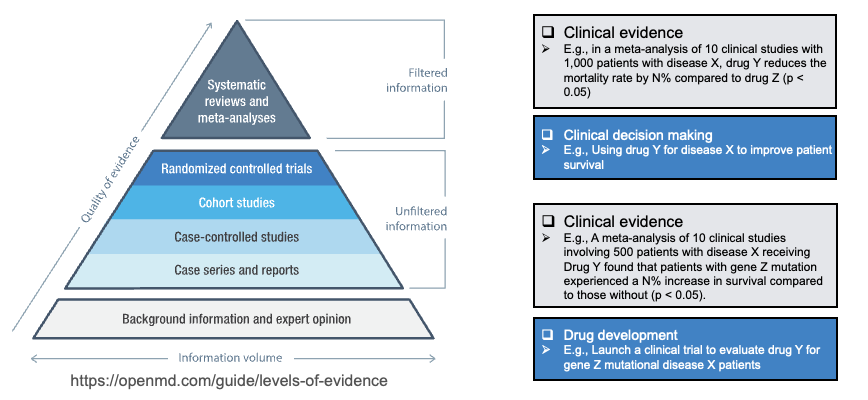
图1. 证据层级与临床应用:系统综述与 meta 分析位于证据金字塔顶端,支撑临床证据、临床决策与药物研发。
据估计,PubMed上每年发表超过5万篇系统综述 [3, 4]。然而,完成一篇系统综述从立项到发表平均需要67周以上 [5],顶尖研究机构和制药企业每年在此类工作上的投入高达数千万美元 [6]。
与此同时,文献数量正在爆炸式增长。例如,PubMed已索引超过3500万篇文献,且每年新增百万级条目。许多条目的元数据质量不高,导致检索精度难以保证 [7],进而引发综述工作中常见的检索不全、筛选偏差、数据提取错误等问题 [8]。
利用通用大模型(如GPT-4o)进行“检索 + 读文献 + 写综述”是一条潜在的解决路径,但目前面临几道关键障碍:
- 任务形态不同:医学系统综述拥有非常固定且严谨的流程:首先确定PICO框架,生成检索式,在PubMed、ClinicalTrials.gov等数据库检索 → 进行标题摘要初筛 → 全文精读筛选 → 数据提取(研究特征、试验分组设计、受试者人数、结局指标等)。这些步骤有明确的输入、输出和评估标准,远非“随意提问并生成一段带引用的答案”所能涵盖。
- 领域数据不可替代:真正能够教会模型“什么样的检索式能有效召回目标研究”、“什么样的研究符合纳入标准”、“如何从全文中准确提取PICO和结果数据”的知识,来源于大量已完成的系统综述及其引用的文献,以及结构化的临床试验注册数据。这类数据是专有的、经过高质量标注的,在开放的网页或通用语料库中几乎不存在。
- 人机协作才靠谱:文献综述对事实准确性和过程可追溯性要求极高,完全自动化容易产生幻觉、漏检或提取错误。更现实的路径是:利用AI加速检索、筛选与数据提取流程,最后由领域专家进行最终判断与修正。
因此,我们关心的不仅是“模型在单一任务上的指标表现”,更是“当专家借助LEADS一起工作时,能否在节省时间的同时,保持甚至提高召回率与准确率”。
我们的研究动机非常直接:在医学系统综述这条特定工作流上,利用高质量的领域专有数据,训练一个面向多个子任务的基础模型,并在人机协作的实际设定下验证其是否真能提升临床与科研人员的工作效率。
专有数据与LEADSInstruct:我们用了什么、怎么用
LEADS模型的训练与评估建立在系统综述、学术文献与临床试验的联动数据基础上:
- 来自PubMed的21,335篇系统综述;
- 这些综述所引用的453,625篇出版物;
- 其中8,485篇综述与27,015条ClinicalTrials.gov临床试验注册记录存在对应关系。
这些数据源自Cochrane、PubMed、ClinicalTrials.gov等权威来源。通过一套规范化的流程,从原始文献和试验报告中抽取并结构化,形成可用于训练和评估的表格与表单(例如研究特征表、试验臂设计表、结局数据表等)。
下图概括了构建这一“数据基础”的流程:从左侧的专有数据源,到右侧生成的结构化研究论文、数据提取表与临床试验数据表。
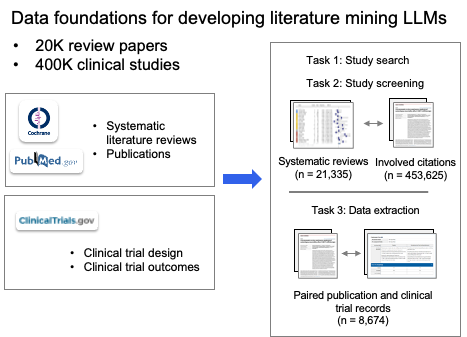
图2. LEADS的数据基础:从Cochrane、PubMed、ClinicalTrials.gov等专有数据源,经流程化处理得到结构化文献与数据表。
我们将系统综述方法学中最核心的三个环节——文献检索、纳入排除筛选、数据提取——拆解为六类具体子任务。利用上述数据,我们构建了包含约633,759条指令的LEADSInstruct数据集,涵盖了检索式生成、研究资格评估、研究特征提取、受试者人数统计、臂设计提取、试验结果提取等任务。
该数据集的规模与任务覆盖度,据我们所知是目前医学文献挖掘领域最大的指令级基准之一。简而言之,我们并非使用开放网页或通用语料进行“泛化阅读”训练,而是利用“综述作者已经做出的决策与标注”来反哺模型。在这里,专有数据直接决定了模型能否真正学会医学系统综述的“规则”与“细节”。
医学领域的workflow为什么值得单独建模
系统综述的流程是高度标准化的,通常使用PRISMA流程图来呈现:识别(检索与去重)→ 筛选(标题摘要筛选)→ 资格评估(全文评估)→ 纳入(定性/定量综合)。
下图展示了一个典型的PRISMA流程示例:从多个数据库检索获得数千篇文献,经过去重、标题摘要筛选、全文评估等步骤,最终纳入数十篇进行定性或定量综合。
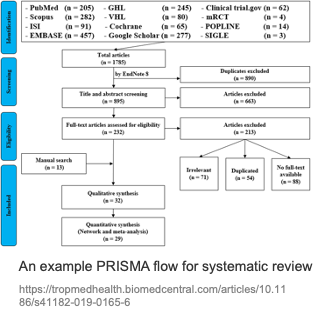
图3. 系统综述的典型 PRISMA 流程示例:从多库检索到定性/定量综合。
该流程在医学场景下的每一步都有具体细节:
- 检索:需要在PubMed和ClinicalTrials.gov上生成既能有效召回目标研究、又能控制无关噪音的检索式。
- 筛选:需要依据PICO框架和明确的纳入排除标准,对大量标题摘要进行快速且一致的判断。
- 数据提取:需要从全文中准确抽取出研究设计、人群特征、干预措施、对照设置、结局指标、效应量等,格式还需能够对接后续的meta分析软件。
传统上,这套流程极度依赖人力和时间。而人机协作的设想是:在关键环节引入AI智能体,由专家主导、AI加速,从而在保证质量的前提下,将“多名专家、耗时数十周”的工作量压缩到“约1名专家、约1周”的量级。
下图的左侧示意了这种AI增强的工作流(专家与多个AI智能体协作,产出研究问题与临床证据),右侧则是与之对应的完整PRISMA流程。
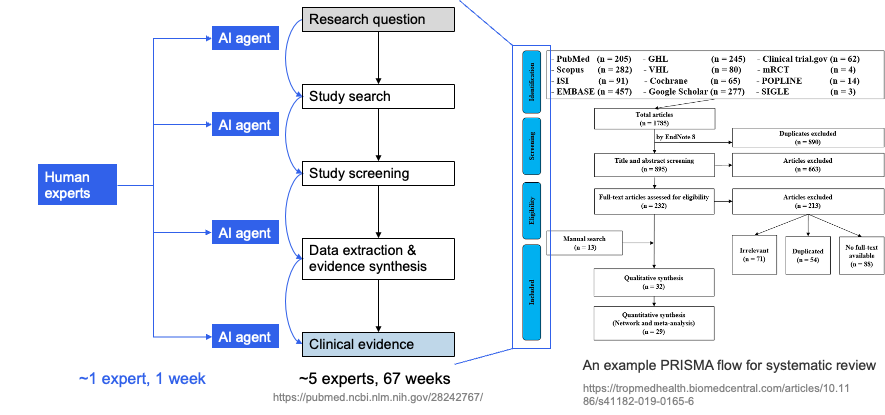
图4. 人机协作的 PRISMA 流程:左侧为专家与 AI agent 协作、约 1 专家 1 周的效率示意,右侧为完整 PRISMA 流程。
这些步骤环环相扣,单独优化“某一步”是不够的。模型需要在一套统一的框架下处理多个步骤,并且能适应不同主题的综述需求。这正是LEADS的设计思路:它将整条工作流显式拆分为六类子任务,使用同一套LEADSInstruct数据集进行指令微调,使得单个模型即具备处理多任务、应对多主题的能力,而无需为每个新的综述课题重新训练。
LEADS表现如何:全面超越通用LLM,且能真正省时提效
我们在数千篇系统综述、数十万篇研究文献上进行了离线评估,并与GPT-4o、GPT-3.5、Claude Haiku、Mistral、Llama以及医学领域模型BioMistral、MedAlpaca等进行了对比。同时,我们还进行了伪前瞻性评估(使用2025年后发表的31篇综述)以降低数据泄露的疑虑。
在离线任务层面(详见论文):LEADS在六类任务上的表现全面优于所有对比模型。
- 例如,在检索式生成任务上,LEADS的召回率比当时最好的基线模型进一步提升(出版物检索+3.76,临床试验检索+7.43)。
- 在筛选与各类数据提取任务上,LEADS的Recall@50或准确率也一致领先。
需要指出的是,仅以通用Mistral-7B为基座模型,在LEADSInstruct数据集上进行指令微调,其表现就显著超越了零样本设定的GPT-4o。这充分说明,高质量的领域指令数据本身就能极大提升模型在医学文献挖掘任务上的能力。
在人机协作层面,我们与来自14家机构的16位临床医生和医学研究者开展了用户研究,对比了“仅专家”与“专家+LEADS”两种工作模式:
- 研究筛选:使用LEADS辅助时,召回率达到0.81(无辅助时为0.78),同时节省了约20.8%的时间。
- 数据提取:准确率达到0.85(无辅助时为0.80),节省了约26.9%的时间。
这意味着,LEADS并未取代专家,而是在保持甚至提高工作质量的前提下,显著缩短了筛选与数据提取环节的耗时。这对于“系统综述太慢、太贵”的行业痛点,给出了一个直接的积极回应。
小结:专有数据 + 领域workflow + 人机协作
OpenScholar展示了“开放科学文献 + 检索增强 + 引用可控”在通用科学问答上的巨大潜力;而LEADS则证明了,在医学系统综述这条更垂直、更强调流程严谨性与证据质量的赛道上,“专有数据”与“针对特定工作流的建模”能带来何种价值:
- 专有数据:基于2万多篇系统综述、45万多篇文献、2.7万多条临床试验记录构建的LEADSInstruct数据集,让模型真正学会了“医学综述该怎么做”,而不仅仅是进行泛化阅读。
- 领域workflow:将检索、筛选、提取拆解为可训练、可评估的子任务,并在一个基础模型中统一处理,才能既覆盖多主题需求,又紧密贴合实际工作流。
- 人机协作:在真实用户研究中,专家借助LEADS在筛选与提取任务上实现了既省时又提效的目标,印证了“AI加速、专家把关”是当前更稳健、更易落地的技术方向。
我们相信,在文献挖掘与综述这个方向上,针对垂直领域的专有数据和专门的工作流建模会变得越来越重要。LEADS是我们在医学领域的一次系统性探索,也欢迎从事系统综述、循证医学或医学自然语言处理的朋友一同探讨与合作。
如果你对这类结合人工智能与垂直领域工作流的指令微调实践感兴趣,可以访问我们的云栈社区,获取更多关于大模型应用与智能 & 数据 & 云计算的讨论与资源。
参考文献
[1] OpenScholar: Synthesizing scientific literature with retrieval-augmented language models. Nature (2026). https://www.nature.com/articles/s41586-025-10072-4
[2] Wang, Z. et al. A foundation model for human-AI collaboration in medical literature mining. Nat. Commun. 16, 8361 (2025). https://doi.org/10.1038/s41467-025-62058-5
[3] PubMed systematic review statistics (e.g. annual growth).
[4] Bastian, H., Glasziou, P. & Chalmers, I. Seventy-five trials and eleven systematic reviews a day: how will we ever keep up? PLoS Med. 7, e1000326 (2010).
[5] Borah, R. et al. Analysis of the time and workers needed to conduct systematic reviews of medical interventions using data from the PROSPERO registry. BMJ Open 7, e012545 (2017).
[6] 见 LEADS 论文正文对 NIH 资助机构与药企文献综述成本的引用。
[7] 见 LEADS 论文对 PubMed 元数据与检索精度的讨论。
[8] 见 LEADS 论文对系统综述中常见问题的综述(如检索不全、筛选偏差、提取错误)。
 发表于 2026-3-3 05:06:56
|
查看: 135|
回复: 0
发表于 2026-3-3 05:06:56
|
查看: 135|
回复: 0
