高并发是衡量分布式系统与互联网架构性能的关键指标,它指的是系统在单位时间内处理大量并发请求或任务的能力。
在消息系统如Kafka中,高并发能力直接体现为每秒消息吞吐量(TPS/QPS)与系统响应延迟。
Kafka的性能基准:多少算高并发?
衡量Kafka是否达到“高并发”标准,通常参考以下经验值:
- 单机吞吐 > 10万条/秒:在单Broker节点上实现稳定的十万级TPS写入,已可视为具备高并发处理能力。
- 集群吞吐 > 100万条/秒:通过横向扩展集群,整体吞吐量达到百万级,是典型的高并发Kafka应用场景。
- 千万级TPS及以上:满足超大规模数据管道、金融交易等场景需求,属于大厂级别的“超高并发”部署。
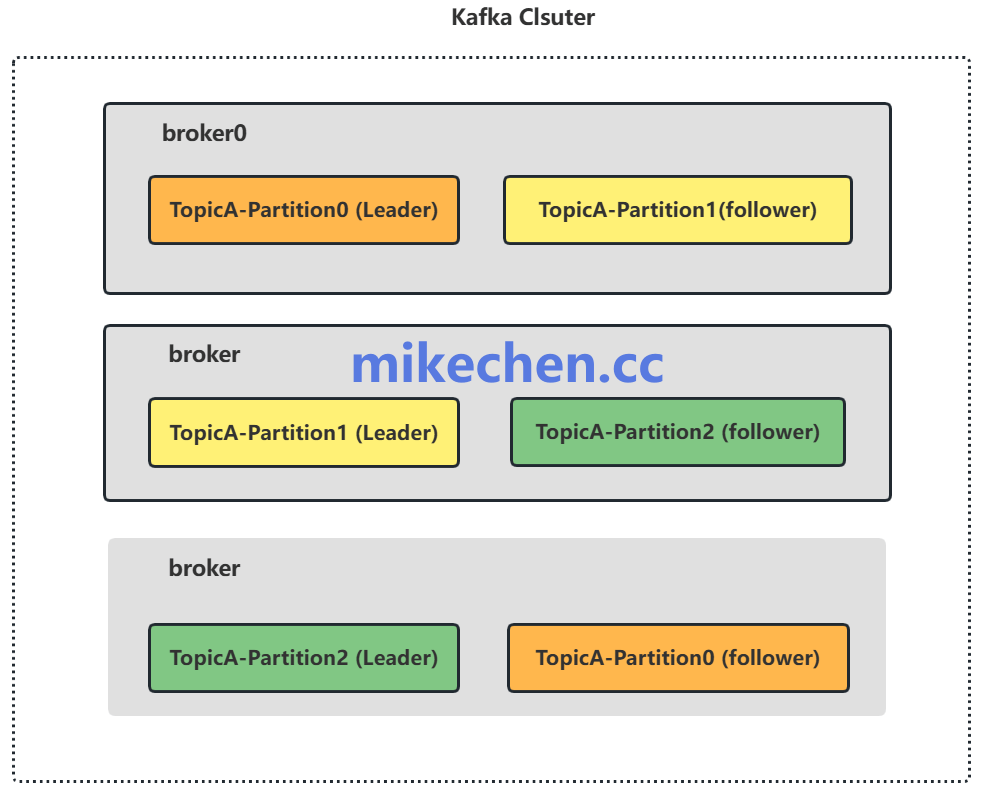
Broker层高并发配置与优化策略
Kafka的高吞吐能力根植于其精巧的架构设计,主要包括分区并行机制、日志顺序追加写入、高效的零拷贝网络传输以及对消息的批量处理。
1. 分区与副本机制优化
- 合理设置分区数:分区是Kafka实现并行消费与写入的基础。增加分区数可以线性提升Topic的吞吐上限,但分区过多会显著增加ZooKeeper的元数据压力与控制器(Controller)领导选举的开销。通常需根据目标吞吐量、消费者组数量以及未来扩展性综合评估。
- 配置副本因子:副本(Replication Factor)通常设置为2或3,以保证数据的可用性与持久性。在高并发场景下追求最低延迟时,可以调整
min.insync.replicas参数和生产者的acks确认机制(如设为1),但这需要在性能与数据可靠性之间做出权衡。
2. 生产者客户端调优
- 启用批量发送:通过合理配置
batch.size(批次大小)和linger.ms(等待时间),将多条小消息合并为一个批次发送,能极大减少网络请求次数,是提升吞吐量的关键。
- 使用消息压缩:启用压缩(如
compression.type=lz4或snappy)可以有效减少网络传输和磁盘写入的数据量,节省带宽与IO。需注意这会增加生产者和Broker端的CPU开销。
- 调整确认策略:
acks参数控制消息的持久化强度。acks=0(不等待确认)或acks=1(仅等待Leader写入)能获得最高的吞吐和最低的延迟,但存在数据丢失风险;acks=all(等待所有ISR副本写入)提供了最强的持久性保证,但会牺牲部分性能。
3. Broker存储与线程优化
- 利用顺序写入优势:Kafka的日志追加写(Append-only Log)对机械硬盘(HDD)友好,但固态硬盘(SSD)能提供更高的IOPS和更低的延迟,尤其适用于对延迟敏感的高并发场景。
- 调整IO与网络线程数:增加
num.io.threads(默认8)和num.network.threads(默认3)可以提升Broker处理磁盘IO和网络请求的并行能力,需根据服务器CPU核心数和网络负载进行调整。
- 优化日志段管理:合理设置
log.segment.bytes以避免产生过多小文件,减少文件句柄压力。同时,规划好log.retention(保留策略),定期清理过期数据。
4. 零拷贝(Zero-Copy)技术
Kafka利用操作系统的sendfile系统调用实现零拷贝传输,数据在内核空间直接从文件系统缓存发送到网络套接字,避免了内核缓冲区与用户缓冲区之间的多次复制,显著提升了网络传输效率。
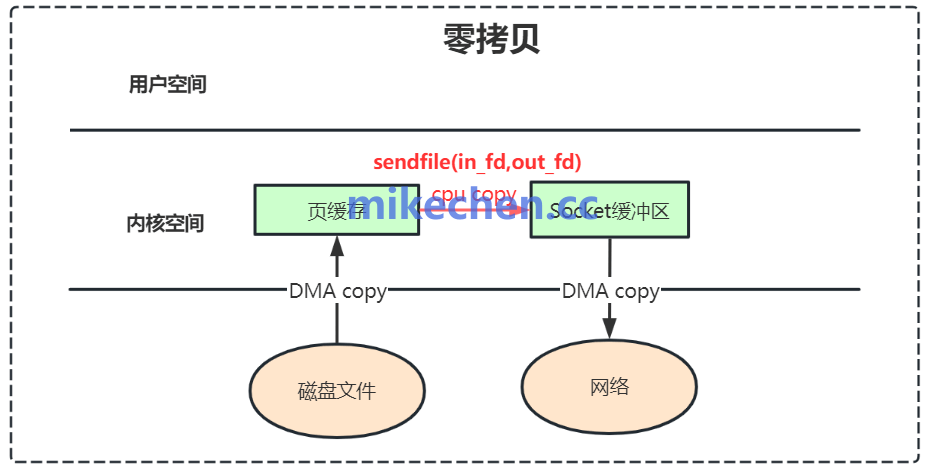
- 系统层面支持:确保Linux操作系统与JVM环境支持零拷贝优化。
- 网络缓冲区调优:根据平均消息大小和吞吐量目标,调整
socket.send.buffer.bytes和socket.receive.buffer.bytes等网络参数,确保缓冲区大小足够,避免成为性能瓶颈。
通过上述对Kafka架构特性与核心配置参数的深入理解和针对性调优,结合合理的分布式系统与集群规划,可以有效构建出支撑百万级乃至更高并发吞吐的消息系统,满足高并发业务场景的苛刻要求。 |  发表于 2025-12-4 01:28:34
|
查看: 160|
回复: 0
发表于 2025-12-4 01:28:34
|
查看: 160|
回复: 0
