在电商领域的后端面试中,如何设计一个能扛住瞬间洪峰流量、保证数据绝对准确的抢购或领券系统,无疑是衡量开发者技术深度的经典考题。这篇文章将带你深入剖析一套经过实战检验的亿级流量高并发领券架构方案,从最基础的原子性问题,一路探讨到内存优化、分片不均的陷阱,直至最终一致性闭环和容灾降级,为你系统性地拆解这个“面试噩梦”。
核心矛盾与架构设计
想象这样一个场景:活动放出1万张神券,预计瞬间有500万用户涌入。面对如此高的并发压力,任何直接让流量穿透到数据库的方案都无异于“自杀”。
- 悲观锁:在数据库层面串行处理,吞吐量可能跌至个位数,系统完全瘫痪。
- 乐观锁:在应用层进行版本控制或重试,CPU因大量请求的自旋而被打满,成功率却极低。
因此,我们必须形成一个共识:核心的交易逻辑(库存扣减、用户去重)必须在内存中完成,数据库只负责异步的最终数据归档和持久化。
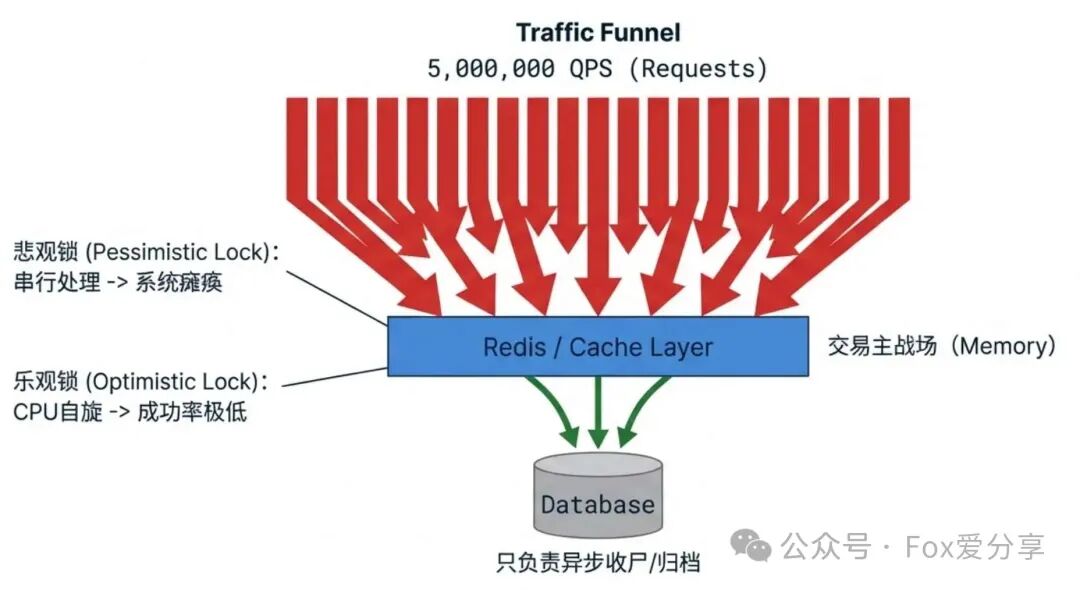
一个健壮的抗压架构通常设计为“三级火箭”,像漏斗一样层层过滤和削减流量。
第一级:网关层(无效流量清洗)
库存总量是确定的。我们可以在Redis中设置一个全局计数器。例如,当券已被领取1.5万次(含成功及风控过滤等)后,后续的498.5万请求根本无需进入核心逻辑。直接在网关层(如Nginx或API Gateway)快速返回“已抢光”的提示。这叫做“拦截下沉”,用最低的代价挡掉绝大部分无效请求。
第二级:应用层(Redis原子战场)
这是真正的核心战场。所有通过网关校验的请求,将在这里通过Redis的原子操作完成扣减和去重。我们后续的优化将集中于此。
第三级:数据层(MQ异步兜底)
用户成功“抢到”的体验,不应该依赖于数据库的实时写入速度。我们只需要在内存中操作成功,就立即给用户返回成功结果。同时,向消息队列发送一条异步消息,由下游服务“慢慢”处理数据库落库等后续逻辑,实现系统解耦。
基础防线:Redis + Lua脚本防止超发
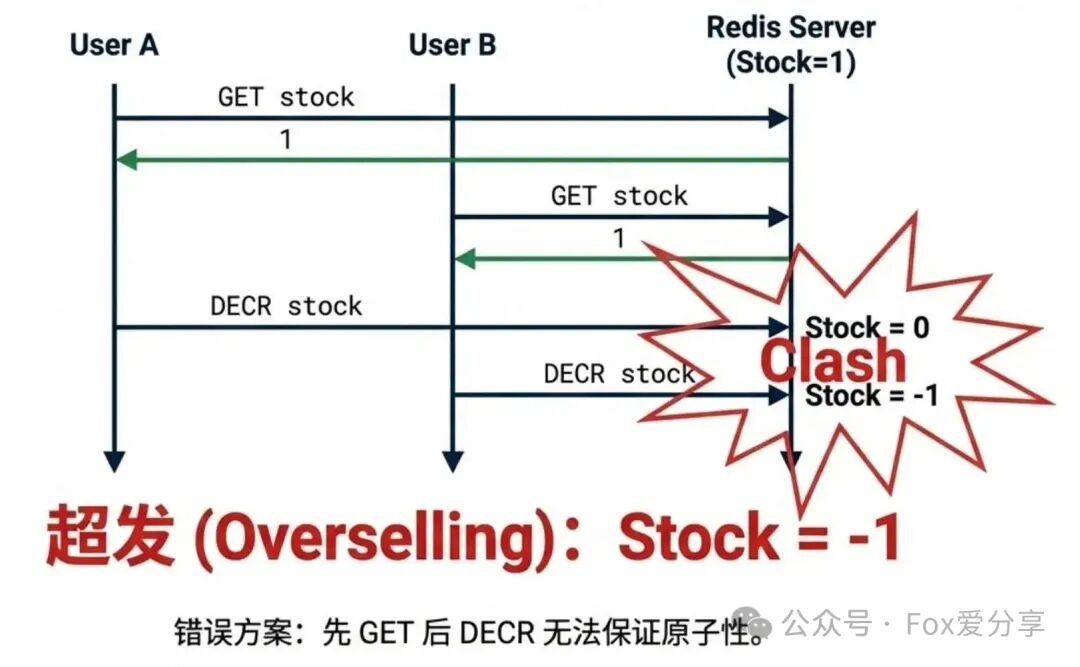
面试官常常会在这里设置陷阱:“你用Redis的decr扣库存,那怎么保证同一个用户不能重复领取?如果你先get判断用户是否存在,再执行decr,在超高并发下,这两个操作之间的间隙必然导致竞态条件(Race Condition),从而出现超发!”
P8级的解法是:使用Redis Lua脚本。
虽然单个Redis命令是原子的,但“检查库存 -> 检查用户 -> 扣减库存 -> 记录用户”这一串业务逻辑不是。Lua脚本可以被Redis单线程原子性地执行,相当于把整个业务逻辑打包成一个不可分割的原子命令,完美解决并发问题。
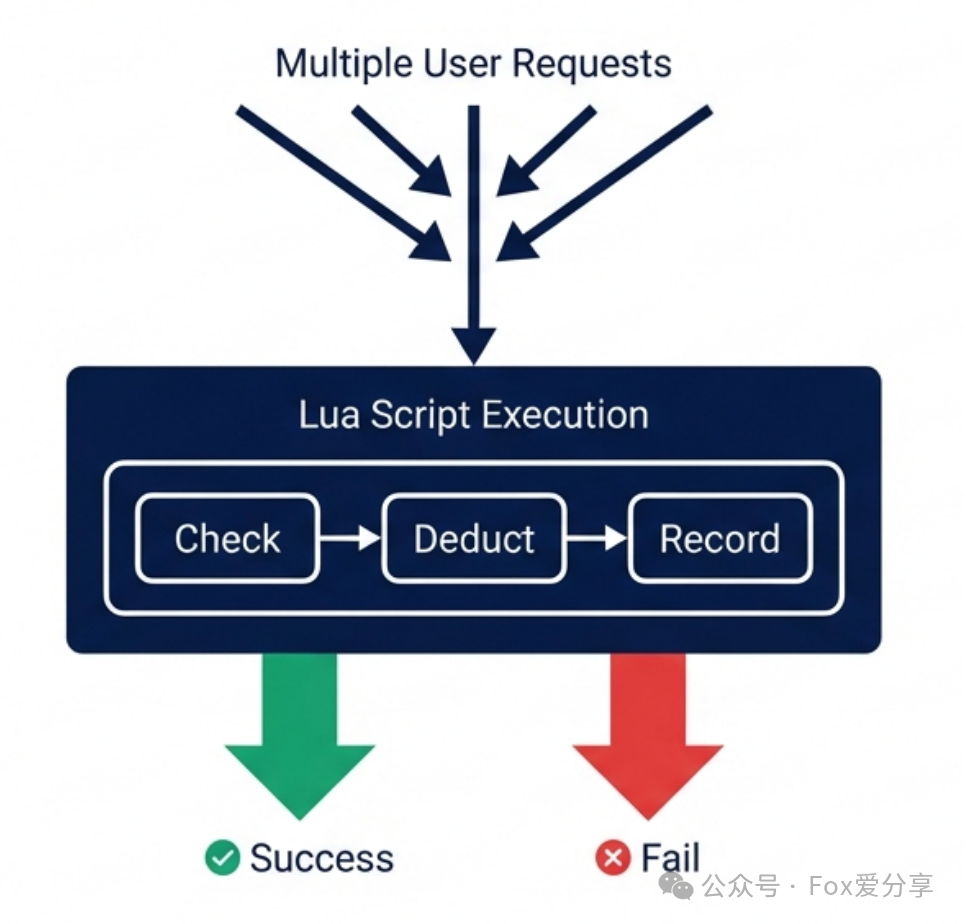
一个基础的Lua脚本逻辑如下:
-- KEYS[1]: 库存Key (e.g., stock_1001)
-- KEYS[2]: 用户已领记录 (e.g., users_1001)
-- ARGV[1]: 用户ID
-- 1. 校验用户是否已领取 (使用Set结构 - 这里有坑,下文优化)
if redis.call('SISMEMBER', KEYS[2], ARGV[1]) == 1 then
return -1 -- 重复领取
end
-- 2. 校验库存是否充足
local stock = tonumber(redis.call('GET', KEYS[1]))
if stock <= 0 then
return -2 -- 库存不足
end
-- 3. 核心动作:扣减库存 + 记录用户
redis.call('DECR', KEYS[1])
redis.call('SADD', KEYS[2], ARGV[1]) -- 写入Set
return 1 -- 抢券成功
写到这一步,你或许能解决P6级别的问题,但同时也为系统埋下了一个核弹级隐患:BigKey。
深度填坑:BitMap消灭BigKey
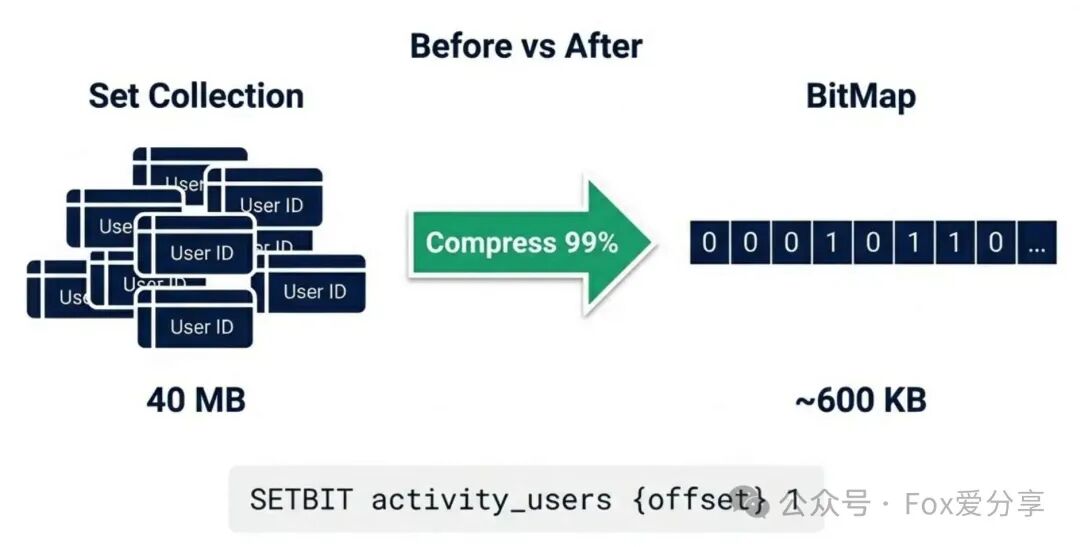
隐患分析:上面的脚本使用SADD将用户ID存入一个Set集合。假设有500万用户参与(无论成功与否),这个Set将包含500万个ID。
- 内存占用:按ID为Long类型(8字节)估算,500万 * 8字节 ≈ 40MB,加上Redis内部数据结构开销,轻松突破百兆。
- 后果:这是一个标准的BigKey。在集群数据迁移、生成RDB快照时,会长时间阻塞Redis主线程,可能引发全站服务雪崩。
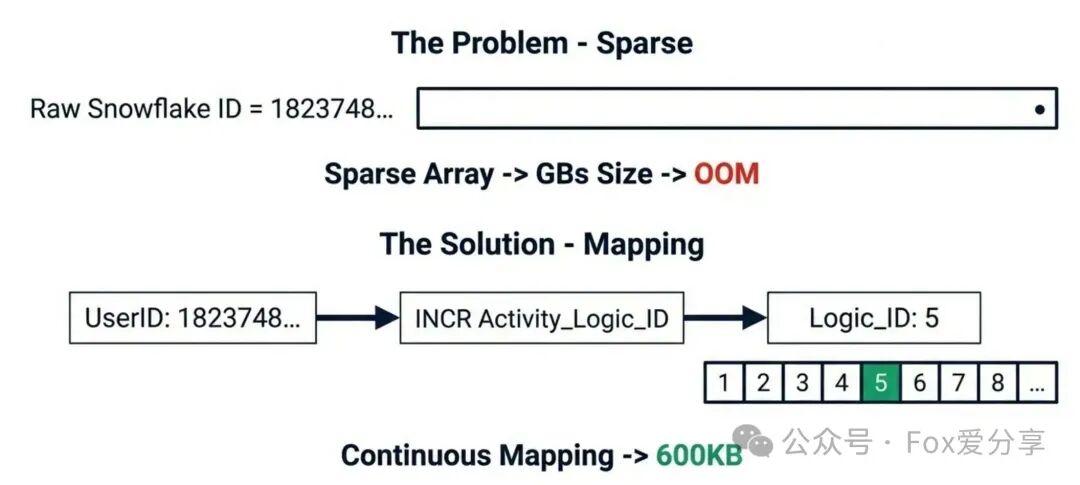
P8级的解法:BitMap + ID映射(ID Mapping)。
我们不存储完整的用户ID,而是用一个比特位(Bit)来表示用户是否已领取。500万用户只需要500万个bit,大约600KB,内存节省超过99%!
但这里有一个天坑:稀疏ID问题。
现代分布式ID(如雪花算法)生成的ID是长达19位的大整数(如1823748...)。如果你直接执行SETBIT key 1823748... 1,Redis会为这个BitMap分配一个足以容纳0到该最大偏移量的连续内存空间,可能导致数百MB甚至GB的内存被瞬间占用,直接触发OOM(内存溢出)!
终极方案:自增ID映射(ID Mapping)
我们需要将离散的、巨大的原始用户ID,映射为连续的、紧凑的小整数偏移量(Offset)。
- 分配逻辑ID:当用户首次请求该活动时,使用Redis的
INCR命令,为该用户分配一个从1开始自增的activity_logic_id。
- 存储映射关系:将
user_id -> logic_id的映射关系存入一个辅助的Redis Hash或本地缓存(仅活动期间有效)。
- 操作BitMap:后续所有去重检查,都使用这个紧凑的
logic_id作为偏移量来操作BitMap(SETBIT key logic_id 1)。
通过这种方式,500万用户的偏移量范围被严格控制在1~5,000,000,BitMap大小完美控制在600KB以内,极致紧凑。
抗压进阶:库存分片与“贫富不均”之痛
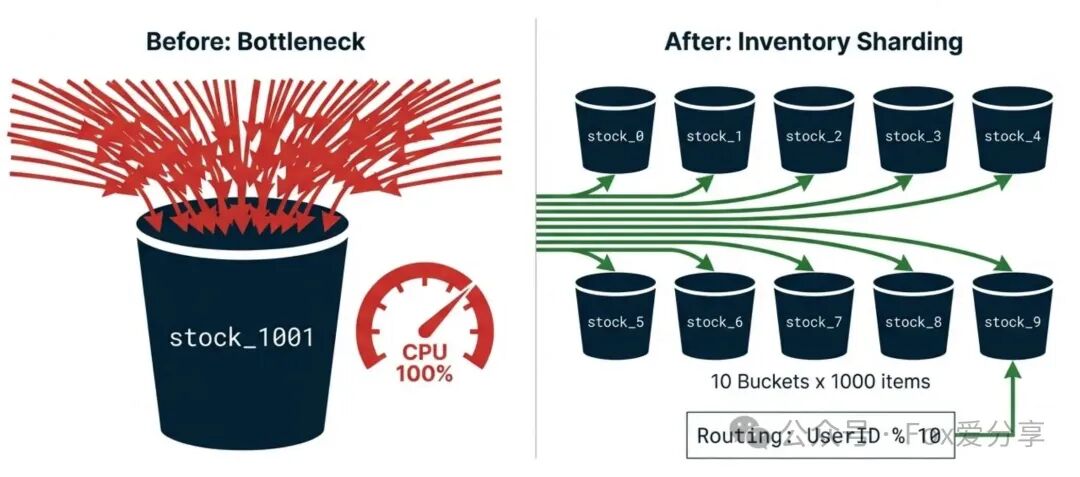
面试官的追问不会停止:“你的库存只有一个Key(如stock_1001),500万并发都来DECR这一个Key,这个Key所在Redis实例的CPU必然100%,形成热点Key,拖垮整个分片。你怎么解决?”
常规解法:库存分片(Sharding)
思路很简单:不要把鸡蛋放在一个篮子里。
- 拆分库存:将1万总库存拆分成10份,存储为10个Key:
stock_1001_0 到 stock_1001_9,每个Key存1000库存。
- 路由请求:用户请求到达时,根据
user_id % 10的结果,路由到对应的分片Key上进行扣减。
- 效果:单点压力被分散到10个Key(理想情况下是10个不同的Redis实例),系统吞吐量得到线性提升。
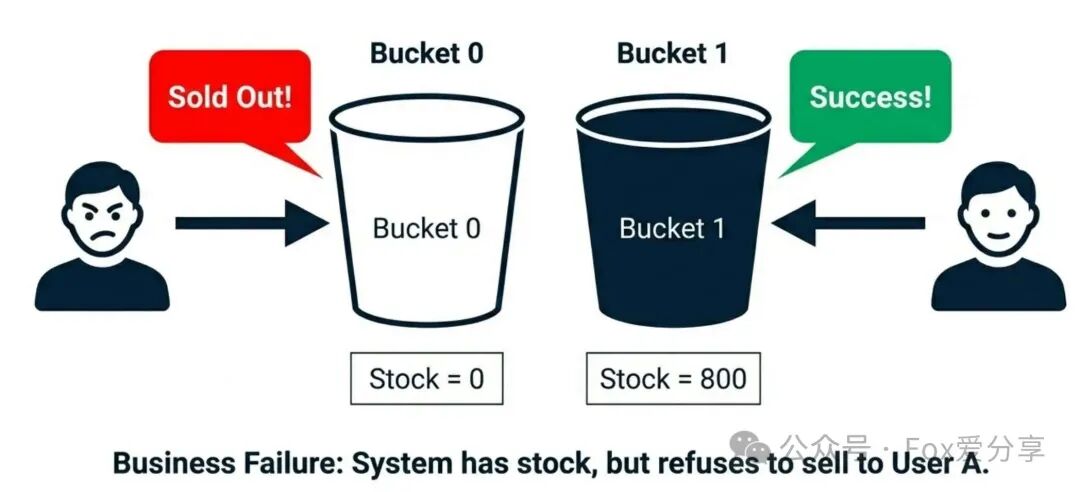
P8级深坑:局部缺货(Hotspot Skew)
面试官会冷笑:“如果按user_id % 10路由,假设分片0(stock_0)对应的用户群体特别活跃,瞬间抢光了1000库存;而分片1(stock_1)的用户比较佛系,还剩800库存。这时,一个新用户路由到分片0,会得到‘已抢光’的提示,但他明明看到朋友(路由到分片1)还能抢。这叫‘局部缺货’,是严重的业务逻辑缺陷和体验事故。”
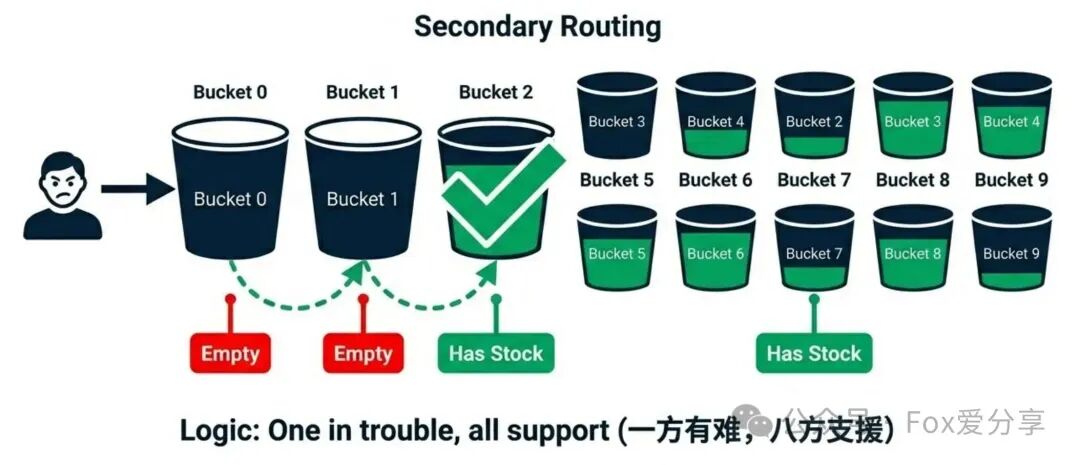
终极方案:Lua脚本内轮询 + 惰性回补
我们不能让用户被死板地绑定在某个分片上。目标应该是“一方有难,八方支援”。
升级版Lua脚本逻辑(带二次路由):
- 首选分片:根据
user_id % 分片数计算初始分片索引。
- 尝试扣减:去该分片扣减库存。
- 成功(库存>0):直接返回成功。
- 失败(库存<=0):不要立即返回失败!
- 极速轮询:在Lua脚本内部,利用Redis内存操作极快的特点,顺序遍历其他所有分片。
- 一旦发现某个分片库存>0,立即尝试扣减。
- 扣减成功则返回成功;若被并发抢走则继续寻找下一个。
- 遍历完毕仍无库存:才最终返回失败。
Lua脚本核心代码片段:
-- ARGV[1]: UserId, ARGV[2]: ShardCount (e.g., 10)
-- 1. 计算初始分片
local index = ARGV[1] % ARGV[2]
local stockKey = "stock_" .. index
-- 2. 尝试扣减首选分片
if redis.call("DECR", stockKey) >= 0 then
return 1 -- 成功
end
-- 失败回补 (DECR 减成了 -1,必须加回去,否则库存变成负数)
redis.call("INCR", stockKey)
-- 3. 兜底轮询 (核心优化:一方有难八方支援)
-- 遍历其他分片,找到一个有库存的
for i = 1, ARGV[2] - 1 do
local nextIndex = (index + i) % ARGV[2]
stockKey = "stock_" .. nextIndex
local stock = tonumber(redis.call("GET", stockKey))
if stock > 0 then
-- 发现有货!尝试扣减
if redis.call("DECR", stockKey) >= 0 then
return 1 -- 救活了!
else
redis.call("INCR", stockKey) -- 并发下也被抢光了,继续找下一个
end
end
end
return -1 -- 真的全抢光了
效果:只要系统总库存还有剩余,用户就有机会抢到,完美解决了分片不均带来的业务问题,同时保留了分片带来的高并发性能优势。
一致性死局:Redis成功,MQ挂了怎么办?
面试官的绝杀题来了:“你的Lua脚本执行成功了(库存扣减,BitMap置位),但在发送MQ消息通知数据库落库时,网络突然断了,或者应用进程崩溃。结果就是:Redis里库存少了,用户也看到‘成功’,但数据库里没有订单记录。数据不一致了,怎么解决?”
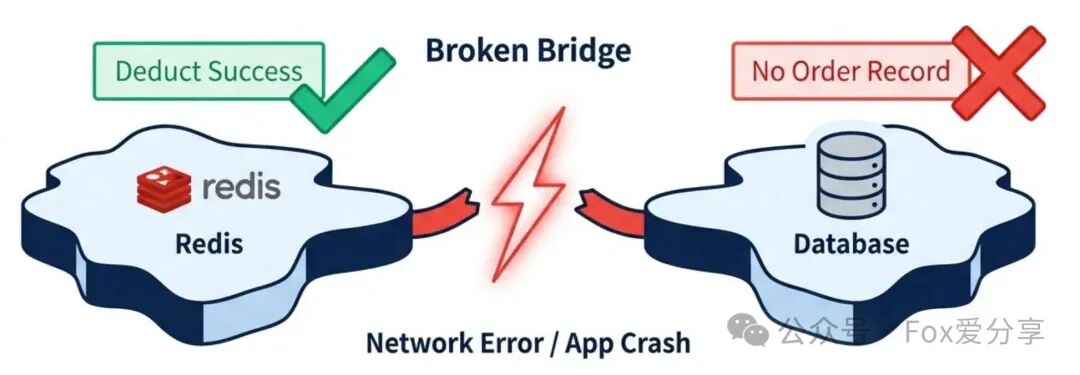
错误解法:
- “先发MQ,再执行Lua?” → 万一Lua执行失败(库存不足),MQ消息无法撤回,会导致数据库多记。
- “本地重试?” → 如果应用进程崩溃,内存中的重试任务会丢失。
P8级解法:RocketMQ事务消息(两阶段提交)
我们需要借助支持事务消息的消息中间件(如RocketMQ),将流程“倒置”,利用其半消息(Half Message)机制实现最终一致性。
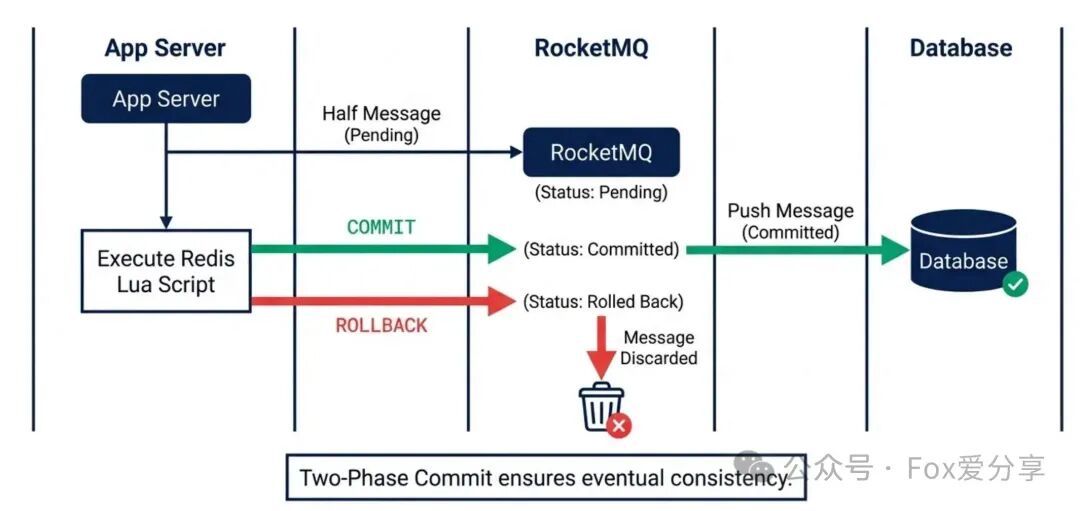
第一阶段:发送半消息(Prepare)
应用先向MQ发送一条状态为待确认的半消息,消息体中包含事务ID(如logic_id)。MQ服务端会持久化此消息,但不会立即投递给消费者。此时即向应用返回发送成功。
第二阶段:执行本地事务(Execute)
应用收到半消息发送成功的响应后,开始执行本地事务——即我们上文核心的“Redis Lua抢券脚本”。
第三阶段:提交或回滚(Commit/Rollback)
- 如果Lua脚本执行成功:应用向MQ发送
Commit指令,MQ才会将这条半消息的状态改为可投递,并推送给下游的数据库消费者进行落库。
- 如果Lua脚本执行失败(库存不足或异常):应用向MQ发送
Rollback指令,MQ将丢弃这条半消息。
这就结束了吗?远没有!这里隐藏着最棘手的“回查死局”。
回查死局:MQ来回查时,你该查谁?
极端场景:Lua脚本执行成功了,应用正准备发送Commit指令时,服务器突然断电宕机。MQ迟迟收不到Commit或Rollback,这条半消息将处于“悬而未决”的状态。此时,MQ会主动回调应用提供的checkLocalTransaction接口进行事务状态回查。
关键问题:回查时,应用如何判断当初这个logic_id对应的抢券操作到底成功了没有?去查数据库?肯定没数据(消息还没投递)。去查Redis?万一Redis也暂时不可用呢?
闭环解法:以“BitMap”为唯一信源(WAL)
我们之前为内存优化而设计的BitMap,此时扮演了更关键的角色——它成了整个操作的预写日志(Write-Ahead Logging, WAL)!
回查逻辑实现完美闭环:
- MQ来回查,携带半消息中的
logic_id。
- 应用直接查询Redis中的BitMap:
GETBIT activity_users logic_id。
- 逻辑判断:
- 结果为 1:证明当初Lua脚本一定成功执行了(置位和扣库存是原子的)。 → 向MQ返回
COMMIT。
- 结果为 0:证明当初Lua脚本没有执行或执行失败。 → 向MQ返回
ROLLBACK。
- Redis查询异常:返回
UNKNOWN,让MQ稍后再试。
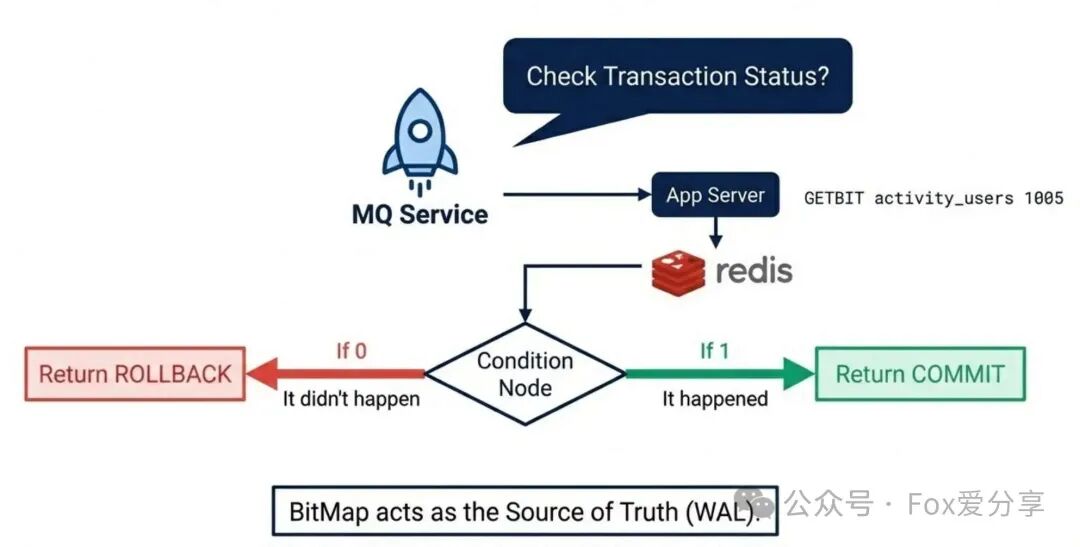
至此,我们构建了一个完美的最终一致性闭环:
- Redis挂了:有熔断降级策略(见下文)。
- MQ挂了:事务消息机制保障消息不丢。
- 应用挂了:重启后MQ来回查,BitMap提供最终决策依据。
最后的防线:Redis全挂,如何“降级求生”?
面试官的终极大考:“你的架构严重依赖Redis。如果Redis集群主从全部故障,或者机房网络隔离,完全不可用。此时500万流量洪峰到来,你的服务是会优雅失败,还是会把数据库直接打死?”
错误解法:
- “捕获异常,降级去查数据库?” → 这是自杀式行为,数据库会被瞬间击穿,引发全站雪崩。
- “直接抛异常,返回失败?” → 用户体验极差,活动完全失败。
P8级解法:本地缓存有损降级(保命优先)
当核心依赖(Redis)完全不可用时,我们必须牺牲一部分业务特性(如全局一致性、精确总量控制),优先保障核心服务的可用性和数据库的安全。
策略:本地内存预载少量库存
在活动开始前,从总库存中预先分配一小部分(例如1%,即100张),加载到每一台应用服务器的本地内存(如Guava Cache或Caffeine)中。使用AtomicInteger来管理这部分本地库存。
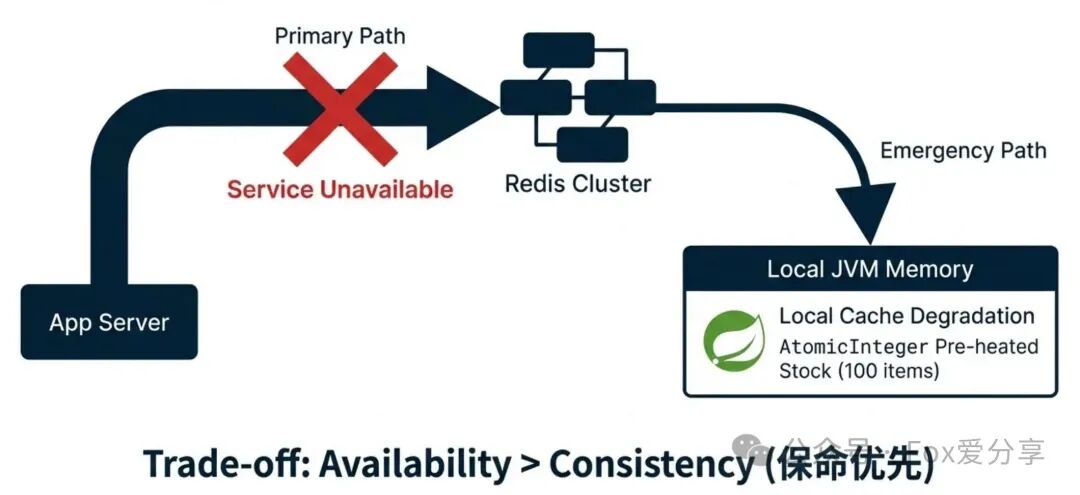
执行流程:
- 正常模式:所有请求走Redis Lua脚本流程。
- 故障感知:通过熔断器(如Sentinel/Hystrix)监测到Redis集群连续超时或不可用,触发熔断。
- 自动降级:流量不再访问Redis,转而请求本机JVM内的
AtomicInteger进行扣减(localStock.decrementAndGet())。
- 异步处理:本地扣减成功后,依然尝试发送MQ(若MQ也挂,则写入本地磁盘日志等待恢复)。
需要付出的代价(Trade-off):
- 无法精确控制总量:100台机器每台100张,可能实际放出超过1万张,或少于1万张。
- 无法全局防刷:本地缓存无法做跨JVM的用户去重。
- 但是:在极端灾难情况下,可用性远大于一致性。服务没有全面崩溃,大部分用户依然能获得“抢购”体验,数据库得到了绝对保护。这是符合业务收益的理性选择。
架构全景与面试复盘
一套完整的、能扛住亿级并发的高可用领券系统设计全景图如下,它融合了上述所有策略:
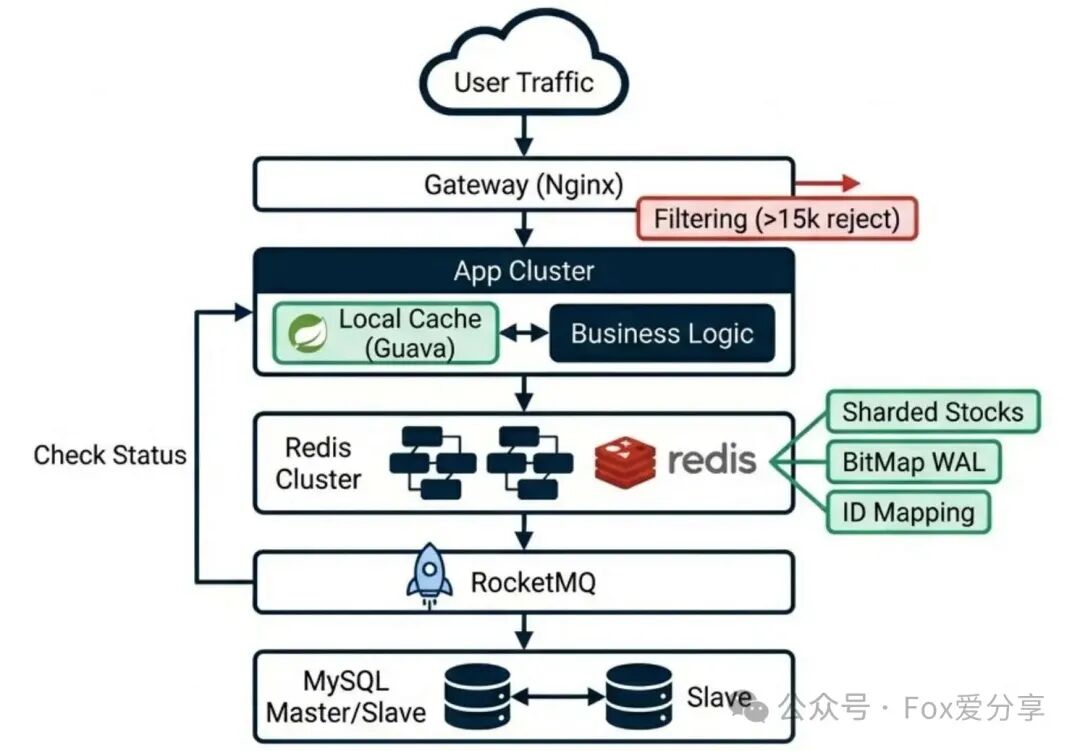
下次在面试中遇到类似“高并发秒杀/抢券”问题,你可以系统地阐述这个涵盖抗压、优化、一致、容灾四个维度的架构方案:
“面试官,这个问题表面是并发控制,本质是资源竞争与系统韧性的博弈。我的方案是一个分层治理的体系:
- 架构分层与流量漏斗:采用
网关拦截 -> Redis抗压 -> MQ异步三级架构,在入口处削减无效流量。
- 极致内存与存储优化:通过
ID映射 + BitMap,将海量用户记录从百MB级压缩至600KB,根治BigKey问题。
- 热点分散与业务兜底:采用
库存分片 + Lua内轮询,既解决单点热点,又通过二次路由规避‘局部缺货’的业务Bug。
- 分布式事务一致性闭环:引入
RocketMQ事务消息,并以BitMap作为WAL回查凭证,确保缓存与数据库的最终一致性。
- 容灾降级与系统韧性:设计
本地缓存降级方案,在Redis完全不可用时,牺牲部分一致性,优先保障服务不死和数据库安全。”
为什么这道题能区分P6到P8?
- P6:知道用Redis原子命令或基础Lua脚本。
- P7:能想到BitMap省内存、MQ解耦。
- P8:能深入解决
ID映射稀疏位图、Lua轮询平衡分片、事务消息闭环保障一致、本地降级应对灾难。
技术的价值在于解决现实世界中复杂、多变的约束问题。希望这套经过深度思考和提炼的架构方案,能帮助你在云栈社区与更多开发者交流时,或者在未来的技术挑战中,拥有更系统、更底层的解决思路。
 发表于 2026-2-7 10:59:26
|
查看: 187|
回复: 0
发表于 2026-2-7 10:59:26
|
查看: 187|
回复: 0
