想象一下这样一个场景。
你在一家互联网公司上班,公司业务不大不小:有订单服务、有库存服务、有支付服务、有日志服务、有配置中心、有定时任务调度。
某天早上 9 点,系统刚上线。突然有人问你一句:“现在到底谁是主节点?”
你一愣。
订单服务说:“我觉得我是老大。”
库存服务说:“不对,昨天我刚被选为 Master。”
支付服务冷冷地说:“你们别吵,我刚刚启动得最晚,理论上我最新。”
这下麻烦大了,系统开始“内讧”了。
接着又来一个问题:“配置改了没有?大家用的是不是同一份?”
你一查:A 机器用的是旧配置,B 机器已经更新,C 机器还在读缓存。整个系统就像一个没有村委会的村子:大家都很努力,但没人统一协调,每个人都觉得自己是对的。
这时候,ZooKeeper 登场了。

ZooKeeper 是什么?
如果你在面试中被问到这个问题,标准答案是:ZooKeeper 是一个开源的分布式协调服务,用于为分布式应用提供一致性服务。
但这个定义听起来有点干巴巴的。如果用更形象的话来说:ZooKeeper 就是分布式系统里的“居委会 + 公证处 + 公告栏 + 裁判 + 记账本”。
- 谁是老大? 它来裁决 (Master选举)。
- 配置有没有改? 它来发布 (数据发布/订阅)。
- 谁先来谁后到? 它来记账 (顺序一致性)。
- 锁到底是谁的? 它来公证 (分布式锁)。
一句话总结:ZooKeeper 的目标,就是把“分布式系统里最容易写崩的那部分” —— 也就是协调与一致性问题 —— 统一收走,替你兜底。
ZooKeeper 能干什么?(面试官最爱追问)
首先得明确,ZooKeeper 不是一个“存海量数据的数据库”,它是一个 “协调型基础设施”。它的数据模型是类似文件系统的树形结构(ZNode),数据量小,但可靠性要求极高。
基于此,你可以用ZooKeeper来实现多种分布式协调场景:
- 数据发布 / 订阅 (配置中心)
- 命名服务 (服务发现)
- 负载均衡
- 分布式协调 / 通知
- 集群管理 (节点上下线感知)
- Master 选举
- 分布式锁
- 分布式队列
为了更好理解,我们可以把这些能力对应到现实世界的角色:
ZooKeeper 能力现实类比表
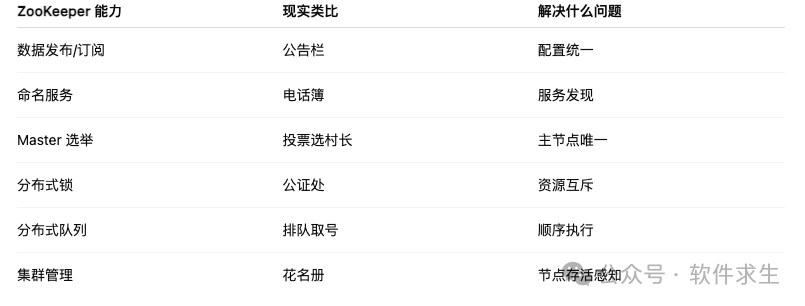
ZooKeeper 的设计目标:一句话很重要
官方对 ZooKeeper 的定位非常清楚:封装好复杂、易出错的分布式一致性问题,对外提供简单、稳定、高性能的接口。
这句话在面试中非常加分。它意味着,你作为应用开发者,不用再自己造轮子、踩坑、花半个月去调试各种一致性 Bug。ZooKeeper 提供了一个现成的、经过验证的解决方案。
ZooKeeper 最核心的:一致性保证
面试官真正想听的,其实不是“它能干什么”,而是:“它凭什么敢说自己能协调?” 这就引出了 ZooKeeper 对外承诺的 5 个核心一致性特性。
1、顺序一致性
ZooKeeper 保证,来自所有客户端的所有更新操作,都是全局有序的。不管请求从哪台机器发起,最终在 ZooKeeper 内部都会排成一条唯一顺序的队列。这就像银行取号,不管你从哪个窗口进来,最终都要按叫号顺序办事。
2、原子性
ZooKeeper 的更新操作要么完全成功,要么完全失败,不存在“成功一半”的中间状态。这确保了数据状态不会分裂,不会出现 A 机器看到了更新而 B 机器没看到的混乱情况。
3、单一视图
不管客户端连接的是 ZooKeeper 集群中的哪一台服务器(Follower),看到的数据视图都是一致的。就像你问村里任何一个村干部“村长是谁”,得到的答案都应该相同。
4、可靠性
一旦一个更新操作被 ZooKeeper 应用成功,只要集群中大多数节点还存活,这个更新就会被持久化,数据就不会丢失。这也是为什么 ZooKeeper 集群通常推荐部署为奇数个节点的原因,便于在故障时形成“大多数”。
5、实时性(最终一致性)
ZooKeeper 不保证所有客户端能在同一瞬间看到最新数据(强实时),但它保证:在有限时间内,所有客户端最终都将看到同一份最新的数据。这种“最终一致性”在绝大多数分布式协调场景中已经足够可靠。
ZooKeeper 的读写模型:为什么“读快,写慢”
这是一个高频面试点,理解它就能明白 ZooKeeper 的适用场景。
1、读请求
- 客户端可以连接任意一台 ZooKeeper 服务器(Follower 或 Leader)。
- 读请求直接在所连接服务器的内存中返回数据,速度极快。
- 如果注册了 Watcher(监听器),也由当前连接的这个服务器节点负责触发回调。
- 结论:读性能高,且可以通过增加 Follower 节点横向扩展。
2、写请求
- 所有写请求都必须转发到Leader节点进行处理。
- Leader 会发起一个类似两阶段提交的过程,将写请求(提案)同步给所有 Follower。
- 必须等到多数节点(Quorum)确认后,写操作才被视为成功,并向客户端返回响应。
- 结论:写吞吐量受限于集群达成共识的速度,节点越多,延迟可能越高,吞吐可能越低。
所以,一句话总结:ZooKeeper 是一个典型的为“读多写少”场景设计的协调系统。
ZooKeeper 的灵魂:zxid(事务 ID)
谈 ZooKeeper 的核心机制,不能不提 zxid。这就像是 ZooKeeper 全局有序性的“身份证”。
1、什么是 zxid?
zxid = ZooKeeper Transaction Id,即 ZooKeeper 事务ID。
- 每一次数据的变更(创建、更新、删除节点)都会产生一个全局唯一的 zxid。
- zxid 是一个 64 位的数字,单调递增。
- 它是保证全局顺序一致性的基石。你可以把 zxid 想象成整个 ZooKeeper 集群的全局逻辑时钟或“时间轴刻度”。
2、zxid 的结构
zxid 通常由两部分组成:高 32 位是epoch(纪元,Leader 任期编号),低 32 位是counter(该任期内的事务计数器)。这种结构也服务于 Leader 选举和数据同步过程。
3、zxid 的作用
在读请求中,返回的数据会附带当前数据节点的状态信息,其中就包括最新的 zxid。这意味着:你读到的数据状态,一定不早于这个 zxid 所对应的那个时间点。客户端可以利用 zxid 来进行条件更新等操作。
代码时间:用 ZooKeeper 实现一个分布式锁
理论说得再多,不如看代码实在。下面用 Java 和 Curator(Apache 官方推荐的 ZooKeeper 客户端,封装了高级特性)来演示如何实现一个分布式锁。

1、Maven 依赖
首先,需要在项目中引入 Curator 的依赖。

2、分布式锁示例代码
使用 Curator 提供的 InterProcessMutex(可重入互斥锁)可以非常简洁地实现分布式锁。

这段代码背后,Curator 和 ZooKeeper 做了什么?
- 创建临时有序节点:每个尝试获取锁的客户端,都会在 ZooKeeper 的指定路径(如
/lock/order)下创建一个临时有序节点。
- 判断最小序号:所有客户端查看该路径下的子节点列表,序号(zxid体现的顺序)最小的那个客户端成功获取锁。
- 监听前一个节点:未获锁的客户端监听自己序号的前一个节点的删除事件。
- 释放锁/故障处理:客户端业务完成后主动删除自己创建的节点以释放锁;如果客户端发生宕机,由于其创建的是临时节点,ZooKeeper 服务器会自动将该节点删除,从而自动释放锁。
这正是利用了 ZooKeeper 的临时节点和顺序一致性特性,完美避免了分布式场景下的死锁问题。
ZooKeeper 的本质一句话总结(面试必杀)
用一句话总结 ZooKeeper:ZooKeeper 不负责干具体的业务活(存储、计算),它只负责让分布式系统里的各个成员“别打架”,维持秩序。
它不是数据库,不是缓存,也不是消息队列。它是:分布式系统里那个不可或缺的秩序维护者与协调员。
很多同学一听 ZooKeeper 就觉得抽象复杂,其实抓住核心就好:
- 它解决的终极问题是分布式一致性。
- 它提供的核心价值是协调。
- 它实现的关键机制是全局顺序(zxid)。
下次面试官再问你“ZooKeeper 是什么?”,你除了说出标准定义,还可以自信地补充一句:“它是我们分布式系统里的‘定海神针’,负责选举、同步、上锁这些脏活累活,没它,整个系统就容易乱套。”
希望这篇从场景到原理,再到代码的解析,能帮助你更深入地理解 ZooKeeper。如果你想了解更多关于分布式中间件或其他后端技术的深度讨论,欢迎来 云栈社区 交流探讨。
 发表于 2026-2-7 03:14:11
|
查看: 226|
回复: 0
发表于 2026-2-7 03:14:11
|
查看: 226|
回复: 0
