看到“65535”这个数字时,不少技术人员的第一反应是:单个 Linux 服务器的 TCP 连接数难道就卡死在 65535 了吗?如果真是这样,动辄百万访问的网站岂不是需要几十台机器才能撑住?但现实显然不是这样——单台 Linux 机器完全可以撑起远超 65535 的并发连接,关键在于你如何理解端口、连接四元组以及操作系统的资源瓶颈。
在 Linux 中,系统用四元组唯一标识一个 TCP连接:{本机 IP, 本机端口, 远端 IP, 远端端口}。端口字段是一个 16 位的无符号短整型(unsigned short),因此端口号的范围是 0~65535,去掉保留的 0 号端口,可用端口共 65535 个。很多人误以为这就是连接数的上限,其实是混淆了“端口数量”与“连接数量”的概念。
我们先从客户端(client)视角看:客户端发起 TCP 连接时,如果没有主动绑定端口,内核会分配一个空闲的本地端口,该端口被当前连接独占。因此,一台机器只作为客户端时,最多只能同时使用 65535 个不同的本地端口,也就是说最多可以同时维持 65535 条连接去连接不同的服务器。这个场景恰好符合题主的假设,但它的前提是“只做客户端、不考虑端口复用”,在生产环境中极为罕见。
再切换到服务端(server)视角:服务端固定在某个端口(比如 80)监听。即使服务端 IP 和端口固定不变,只要客户端的 IP 或端口其中一项不同,就可以构成不同的连接。IPv4 的客户端 IP 有约 2^32 个,端口有 65535 个,组合起来理论上服务端单机能支持的 TCP 连接数可达 2^48(约 281 万亿)。当然,这只是纸面上的计算。
在实际系统中,限制连接上限的从来不是端口号的数量,而是内存与文件描述符。每个 TCP 连接在内核中都需要分配相应的 socket 结构、发送/接收缓冲区等,每个 socket 又是一个文件描述符。因此,真正制约单机并发量的通常是:
- 可用内存
- 单个进程可打开的文件描述符数量(可通过
ulimit -n 或系统参数调整)
- 内核参数,如
net.ipv4.tcp_mem、net.core.somaxconn 等
通过适当扩容内存、调大文件描述符限制、优化参数,单台 Linux 服务器承载 10 万、甚至百万 TCP 并发连接是完全可行的,这在 CDN 边缘节点、IM 长连接网关等场景中已是常规操作。
一个经典的误读是:“服务器绑定了 80 端口,每来一个客户端不就占一个端口吗?那 80 端口被占完后不就无法接待新连接了?”事实是,服务端监听端口是可复用的。比如在 IIS(或 Nginx)中,同一个 IP 的 80 端口可以同时服务成千上万个客户端请求,只要客户端 IP 或端口不同,四元组就不同。
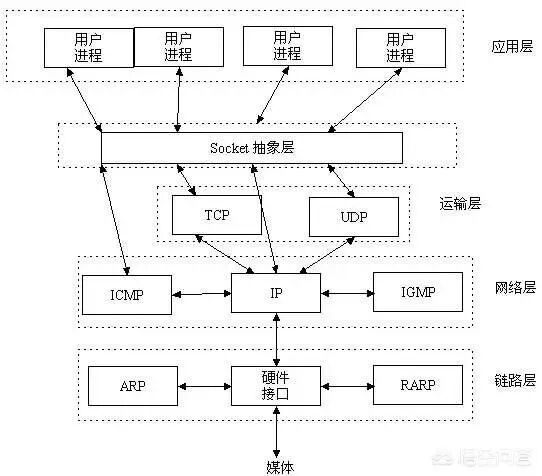
从进程间通信的角度看,网络通信的本质是让不同主机上的进程能够互相识别。IP 地址 + 传输协议 + 端口号 可以唯一标识网络中的一个进程,socket 则是对这一套复杂机制的抽象,它将 TCP/IP 的细节封装成类似文件的“打开—读/写—关闭”操作。
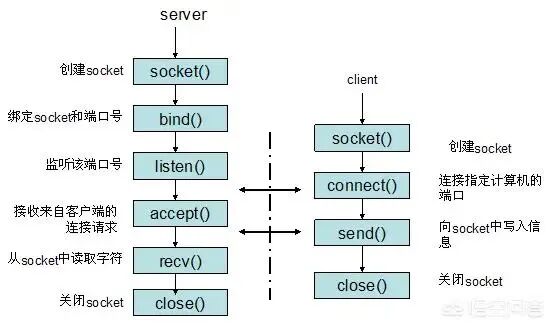
建立连接时,双方的 socket 通过四元组 (源 IP, 源端口, 目的 IP, 目的端口) 加以区分。比如你的主机 IP 是 1.1.1.1,监听 8080 端口;客户端 2.2.2.2 第一次用端口 5555 连接,第二次用端口 6666 连接,这会是两条独立的连接(四元组不同)。但当同一个客户端重复使用完全相同的四元组建立第三条连接时,才会因为无法区分而失败。
由此可以推演不同角色下的理论上限:
- 纯客户端:最多 65535 个连接(本地端口用尽)。
- 纯服务端:理论上可达 2^48 个连接,远不受 65535 端口限制。
- 实际部署:受内存、文件描述符、网络栈参数等影响,但单机 10 万+ 连接不成问题。
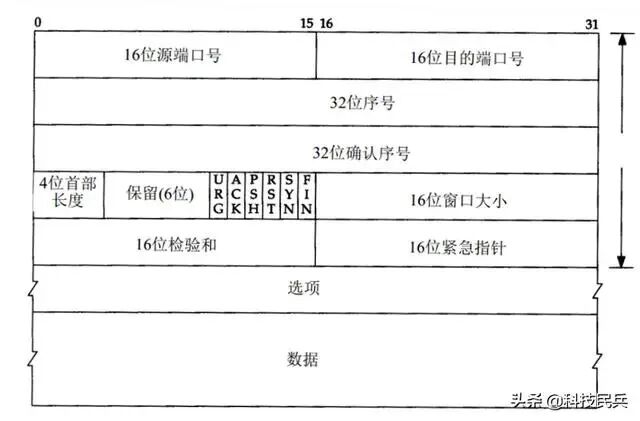
那“65535”这个数字究竟从哪来的?它只是端口号的取值范围。端口号用 16 位二进制表示,总共 65536 个可能的值(0 保留),所以端口数量最大 65535。但这仅仅表示一台机器上可用的端口标识数量,不等于连接数。在连接建立后,服务端的监听端口可以继续接收新连接,而数据传输阶段用的是新创建的 socket,原来的端口可以被复用给其他连接。正是这种“端口复用”机制,使得并发连接数可以远超 65535。
在高流量的商业架构中,单台服务器还会配合负载均衡组成分布式集群。当某台机器内存使用率超过安全阈值时,系统会自动限流或横向扩容,绝不会让单机内存耗尽。这就是大规模网站应对几十万、几百万并发请求的底层逻辑。
总的来说,65535 只是端口号的上限,它与 TCP 并发连接数从来都不是简单的等号关系。真正决定单机能扛住多少并发的是内存、文件描述符以及内核参数的调优。合理利用端口复用和操作系统资源,单机跑到 10 万量级极为轻松,配合服务器集群与分布式架构,百万甚至千万并发也早已是互联网基础设施的日常。
在云栈社区,技术人乐于深挖这些底层真相,再用工程实践去论证它们的边界。
来源:jianshu.com/p/f070212024a1
 发表于 2026-5-7 20:11:50
|
查看: 123|
回复: 0
发表于 2026-5-7 20:11:50
|
查看: 123|
回复: 0
