最近在支持用户使用 WALMiner 实现 PostgreSQL 自动故障转移时,遇到了一个棘手的问题。故障转移完成后,工具无法从新的主库获取所需的 WAL 日志。原因在于,当备库被提升(promote)为新主后,如果立即面临高强度的业务写入,那么在 WALMiner 成功连接到新主之前,旧的 WAL 文件可能就已经被数据库的清理机制给删除了。
解决这个问题的常规思路是配置适当的 wal_keep_size 参数,确保 WAL 文件不会被立即移除,从而为故障转移后的日志读取提供一个缓冲窗口,避免出现 WAL 间隙(GAP)。
然而,当用户反馈说他已经配置了 wal_keep_size,但 WALMiner 在新主库上依然找不到日志时,我不禁陷入了深深的自我怀疑:难道 wal_keep_size 这个参数在备库上不生效吗?为了寻求答案,我决定去问问当下最热门的“智囊团”——各大 AI 模型。
大型 AI 模型观点PK
我向几个主流模型抛出了同一个核心问题:在备库上设置的 wal_keep_size,对于备库自身的 WAL 保留行为有效吗?
得到的回复几乎一面倒,结论非常明确:
1. DeepSeek
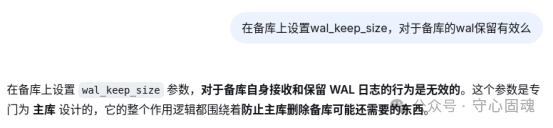
DeepSeek 指出,在备库上设置 wal_keep_size 参数,对于备库自身接收和保留 WAL 日志的行为是无效的。这个参数是专为主库设计的,其核心逻辑是防止主库过早删除下游备库可能还需要的数据。
2. GLM-4
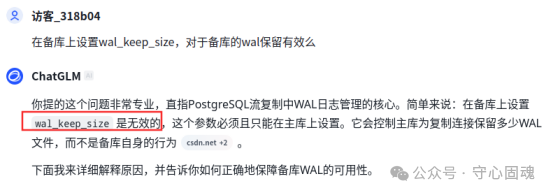
GLM-4 的回答更直接,它高亮强调:在备库上设置 wal_keep_size 是无效的。这个参数必须且只能在主库上设置,它控制的是主库为所有复制连接保留的 WAL 文件数量,而非备库自身的行为。
3. 针对源码的追问

我不死心,进一步要求 AI 直接分析 PostgreSQL 源码中的关键函数 CreateRestartPoint() -> KeepLogSeg(),探究备库的 WAL 回收逻辑是否会受其自身配置的 wal_keep_size 影响。

GLM-4 在严格分析源码(以 src/backend/access/transam/xlog.c 中的 KeepLogSeg 函数为例)后,给出了斩钉截铁的结论:备库的 WAL 回收逻辑完全不受参数 wal_keep_size 的影响。只要数据库运行在备库模式,这个配置项就会被 KeepLogSeg() 函数直接忽略。
4. 其他模型(元宝、豆包)

元宝的回复在承认主库主导性的同时,提到了一个特殊场景:当备库启用级联复制(cascading replication)时,它会充当“中间主库”的角色,此时其自身的 wal_keep_size 需要设置得足够大,以覆盖下游备库的同步延迟。

而豆包的总结则与众不同,它赫然写着:库的 WAL 回收逻辑直接受 wal_keep_size 参数影响,KeepLogSeg() 是实现该逻辑的核心函数。
实践出真知:动手测试
面对 AI 们(除豆包外)众口一词的“无效论”,和我阅读部分源码产生的“似乎有效”的模糊印象,最好的解决办法就是搭建环境,实际测试一下。真理往往存在于代码和实验之中。
测试步骤:
- 设置主库参数:将主库的
wal_keep_size 设置为 0(即默认行为,不主动保留)。
- 设置备库参数:将备库的
wal_keep_size 设置为一个很大的值,例如 10000(约 160GB,远超测试所需)。
- 生成 WAL:在主库上执行大量写入操作,产生足够的 WAL 文件,并手动触发
CHECKPOINT,促使旧 WAL 文件可以被回收。
- 触发备库回收:在备库上也执行
CHECKPOINT,触发其自身的 WAL 回收逻辑。
观察现象:
- 主库:
pg_wal 目录下旧的 WAL 文件被迅速清理,只保留当前正在写入的少数几个文件。
- 备库:
pg_wal 目录下积压了大量早已在主机上被删除的旧 WAL 文件,并未被清理。
测试结论:
测试结果清晰地表明,备库上配置的 wal_keep_size 参数确实影响了其自身的 WAL 文件回收行为。当备库设置了较大的 wal_keep_size 时,它会保留更多的历史 WAL 文件,即使主库那边早已删除。在这场“AI大战”中,豆包笑到了最后。
问题复盘与引申
回到最初让用户和笔者都困惑的那个 WALMiner 问题。经过后续深入排查,问题根源其实与 wal_keep_size 或新的 WAL 文件无关。核心症结在于,WALMiner 在处理因时间线(Timeline)切换而产生的 WAL 日志分叉(fork)场景时,逻辑存在缺陷。这个修复会在后续版本中完成。
后记
“尽信书则不如无书”,这句古训在 AI 时代被无限放大。AI 大模型无疑是强大的知识聚合与推理工具,但在涉及具体技术细节、尤其是需要结合源码和实际环境验证的场景时,它们仍可能给出看似合理但实则错误的结论。这次关于 wal_keep_size 的探索就是一个生动的例子。它提醒我们,在拥抱 AI 效率的同时,必须保持技术人的严谨和批判性思维。对于数据库配置、内核行为这类问题,最可靠的答案永远来自于官方文档、源代码和亲手构建的测试环境。
作为开发者,在 PostgreSQL 等高可用架构的实践中,理解每一个参数的真实行为至关重要。如果您在流复制、故障恢复或 数据库/中间件 的其它方面有更多的经验或疑问,欢迎到技术社区进行交流分享,比如在 云栈社区 的相关板块,常常能碰撞出更接地气的解决方案。

 发表于 2026-2-6 07:03:02
|
查看: 193|
回复: 0
发表于 2026-2-6 07:03:02
|
查看: 193|
回复: 0
