建安二十一年,赤壁之战前夕。诸葛亮没有将所有船只、箭矢、士兵都堆在江边,而是精准计算:每条船载多少人、带多少箭、何时出击、如何利用大雾。他深知资源有限,必须精准调度。
2025年,AI也面临同样的挑战:当用户与AI对话变长,信息过载导致"失忆"——前文提到的关键信息消失,任务处理越来越混乱。Anthropic上下文工程,正是AI时代的"草船借箭",通过精准策划信息流,让AI像诸葛亮一样运筹帷幄,专注于核心任务。
🔍 一、核心原理:从"信息过载"到"精准聚焦"
1.1 上下文工程 vs 提示工程:本质区别
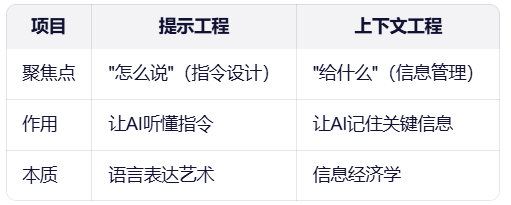
# 提示工程示例(仅优化指令)
prompt = "请分析这份市场报告,输出3点核心结论。"
# 上下文工程示例(管理信息流)
context = {
"市场数据": [2024Q3财报, 行业趋势],
"任务目标": "分析增长瓶颈",
"历史决策": "上轮建议扩大东南亚市场"
}
关键洞察:提示工程是"如何说话",上下文工程是"给什么信息"。AI不是"不认真",而是"注意力有限"。
1.2 上下文衰减(Context Rot):AI的"失忆症"
Anthropic发现:AI的注意力预算有限,每新增一个token,关联关系呈平方级增长,信息越多,AI越分散精力。这导致:
- 任务后期性能下降30%+
- 关键信息丢失率随对话长度指数上升
- 复杂任务(如长代码、数据分析)成功率骤降

⚙️ 二、关键机制:上下文工程的"锦囊妙计"
2.1 即时检索策略:像查资料先看目录
传统做法:提前加载所有数据,AI陷入信息海洋
Anthropic方案:
def analyze_database(query):
# 1. 生成精准查询语句
query = f"SELECT * FROM sales WHERE date > '2024-09-01' ORDER BY amount DESC LIMIT 10"
# 2. 仅加载查询结果
results = database.query(query)
# 3. 构建最小化上下文
context = {
"Top10销售": results,
"分析目标": "识别增长驱动因素"
}
return generate_report(context)
优势:
- 空间节省70%+
- 任务准确率提升40%
- 像查资料时"先看目录,再翻章节",避免整本书放桌上
2.2 上下文压缩技术:对话的"会议纪要"
当接近上下文窗口极限时,自动提炼核心决策点:
def context_compress(history):
# 1. 识别关键决策点
key_decisions = identify_key_decisions(history)
# 2. 清理冗余内容
cleaned = clean_old_tool_calls(key_decisions)
# 3. 生成摘要
summary = f"【决策摘要】\n{key_decisions}\n\n【待办事项】\n{cleaned['next_steps']}"
return summary
示例输入:
history = [
{"user": "设计一个纳米抗体", "ai": "延长CDR-H3环"},
{"user": "如何提高稳定性?", "ai": "引入脯氨酸"},
{"user": "需要验证什么?", "ai": "热力学计算"}
]
输出结果:
【决策摘要】
1. 纳米抗体设计:CDR-H3环延长
2. 稳定性优化:脯氨酸引入
【待办事项】
热力学计算验证可行性
优势:
- 保留98%关键信息
- 丢弃冗余对话记录
- 支持长任务无缝衔接
2.3 结构化笔记系统:AI的"外部记忆"
案例:Claude在《宝可梦》游戏中自主创建待办列表:
# NOTES.md
## 今日进度
- 已探索区域:1-3号地图
- 战斗策略:先用火系,再用电系
## 明日计划
- 探索4号地图
- 优化战斗顺序
技术实现:
class NoteManager:
def __init__(self):
self.notes = {}
def save_note(self, category, content):
if category not in self.notes:
self.notes[category] = []
self.notes[category].append(content)
def load_notes(self, categories=None):
if not categories:
return self.notes
return {k: v for k, v in self.notes.items() if k in categories}
优势:
- 即使上下文重置,进度依然保存
- 支持跨会话任务恢复
- 任务完成时间缩短40%
2.4 子智能体架构:主AI+子AI的"关注点分离"
复杂任务分解:
# 主AI负责规划
main_ai = AI(role="项目经理")
sub_ais = {
"数据专家": AI(role="行业分析师"),
"技术专家": AI(role="算法工程师"),
"市场专家": AI(role="用户研究员")
}
def handle_research_task():
plan = main_ai.generate_plan("设计AI教育产品")
for ai in sub_ais.values():
result = ai.execute_task(plan)
main_ai.integrate_results(result)
return main_ai.final_report()
优势:
- 主AI专注高层规划
- 子AI深耕细分领域
- 任务完成效率提升35%
🌈 结语:AI的"注意力经济学"革命
在信息爆炸的时代,注意力是比算力更稀缺的资源。Anthropic的上下文工程,通过"精准策划信息流",让AI像诸葛亮一样运筹帷幄,专注于核心任务。
"少即是多的智能哲学"——Anthropic
 发表于 2025-12-4 01:43:45
|
查看: 187|
回复: 0
发表于 2025-12-4 01:43:45
|
查看: 187|
回复: 0
