随着 OpenClaw 智能体框架的流行,许多开发者在实际部署时遇到的第一个难题就是:究竟该为它选择哪个大模型?这直接关系到运行成本、响应速度和应用效果。
为此,OpenClaw 的创始团队亲自推荐了一个有趣的工具:PinchBench。这是一个专为评估大模型在真实 OpenClaw 工作流中表现而设计的基准测试榜单,从成功率、速度和成本三个核心维度进行实时排名。
国产模型表现亮眼:成功率与速度领先
对于 OpenClaw 这类需要消耗大量 Token 并追求快速响应的智能体应用,模型选择需要在价格、速度和效果之间艰难权衡。PinchBench 的价值就在于直接给出了多维度的对比数据。
截至发稿,从榜单的整体情况来看,中国模型在成功率和速度方面表现突出,但在成本控制上与传统巨头相比仍有提升空间。
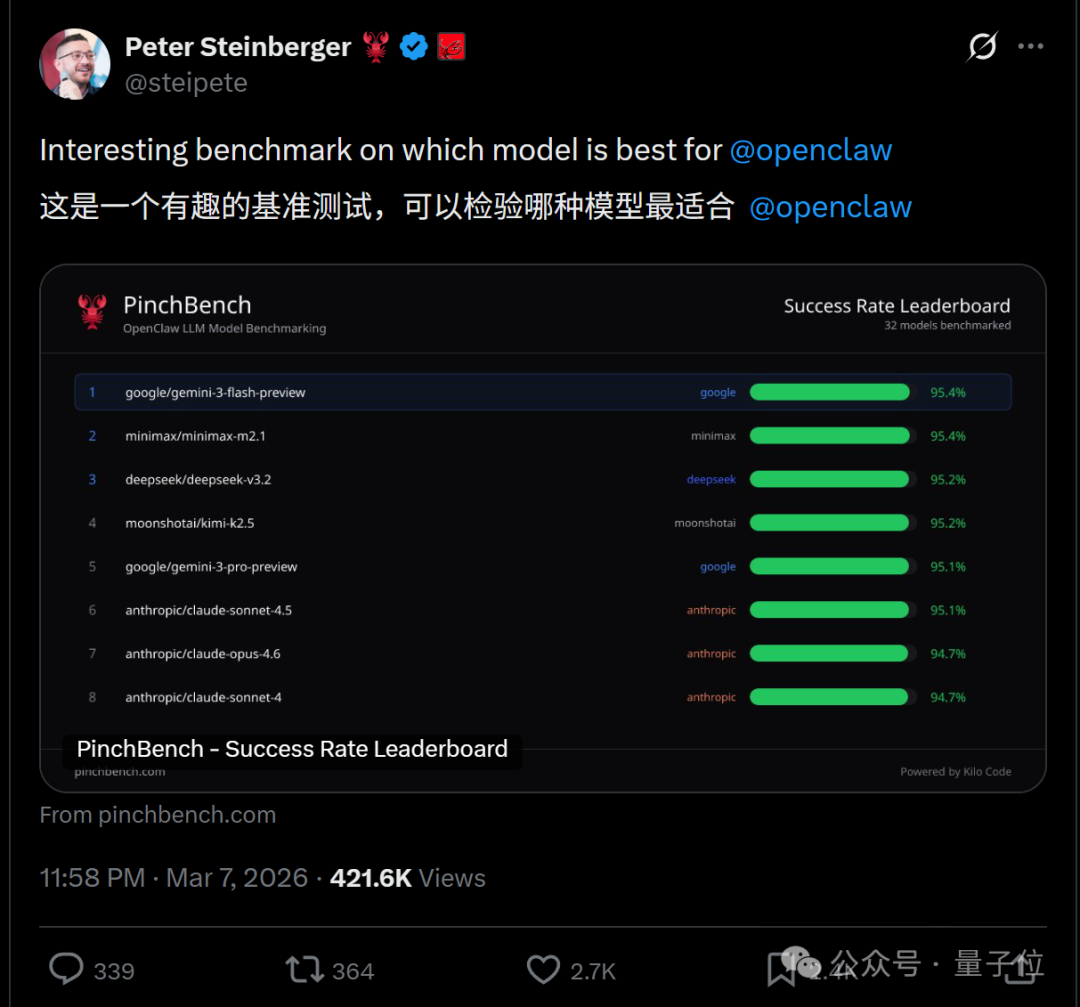
成功率方面,排行榜前列的国产模型含量很高。除了榜首的谷歌 Gemini 3 Flash Preview(95.4%),紧随其后的第二名和第三名均来自国内厂商:
- 第一名:google/gemini-3-flash-preview — 95.4%
- 第二名:minimax/minimax-m2.1 — 95.4%
- 第三名:deepseek/deepseek-v3.2 — 95.2%
值得注意的是,取得优异成绩的 MiniMax M2.1 并非其最新型号。该公司在春节期间发布了主打“让无限运行复杂 Agent 在经济上可行”的 M2.5 模型。
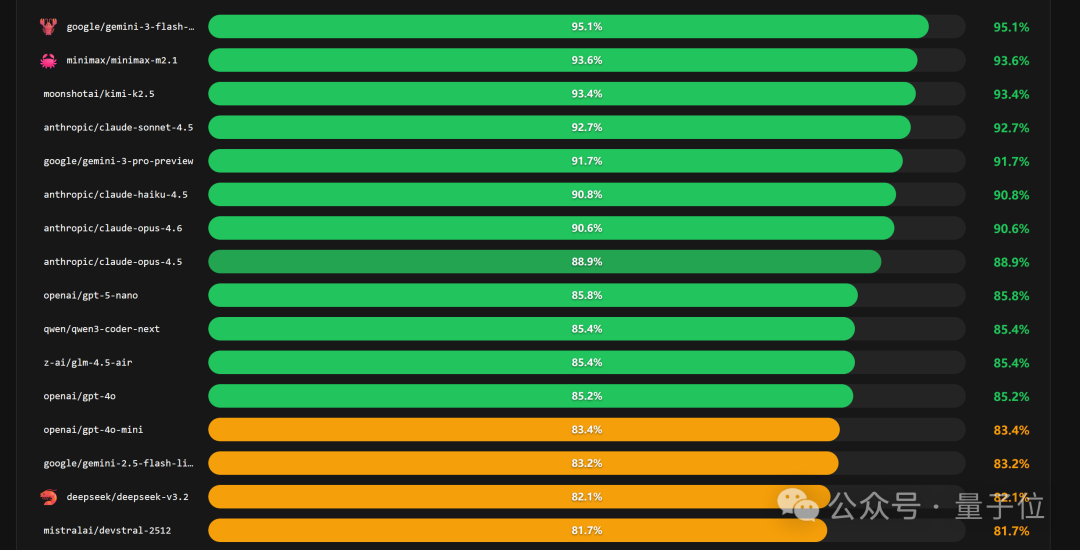
速度方面,国产模型 MiniMax M2.5 的表现更为抢眼,超越了 Gemini、Llama 等知名模型,登顶速度排行榜榜首。
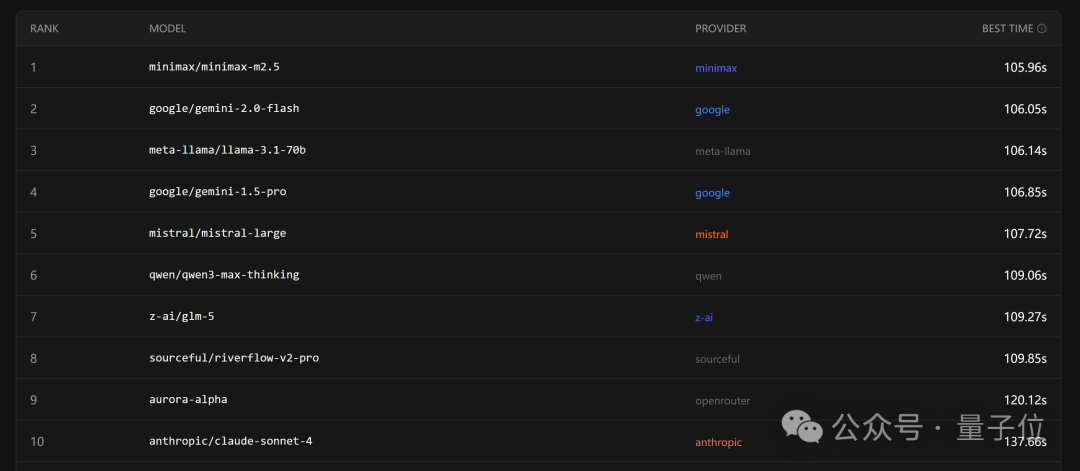
根据发布时的数据,MiniMax M2.5 在 SWE-Bench Verified 测试中,端到端任务完成时间较上一代 M2.1 提升了37%,缩短至22.8分钟,与 Claude Opus 4.6 持平。而在 PinchBench 的最新速度排名中,Claude Opus 4.6 位列第30名。
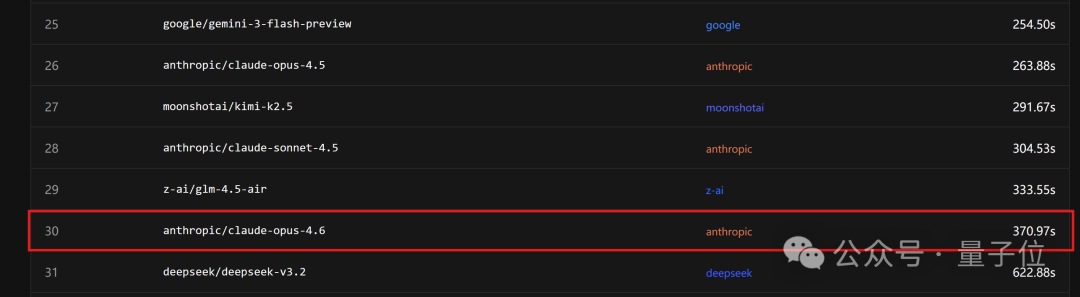
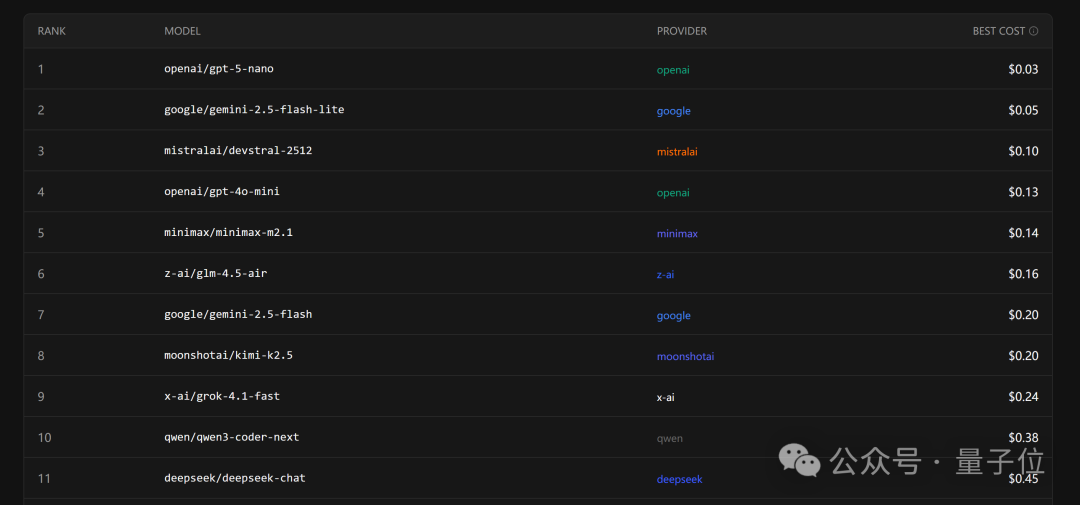
成本方面,国产模型目前与 OpenAI、谷歌的模型相比优势不明显。排名成本榜首的是专为轻量级场景设计的 GPT-5-nano,其输入价格极低。相比之下,国产模型中成本较低的 MiniMax M2.1,平均价格约为前者的3倍。
如果综合考虑成功率和成本,寻求最佳性价比,下面这张“成功率-成本”散点图提供了直观参考。图中左上角“最具吸引力象限”内圈出的8个模型中,有4个是中国模型。
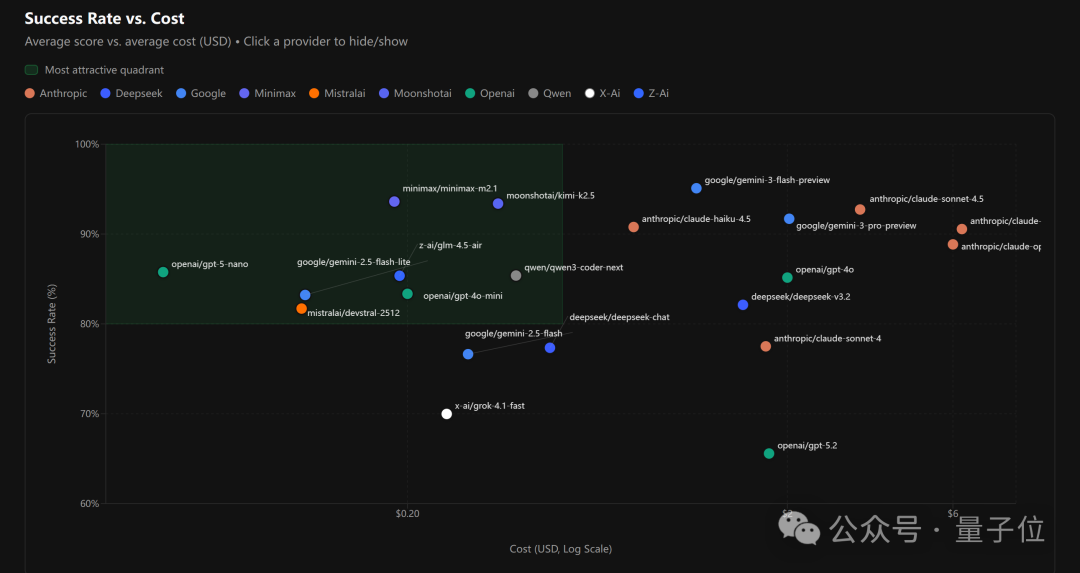
无论如何,在这份为 OpenClaw 量身定制的基准测试中,国产模型展现了强大的竞争力,并在特定维度上名列前茅。
PinchBench 是什么?为何它能提供参考?
你可能会问,这个榜单真的靠谱吗?它的评测机制是什么?
简单来说,PinchBench 并非来自某家科技巨头的官方评测,而是由一家专注于 Agent 基础设施的创业公司 Kilo AI 推出的工具。该公司由 GitLab 前联合创始人兼 CEO Sid Sijbrandij 投资并参与创立。
今年年初,随着 OpenClaw 的走红,Kilo AI 推出了基于 OpenClaw 构建的全托管智能体平台 KiloClaw。PinchBench 便是随之一同发布的、用于评测智能体框架下不同大模型表现的工具。
与传统的、侧重于知识问答或数学推理的大模型评测不同,PinchBench 的定位更接近 “智能体能力测试”。它不仅仅考察模型“会不会回答问题”,更关键的是评估模型“能不能完成一整套真实任务”。
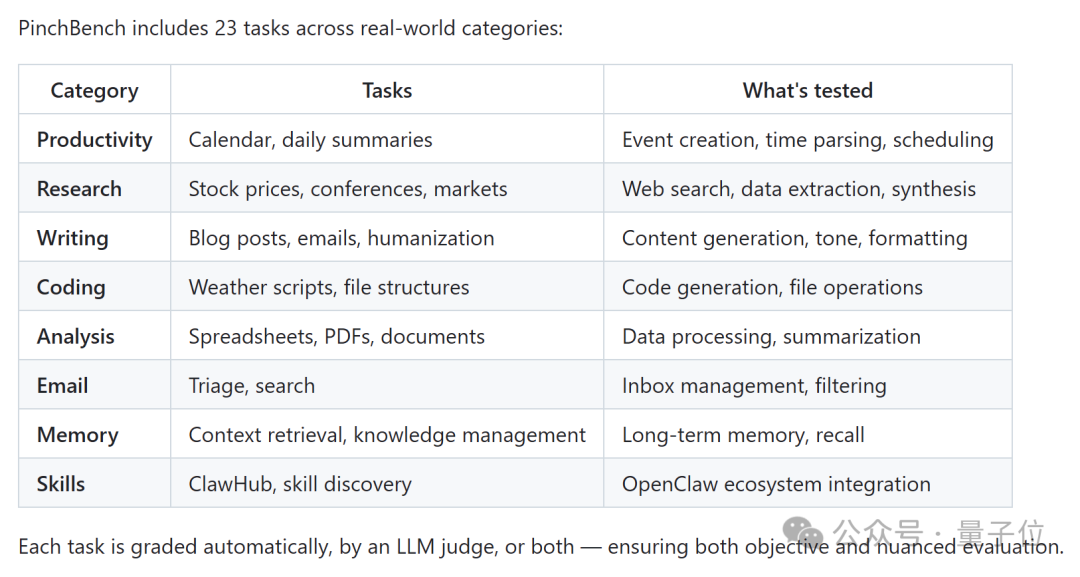
目前,PinchBench 包含了约23个真实世界任务的测试,涵盖多个类别:
- 效率工具:日程管理、每日摘要(测试事件创建、时间解析)
- 研究分析:查询股价、整理会议信息(测试网络搜索、数据提取与综合)
- 内容创作:撰写博客、邮件拟写(测试内容生成、语气把控)
- 编程相关:生成天气脚本、组织文件结构(测试代码生成、文件操作)
- 技能集成:ClawHub 使用、技能发现(测试 OpenClaw 生态集成)
在评分机制上,PinchBench 采用了 “自动化检查 + LLM 评审” 的组合方式:
- 部分任务有明确的自动化检查脚本(例如,是否生成了指定格式的文件,是否成功调用了某个 API)。
- 另一部分任务则由另一个 LLM 作为“裁判”来评判输出结果的质量。
最终,系统会统计每个模型在大量任务运行后的平均成功率(Success Rate)、平均速度(Speed)和平均成本(Cost),并生成排行榜。
正是由于这种贴近真实工作流的评测方式,PinchBench 揭示了一个有趣且对开发者极具启发性的现象:“更大的模型并非总是赢家”。换句话说,那些针对 Agent 场景进行过优化、或推理效率更高的模型,其综合排名可能优于某些参数规模更大、但在传统评测中领先的通用模型。
这一发现最近也在技术社区引发了广泛讨论,因为它直接关乎生产环境中 Agent 应用的经济可行性和效率。

目前,PinchBench 是一个完全开源的项目。这意味着开发者不仅可以查看现有的排行榜,还可以在本地或平台上自行运行基准测试,甚至根据自己特定的工作流添加新的测试任务。这对于深入 开源实战 和定制化评估非常有帮助。
当你下次再为 OpenClaw 或其他智能体项目挑选“发动机”(大模型)而犯难时,不妨亲自上手试试 PinchBench,让数据帮你做出更明智的决策。
相关链接:
 发表于 2026-3-10 13:29:11
|
查看: 256|
回复: 0
发表于 2026-3-10 13:29:11
|
查看: 256|
回复: 0
