在终端执行 ls -l myfile.txt 命令时,屏幕上会显示文件的权限、大小、时间戳等信息。你是否想过,Linux 系统是如何记住这些细节的?又为什么删除一个 10GB 的大文件几乎瞬间完成,而复制同样的文件却需要好几分钟?
这些问题的答案,都藏在文件系统的两个核心概念里:Inode(索引节点)和 Block(数据块)。它们不仅是文件存储的技术基石,更是理解 Linux 性能优化、数据恢复乃至系统调优的关键。本文将深入它们的底层逻辑,揭示 Linux 是如何高效、可靠地管理海量文件的。
为什么需要 Inode 与 Block?
在理解 Inode 和 Block 之前,我们先要思考文件系统面对的一个根本问题:磁盘的物理结构是连续的扇区(通常为 512 字节),而文件的大小、属性(权限、所有者、时间等)千差万别。系统如何高效地管理它们?
如果直接将文件内容按扇区顺序存储,会遇到两个致命缺陷:首先是碎片化——小文件会浪费扇区的剩余空间;同时,大文件很难被连续存放,往往被拆分成多个不连续的扇区,读取时需要频繁寻址,效率极低。其次是属性缺失——系统无法快速获取文件的权限、修改时间等关键信息,只能逐个读取扇区内容来判断,操作成本极高。
为了解决这些问题,Linux 引入了“索引与数据分离”(或者说元数据与数据分离)的设计思想:用 Block 统一管理文件数据(解决碎片化问题),用 Inode 专门记录文件属性与 Block 位置(解决属性查询与寻址效率问题)。
核心解析:inode
Inode(Index Node,索引节点)是 Linux 系统中文件的唯一标识。它本身不存储文件内容,而是专门记录文件的核心属性和文件数据所在的 Block 地址。每个文件都对应一个唯一的 Inode,系统通过 Inode 编号来识别文件,而不是我们看到的文件名。
通过 stat 命令可以查看一个文件的 Inode 信息:
stat ./README
File: ./README
Size: 727 Blocks: 8 IO Block: 4096 regular file
Device: 8,48 Inode: 67014 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ zhangzs) Gid: ( 1000/ zhangzs)
Access: 2025-12-23 19:43:08.186537162 +0800
Modify: 2025-12-17 21:51:26.523557371 +0800
Change: 2025-12-17 21:51:26.523557371 +0800
Birth: 2025-12-17 21:51:26.523557371 +0800
那么,一个 Inode 里到底包含了哪些信息呢?我们可以从 Linux 内核源码(以 5.x 版本为例)中一窥其复杂的结构设计。以下是对 struct inode 关键字段的解析:
/*
* 1. 将频繁访问的字段(RCU路径查找、stat数据)放在结构体开头,利用CPU缓存局部性
* 2. 读写分离:读多写少的字段放前面,需要加锁的字段放后面
* 3. 随机化布局防止安全攻击(__randomize_layout)
*/
struct inode {
/* ============ 第一部分:基础身份标识 ============ */
umode_t i_mode; /* 文件类型和权限(16位)
* 低12位:权限位 (rwxrwxrwx)
* 高4位:文件类型(普通文件、目录、符号链接等)
* 例如:0x81A4 = 普通文件,权限644
*/
unsigned short i_opflags; /* 操作标志位(内部使用)
* IOP_FASTSYNC, IOP_NOFOLLOW等
* 影响inode操作的行为
*/
kuid_t i_uid; /* 文件所有者用户ID(内核用户ID)
* 现代内核使用kuid_t而非uid_t,支持用户命名空间
*/
kgid_t i_gid; /* 文件所属组ID(内核组ID)
* 同样支持命名空间
*/
unsigned int i_flags; /* 文件系统级别的标志位
* 如:S_SYNC(同步写入)、S_IMMUTABLE(不可变)
* S_APPEND(仅追加)、S_NOATIME(不更新访问时间)
*/
/* ============ 第二部分:访问控制与安全 ============ */
#ifdef CONFIG_FS_POSIX_ACL
struct posix_acl *i_acl; /* 访问控制列表(ACL)
* 细粒度权限控制,超越传统的9位权限
* 需要内核配置CONFIG_FS_POSIX_ACL
*/
struct posix_acl *i_default_acl; /* 默认ACL(用于目录)
* 目录下新建文件/目录时继承的ACL
*/
#endif
/* ============ 第三部分:操作函数表与基础关联 ============ */
const struct inode_operations *i_op; /* inode操作函数表(虚函数表)
* 包含:lookup、create、link、unlink、mkdir等
* 这是VFS实现多态的关键
*/
struct super_block *i_sb; /* 指向所属超级块
* 超级块包含文件系统全局信息
* 通过i_sb可以找到挂载点、文件系统类型等
*/
struct address_space *i_mapping; /* 地址空间对象(页缓存管理)
* 指向i_data或独立地址空间
* 管理文件的页缓存、脏页回写等
*/
#ifdef CONFIG_SECURITY
void *i_security; /* 安全模块私有数据
* SELinux、AppArmor等安全模块可在此挂接数据
* 需要内核配置CONFIG_SECURITY
*/
#endif
/* ============ 第四部分:统计信息(stat数据) ============ */
/* 部分数据不从路径查找访问,主要供stat()使用 */
unsigned long i_ino; /* inode号码(在同一文件系统内唯一)
* 虽然定义为unsigned long,但实际大小依赖文件系统
* ext4支持32位或64位inode号
*/
/*
* 重要设计:i_nlink的访问限制
* 文件系统不能直接修改i_nlink,必须使用以下函数:
* - set_nlink(inode, nlink) 设置链接数
* - inc_nlink(inode) 增加链接数
* - drop_nlink(inode) 减少链接数
* - clear_nlink(inode) 清除链接数
* - inode_inc_link_count(inode) 增加链接数并检查是否超过上限
* - inode_dec_link_count(inode) 减少链接数
*/
union {
const unsigned int i_nlink; /* 外部只读视图:硬链接计数
* 当链接数为0时,inode可能被删除
* ext4最大链接数:65000(16位限制)
*/
unsigned int __i_nlink; /* 内部可修改视图
* 通过上述函数修改,避免竞态条件
*/
};
dev_t i_rdev; /* 设备文件的主/次设备号
* 仅对字符设备或块设备文件有意义
* 例如:0x0801 = 主设备号8,次设备号1
*/
loff_t i_size; /* 文件大小(字节)
* loff_t是64位有符号整数
* 目录的i_size通常是块大小的整数倍
*/
struct timespec64 i_atime; /* 最后访问时间(64位纳秒精度)
* 解决2038年问题的timespec64
* 某些文件系统挂载时可禁用atime更新(noatime)
*/
struct timespec64 i_mtime; /* 最后修改时间(内容修改)
* 通常tar、cp等命令会更新此时间
*/
struct timespec64 i_ctime; /* 最后改变时间(inode元数据修改)
* chmod、chown等命令会更新此时间
*/
spinlock_t i_lock; /* 保护以下字段的自旋锁:
* - i_blocks(块计数)
* - i_bytes(文件最后一个不完整块的字节数)
* - 有时也保护i_size(取决于文件系统)
* 快速锁,适用于短临界区
*/
unsigned short i_bytes; /* 文件最后一个块的字节数(0~块大小-1)
* 例如:文件大小1005字节,块大小1024
* 则i_bytes = 1005 % 1024 = 1005
* (因为文件未占满一个块)
*/
u8 i_blkbits; /* 块大小位数(log2(块大小))
* 例如:块大小4096字节,则i_blkbits = 12
* 因为2^12 = 4096
*/
u8 i_write_hint; /* 写入提示(I/O调度优化)
* 来自fadvise()的提示:如WRITE_LIFE_*
* 帮助SSD等设备优化写入策略
*/
blkcnt_t i_blocks; /* 文件占用的512字节扇区数
* 注意:不是文件系统块数,而是固定512字节单位
* 用于stat命令显示"Blocks:"
*/
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount; /* 顺序锁,保护i_size的原子读写
* 用于需要原子更新i_size的场景
* 通常用于网络文件系统
*/
#endif
/* ============ 第五部分:状态与同步 ============ */
unsigned long i_state; /* inode状态标志位
* I_DIRTY_SYNC/I_DIRTY_DATASYNC(脏页需要同步)
* I_DIRTY_PAGES(页缓存脏)
* I_NEW(新分配未初始化的inode)
* I_FREEING(正在释放)
* I_WILL_FREE(即将释放)
* I_CLEAR(已被清除)
*/
struct rw_semaphore i_rwsem; /* 读写信号量,保护inode内容
* 用于文件截断、目录修改等操作
* 允许多个读或单个写
*/
/* ============ 第六部分:脏页与回写管理 ============ */
unsigned long dirtied_when; /* 首次变脏的时间(jiffies)
* 用于writeback策略,优先回写旧的脏inode
*/
unsigned long dirtied_time_when; /* 类似dirtied_when,但以秒为单位
* 用于/proc/sys/vm/dirty_expire_centisecs
*/
/* ============ 第七部分:哈希与链表管理 ============ */
struct hlist_node i_hash; /* 哈希表节点,用于inode缓存查找
* 内核维护全局inode哈希表,加速inode查找
* 哈希键值:(super_block, inode_number)
*/
struct list_head i_io_list; /* 回写IO链表
* 链接到super_block->s_inodes或writeback列表
* 用于管理需要回写的inode
*/
#ifdef CONFIG_CGROUP_WRITEBACK
/* 控制组回写相关字段 */
struct bdi_writeback *i_wb; /* 关联的回写控制结构
* 用于cgroup writeback,将回写IO按cgroup分组
*/
int i_wb_frn_winner; /* 外来源inode检测(竞争解决) */
u16 i_wb_frn_avg_time;
u16 i_wb_frn_history;
#endif
struct list_head i_lru; /* LRU链表节点(最近最少使用)
* 用于内核inode缓存淘汰算法
* 当系统内存不足时,从LRU淘汰不活跃inode
*/
struct list_head i_sb_list; /* 超级块inode链表
* 链接到super_block->s_inodes
* 便于遍历文件系统所有inode
*/
struct list_head i_wb_list; /* 回写链表(旧接口,逐步淘汰) */
union {
struct hlist_head i_dentry; /* dentry哈希表头
* 所有指向此inode的dentry都链接在此
* 用于inode引用计数和快速查找dentry
*/
struct rcu_head i_rcu; /* RCU回调头,用于安全释放inode
* RCU(Read-Copy-Update)是一种无锁同步机制
*/
};
/* ============ 第八部分:版本与引用计数 ============ */
atomic64_t i_version; /* 版本号(每次修改递增)
* 用于NFS等网络文件系统,检测文件变化
* 也用于某些应用的缓存有效性检查
*/
atomic64_t i_sequence; /* 序列号(用于futex机制)
* 某些场景下替代i_version,避免ABA问题
*/
atomic_t i_count; /* 引用计数(当前使用此inode的进程数)
* 通过iget()增加,iput()减少
* 当i_count为0时,inode可被回收
*/
atomic_t i_dio_count; /* 直接IO引用计数
* 跟踪正在进行直接IO(绕过页缓存)的进程
*/
atomic_t i_writecount; /* 写者引用计数
* 跟踪以写模式打开文件的进程数
* 用于实现O_APPEND等语义
*/
#if defined(CONFIG_IMA) || defined(CONFIG_FILE_LOCKING)
atomic_t i_readcount; /* 读者引用计数(只读打开)
* 用于IMA(完整性测量架构)或文件锁定
* 跟踪以只读模式打开文件的进程
*/
#endif
/* ============ 第九部分:文件操作与锁 ============ */
union {
const struct file_operations *i_fop; /* 文件操作函数表(原i_op->default_file_ops)
* 包含:read、write、mmap、fsync等
* 文件打开时从i_op复制过来
*/
void (*free_inode)(struct inode *); /* inode释放回调函数
* 某些文件系统(如ramfs)使用
*/
};
struct file_lock_context *i_flctx; /* 文件锁定上下文
* 管理此inode上的POSIX锁、FLOCK锁等
*/
/* ============ 第十部分:地址空间与设备映射 ============ */
struct address_space i_data; /* 内联地址空间(如果i_mapping指向它)
* 管理此inode的页缓存、私有映射等
* 包含页树(radix tree)、写回标签等
*/
struct list_head i_devices; /* 设备链表(用于字符/块设备inode)
* 链接到cdev->list或block_device->bd_inodes
*/
union {
struct pipe_inode_info *i_pipe; /* 管道信息(如果是管道文件) */
struct block_device *i_bdev; /* 块设备指针(如果是块设备文件) */
struct cdev *i_cdev; /* 字符设备指针(如果是字符设备文件) */
char *i_link; /* 符号链接目标路径(如果是软链接) */
unsigned i_dir_seq; /* 目录序列号(防止目录遍历竞争) */
};
/* ============ 第十一部分:杂项与扩展特性 ============ */
__u32 i_generation; /* 世代号(用于NFS文件句柄)
* inode重用(删除后重新创建)时递增
* 防止旧的NFS文件句柄访问新文件
*/
#ifdef CONFIG_FSNOTIFY
__u32 i_fsnotify_mask; /* 文件系统通知掩码
* 此inode关注的文件系统事件掩码
* 用于inotify、fanotify等机制
*/
struct fsnotify_mark_connector __rcu *i_fsnotify_marks; /* 通知标记链表 */
#endif
#ifdef CONFIG_FS_ENCRYPTION
struct fscrypt_info *i_crypt_info; /* 文件加密信息
* 用于fscrypt(文件系统级加密)
* 包含加密密钥、策略等
*/
#endif
#ifdef CONFIG_FS_VERITY
struct fsverity_info *i_verity_info; /* 文件完整性验证信息
* 用于fs-verity(文件完整性保护)
* 包含Merkle树、哈希等
*/
#endif
void *i_private; /* 文件系统或设备私有指针
* 各文件系统可在此存储私有数据
* 例如:ext4_inode_info、btrfs_inode等
*/
} __randomize_layout; /* 随机化布局:防止内核地址空间布局随机化被绕过 */
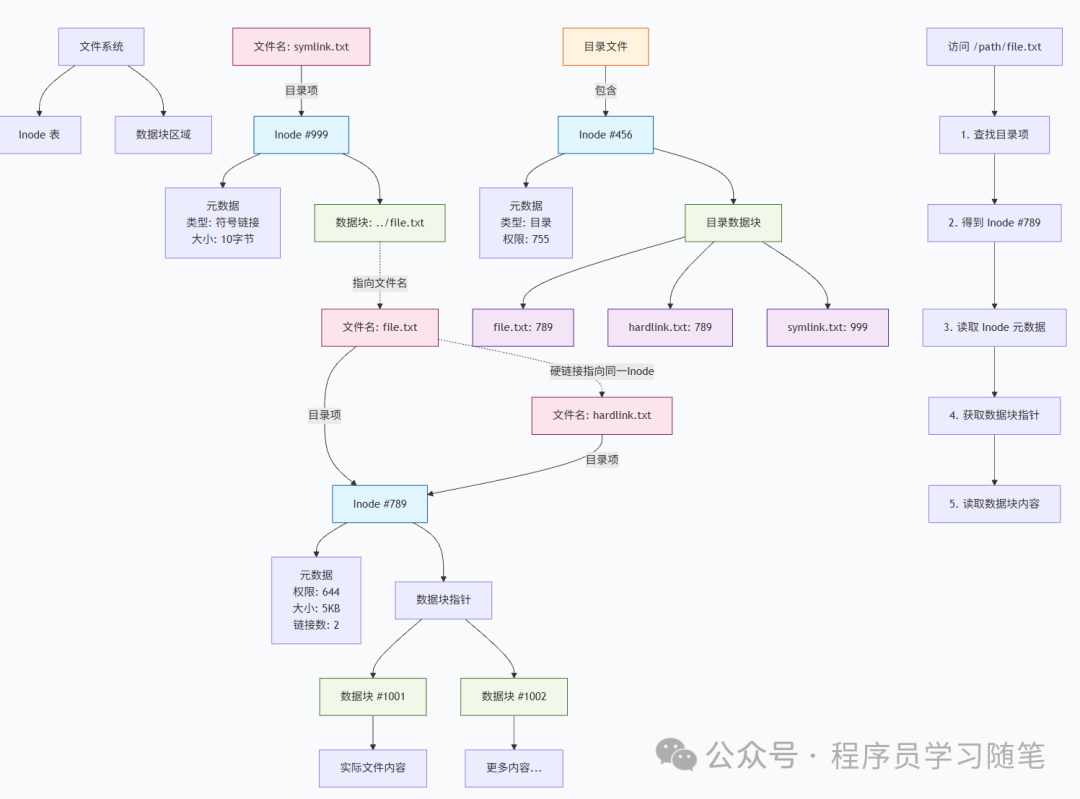
了解完 inode 的结构,我们需要澄清一个常见的误区。许多人误以为“文件名是文件的标识”,但在 Linux 底层,文件名只是 Inode 的“别名”,两者通过“目录项”(dentry)建立关联。
具体来说,目录本身也是一个文件,它的 Inode 会记录多个目录项,每个目录项包含“文件名”和对应的“Inode 编号”。当我们通过文件名访问文件时,系统会先查找目录的 Inode,通过目录项找到文件名对应的 Inode 编号,再通过 Inode 编号找到对应的 Inode,最后从 Inode 中获取文件数据的 Block 地址,从而读取文件内容。
这也解释了为什么 Linux 支持“硬链接”:硬链接本质上是为同一个 Inode 新增一个目录项(别名),所以多个硬链接对应的是同一个文件(同一个 Inode),修改其中一个,其他都会同步变化。而软链接(符号链接)则是一个独立的文件,它的 Inode 记录的是目标文件的路径字符串,而非目标文件的 Inode 编号,因此软链接更像一个“快捷方式”,其数据块里存储的是路径信息。
核心解析:Block
Block(数据块)是 Linux 系统中最小的数据存储单位。它的本质是磁盘上的一块连续扇区(例如,8 个 512 字节的扇区可以组成一个 4KB 的 Block)。系统在格式化磁盘时,会预先将磁盘划分为固定大小的 Block(常见大小为 4KB,也可设置为 1KB、2KB、8KB 等)。后续存储文件时,文件内容会被拆分并写入一个个 Block 中。
1)Block 的核心特性
- 大小固定:Block 大小由格式化时指定,一旦确定无法修改。例如,ext4 文件系统默认 Block 大小为 4KB,这意味着每个 Block 最多只能存储 4KB 的数据。
- 按块分配:无论文件大小是多少,系统都会以 Block 为单位为其分配存储空间。即使是一个 1KB 的小文件,也会占用一个完整的 Block,剩余的 3KB 空间会被浪费(这就是“内部碎片”)。
- 可连续/离散分配:小文件可能占用 1 个连续的 Block,大文件则会占用多个 Block。这些 Block 可以是物理上连续的,也可以是离散的(由 Inode 中的块指针或 Extent 结构来记录其顺序和位置)。
2)Block 大小的选择影响
Block 大小的设置并非随意,它直接影响磁盘利用率和文件读写效率,具体对比如下:
- 小 Block(如 1KB):优点是减少内部碎片,适合存储大量小文件(如日志文件、配置文件),磁盘利用率高;缺点是大文件会被拆分成更多 Block,读取时需要频繁寻址,I/O 效率较低。
- 大 Block(如 8KB):优点是大文件占用的 Block 数量少,寻址次数少,连续读写效率高;缺点是内部碎片严重,如果存储大量小文件会浪费大量磁盘空间。
因此,在不同场景下需要选择合适的 Block 大小。例如,日志服务器适合使用小 Block,而视频存储服务器则更适合大 Block。
我们可以使用 debugfs 工具来直接查看和操作 Block 层面的信息(需谨慎使用):
# 2. 查看块位图信息
debugfs: testb <block_number> # 测试块是否被使用
Block <block_number> marked in use
# 3. 直接读取块内容
debugfs: cat <block_device>:<block_number> | hexdump -C
# 4. 查看extent树结构
debugfs: extent <inode_number>
Depth: 0 Depth: 0 Depth: 0 Depth: 0
Extents:
0: [0..1023] -> [65536..66559] # 逻辑块0-1023映射到物理块65536-66559
接下来我们看看 Block I/O 请求在内核中的表示结构 struct bio。理解它有助于我们了解数据从文件系统层到底层驱动的旅程。以下是其关键字段解析:
/*
* 块层和下层(即驱动程序和堆叠驱动程序)的I/O主单元
*/
struct bio {
/* --- 链表和请求队列管理 --- */
struct bio *bi_next; /* 请求队列链表指针。将多个bio链接成一个链表,形成请求队列 */
/* --- 目标设备信息 --- */
struct gendisk *bi_disk; /* 指向该I/O操作的目标通用磁盘结构(gendisk)的指针 */
/* --- 操作类型和请求标志 --- */
unsigned int bi_opf; /*
* 复合字段:低比特位存储请求标志(如同步、屏障等),
* 高比特位存储操作类型(REQ_OP_READ/REQ_OP_WRITE等)。
* 应使用访问器函数(如bio_op、req_op_flags)来操作此字段。
*/
/* --- 状态和控制标志 --- */
unsigned short bi_flags; /*
* 状态标志(如BIO_SEG_VALID、BIO_CLONED等)
* 同时包含bvec内存池编号信息
*/
unsigned short bi_ioprio; /* I/O优先级(基于cgroup或进程优先级) */
unsigned short bi_write_hint; /* 写入提示,用于SSD等设备的优化(如寿命管理) */
/* --- I/O操作结果状态 --- */
blk_status_t bi_status; /* I/O操作完成状态(BLK_STS_OK, BLK_STS_IOERR等) */
u8 bi_partno; /* 目标分区号(在主磁盘内的分区索引) */
/* --- 剩余计数(用于切分的bio) --- */
atomic_t __bi_remaining; /*
* 原子计数器:当bio被分割时,记录剩余未完成的片段数。
* 当计数减到0时,触发完成回调。
*/
/* --- 迭代器:跟踪当前处理位置 --- */
struct bvec_iter bi_iter; /*
* bvec迭代器:记录当前在bio_vec列表中的处理进度,
* 包括当前bvec索引、偏移量和剩余字节数。
*/
/* --- 完成回调函数 --- */
bio_end_io_t *bi_end_io; /*
* I/O完成时的回调函数指针。
* 当bio的所有操作完成时被调用。
*/
/* --- 私有数据指针 --- */
void *bi_private; /*
* 供所有者(提交者)使用的私有数据指针。
* 通常用于存储完成时需要传递的上下文信息。
*/
/* --- 控制组(cgroup)相关 --- */
#ifdef CONFIG_BLK_CGROUP
/*
* 表示该bio与cgroup子系统(css)和请求队列(request_queue)的关联。
* 如果bio直接发送到设备(绕过请求队列),则不会有blkg。
* 在bio释放时,该引用会被放下。
*/
struct blkcg_gq *bi_blkg; /* 块控制组队列结构,用于I/O限流和统计 */
struct bio_issue bi_issue; /* 记录bio下发的时间、位置等信息,用于cgroup统计 */
#ifdef CONFIG_BLK_CGROUP_IOCOST
u64 bi_iocost_cost; /* I/O成本估算,用于基于成本的权重分配 */
#endif
#endif
/* --- 内联加密支持 --- */
#ifdef CONFIG_BLK_INLINE_ENCRYPTION
struct bio_crypt_ctx *bi_crypt_context; /* 加密上下文,用于硬件内联加密 */
#endif
/* --- 完整性校验相关(可选) --- */
union {
#if defined(CONFIG_BLK_DEV_INTEGRITY)
struct bio_integrity_payload *bi_integrity; /* 数据完整性元数据(如DIF/DIX) */
#endif
};
/* --- bio_vec列表管理 --- */
unsigned short bi_vcnt; /* bio_vec数量:当前bio包含的物理内存段数 */
/*
* 以下所有字段(从bi_max_vecs开始)在调用bio_reset()时会被保留
*/
unsigned short bi_max_vecs; /* 最大容量:该bio结构能容纳的bio_vec最大数量 */
/* --- 引用计数 --- */
atomic_t __bi_cnt; /* 引用计数(pin count):跟踪该bio的活跃引用数 */
/* --- 物理内存段数组 --- */
struct bio_vec *bi_io_vec; /* bio_vec数组指针:指向物理内存段描述符数组 */
/* --- 内存池信息 --- */
struct bio_set *bi_pool; /* 该bio所属的内存池,用于分配和释放管理 */
/* --- 内联bio_vec(优化小I/O) --- */
/*
* 我们可以在bio末尾内联存储少量bio_vec,避免为少量内存段进行双重分配。
* 该成员必须保持在bio结构体的最末尾。
*/
struct bio_vec bi_inline_vecs[]; /* 内联的bio_vec数组,用于小规模I/O的优化 */
};
总结
通过本文的解析,我们可以清晰地总结出 Linux 文件存储的核心逻辑:以 Inode 为索引,记录文件属性与 Block 位置;以 Block 为容器,存储文件实际内容;通过目录项关联文件名与 Inode,实现文件的快速访问与管理。
理解 Inode 与 Block 的本质,不仅能帮助你避开“Inode 耗尽”、“碎片化”等常见问题,更能让你从底层领悟 Linux 文件系统的设计精髓——“索引与数据分离”的架构。这种设计在保证文件管理高效性的同时,也兼顾了极大的灵活性,是理解更高级操作系统特性和进行内存管理优化的基础。如果你想深入探讨更多 Linux 内核或系统原理的细节,欢迎来云栈社区交流。
 发表于 2026-2-5 03:41:59
|
查看: 137|
回复: 0
发表于 2026-2-5 03:41:59
|
查看: 137|
回复: 0
