AI记忆的难点,从来不在“存”,而在“取”和“保”。
昨天聊了Clawdbot到Moltbot的改名风波,但名字不是重点。我更在意的是它背后的一个设计:它如何把“长期记忆”做稳。因为改名只是一次突发事件;而记忆系统决定的,是一个Agent能否在现实世界中长期运行,能否在第30次对话时依然保持靠谱。
“AI记忆”常被讲成模型能力,但落到工程现场,问题会变得很具体,也很不浪漫:
- 对话一长就要压缩,压缩是有损的
- 工具输出会膨胀上下文,成本和延迟一起上涨
- 记忆文件越堆越多,真正需要的那条信息反而更难召回
Clawdbot给出的答案非常克制:把记忆当作工作区里的Markdown文件,把回忆交给工具检索,把“丢失风险”收敛到“压缩前刷新”这一道闸口。
这套路线的价值不在“新”,而在三件事:可解释、可编辑、可迁移。
太长不看版
- 上下文(Context):模型一次请求能看到的全部内容,短暂、有界、昂贵。
- 记忆(Memory):磁盘上的内容,持久、无界、可版本化。
- Clawdbot的记忆默认是工作区纯Markdown:
memory/YYYY-MM-DD.md + 可选的 MEMORY.md。(官方英文文档的原话:plain Markdown in the agent workspace)
- 会话开始会读取今天 + 昨天的每日文件;
MEMORY.md 只在主私人会话加载,群组上下文永不加载。这一条非常关键——我们经常忽略“群聊泄露个人上下文”的风险面。
- 写入没有专用
memory_write:就是普通文件写入。也正因为如此,记忆本质上是“可审计的资产”,而不是“黑盒状态”。
- 压缩前刷新(pre-compaction memory flush)是关键闸口:接近自动压缩时先静默写入持久记忆,再允许压缩发生。
- 刷新默认是静默轮次,通常用
NO_REPLY 抑制输出,让用户侧无感。2026.1.10 之后的版本,流式输出如果以 NO_REPLY 开头也会被抑制,避免半截内容泄露到用户侧。
- 记忆检索工具:
memory_search(片段召回,带文件 + 行范围)+ memory_get(按路径读取内存文件,支持 startLine + lines 参数做精确定位)。
- 向量检索解决“意思相近”,BM25 解决“精确命中”,混合更稳。
- 混合合并的默认思想是简单加权:
finalScore = vectorWeight * vectorScore + textWeight * textScore(默认权重 0.7/0.3)。
- 索引存储是可重建的派生数据:每个代理一个 SQLite,默认在
~/.clawdbot/memory/<agentId>.sqlite。
- 索引会记录嵌入提供程序 + 模型 + 端点指纹 + 分块参数,任何一项变化都会触发自动重建。
- 除了压缩,还需要会话修剪(session pruning):每次请求前修剪旧工具结果,避免上下文被日志淹没,尤其是 Anthropic 的 TTL 缓存过期场景。
- 工作区文件(
AGENTS.md、SOUL.md、USER.md、IDENTITY.md、TOOLS.md、HEARTBEAT.md)在每个会话开始时被注入系统提示;大文件会被截断(默认上限 20000 字符)。
01|先把“上下文”与“记忆”拆开:调试时就不会乱
在 Clawdbot 的定义里:
- 上下文:发送给模型的所有内容(系统提示、对话历史、工具结果、附件),受模型上下文窗口限制。
- 记忆:存储在磁盘上,后续可重新加载或被检索的内容。
我自己快速检查上下文膨胀时,常用命令是:
/status:窗口使用概览与会话设置/context list:注入内容清单与大小/context detail:更细的拆分(文件、技能列表、工具 schema 的开销)/usage tokens:把 token 使用情况附在回复页脚/compact:手动触发压缩
这些命令的共同目标是:让“模型看到了什么”变得可观测,否则记忆系统的优化会变成盲调。
02|文件系统即记忆:两层结构把“流水账”和“长期事实”隔离开
Clawdbot 的内存文件默认是两层:
memory/YYYY-MM-DD.md
MEMORY.md(可选)
- 精选的长期内存
- 仅在主私人会话加载,群组上下文永不加载
我自己踩过的坑:在群聊里问助手“我之前的决定是什么”,结果它一无所知——因为 MEMORY.md 根本没被加载。这不是 bug,是安全设计。群聊场景永远不应该注入个人上下文。
写入策略同样分层:
- 决策、偏好、持久事实写入
MEMORY.md
- 日常运行上下文写入
memory/YYYY-MM-DD.md
- 出现“记住这个”的指令时,我建议立刻落盘,不要让助手“脑内记住”——“Mental notes” don‘t survive session restarts. Files do.(这句话来自官方
AGENTS.md 模板,我觉得说得很好)
这种拆分的工程意义非常直接:
- 每日文件允许“低摩擦记录”,我们不追求结构化完美
MEMORY.md 保持“小而稳”,更接近“每次都值得读”的核心事实区- 群聊不注入
MEMORY.md,避免个人上下文泄露到共享场景
03|“压缩前刷新”是记忆系统的保险丝
长对话不可避免触达上下文上限,压缩也不可避免。
压缩操作本质上,是把旧对话总结为紧凑摘要,并持久化到会话 JSONL 中;最近消息保持完整。压缩是有损的——这不是 Clawdbot 的缺陷,而是所有上下文有限的模型必须面对的物理约束。
Clawdbot 在接近自动压缩时,会触发自动内存刷新(压缩前 ping):
- 先运行一个静默的代理轮次
- 提醒模型把“应该持久保存”的内容写入内存文件
- 通常用
NO_REPLY 抑制用户可见输出
对应的配置入口是 agents.defaults.compaction.memoryFlush,示例:
{
agents: {
defaults: {
compaction: {
reserveTokensFloor: 20000,
memoryFlush: {
enabled: true,
softThresholdTokens: 4000,
systemPrompt: "Session nearing compaction. Store durable memories now.",
prompt: "Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store."
}
}
}
}
}
几个容易踩坑的边界也在文档里写得很清楚:
- 触发是“软阈值”策略:当估算 token 超过
contextWindow - reserveTokensFloor - softThresholdTokens 时执行刷新。
- 每个压缩周期只刷新一次,避免频繁打扰。
- 工作区必须可写;如果会话在
workspaceAccess: "ro" 或 "none" 中运行,会跳过刷新。
- 静默的实现细节:如果模型回复以
NO_REPLY 开头,Clawdbot 不仅不递送最终消息,还会抑制流式输出,避免用户看到半截内容。
我自己觉得这一段机制,是“长会话不失忆”的关键。
04|记忆检索:我们先把“召回单位”做对
Clawdbot 的记忆检索工具是两段式:
memory_search
- 语义搜索来自
MEMORY.md + memory/**/*.md
- 返回片段文本(上限约 700 字符)、文件路径、行范围、分数、提供程序/模型信息
- 不返回完整文件负载,避免把上下文窗口塞满
memory_get
- 读取特定内存 Markdown 文件
- 支持
startLine + lines 参数做精确定位(而不是一次性拉全文)
- 拒绝
MEMORY.md / memory/ 之外的路径——这是一条重要的安全边界
这两点看似细节,实际决定了“记忆系统会不会反噬上下文”:
- 召回单位越大,上下文越容易被污染
- 召回单位过小,信息缺乏自足性,模型会“脑补”
Clawdbot 的选择是:以 Markdown 块为召回单位,目标约 400 token,带 80 token 重叠,并且返回可追溯引用(文件 + 行范围)。
05|混合搜索:BM25 解决精确命中,向量解决语义改写
纯向量检索往往输在“高信号精确 token”:
- ID(例如短哈希
a828e60、b3b9895a…)
- 配置路径(
memorySearch.query.hybrid)
- 环境变量名
- 代码符号
- 具体错误字符串(
"sqlite-vec unavailable")
Clawdbot 的做法是混合:
- 向量相似度:语义匹配,措辞不同也能召回
- BM25 关键词相关性(FTS5):精确 token 更稳
官方文档里有一句话我很喜欢:“Vector search is great at ‘this means the same thing’… But it can be weak at exact, high-signal tokens.”
合并方式强调简单可控。文档给了实现草图:
- 两侧各取候选池(向量 + BM25),数量是
maxResults × candidateMultiplier
- BM25 rank 转成 0..1 的
textScore:
textScore = 1 / (1 + max(0, bm25Rank))
- 按块 ID 合并候选并加权:
finalScore = vectorWeight * vectorScore + textWeight * textScore
配置示例(默认权重 0.7/0.3):
agents: {
defaults: {
memorySearch: {
query: {
hybrid: {
enabled: true,
vectorWeight: 0.7,
textWeight: 0.3,
candidateMultiplier: 4
}
}
}
}
}
还有两个很务实的降级策略:
- 平台上无法使用全文搜索时,回退到仅向量
- sqlite-vec 扩展不可用时,回退到进程内余弦相似度(不硬失败)
官方文档对这套策略的定位是:“This isn’t ‘IR-theory perfect’, but it‘s simple, fast, and tends to improve recall/precision on real notes.”——我自己的体感也是这样,能解释、能调参、能降级,比学术完美更重要。
06|索引与提供程序:派生数据可重建,密钥能力要单独算
索引存储是每个代理一个 SQLite,默认路径:
~/.clawdbot/memory/<agentId>.sqlite
索引由文件变更触发标脏(防抖 1.5 秒),同步可以在会话开始、搜索时、或按调度异步运行。
一个很重要的自动化行为:索引会记录嵌入提供程序 + 模型 + 端点指纹 + 分块参数,任何一项变化都会触发自动重建。这意味着我们换个嵌入模型,不需要手动清索引。
向量检索的嵌入提供程序选择也有明确规则:
- 如果配置了本地模型路径且存在,优先
local
- 如果能解析 OpenAI 密钥,选择
openai
- 如果能解析 Gemini 密钥,选择
gemini
- 否则禁用内存搜索,直到配置完成
这里有一个容易被忽略的工程点:
- Codex OAuth 仅覆盖聊天/补全,不覆盖嵌入
- 远程嵌入仍需要单独的 API Key
对于“离线优先”的场景,本地嵌入的默认模型是 hf:ggml-org/embeddinggemma-300M-GGUF/embeddinggemma-300M-Q8_0.gguf(约 0.6 GB),会自动下载到缓存目录。但 node-llama-cpp 可能需要先跑一次 pnpm approve-builds,否则本地嵌入会回退到远程。
07|压缩之外,还需要会话修剪:别让工具输出吞掉上下文
压缩会把旧对话总结为持久条目。
但还有一类膨胀更隐蔽:工具结果(toolResult)。
一次 exec、一次抓取网页、一次读取大文件,可能带来几十 KB 的文本。把这些结果长期留在运行上下文里,会直接导致:
- 上下文更快触顶
- 缓存命中下降,TTL 过期后重新缓存更贵
- “真正重要的消息”被淹没在工具噪音里
Clawdbot 的会话修剪(Session Pruning)做的是一件很明确的事:
- 每次 LLM 调用之前,从内存上下文里修剪旧工具结果
- 不会重写磁盘上的会话历史(
*.jsonl)
- 仅影响本次请求发送给模型的消息集合
默认启用的策略是 cache-ttl:
- 仅当最后一次 Anthropic 调用早于
ttl 时才运行修剪
- 目标是缩小 TTL 过期后的第一次请求的
cacheWrite 体积,让重新缓存更便宜
默认行为还区分了两种修剪:
- 软修剪:只针对过大的工具结果,保留头尾并插入
...,跳过包含图像块的结果
- 硬清除:用占位符替换整个工具结果
示例配置(启用 TTL 感知修剪):
{
agent: {
contextPruning: { mode: "cache-ttl", ttl: "5m" }
}
}
默认值也值得一看(启用时):
keepLastAssistants: 3(保护最近几条助手消息之前的工具结果不被清除)minPrunableToolChars: 50000softTrim.maxChars: 4000hardClear.placeholder: "[Old tool result content cleared]"
一句话总结这部分:压缩解决“历史太长”,修剪解决“工具太吵”。
图1:Clawdbot 记忆闭环架构(写入、索引、召回、刷新、压缩)
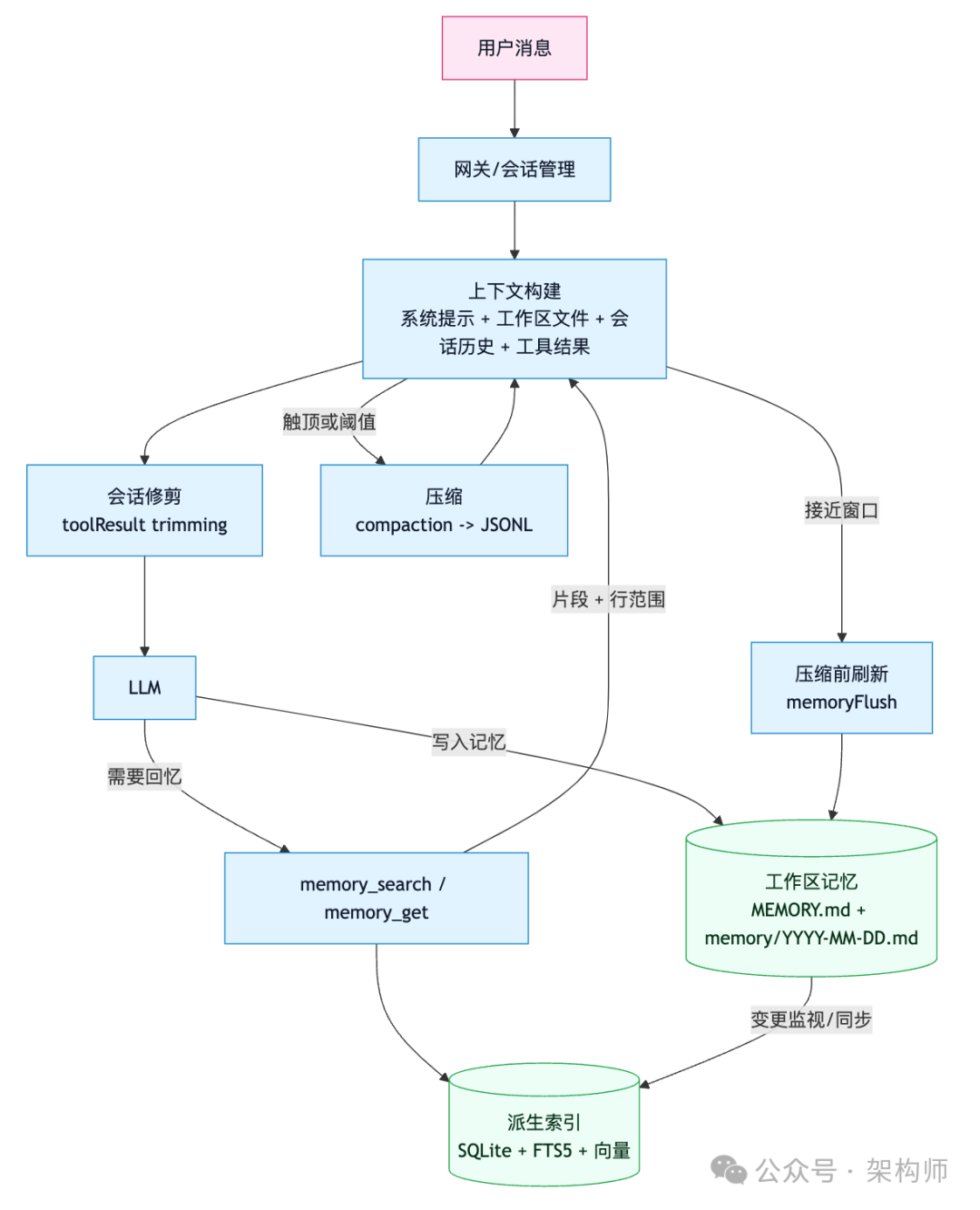
08|我们把作业抄走:一套最小可行的“文件记忆系统”怎么搭
不绑定 Clawdbot,我们也能把核心思想落地。关键是把边界立住,再逐步扩展。这套思路涉及很多系统设计层面的考量,值得仔细推敲。
1)把“记忆文件”做成规范,而不是随手堆文本
memory/YYYY-MM-DD.md:仅追加,放运行轨迹与当天上下文MEMORY.md:精选长期事实/偏好/决策,保持小而稳定
我自己的做法是:落盘规则写进“项目规则文件”(类似 AGENTS.md 的位置与触发条件),避免靠临场对话约定。
2)写入时机必须包含“压缩前刷新”
只依赖“用户想起来才让写”是不够的。我自己觉得最少也要有三个触发:
- 显式“记住这个”
- 会话接近压缩阈值(预压缩刷新,我建议静默)
- 会话结束或重置前(把临时线索升级为长期事实,或明确丢弃)
3)检索不要返回整本记忆
召回我建议遵循两条硬约束:
- 只返回片段(带出处:文件 + 行范围)
- 只允许读取白名单路径(内存目录之外拒绝)
这既是成本控制,也是安全边界。
4)混合检索优先于“只上向量库”
工程上我们最常见的查询分两类:
- 自然语言模糊查询(适合向量)
- 精确 token 命中(适合 BM25/FTS)
混合权重我们不需要复杂,先能解释、能调参、能降级。
5)索引必须是派生数据,可随时重建
索引库坏了就能重建,这是我们“可维护”的底线。
- canonical:Markdown 文件(可版本化)
- derived:SQLite/向量索引(可重建)
6)把“工具输出膨胀”当成记忆系统的一部分来治理
长期运行的 Agent,工具输出往往比对话更占窗口。
结尾:记忆系统的目标不是“记得多”,而是“想得起、丢不掉、讲得清”
Clawdbot 这套设计最大的优点,在我看来是把“记忆”从玄学拉回工程:
- 记忆是文件,用户可读可改
- 回忆靠工具检索,按需注入片段
- 长对话靠“压缩前刷新”兜底,重要信息先落盘
- 工具噪音靠修剪治理,避免上下文被日志吞没
这套路线不追求豪华配置,追求稳定边界与可解释的机制。关于AI Agent和后端架构的更多实践思考,也欢迎到云栈社区与更多开发者交流探讨。
 发表于 2026-2-5 03:23:38
|
查看: 248|
回复: 0
发表于 2026-2-5 03:23:38
|
查看: 248|
回复: 0
