阿里千问团队发布了 Qwen3.5-Omni 全模态大模型。从 AI 产品设计的角度,它确实值得更高的讨论热度。
近几个月,大模型领域的注意力大多集中在 Vibe Coding 与 Agent 上。但全模态模型线也在不断加速,3 月以来,小米发布了 MiMo-V2-Omni,美团发布了 LongCat-Next。而作为国内 Omni 模型的主要开源贡献者,千问也在前两天发布了最新的 Qwen3.5-Omni。

聊全模态,先从 AI 语音通话聊起
不知道你是否还记得 ChatGPT 高级语音模式?彼时,GPT 凭借随时可打断、真人音效的优势——挂着语音,开车聊、走路问,成了很多人日常使用 AI 的自然方式(国内豆包也把语音通话做成了核心体验)。
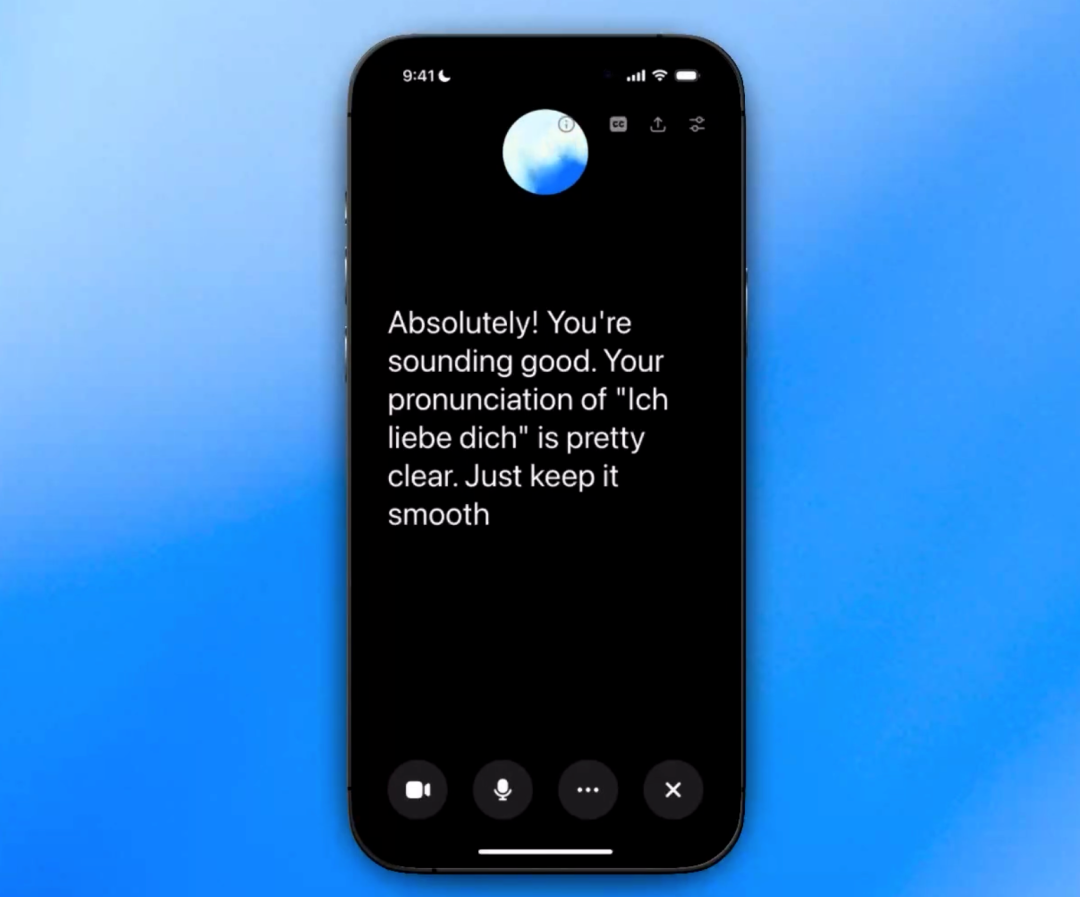
但这种体验并非从一开始就如此自然。OpenAI 在发布 GPT-4o 时的原话揭示了过去的局限:
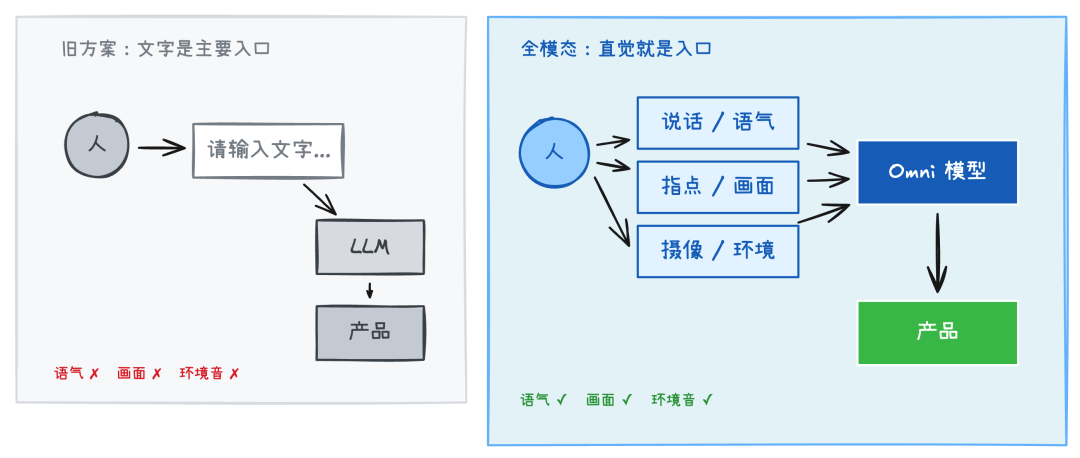
- 在 4o 之前,语音模式需要通过「你说话 → 语音识别转成文字 → 模型理解文字并生成回复 → 文字转语音念给你听」的旧管线。
- 作为主要智能源的 AI,在旧管线中,并不能直接观察语气、说话者人数,也不能输出情感。

这也是大多数 AI 产品语音交互的旧方案:
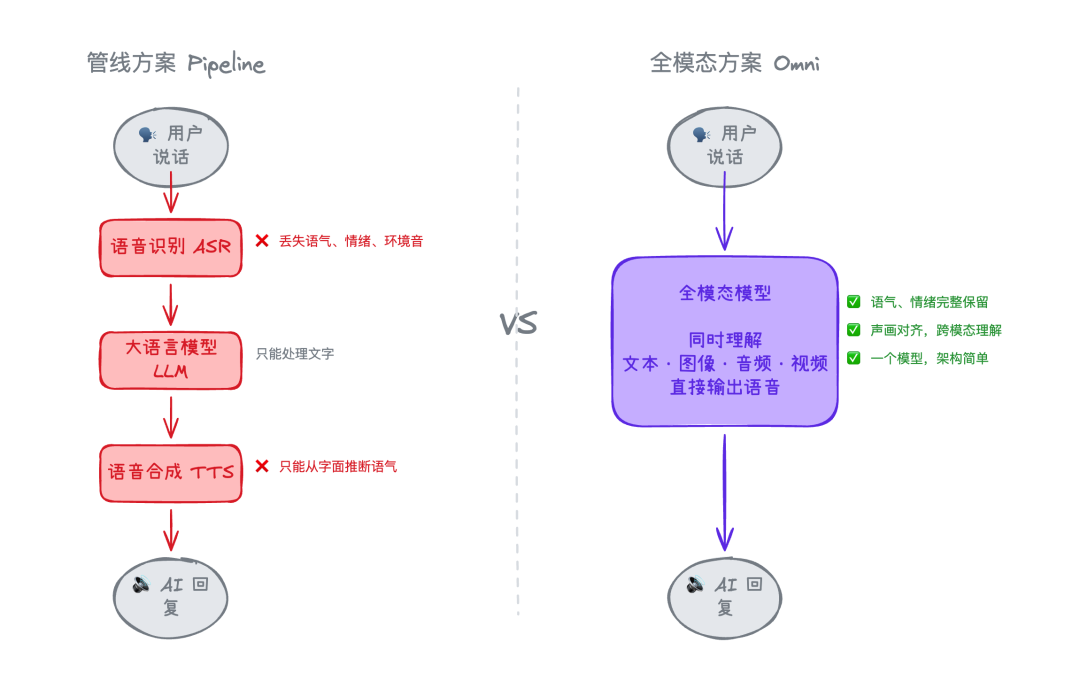
不难发现,这种管线方案的每一层都可能损耗信息:
- 语音识别(ASR):语气、情绪、停顿节奏、声调变化、环境音、说话人特征全部丢失。你阴阳怪气说了一句话,转成文字后意思变得很平和,模型完全感知不到你的语气。
- 级联错误:ASR 转录错了,后面所有环节跟着错。一个识别失误逐级放大,没有纠错机会。
- 语音合成(TTS):模型只能输出文字,不能输出语气。你所听到的语调,只是 TTS 从字面推断出来的语气。
我们可以做一个简单的测试:用不同的语气、节奏,说「哎,好的,没问题」,然后用同系列的 Qwen3.5 非全模态模型与 Qwen3.5-Omni-Plus 全模态模型进行直观对比。
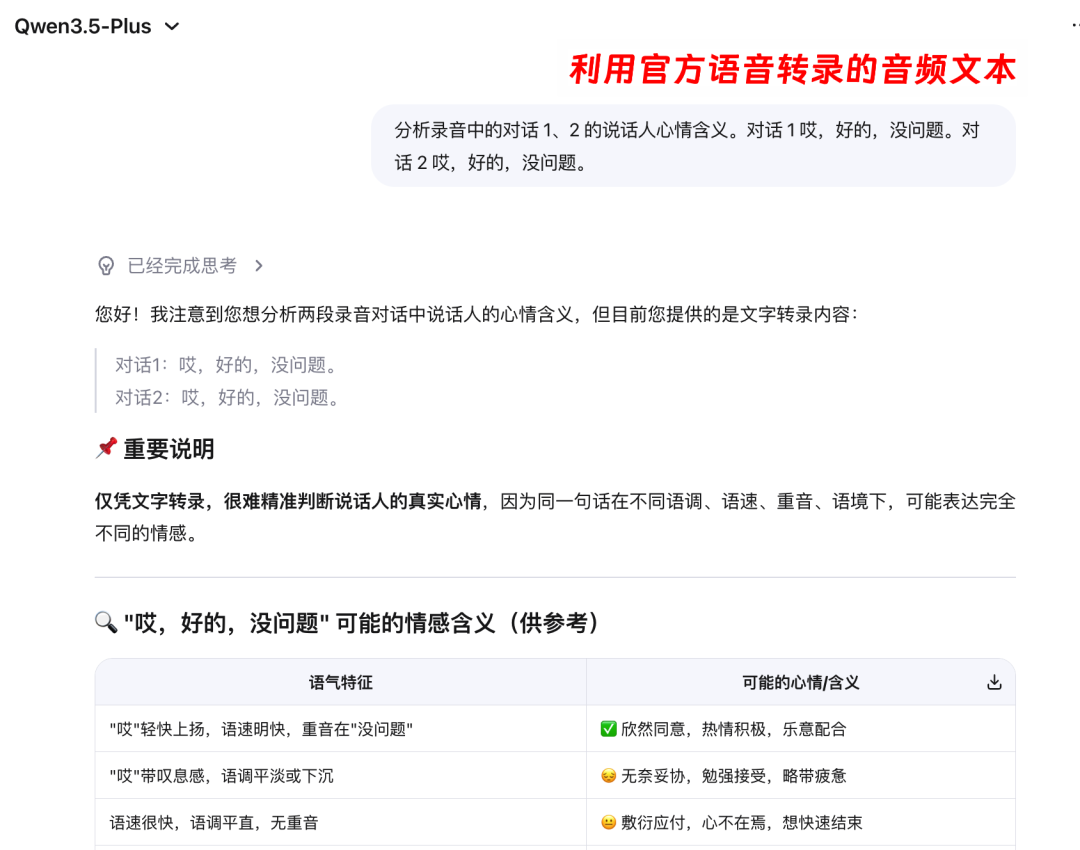

前者仅凭文字转录无法辨别语气,后者则能通过音频直接捕捉到说话人的疲惫、无奈或积极、爽快等心情与含义。在非全模态方案中,声音抵达模型智能核心之前,就损失了大量信息,这可以称之为 “模型从来没有真正听过你说话”。
全模态加速人AI交互的效率
语音通话的信息损耗,只是人AI交互中信息不完整的一种体现。在现实任务中,AI 还要处理图像、视频、音频的理解或输出。每次中间环节的模态转换,不仅会丢失信息,还会大大降低人机交互的效率与准确性(比如部分模型依赖 OCR 识别照片内容后,才能交给 AI 推理,但无法理解照片内的文字笔锋、颜色深浅)。
全模态模型要做的,就是让模型直接听音频、看图像、看视频,并通过端到端输出语音、图像等模态,减少中间转换的损耗(在行业语境下,“多模态”更侧重多模态理解,尤其指文本、图像理解,而“全模态/Omni”强调端到端的理解与生成)。
例如,在 Qwen3.5-Omni 中,用户可以直接对着 Excel 数据表,通过口述来下达数据分析要求。
AI 能够自动理解整个视频内的口述要求,并执行相应的指标计算:
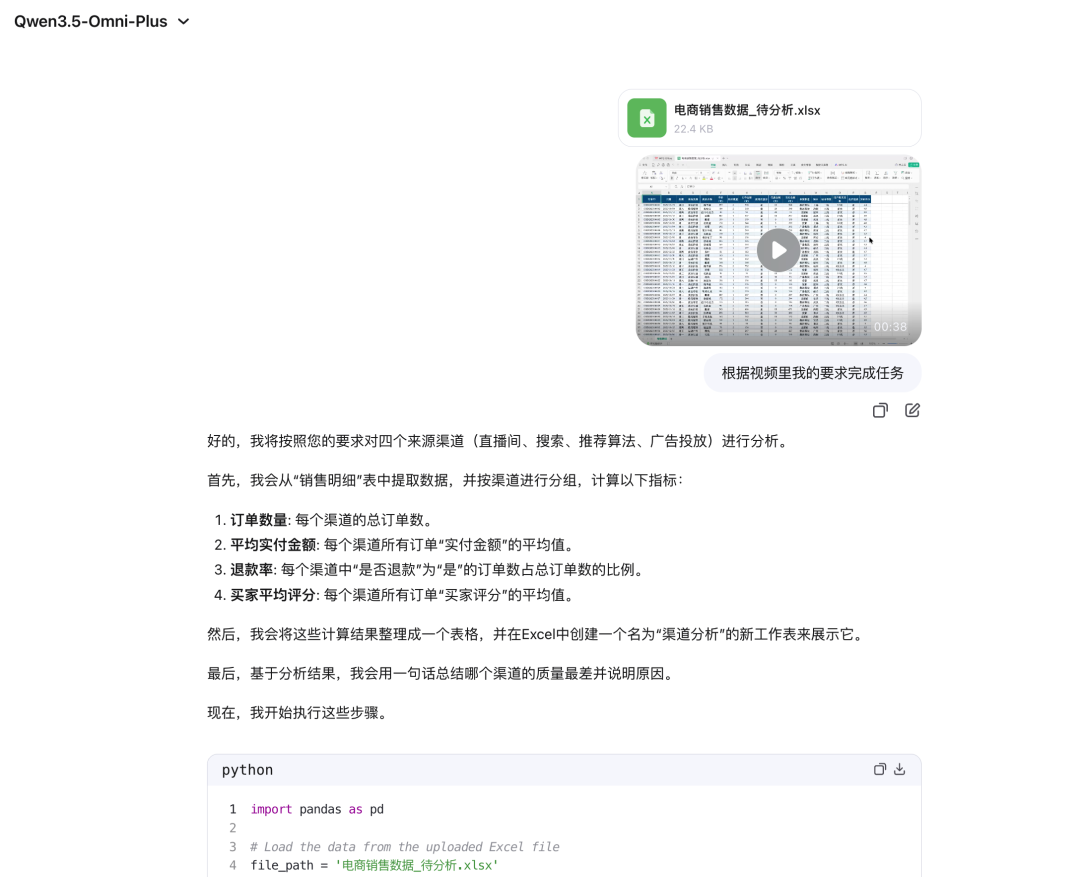
并将结果自动保存到了新的 Excel 工作表中。
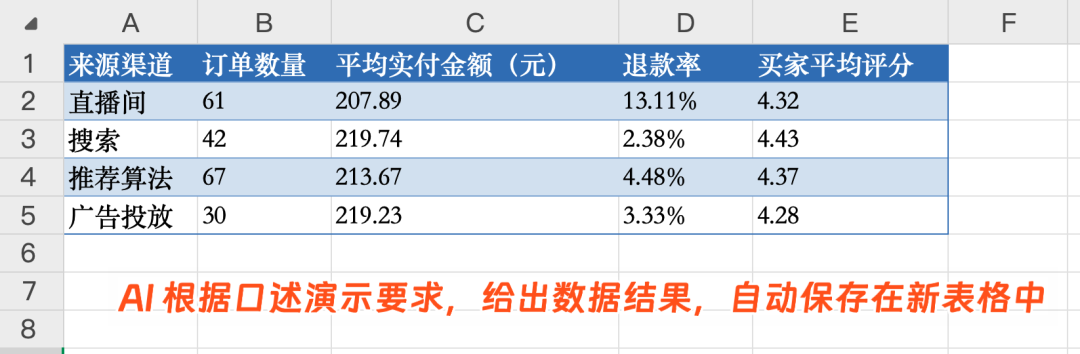
模型能端到端处理的模态越完善,AI 就越理解人的原始、完整需求。人与 AI 的交互方式也越接近「让真实人类做事」的自然方式。
Qwen3.5-Omni,你所需知道的一切
Qwen3.5-Omni 是千问最新一代的全模态大模型,支持以下模态的端到端处理:

- 输入:文本、图片、音频、视频理解(视觉能力与 Qwen3.5-Plus 对齐)。
- 输出:文本、音频。
在模型规格方面:
- 三种尺寸:Plus、Flash、Light(线上暂无 light 版)。
- API 版本:分为 Offline、Realtime 两个版本。离线版支持长音视频文件处理,实时版可进行实时音视频通话。
- 架构:采用 Thinker-Talker 架构,均基于 Hybrid-Attention MoE(混合专家)。
- 上下文:支持 256k 长上下文。
其核心能力提升明显,主要亮点包括:
- 长音视频处理:目前在线 API 支持 3 小时音频、1 小时视频处理。
- 语音输出:支持音色克隆,端到端情绪、音量、语速控制。
- 多语种:支持 113 种语言和方言的语音识别,36 种语言的语音生成。
- 语义打断:能区分「真实插话」与「附和/背景噪音」,不会被“嗯”一声或咳嗽误触发。
- 实时工具调用:实时通话时,支持联网搜索 + Function Call,模型自行判断是否触发工具。
官方评测显示,新模型在音视频理解、图像理解、语音生成等多项基准测试中,与 Gemini 3.1 Pro 等海外顶级模型相比得分靠前。
全模态,为什么值得更高的讨论度?
Omni 类模型虽然还未大规模应用于 AI 产品,但其潜力巨大,能启发许多新的 AI 用法和产品设计思路。
音视频实时通话:AI 产品的 Vibe 交互方式
AI时代的产品交互现在常被分为 GUI(图形界面)和 LUI(语言界面)两种模式。GUI 依赖人学会使用按钮、框选与点击。
LUI 则需要人用文本相对准确地描述需求,等待 AI 回应。
那么,如果让 Omni 模型能够同时“看到”用户在 AI 产品内的光标活动、听到用户的说话声音呢?(简单实现可以是摄像头同时对着人和电脑屏幕)。这是不是就能更进一步降低 AI 产品的使用门槛,让更多不熟悉复杂操作、不擅长精准语言表达的用户,也能体验到 AI 时代“随心而动”的操作便利?
比如,通过“指点+口述”进一步降低 AI Coding 的门槛(用户可以在线框图或设计稿上指指点点并口述需求,Omni 模型直接生成对应代码)。在实际应用中,可以直接结合纸笔草图、手指指点来录像,实现更自然的交互。
甚至可以将这种思路扩大到更广泛的非技术类应用:比如前文提到的 Vibe Excel 操作,如果 Excel 或系统级的通用 Agent 支持观察应用内的用户活动(光标位置、操作步骤),自然就能更加流畅、无感地调用 Agent 智能来协助完成任务。
长音频处理:LifeLog 的精细化识别(情绪、场景音)
另一个典型场景是个人全天录音的识别与日志生成。传统的方案通常是管线式的:先由专业 ASR 模型转写文字,再用说话人分离模型区分角色,最后交由大语言模型分析文字内容。这种方案的优势在于能建立详细的文字记录,但无法识别声音中的情绪、语调变化以及环境背景信息,所有分析都只能基于语义进行推理。
而基于全模态模型(如 Gemini 3 Flash 或 Qwen3.5-Omni),可以直接从原始录音中总结日志,自然区分说话人,并结合人声音调、环境背景推理出更丰富的 lifelog 信息。
使用 Qwen3.5-Omni-Plus 分析一段约 50 分钟的行业论坛实录音频,模型能快速流式返回内容摘要和详细记录:
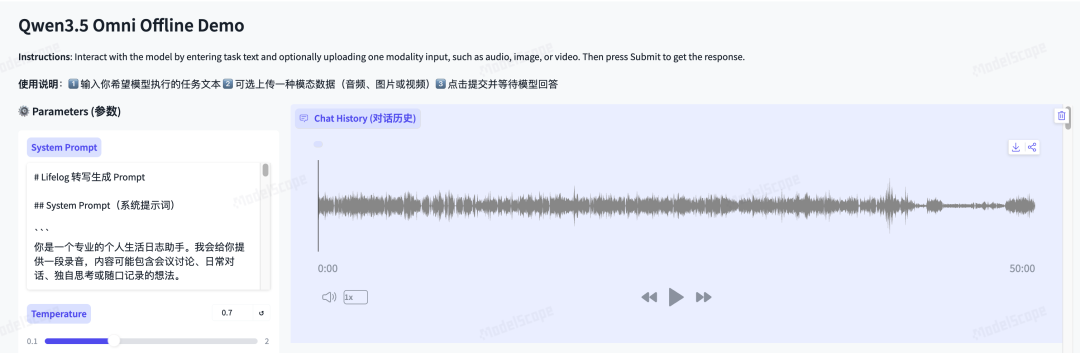

特别的是,它成功识别了分享过程中人物的语速、语调特征,更大程度地保留了 lifelog 中的非文字信息。如果进一步要求细化语调情绪分析,甚至能做到「识别吐字、重音、音调走向」的程度:

若要求 AI 进一步分析环境背景音,基于全模态模型,还能推断出录音所处的物理环境特征(如大型会议室、报告厅等)。
多语种端到端语音:沉浸式外语对练(多音色)
这个能力对于语言学习场景非常实用。Qwen3.5-Omni 既支持实时语音通话,又支持大量外语的端到端音频输入与输出。

在实际测试中,模型在中、英、日、德等多语种会话间切换自如,语音自然真实。更重要的是,它支持切换多种不同音色,且每种音色都支持多国语言,这为 AIGC 语音应用和出海产品提供了丰富的选择。
🎐 写在最后
除了以上用法,Qwen3.5-Omni 还有一些能力没有完全展示,比如实时通话中自动触发的联网检索、精准的音色克隆等。
总的来看,全模态模型发展至今,其成熟度已经足以进入 AI 产品设计的核心考量范围:
- 论设备:手机、车载系统、智能眼镜——这些下一代主流硬件的交互本来就不是纯文字的。
- 论用户习惯:更多人并不擅长用文本准确描述需求,更习惯口述加简单指点。
当模型能直接处理语气、画面和环境信息,不需要先把用户的直觉反应“有损翻译”为文本指令时,产品设计的想象空间就完全不同了。
有了全模态模型的加持,人与 AI 的交互方式能更接近「让真实人类协作」的自然形式。而兼具了全模态理解与生成、Agent 任务执行、代码生成等能力的 Qwen3.5-Omni 是一个重要的里程碑。未来能创造出什么,越来越取决于产品与开发者的想象力。对全模态技术感兴趣的开发者,可以关注 云栈社区 的相关讨论,与同行交流实践心得。
如何上手体验?
 发表于 2026-4-2 01:30:08
|
查看: 152|
回复: 0
发表于 2026-4-2 01:30:08
|
查看: 152|
回复: 0
