曾经遇到过一次诡异的线上故障:服务响应突然变得很慢,但日志里没有任何报错,CPU 和内存也都在正常范围。
折腾半天,最后靠一条命令锁定了真凶:
ss -antp | grep CLOSE_WAIT | wc -l
输出: 4096
四千多个 CLOSE_WAIT 。连接泄漏,文件描述符都快耗尽了。
这便是 ss / netstat 的核心价值——无需额外埋点、不用重启服务,一条命令就能把当前所有 TCP 连接的状态直接摊在桌面上。很多问题,看一眼就明白了。
这篇文章会把这两个工具从原理到实战彻底梳理一遍,让你下回面对网络问题时,不再“抓瞎”。
一、先把 TCP 状态搞明白
工具本身用起来不难,但要真正看懂输出,得先理解 TCP 的连接状态。
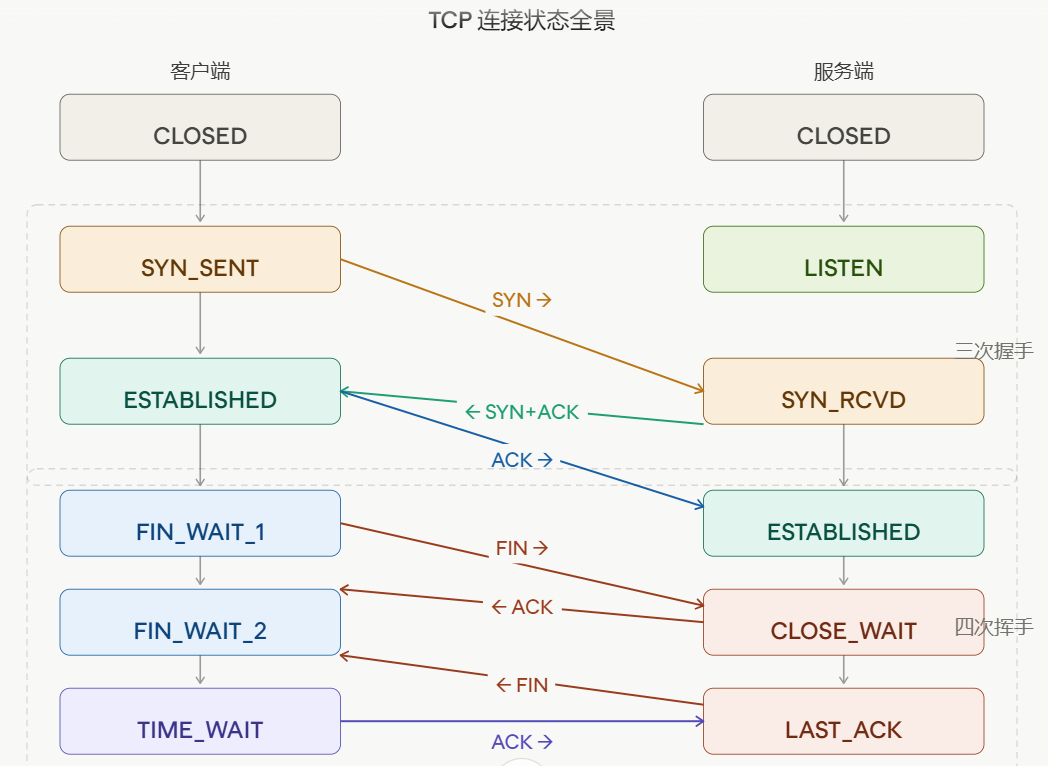
上图已经把常见的状态变迁画得很清晰了,下面再补充几点关键解释:
三次握手(建立连接) :
- 客户端发 SYN → 进入
SYN_SENT
- 服务端收到,回 SYN+ACK → 进入
SYN_RCVD
- 客户端再回 ACK → 双方都进入
ESTABLISHED ,连接建立完成
四次挥手(关闭连接) :
- 主动关闭方发 FIN → 进入
FIN_WAIT_1
- 对方回 ACK → 进入
FIN_WAIT_2(此时对方仍然可以继续发送数据)
- 对方发完数据,发 FIN → 主动关闭方进入
TIME_WAIT ,被动方进入 LAST_ACK
- 主动关闭方回 ACK → 等待 2MSL 时间后彻底关闭
排查问题,记住下面这几个最重要的状态就够了,搞定 90% 的故障不在话下:
| 状态 |
出现在哪方 |
表示什么 |
大量出现意味着 |
ESTABLISHED |
双方 |
正常连接 |
正常;但数量过大多因连接池未限制 |
TIME_WAIT |
主动关闭方 |
等待2MSL |
短连接过多,属正常现象,但数量过万需警惕 |
CLOSE_WAIT |
被动关闭方 |
对方已关闭,本地尚未关闭 |
连接泄漏,代码没有调用 close() |
SYN_SENT |
客户端 |
等待服务端响应 |
连接建立慢或被目标端拒绝 |
LISTEN |
服务端 |
监听端口,等待连接 |
正常状态 |
二、netstat vs ss:到底该用哪个?
不少文章把这两个工具混着讲,这里明确一下区别:
netstat 是老牌工具,几乎在所有系统上都预装了,功能很全。但它有个致命弱点:连接数量一多,速度会非常慢。因为它要从 /proc/net/tcp 里读取信息,再逐条进行解析。
ss(socket statistics)是新一代工具,直接通过 netlink 接口读取内核的连接信息,速度极快,哪怕是十万条连接的规模也能秒出结果。
结论很明确:优先用 ss ,只有在没有 ss 的环境中再退回到 netstat 。两者常用的参数几乎是完全对应的。
三、最常用的几条命令
查看所有 TCP 连接
# ss(推荐)
ss -antp
# netstat(备用)
netstat -antp
参数说明:-a 显示所有连接、-n 不解析域名(会快很多)、-t 只看TCP、-p 显示进程名
典型输出如下:
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 128 0.0.0.0:8080 0.0.0.0:* users:(("myapp",pid=1234))
ESTAB 0 0 10.0.0.1:8080 10.0.0.2:54321 users:(("myapp",pid=1234))
TIME-WAIT 0 0 10.0.0.1:8080 10.0.0.3:54322
有几个字段要特别留意:
- Recv-Q:接收缓冲区里积压的字节数。在
LISTEN 状态下,这个值代表等待 accept 的连接数。如果持续不为 0,就说明 accept 处理 跟不上请求进来的速度了。
- Send-Q:发送缓冲区积压的字节数。如果持续不为 0,说明对端接收数据变慢了。
统计各状态的数量(最常用)
ss -ant | awk 'NR>1 {print $1}' | sort | uniq -c | sort -rn
输出类似这样,一眼就能看出哪个状态不对劲:
4096 CLOSE-WAIT
256 ESTABLISHED
12 TIME-WAIT
1 LISTEN
查看特定端口的连接
# 查看 8080 端口
ss -antp sport = :8080
# 查看连接到某个远端 IP 的所有连接
ss -antp dst 10.0.0.2
只看某一种状态的连接
# 只看 ESTABLISHED
ss -antp state established
# 只看 CLOSE_WAIT(排查连接泄漏必用)
ss -antp state close-wait
# 只看 TIME_WAIT
ss -antp state time-wait
统计模式:快速看连接数全局
# 当前 TCP 连接的统计总览
ss -s
输出示例:
Total: 1024
TCP: 512 (estab 256, closed 200, orphaned 12, timewait 44)
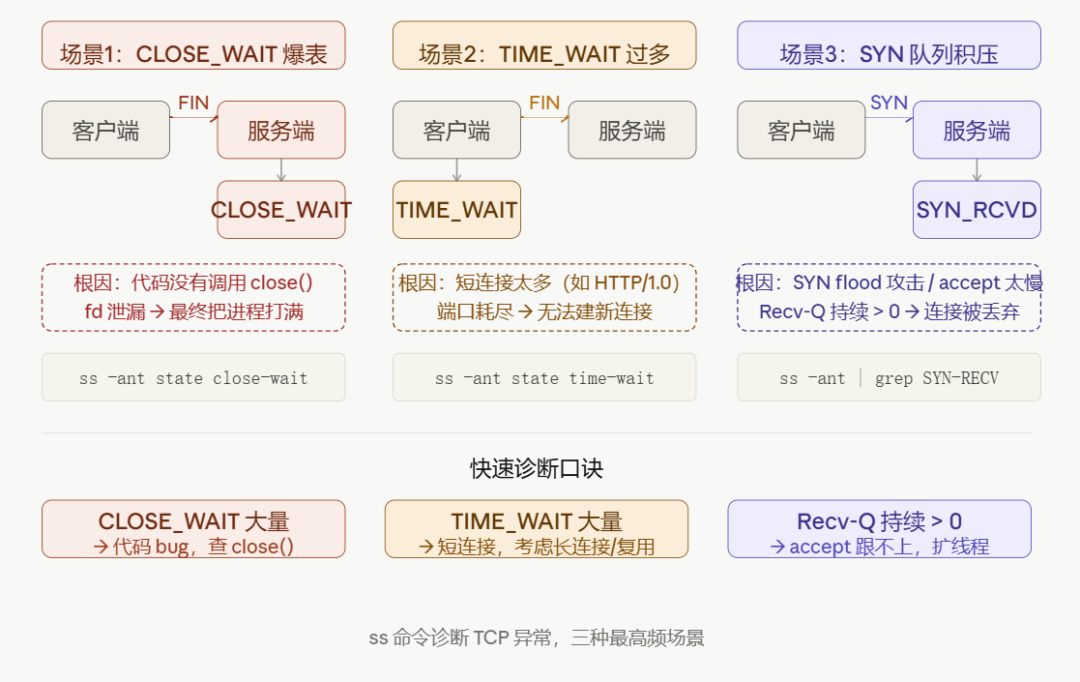
四、图解:三种最常见的异常场景
下面这张图梳理了线上最高频的三种 TCP 异常,一看就明白。
五、三个真实排查场景,手把手走一遍
场景一:CLOSE_WAIT 堆积——连接泄漏
症状:服务跑着跑着逐渐变慢,日志查不出任何报错,重启后恢复,但过段时间又开始循环。
先跑一条统计命令看看状态分布:
ss -ant | awk 'NR>1{print $1}' | sort | uniq -c | sort -rn
输出结果触目惊心:
3847 CLOSE-WAIT
128 ESTABLISHED
1 LISTEN
接下来定位是哪个进程在泄漏:
ss -antp state close-wait | head -20
找到对应的端口和进程后,翻开代码一查便知——必然存在某个异常逻辑分支,连接用完后没能进入 finally 块来执行关闭操作。
CLOSE_WAIT 的本质是什么呢?对方已经给你发了 FIN,意思是“我说完了”,但你的代码就是没调用 close() ,连接就那么一直挂着,白白占用文件描述符。等累积到 ulimit -n 的上限,新请求就完全进不来了。
解决方法:从代码层面根治,比如用 try-with-resources,或者严格保证在 finally 里关闭连接,千万别指望靠 GC 来回收。
场景二:TIME_WAIT 过多——端口快耗尽了
症状:高并发场景下,压测一段时间后,大量新建连接失败,报错 Cannot assign requested address 。
先看全局统计:
ss -s
输出令人担忧:
Total: 65280
TCP: 62000 (estab 200, closed 61500, timewait 61200)
六万多个 TIME_WAIT !系统默认的临时端口范围通常是 32768~60999 ,总共才两万多个,端口早已被耗尽。
TIME_WAIT 本身是正常状态,它只出现在主动关闭方,会等待 2 倍 MSL(通常共 60 秒)才会彻底释放,目的是为了让网络中残留的数据包有足够的时间消散。但短连接高并发的场景下(比如使用 HTTP/1.0,每次请求都建新连接), TIME_WAIT 极其容易堆满。
应对方案有这样几个:
- 开启长连接(HTTP keep-alive),这是最根本的解法。
- 开启
tcp_tw_reuse ,允许新连接复用处于 TIME_WAIT 状态的端口:
sysctl -w net.ipv4.tcp_tw_reuse=1
- 扩大本地端口范围以应急:
sysctl -w net.ipv4.ip_local_port_range="1024 65535"
场景三:Recv-Q 不为零——accept 处理跟不上了
症状:服务端 CPU 使用率明明不高,但客户端频繁出现连接超时。
查看监听套接字的状态:
ss -antp | grep LISTEN
输出如下:
State Recv-Q Send-Q Local Address:Port
LISTEN 128 128 0.0.0.0:8080
在 LISTEN 状态下的 Recv-Q ,其含义是已完成三次握手、正等待应用调用 accept 的连接数。这里已经到了 128,也就是 backlog 的上限。此时,新到达的连接会直接被内核丢弃,在客户端看来就是连接超时。
这通常意味着处理请求的线程池太小,或者 accept 之后进行的处理过程太慢,导致了积压。可以先把 backlog 调大来应急:
sysctl -w net.core.somaxconn=65535
根本解法依然是扩充处理线程/协程,或是进行异步化改造。
六、常用命令速查
# 查所有 TCP 连接(推荐加 -n,速度快很多)
ss -antp
# 统计各状态的数量
ss -ant | awk 'NR>1{print $1}' | sort | uniq -c | sort -rn
# 只看 CLOSE_WAIT(连接泄漏排查)
ss -antp state close-wait
# 只看 TIME_WAIT(端口耗尽排查)
ss -antp state time-wait
# 只看 ESTABLISHED(当前活跃连接)
ss -antp state established
# 查某个端口的连接情况
ss -antp sport = :8080
# 查连到某个目标 IP 的连接
ss -antp dst 10.0.0.2
# 实时监控连接数变化(每秒刷新)
watch -n 1 'ss -s'
# 查看 LISTEN 状态的 Recv-Q(是否有积压)
ss -antp | grep LISTEN
# 综合统计(类似 netstat -s)
ss -s
七、ss 和 netstat 常用参数对照
| 功能 |
ss 写法 |
netstat 写法 |
| 查所有 TCP |
ss -antp |
netstat -antp |
| 只看监听端口 |
ss -lntp |
netstat -lntp |
| 指定状态过滤 |
ss -antp state established |
netstat -antp \| grep ESTABLISHED |
| 统计总览 |
ss -s |
netstat -s |
| 按端口过滤 |
ss -antp sport = :80 |
netstat -antp \| grep :80 |
结论很明确了:ss 更快、更灵活,其原生的 state 过滤功能是 netstat 所不具备的,强烈推荐切换过来使用。
八、和 strace 配合使用
有时候光看连接状态还不够,比如发现一堆 CLOSE_WAIT 却不确定具体是哪段代码没关连接,这时候可以结合 strace 来追踪行为。
# 先用 ss 找到问题进程的 PID
ss -antp state close-wait | grep myapp
# 再用 strace 追踪这个进程的系统调用,看 close(fd) 有没有被调用
strace -p <pid> -e trace=close,shutdown
如果说 ss 让你看到的是“当前的状态”,那 strace 让你看到的就是“行为的过程”,两者配合,能大幅缩短定位问题的时间。
写在最后
下次线上服务再出网络问题,先别急着改配置、改代码。
跑一下这条命令,看看各种状态的数量分布,80% 的问题当场就有排查方向了:
ss -ant | awk 'NR>1{print $1}' | sort | uniq -c | sort -rn
CLOSE_WAIT 激增 → 代码没关连接,去查 close()TIME_WAIT 激增 → 短连接太多,考虑改用长连接或连接复用Recv-Q > 0 → accept 处理跟不上请求速度,考虑扩线程或加大 backlog
只有当理解了 TCP 各个状态背后的含义,工具在你手里才能发挥最大价值。所以说,工具是手段,理解才是根本。
 发表于 2026-5-7 20:26:56
|
查看: 130|
回复: 0
发表于 2026-5-7 20:26:56
|
查看: 130|
回复: 0
