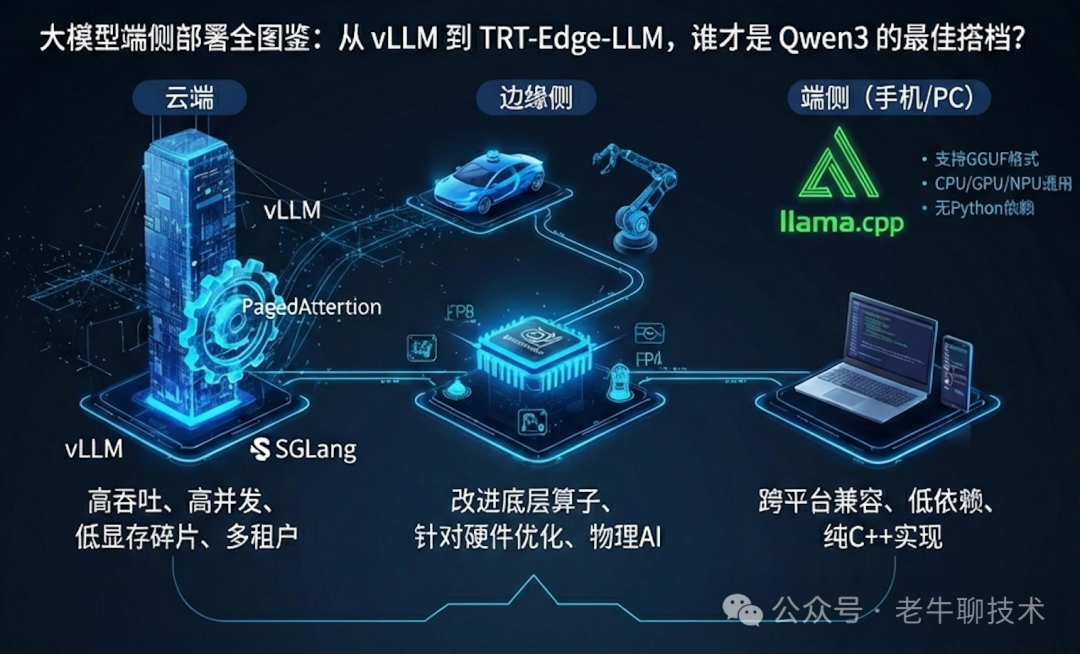
最近在部署 Qwen3-4B 时遇到了一个令人困惑的问题:原本以为 vLLM 已经是云端推理的不二之选,结果在实际对比中发现,TensorRT-Edge-LLM 在特定场景下的速度表现异常突出,甚至 llama.cpp 也有其独特的优势。这不禁让人思考,面对如此多的部署框架,我们究竟该如何选择?它们各自的核心差异又在哪里?
其实,各种 大模型推理 框架看似百花齐放,但其设计核心主要围绕着三个关键指标进行权衡:
- 吞吐量:指单位时间内能够处理的请求数量或生成的 token 总数。这是
vLLM 这类框架的立身之本,旨在高效服务高并发请求。
- 延迟:指从收到请求到开始返回第一个 token 所花费的时间,以及后续 token 的生成间隔。低延迟对于追求极致响应速度的交互式应用至关重要,是
TensorRT-Edge-LLM 这类框架重点优化的方向。
- 兼容性:指框架在不同硬件平台(如不同品牌的 GPU、CPU、NPU)和操作系统上的运行能力。
llama.cpp 正是凭借其卓越的跨平台兼容性脱颖而出。
性能实测:数据揭示差异本质
理论归理论,实战数据才最能说明问题。以下是在 NVIDIA RTX 4090 单卡上,对 Qwen3-4B (FP16) 模型进行的简单性能实测对比:
| 框架 |
Prefill (理解/首 token 延迟) |
Decode (生成速度) |
核心特点分析 |
| TensorRT-Edge-LLM |
~23000 tokens/s |
~100 tokens/s |
预填充阶段性能极佳,得益于对 NVIDIA 硬件的底层算子深度优化。 |
| vLLM |
~15000 tokens/s |
~98 tokens/s |
吞吐量导向,在多请求并发场景下能保持高且稳定的生成速度。 |
| llama.cpp |
~6300 tokens/s |
~100 tokens/s |
兼容性极强,生成阶段速度不弱,预填充相对较慢。 |
从数据中可以清晰地看出一个关键现象:TensorRT-Edge-LLM 在预填充阶段的性能一骑绝尘,这源于它对计算密集型阶段的极致优化。而到了以内存访问为主的 Decode(生成)阶段,三者的性能则趋于接近,因为此时性能瓶颈主要转移到了显存带宽上。
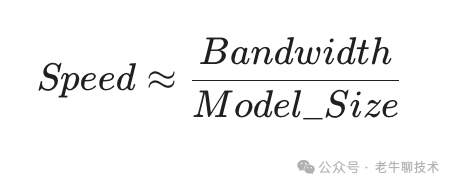
当模型参数加载到显存后,持续的 token 生成速度很大程度上受到“显存带宽”这一物理天花板限制。公式 Speed ≈ Bandwidth / Model_Size 形象地说明了这一点:在给定硬件带宽下,模型越大,理论最大生成速度就越低。因此,当带宽成为瓶颈时,不同框架的优化空间会变得有限。
深入场景:为何 vLLM 不是万能的?
既然 vLLM 吞吐量表现优秀,是否意味着它可以统一所有部署场景?答案是否定的。这就像不能用公交车的引擎去要求 F1 赛车的起步速度。不同框架是为不同“路况”设计的:
-
vLLM:面向服务的“公交车”
vLLM 的核心优势 PagedAttention 旨在高效管理显存、服务多用户并发请求。但其依赖较重(Python 环境、较大的容器镜像),启动和初始化时间较长。在需要秒级启动、资源严格受限的端侧环境(如车载系统、嵌入式设备)中,它就显得过于“笨重”了。
-
TensorRT-Edge-LLM:追求极速的“赛车”
这是 NVIDIA 针对边缘和端侧场景推出的利器。它采用纯 C++ 编写,剥离了复杂的多租户调度,专门为单请求或低并发场景下的极致延迟优化。通过深度 定制化底层算子 和利用 TensorRT 的优化能力,它在 NVIDIA GPU(特别是 Jetson、消费级显卡)上能实现惊人的首 token 响应速度。
-
llama.cpp:全地形的“越野车”
它的最大优势在于兼容性。纯 C++ 实现、无 Python 依赖、支持 GGUF 模型格式,使得它可以轻松编译并运行在从 x86 CPU、Apple Silicon 到各种边缘 GPU 的广泛平台上。当你需要开发一个面向 Windows、macOS、Linux 多平台的 PC 客户端时,llama.cpp 往往是最高效的选择。
选型决策树:如何为你的项目选择框架?
根据不同的业务目标和部署环境,可以参考以下决策路径:
-
场景:提供云端 API 服务,需要高并发处理数百个请求。
推荐:vLLM 或 SGLang。
理由: 这类框架专为高吞吐量设计,能充分利用 GPU 资源服务大量用户。
-
场景:开发跨平台桌面应用(Win/Mac/Linux)。
推荐:llama.cpp。
理由: 一套 C++ 代码可编译至各主流平台,依赖极简,用户体验一致。
-
场景:在 NVIDIA 边缘设备(如 Jetson)或消费级显卡上部署,追求最低延迟和最快响应。
推荐:TensorRT-Edge-LLM。
理由: 针对 NVIDIA 硬件栈的深度优化,能压榨出硬件的极限性能,特别适合交互式应用。
-
场景:针对特定品牌硬件进行深度集成(如 Intel AI PC、Apple 设备、高通骁龙手机)。
推荐:优先考虑厂商原生 SDK,如 Intel OpenVINO GenAI、Apple MLX、Qualcomm AI Engine。
理由: 厂商提供的工具链通常能最大程度发挥其自家硬件的异构计算能力(CPU+GPU+NPU),在能效比和性能上具有独特优势。
总结与展望
回到最初的问题:谁才是 Qwen3 的最佳搭档?答案取决于你的“赛道”。vLLM 是多租户云端服务的标杆,TensorRT-Edge-LLM 是 NVIDIA 端侧低延迟的王者,而 llama.cpp 则是实现最大范围跨平台覆盖的瑞士军刀。
未来,随着大模型加速向端侧渗透,硬件原生的优化框架将变得更加重要。对于开发者而言,理解吞吐量、延迟、兼容性这三个维度的 trade-off,并结合实际的应用场景与目标硬件进行选型,是成功部署端侧大模型的关键第一步。
希望这份基于实测的对比分析能为你下一次的模型部署选型提供清晰的参考。如果你对具体某个框架(例如 TensorRT-Edge-LLM 的量化编译细节)的实战操作有更多兴趣,欢迎在技术社区深入探讨。获取更多 AI 与部署相关的实战资源,可以关注像 云栈社区 这样的开发者聚集地。 |  发表于 2026-3-2 03:23:41
|
查看: 194|
回复: 0
发表于 2026-3-2 03:23:41
|
查看: 194|
回复: 0
