你对语音助手说:“我没事。”
它把这三个字转写得完全正确,然后很放心地继续往下聊。可真正听过那段声音的人,可能会立刻察觉不对:声音在抖,语速变慢,背景里还有一下很重的摔门声。
这就是音频大模型最容易骗人的地方。它看起来在“听”你说话,实际很多时候只是先把声音压成文字,再把文字丢给 LLM 推理。文字没错,不代表声音被理解了。
腾讯微信 AI 和北大这篇《Beyond Transcription: Unified Audio Schema for Perception-Aware AudioLLMs》抓住的就是这个问题。我觉得它值得写,不是因为又出了一个 AudioLLM,而是它把一个很朴素的问题讲透了:会转写,不等于真的听见。
论文里有个反直觉现象。当前 AudioLLM 在复杂推理题上可以做到大约 70% 的准确率,但到了基础听觉感知,成绩会掉到 40% 左右。也就是说,模型能回答复杂问题,却经常听不准说话人的情绪、口音、语气,甚至漏掉简单的非语言声音。这很像一个只看字幕的观众。
会转写,不等于真的听见
ASR 的目标很明确:把声音还原成标准文字。这个目标在过去十几年里非常成功,也让语音交互真正可用。但它天然有一个副作用:为了得到干净文字,系统会主动忽略很多“文字之外”的东西。比如 prosody——说话的节奏、重音和语调;比如 timbre——声音质感;再比如情绪、口音、背景噪声、音乐、门响、笑声。这些信息对 ASR 来说常常是干扰项,对真实理解却可能是关键线索。
所以问题不是 AudioLLM 不够聪明,而是训练目标从一开始就把它带偏了。模型一直被奖励“说了什么”答对,却很少被奖励“怎么说”听准。久而久之,它会形成一种很合理但很危险的能力分布:推理越来越强,感知仍然很粗。
有人会说,那就给模型加 audio caption,让它生成一段完整描述不就行了?这条路也有问题。自然语言描述太自由了,同一段声音可以被写成十几种句子:有人先写情绪,有人先写背景声,有人把口音和语速混在一起。对模型来说,这种监督信号信息很多,但形状很散。
我读到这里的第一反应是:这篇论文真正攻击的不是某个模型,而是“字幕中心主义”。我们长期把语音理解简化成文字理解,结果模型也真的学会了只盯字幕。
腾讯北大补的不是模型,是训练目标
Unified Audio Schema,简称 UAS,做的事很直接:把一段音频拆成三张账本。
一张账本记录 transcription,也就是原话说了什么。它保留 ASR 最擅长的部分,要求文字不能丢、不能改。第二张账本记录 paralinguistics,也就是这句话是怎么说出来的。里面包括年龄、性别、情绪、口音、prosody、timbre。你可以把它理解成声音里的“人味”:这个人是平静还是愤怒,是急促还是迟疑,声音是清亮还是含混。第三张账本记录 non-linguistic events,也就是语言之外发生了什么。它会描述背景环境、突然出现的声音,以及持续存在的噪声或音乐。比如门响、笑声、背景 hiss、低频 hum,都不再被当成没用的噪声扔掉。
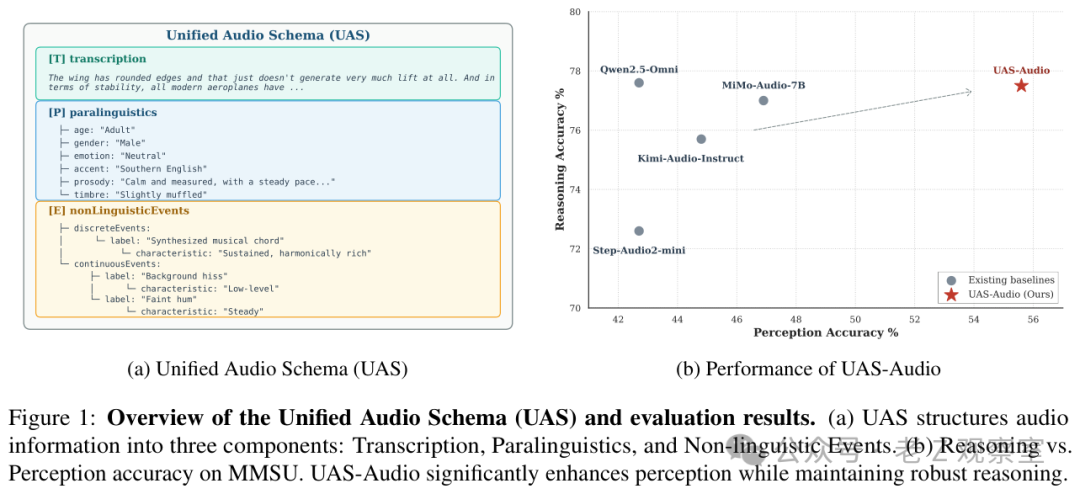
这张图左边是 UAS 的三层结构,右边是最重要的结果:红色星标代表 UAS-Audio。横轴是感知能力,纵轴是推理能力。它被往右推了一大截,但纵向没有明显掉下去。也就是说,它不是用推理换感知。
更有意思的是,UAS 不是靠人工一条条标出来的。论文做了一条自动数据流水线:先用 acoustic caption model 从原始音频里抓出说话人特征、情绪、背景声;再用 LLM 把这些描述和原始 transcript 合并成固定 JSON;接着用规则做质量校验,过滤字段不合法、文字不完整、逻辑冲突或者描述过度复杂的样本。
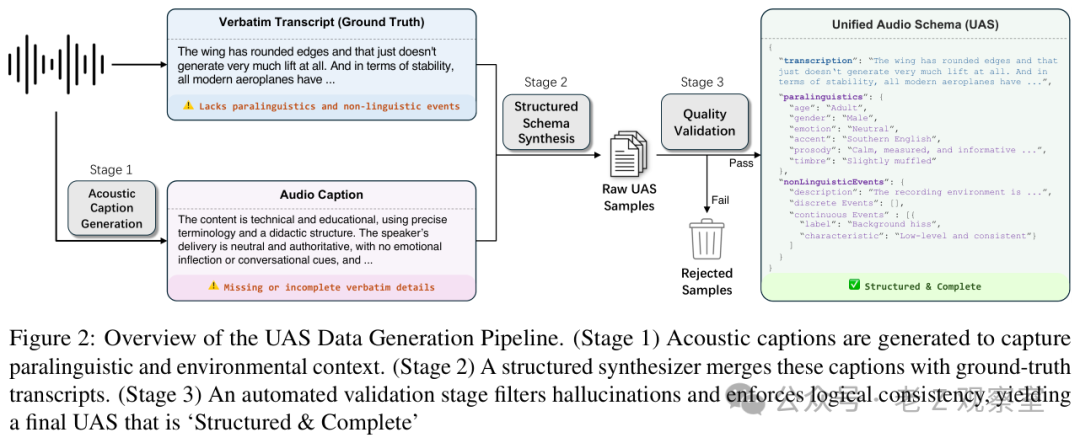
这张流程图很关键。它说明 UAS 不是一个“好但很贵”的标注方案,而是可以把已有 ASR 数据重新加工成更完整的音频监督。论文还抽了 400 条样本做人类审核,多数字段准确率超过 95%。情绪和短促事件低一些,但也分别有 89% 和 91.75%。
模型结构反而不是主角。UAS-Audio 可以接连续 audio encoder,也可以接离散 audio tokenizer。论文验证了两种架构,重点不是发明一个神奇模块,而是把训练数据从“纯 transcript”改成“完整声学结构”。我觉得这点很重要。很多论文会把故事讲成“我们设计了一个新网络,所以模型变强了”。这篇更像是在说:你不用急着堆新模块,先把老师给学生的答案改对。
这件事放到真实产品里,会变得更明显。一个客服质检系统如果只拿 transcript 做分析,只能知道用户说了“可以”“不用了”“你们处理吧”。但这些词在不同语气下含义差很多。有的人是真的接受了方案,有的人是在压着火结束对话。一个会议助手如果只记文字,也会漏掉谁在迟疑、谁在强硬打断、哪段讨论伴随着明显的笑声或沉默。对人来说,这些都是上下文;对只吃 transcript 的模型来说,它们从数据入口就消失了。所以 UAS 的价值不只是涨 benchmark。它把音频应用从“语音转文字后的 NLP”往前推了一层:声音本身开始成为一等公民。
最关键的数字,不是平均分
看这类论文,平均分通常没那么重要。真正要看的,是它有没有解决原先的能力倒挂。MMSU 是这篇里最有价值的 benchmark,因为它把 perception 和 reasoning 拆开看。UAS-Audio 在 perception 上做到 55.7%,比同尺寸最强 baseline Kimi-Audio 的 44.8% 高 10.9 个点。与此同时,它的 reasoning 是 77.4%,只比 Qwen2.5-Omni 的 77.6% 低 0.2 个点。

这个数字说明一件事:细粒度听觉感知不是非得牺牲推理能力。过去模型听不准,不一定是因为它的语言脑不够强,而是因为音频监督长期把信息压扁了。
消融实验更能打到要害。去掉 UAS annotation,perception 从 55.7% 掉到 50.7%;去掉 UAS-QA,掉到 47.0%;两者都去掉,掉到 42.8%。但 reasoning 几乎一直在 77% 附近。
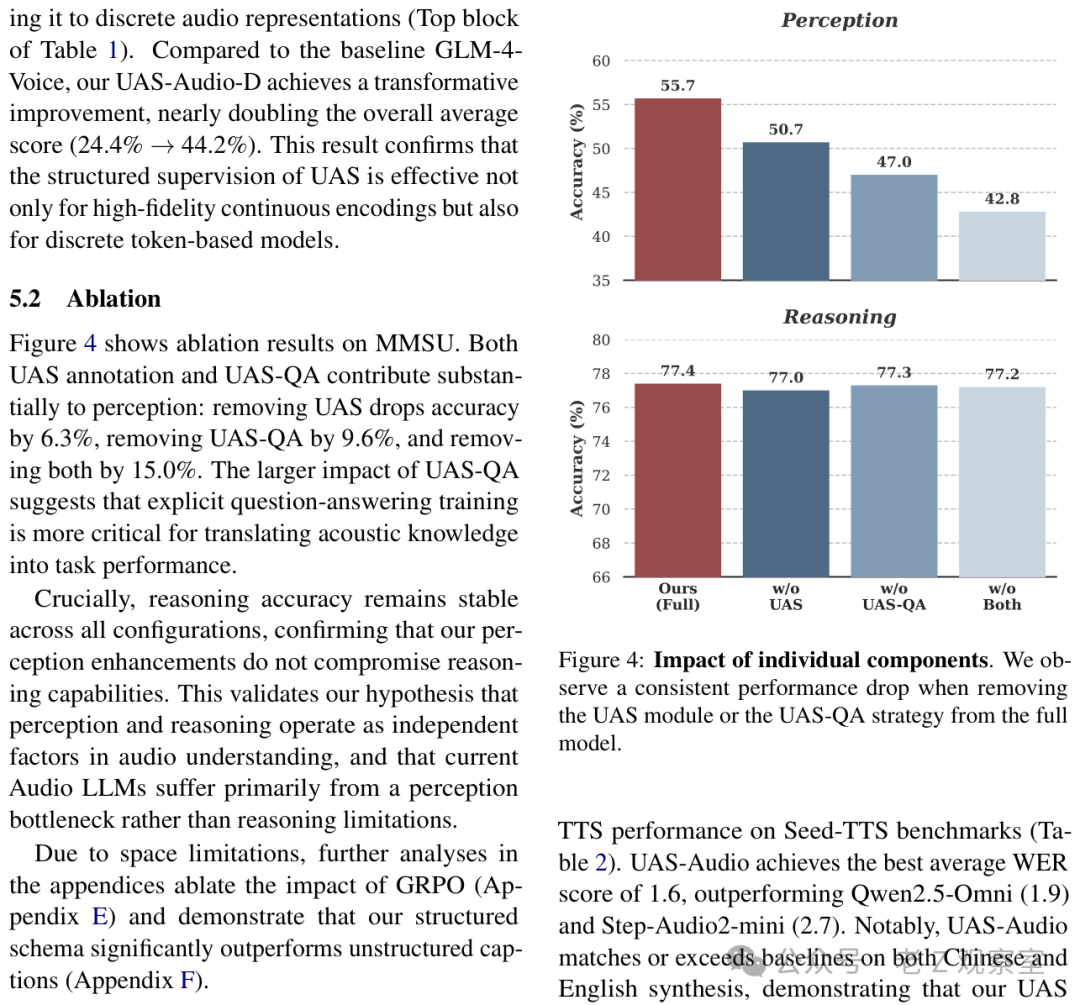
这个结果我觉得比主表更重要。它说明 UAS 和 UAS-QA 不是装饰,而是在专门补感知缺口。UAS annotation 教模型“应该听见什么”,UAS-QA 教模型“怎么把听见的东西拿来回答问题”。
还有一个小实验很漂亮。论文把 structured UAS 和 unstructured caption 做了对比。两边用同样的数据源,也都不加 GRPO,只看监督格式本身的差别。结果 structured UAS 的 perception 是 54.8%,自然语言 caption 是 48.4%,差了 6.4 个点。
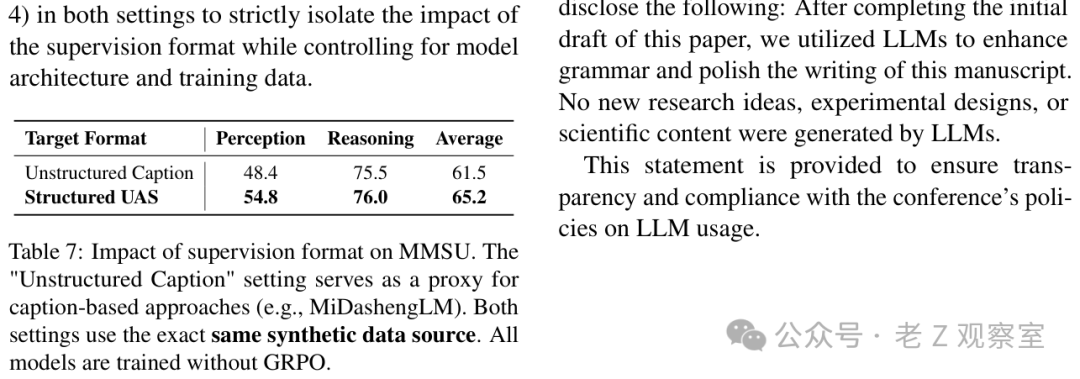
这就是我最喜欢的工程直觉:不是信息越多越好,而是信息要摆在模型容易学、系统容易取的位置上。自然语言 caption 像一段听感作文,UAS 更像一张表。作文更流畅,表更稳定。
这里也能解释为什么简单加 tag 不够。像“这里有笑声”“这里是开心语气”这种扁平标签,适合少量稀疏事件,但很难覆盖持续存在的声学状态。一个人的语速、停顿、音色、口音、背景噪声,往往不是某个瞬间出现一下,而是贯穿整段音频。UAS 的好处是给这些连续信息留了位置,让模型在训练时反复看到同一类属性应该放在哪里。更现实一点说,如果下游应用只想知道“说话人是不是生气”“背景里有没有报警声”,结构化字段也比一段自然语言更容易接入产品。论文也强调,UAS 主要是训练时的脚手架,推理时不一定非要生成完整 JSON。你可以直接问模型某个属性,让它短答。
声音比表格更滑,这条路还没走完
当然,声音不是天然规整的数据库字段。论文自己承认了两个限制。验证主要集中在中英文等高资源语言,低资源语言和 code-switching 场景还没充分测。当前 schema 也主要围绕单个主说话人,对多人重叠说话、鸡尾酒会式场景还不够完整。
我额外有一点存疑。UAS 的自动生成依赖 caption model 和 LLM 合成,虽然人类抽检整体不错,但 emotion 只有 89%,离散事件 91.75%。这两个字段本来就难。一个人到底是疲惫、冷淡还是难过,很多时候连人类都不一定一致;一个很短的碰撞声,到底该不该标出来,也会受听者注意力影响。
还有一个更产品化的问题:schema 一旦固定,系统会天然偏向它已经定义好的属性。年龄、性别、情绪、口音这些字段容易被枚举,但亲密关系里的讽刺、会议里的压迫感、客服场景里的不耐烦,未必能被几个标签完整覆盖。换句话说,UAS 让模型开始认真听声音,但它听见的东西仍然被表格形状限制。
所以 UAS 更像一个好脚手架,不是世界本身。它把混乱声音整理成模型可以学习的结构,但也可能把一些连续、暧昧、上下文相关的信号硬塞进离散字段。这个代价值得接受,但不能忘记它存在。
即便如此,这篇论文的方向我觉得是对的。音频大模型如果只追求更准的 transcript,本质上还是文字模型的外接耳朵。真正的 AudioLLM 应该能听见文字之外的世界:语气里的犹豫,背景里的异常,沉默里的压力。
回到开头那句“我没事”。未来好的语音模型,不该只把它转成三个字。它应该知道,这三个字有时候是真的没事,有时候恰恰是在求救。
云栈社区将持续关注音频人工智能的最新进展,与你一起跟踪那些能让技术“听见人心”的突破。
 发表于 2026-4-29 07:04:48
|
查看: 144|
回复: 0
发表于 2026-4-29 07:04:48
|
查看: 144|
回复: 0
