前言
你有没有遇到过这种情况:
服务器程序崩溃重启,或者你手动 kill 掉进程再重启,结果:
bind: Address already in use
明明进程都已经死了,端口为什么还“占着”?
用 netstat 一看:
tcp 0 0 0.0.0.0:8080 0.0.0.0:* TIME_WAIT
这个 TIME_WAIT 是什么?为什么要等那么久?能不能直接干掉它?
这篇文章把这些问题一次性讲清楚。
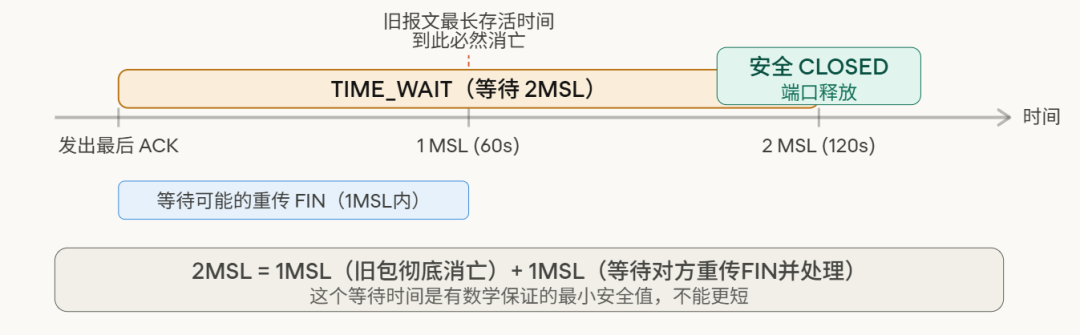
一、TIME_WAIT 是什么?它从哪里来?
回忆上一篇讲的 四次挥手,主动关闭连接的一方在发完最后一个 ACK 之后,不会立刻消失,而是进入一个叫 TIME_WAIT 的等待状态。先从四次挥手中定位 TIME_WAIT 的位置,让读者立刻对号入座。
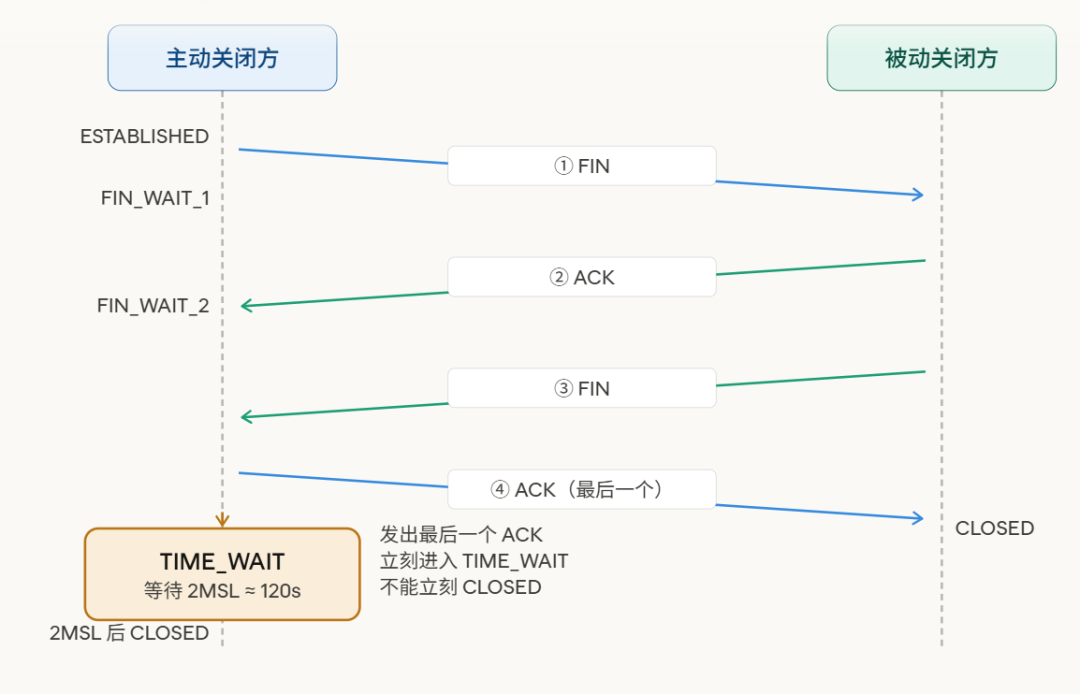
发完最后一个 ACK,主动关闭方没有立刻消失,而是在 TIME_WAIT 里“站岗”,等待 2MSL 时长。
MSL(Maximum Segment Lifetime) 是一个 TCP 报文在网络中的最大存活时间,Linux 默认 60 秒,所以 2MSL = 120 秒。
这 120 秒,就是端口被“占住”的根源。
二、为什么非得等 2MSL?两个缺一不可的理由
很多人觉得这 2MSL 是“多此一举”。其实不等不行,有两个硬逻辑:
理由一:保证最后一个 ACK 能送到
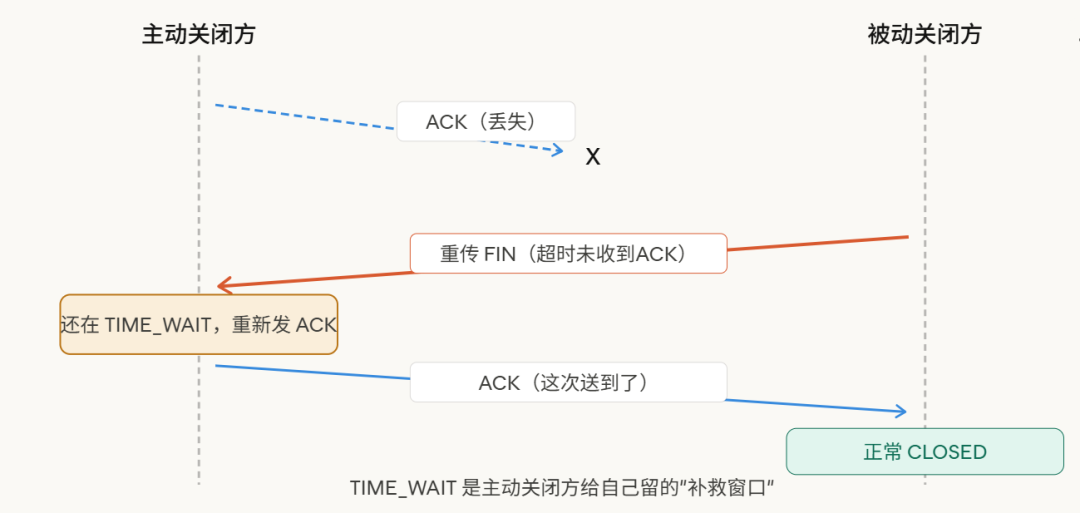
发出去的 ACK 可能在网络里丢失。一旦丢失,被动关闭方(服务端)会重发 FIN。
如果主动关闭方已经 CLOSED 了,收到这个重传的 FIN,只能回一个 RST(连接重置)。被动关闭方会认为连接异常关闭——这不是我们想要的优雅断开。
等 2MSL,就是为了“我如果没收到重传的 FIN,说明我的 ACK 对方收到了,可以安全关闭了”。
理由二:让网络里的“迷路包”彻底消亡
网络里可能还漂着上一条连接残留的数据包——它们走了弯路,迟迟没到。
如果立刻用同一个 {源IP:源端口, 目标IP:目标端口} 四元组建立新连接,这些旧包被新连接收到,数据就乱了。
等 2MSL,就是等网络中所有残留报文(最多漂 1 MSL)都超时失效,新连接绝对不会被旧包污染。
三、TIME_WAIT 堆积的真实场景
理解了原理,来看看生产中它是怎么出问题的。
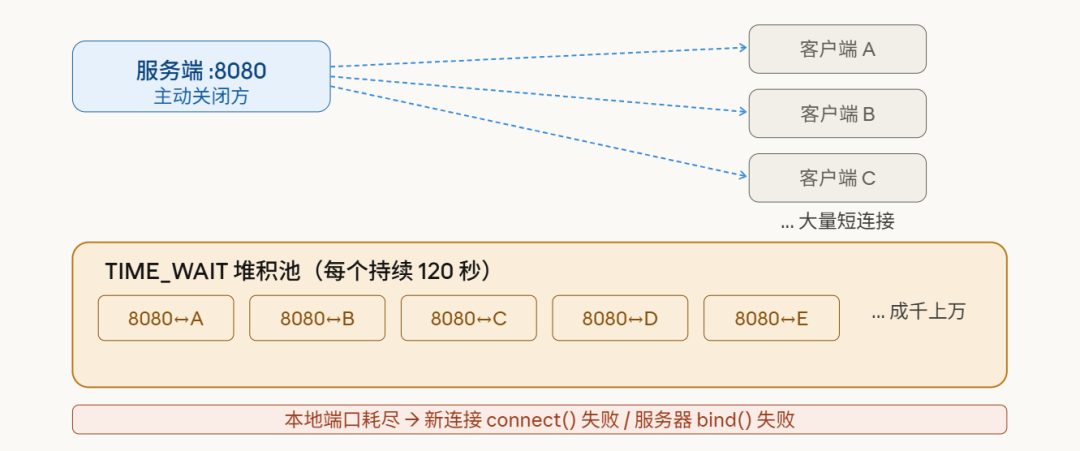
场景一:服务端主动关闭连接(最常见)
HTTP/1.0 时代,每次请求后服务端都会主动 close(),自己就成了主动关闭方。高并发下大量短连接被关闭,TIME_WAIT 快速堆积:
# 查看 TIME_WAIT 数量
$ ss -tan | grep TIME-WAIT | wc -l
18342 # 一万多个!端口耗尽只是时间问题
场景二:服务进程崩溃重启
进程崩溃,内核自动关闭所有 socket,服务器成了主动关闭方,占用的端口全进入 TIME_WAIT。重启一试:
$ ./server
bind: Address already in use # 端口还被 TIME_WAIT 占着
用 ss 确认一下:
$ ss -tan | grep 8080
TIME-WAIT 0 0 0.0.0.0:8080 0.0.0.0:*
端口还没“还回来”,新进程当然绑不上。
下图展示了 TIME_WAIT 堆积的全过程:
四、三种解决方案,按场景选
不同场景有不同的最优解,不要一上来就乱调内核参数。
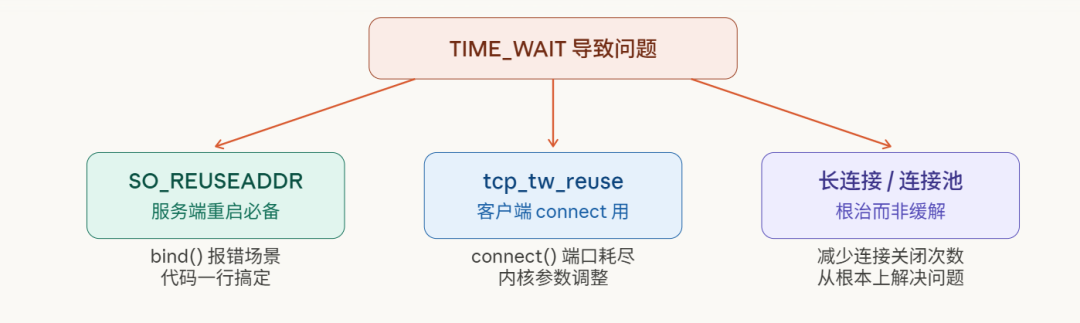
方案一:SO_REUSEADDR——服务端重启必加
这是最常用也最正确的方案,专门解决“服务重启 bind() 失败”问题。
int listen_fd = socket(AF_INET, SOCK_STREAM, 0);
// 必须在 bind() 之前设置!
int opt = 1;
setsockopt(listen_fd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
// 现在 bind() 即使端口在 TIME_WAIT 也不会失败
bind(listen_fd, (struct sockaddr*)&addr, sizeof(addr));
SO_REUSEADDR 的语义是:允许新 socket 绑定到一个仍处于 TIME_WAIT 状态的端口上,只要新旧连接的四元组不完全相同(通常是客户端端口号不同,所以没问题)。
注意:SO_REUSEADDR 不是在“绕过” TIME_WAIT,那个旧连接的 TIME_WAIT 还在,只是允许你的新 socket 绑定同一个本地端口,内核会正确区分新旧连接。
每个 TCP 服务端都应该默认加这一行,没有任何理由不加。
方案二:tcp_tw_reuse——连接发起方(客户端)的救星
SO_REUSEADDR 解决的是服务端 bind() 的问题。如果是连接发起方(比如你的服务作为客户端去请求下游)大量 connect(),本地临时端口耗尽,就需要另一个方案:
# 允许将 TIME_WAIT 的 socket 复用于新的 TCP 连接(仅用于发起方)
echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse
# 或者永久生效(写入 sysctl.conf)
echo "net.ipv4.tcp_tw_reuse = 1" >> /etc/sysctl.conf
sysctl -p
tcp_tw_reuse 的前提是开启时间戳(tcp_timestamps,Linux 默认已开启)。内核通过时间戳判断复用是否安全,避免旧包污染新连接。
有一个曾经流行的参数 tcp_tw_recycle,它已从 Linux 4.12 内核中移除,早期版本中开启它在 NAT 环境下会导致大量连接被丢弃,生产绝对不要用。
方案三:长连接 / 连接池——釜底抽薪
前两个方案是在“症状”上打补丁。真正的治本之道是:减少 TIME_WAIT 的产生。
TIME_WAIT 只在连接关闭时出现,所以减少连接关闭次数,才是根治。
短连接模式(会大量产生 TIME_WAIT):
请求 → 建立连接 → 发送数据 → 关闭连接 → TIME_WAIT
请求 → 建立连接 → 发送数据 → 关闭连接 → TIME_WAIT
请求 → 建立连接 → ... (每次都要握手挥手)
长连接模式(大幅减少 TIME_WAIT):
建立连接(一次)
→ 请求1 → 响应1
→ 请求2 → 响应2
→ 请求N → 响应N
关闭连接(一次)→ TIME_WAIT(只有一个)
HTTP/1.1 默认就是长连接(Connection: keep-alive)。服务间调用用连接池(gRPC、数据库连接池)都是这个思路。
五、一张图:TIME_WAIT 的完整生命周期
六、高频面试题精析
Q:TIME_WAIT 过多有什么影响?
占用本地端口。Linux 临时端口范围默认 32768-60999,共约 28000 个。TIME_WAIT 过多,新的 connect() 会因为找不到可用端口而失败(EADDRNOTAVAIL)。服务端 bind() 也可能失败(如果没有 SO_REUSEADDR)。
Q:能不能直接把 TIME_WAIT 时间改短?
不推荐。tcp_fin_timeout 控制的是 FIN_WAIT_2 的超时,不是 TIME_WAIT 的 2MSL。TIME_WAIT 的时长由内核 TCP_TIMEWAIT_LEN 硬编码(通常 60s),改它需要重新编译内核。即便能改,缩短会破坏安全性。正确做法是用上面三种方案。
Q:SO_REUSEADDR 和 SO_REUSEPORT 有什么区别?
SO_REUSEADDR:允许绑定处于 TIME_WAIT 状态的端口,以及绑定 0.0.0.0(通配地址)和具体地址同一端口。SO_REUSEPORT:允许多个 socket 绑定完全相同的 IP:Port,内核负责负载均衡(Nginx 多进程监听同一端口就是靠它)。两者解决的问题不同,通常服务端两个都要设置。
Q:客户端也会有 TIME_WAIT 吗?
会。只要是主动发起 close() 的一方,无论客户端还是服务端,都会进入 TIME_WAIT。短连接场景下客户端关闭连接,同样会堆积大量 TIME_WAIT,导致本地临时端口耗尽,connect() 报 EADDRNOTAVAIL。
七、总结:三句话记住 TIME_WAIT

结语
作为 云栈社区 的开发者,我们深知 TIME_WAIT 的坑。下次再遇到 bind: Address already in use,你已经知道该怎么做了:
- 立刻加
SO_REUSEADDR,解眼前的燃眉之急
- 如果是客户端大量短连接,考虑开
tcp_tw_reuse
- 从架构上改成长连接或连接池,才是真正的根治
TIME_WAIT 不是 TCP 的 bug,是它对“可靠关闭”的承诺。理解了它存在的原因,你才能在需要调优时做出正确的判断,而不是病急乱投医地乱改参数。
 发表于 2026-5-7 20:31:09
|
查看: 131|
回复: 0
发表于 2026-5-7 20:31:09
|
查看: 131|
回复: 0
