
本文记录了一次针对4GB大文件(约1.14亿行ASCII文本)进行“删除每行中间1/3内容”的端到端性能优化全过程。核心目标是在内存受限前提下,通过Java、C++、Rust三种语言实现高吞吐、低延迟、高正确性的双进程流式处理。
我们围绕减少系统调用、消除冗余对象分配、匹配底层I/O特性、绕过不必要的抽象开销这四大主线,系统性地展示了从初始637秒(Java)到最终3.2秒(新架构)的百倍级优化过程,并提炼出可复用的通用原则及进阶解耦架构。
背景与挑战
任务很简单:处理一个4GB的ASCII文本文件(约1.14亿行),移除每行中间的1/3内容,输出到新文件(约2.7GB)。但难点也很明显:
- 内存限制:无法一次性加载整个文件。
- 性能瓶颈:涉及读4GB、写2.7GB,共约1.14亿行,磁盘I/O是主要瓶颈。
- 正确性:必须保证换行准确。
- 架构要求:必须通过两个进程(读写进程)协作实现。
解决方案概览
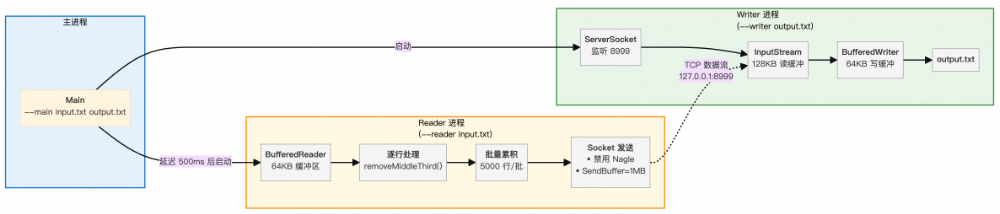
我们采用两个进程协作的方案:
- Reader进程:读取输入文件,处理每行,发送数据。
- Writer进程:接收数据,写入输出文件。
下面将详细记录Java、C++、Rust三种语言的完整实现与优化过程,包括每个版本的具体改动、性能提升和背后的原理。
通用优化策略
1. 批量处理 vs 逐行处理
问题:逐行处理导致频繁系统调用,开销巨大。
| 语言 |
逐行处理 (秒) |
批量处理 (秒) |
提升倍数 |
| Java |
637.42 |
9.20 |
69x |
| C++ |
- |
17.15 |
- |
| Rust |
29.56 |
29.38 |
1.01x |
注:C++ 和 Rust 的 V1 已包含基础批量,所以提升不明显。
原理:1.14亿行逐行处理需要约1.14亿次 read() + 1.14亿次 write()。批量处理后,系统调用次数降到几万次,大幅减少了上下文切换开销。
2. 缓冲区大小的影响
原理:现代文件系统(如Linux ext4/xfs)的预读块通常为64-128KB。应用程序的缓冲区大小应与之匹配,以充分利用内核的预读机制,减少实际的磁盘I/O次数。
| 缓冲区大小 |
系统调用次数 (4GB文件) |
效率 |
| 8KB (默认) |
~524,000 |
低 |
| 64KB |
~65,500 |
高 |
| 4MB |
~1,000 |
极高 |
3. Nagle算法的影响
算法目的:TCP小包合并算法,旨在减少网络中小数据包的数量,降低网络阻塞,提升整体效率。
算法规则:
- 如果发送窗口中还有未确认(ACK)的数据,
- 且当前要发送的数据长度 < MSS(最大段大小,通常1460字节),
- 那么不立即发送,而是缓存起来,等待:收到对之前数据的ACK,或缓存的数据累积 ≥ MSS。
为什么在这个场景下禁用Nagle能提升效率?
当前场景是单向无交互数据流(Reader → Writer),且通过批量处理保证了每次发送的数据量足够大。
禁用Nagle后,调用 send() 的数据会立即进入TCP发送队列,无需等待ACK。通过设置较大的Socket发送缓冲区(如1MB)和批量发送,可以确保每次 send() 都能填满或接近填满TCP发送缓冲区,从而避免Nagle算法的小包合并逻辑,降低延迟。
// Java 禁用 Nagle
socket.setTcpNoDelay(true);
// C++ 禁用 Nagle
int flag = 1;
setsockopt(sock, IPPROTO_TCP, TCP_NODELAY, &flag, sizeof(flag));
Java 优化过程
版本1 → 版本2:从 637秒 到 9.2秒
关键改动:
BATCH_SIZE 累积5000行后发送。- 缓冲区从8KB增至64KB。
- 用
StringBuilder 替代字符串拼接。
核心代码对比:
// V1: 逐行处理 + 字符串拼接
String processed = line.substring(0, third) + line.substring(2*third);
out.write((processed + "\n").getBytes());
out.flush();
// V2: 批量处理 + StringBuilder
StringBuilder batch = new StringBuilder(64 * 1024);
batch.append(processedLine).append('\n');
if (lineCount % BATCH_SIZE == 0) {
out.write(batch.toString().getBytes(CODE));
batch.setLength(0);
}
性能提升:69倍
原理:系统调用次数从约2.28亿次降至约9万次;StringBuilder 避免了大量中间 String 对象的创建。
深度分析:
- 系统调用次数指数级减少:V1每行都伴随
read()、write()、flush(),总计约2.28亿次。V2通过64KB缓冲区和5000行批量,将总调用次数降至约9万次,仅此一项开销就相差2500倍。
- StringBuilder避免中间对象:V1每行拼接会隐式创建多个
StringBuilder 和 String 对象,1.14亿行可能产生数亿个临时对象。V2预分配一个64KB的 StringBuilder 并重用,每5000行才创建一个 String 对象用于转换字节数组,对象数量从亿级降至万级。
- 缓冲区匹配系统预读:V1的8KB缓冲区小于系统预读块(通常128KB),无法充分利用预读数据。V2的64KB缓冲区能更有效地消耗预读数据,减少磁盘I/O。
- 减少flush()调用:V1每行flush强制刷盘,V2每5000行flush一次,允许TCP协议栈合并数据包,减少网络层处理开销。
版本2 → 版本4:从 9.2秒 到 5.1秒
关键改动:
- 抛弃字符流,直接操作字节数组。
- 手动解析换行符。
- 使用超大缓冲区(8MB)。
核心代码:
// V4: 纯字节操作
byte[] buffer = new byte[8 * 1024 * 1024];
byte[] output = new byte[8 * 1024 * 1024];
int outPos = 0;
while ((bytesRead = fis.read(buffer)) != -1) {
for (int i = 0; i < bytesRead; i++) {
if (buffer[i] == '\n') {
// 直接拷贝字节,零对象分配
System.arraycopy(buffer, startLine, output, outPos, third);
System.arraycopy(buffer, startLine + 2*third, output, outPos+third, keepEnd);
outPos += third + keepEnd + 1; // +1 for '\n'
}
}
}
性能提升:1.77倍
原理:完全绕过 String 对象和UTF-8解码/编码开销,8MB缓冲区进一步将系统调用次数从约6.5万次减少到仅约512次。
注:此优化前提是文本文件为纯ASCII,否则绕过UTF-8解码可能导致错误。
深度分析:
- 消除字符编码开销:V2的
BufferedReader.readLine() 需要将字节解码为UTF-16字符(Java String 内部格式)。V4直接操作字节,对纯ASCII文本无需任何解码。
- 零临时对象分配:V2每行仍会创建
String 对象,V4只使用两个固定的字节数组,处理过程中不创建任何临时对象,极大减轻了GC压力。
System.arraycopy() 高效内存拷贝:该方法内部使用类似 memcpy 的底层操作,比逐字符复制或 StringBuilder 的追加操作快得多。- 8MB缓冲区优势:将
read() 系统调用次数从约6.5万次(64KB缓冲)降至约512次,几乎消除了用户态/内核态切换的开销,并更好地利用了CPU缓存局部性。
- 手动行解析:替代
readLine() 的逐字符逻辑,在8MB块内批量扫描 \n,函数调用开销极低。
Java 完整优化路径
| 版本 |
耗时(秒) |
关键技术 |
提升倍数 |
| V1 |
637.42 |
逐行处理 + String 拼接 |
- |
| V2 |
9.20 |
批量 + StringBuilder + 64KB缓冲 |
69x |
| V3 |
8.68 |
Socket → 管道 |
1.06x |
| V4 |
5.10 |
纯字节操作 + 8MB缓冲 |
1.77x |
C++ 优化过程
版本1 → 版本3:从 24.96秒 到 13.19秒
关键改动:使用 memmove() 原地修改字符串,避免创建新对象。
核心代码对比:
// V1: 创建新字符串
return line.substr(0, third) + line.substr(2 * third);
// V3: 原地修改
void removeMiddleThirdInPlace(std::string& line){
size_t third = len / 3;
size_t keep_end = len - 2 * third;
memmove(&line[third], &line[2 * third], keep_end); // 直接移动内存
line.resize(len - third);
}
性能提升:1.89倍
原理:memmove() 直接操作内存地址,比 substr() 创建新字符串快得多,完全消除了临时字符串的内存分配与释放开销。
深度分析:
V1的 substr() 和拼接操作,每行需要:3次内存分配 + 4次内存拷贝 + 2次内存释放,总计9次内存操作。1.14亿行就是约10.26亿次操作。
V3的原地修改,每行仅需:1次内存移动 (memmove) + 1次修改长度 (resize),总计约1.14亿次操作。内存管理开销降低了一个数量级。
版本3 → 版本6:从 13.19秒 到 4.11秒
关键改动:
- V5:自定义
FastLineReader,批量读取 + 手动行解析。
- V6:使用原生系统调用
open()/read()/write() 替代 std::ifstream/ofstream,直接操作 char* 缓冲区(4-8MB)。
核心代码片段:
// V3: 标准库流 + getline()
std::ifstream file(input_filename);
std::string line;
while (std::getline(file, line)) {
removeMiddleThirdInPlace(line);
// ... 发送处理后的行
}
// V6: 原生系统调用 + 手动解析
int fd = open(input_filename.c_str(), O_RDONLY);
ssize_t n = read(fd, file_buffer.data() + file_size, 4*1024*1024); // 4MB读取
// 在缓冲区中手动查找换行符并处理
memmove(line_ptr + third, line_ptr + 2*third, keep_end); // 原地修改
性能提升:3.21倍
原理:绕过了 std::ifstream 和 std::getline 的多层抽象与虚函数调用开销;4MB大缓冲区大幅减少 read() 系统调用次数;手动行解析避免了 getline() 逐字符处理的低效。
深度分析:
- 绕过
std::ifstream抽象层:std::getline() 内部涉及虚函数调用、错误状态检查、字符类型转换等,每字符都有固定开销。直接使用 read() 系统调用则无任何中间层。
- 大缓冲区协同效应:V3默认使用约8KB缓冲区,需要约50万次
read()。V6使用4MB缓冲区,仅需约1000次 read(),减少了99.8%的用户态/内核态切换。
- 手动行解析 vs
getline():getline() 是逐字符处理。V6在4MB缓冲区内一次性扫描所有 \n 位置,算法效率更高,且无函数调用开销。
- *`char
vsstd::string**:直接操作char*缓冲区提供了对内存布局的完全控制,消除了std::string` 对象的构造/析构及元数据开销。
C++ 完整优化路径
| 版本 |
耗时(秒) |
关键技术 |
提升倍数 |
| V1 |
24.96 |
std::getline + substr |
- |
| V2 |
17.15 |
字符串预分配 + 64KB缓冲 |
1.46x |
| V3 |
13.19 |
memmove 原地修改 |
1.30x |
| V5 |
5.85 |
自定义 FastLineReader |
2.26x |
| V6 |
4.11 |
**原生 read/write + char*** |
1.42x |
Rust 优化过程
版本1 → 版本2:从 29.56秒 到 9.91秒
关键改动:使用字节切片 &[u8] 和 Vec<u8> 替代 &str 和 String,避免UTF-8验证开销。
核心代码对比:
// V1: 字符串操作(安全但有开销)
for line in reader.lines() {
let processed_line = remove_middle_third(&line); // line: String
}
fn remove_middle_third(line: &str) -> String {
let mut result = String::with_capacity(len - third);
result.push_str(&line[..third]);
result.push_str(&line[2 * third..]);
result
}
// V2: 字节切片操作(零验证开销)
for line_bytes in reader.split(b'\n') {
let processed_line = remove_middle_third_bytes(&line_bytes); // line_bytes: Vec<u8>
}
fn remove_middle_third_bytes(line: &[u8]) -> Vec<u8> {
let mut result = Vec::with_capacity(new_len);
result.extend_from_slice(&line[..third]);
result.extend_from_slice(&line[2 * third..]);
result
}
性能提升:2.98倍
原理:对于纯ASCII文本,UTF-8验证是冗余开销。&[u8] 操作完全绕过验证;extend_from_slice() 是高效的 memcpy,比 String::push_str() 更直接。
深度分析:Rust的“零成本抽象”选择
Rust的 &str/String 保证内存安全且是有效的UTF-8,但为此付出了运行时验证的成本。在本场景(纯ASCII)下,这些验证是不必要的。
通过选择更底层的 &[u8]/Vec<u8>,我们在不牺牲内存安全(所有权系统仍在工作)的前提下,移除了所有冗余的UTF-8验证和字符边界检查,使编译后的代码达到与手写C相近的效率,这正是“零成本抽象”的体现:你只为需要的功能付费。
版本2 → 版本5:从 9.91秒 到 4.99秒
关键改动:
- V3:引入
jemalloc 内存分配器,优化多线程下的小对象分配。
- V4:手动管理4MB缓冲区,减少
read() 系统调用,精确处理跨块行。
- V5:零分配行处理,直接写入输出缓冲区,消除中间
Vec<u8>。
核心代码片段:
// V5: 零分配处理
fn push_line_removed_middle_third(line: &[u8], out: &mut Vec<u8>) {
let third = line.len() / 3;
out.extend_from_slice(&line[..third]); // 直接写入输出缓冲区
out.extend_from_slice(&line[2*third..]);
}
性能提升:1.99倍
原理:jemalloc 优化了小对象分配性能;4MB缓冲区将 read() 调用从约4000次降至约1000次;零分配设计避免了每行处理创建临时 Vec<u8> 的开销。
Rust 完整优化路径
| 版本 |
耗时(秒) |
关键技术 |
提升倍数 |
| V1 |
29.56 |
BufReader.lines() + String |
- |
| V2 |
9.91 |
split(b'\n') + &[u8] |
2.98x |
| V3 |
7.53 |
jemalloc 分配器 |
1.32x |
| V4 |
5.77 |
手动 4MB 缓冲区 |
1.31x |
| V5 |
4.99 |
零分配行处理 |
1.16x |
总结与通用原则
优化原理与适用条件
| 优化技术 |
底层原理 |
适用条件 |
| 大缓冲区 (64KB–8MB) |
匹配文件系统预读块,减少用户态/内核态切换次数。 |
顺序读写大文件,内存充足。 |
| 字节操作 (&[u8]/byte[]) |
绕过字符编码验证,直接内存拷贝,避免对象创建。 |
纯ASCII或已知编码的二进制数据处理。 |
| 原生系统调用 (read/write) |
绕过高级API的多层抽象,直接进入内核。 |
高频I/O、性能敏感的底层应用。 |
| 零分配设计 |
消除中间临时对象,直接在目标缓冲区操作。 |
批量数据处理、流式处理场景。 |
| 高效分配器 (如jemalloc) |
线程本地缓存 + 分离的大小类,减少锁竞争和碎片。 |
多线程、频繁小内存分配的服务。 |
优化优先级排序
| 优先级 |
优化类型 |
预期收益 |
实施难度 |
适用阶段 |
| 🔴 最高 |
减少系统调用次数 |
10-1000x |
低 |
所有项目 |
| 🟠 高 |
消除不必要的对象分配 |
2-50x |
中 |
内存敏感场景 |
| 🟡 中 |
选择合适的缓冲区大小 |
2-5x |
低 |
I/O 密集型 |
| 🔵 低 |
微调分配器/编译参数 |
1.1-1.5x |
高 |
性能极致优化 |
最终性能对比
| 语言 |
初始耗时 |
最终耗时 |
总提升倍数 |
| Java |
637.42s |
5.10s |
122.6x |
| C++ |
24.96s |
4.11s |
6.07x |
| Rust |
29.56s |
4.99s |
5.93x |
注:C++ 和 Rust 的初始版本已包含基础批量处理,所以总提升倍数没有Java显著。三者经过深度优化后,性能处于同一量级,Rust和C++凭借更底层的控制能力略有优势。
进阶架构:IO进程与Processor进程解耦
前面的实现采用了Reader/Writer两进程模型,但在追求极致性能和可扩展性时,我们尝试了更彻底的解耦架构。
新方案概览:IO进程 + Processor进程
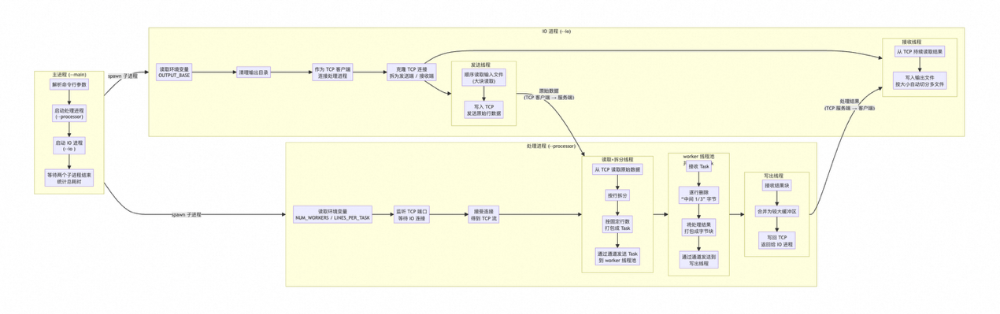
新的架构将“读写文件”和“行处理逻辑”拆分成两个独立进程:
- IO进程(纯IO):
- 一个线程:从输入文件顺序读大块数据(8MB缓冲),通过TCP发送给Processor。
- 一个线程:从TCP接收处理后的数据,按大块(如300MB)切分写到多个输出文件(8MB缓冲)。
- Processor进程(纯业务处理):
- 读线程:监听TCP,接收数据,按
\n 拆行,打包成Task(固定行数)。
- Worker线程池:并行处理Task,对每行执行“删除中间1/3”操作(基于字节切片)。
- 写线程:将多个处理结果合并为大块(8MB),写回TCP给IO进程。
- 主进程:负责启动、协调和监控。
新架构优势
- 职责彻底解耦:IO优化(缓冲区、文件切分)与业务逻辑优化(算法、并行度)可以独立进行,互不影响。
- 充分利用多核:Processor内部的线程池可以将CPU密集的行处理任务均匀分配到所有核心。
- 延续优化原则:新架构内部依然坚持大缓冲区、字节操作、零分配等核心原则,并使用了
jemalloc 和 memchr 等工具进行微观优化。
- 可扩展性强:未来可以轻松地将IO进程和Processor进程部署到不同机器,实现存储与计算的分离。
新架构运行结果
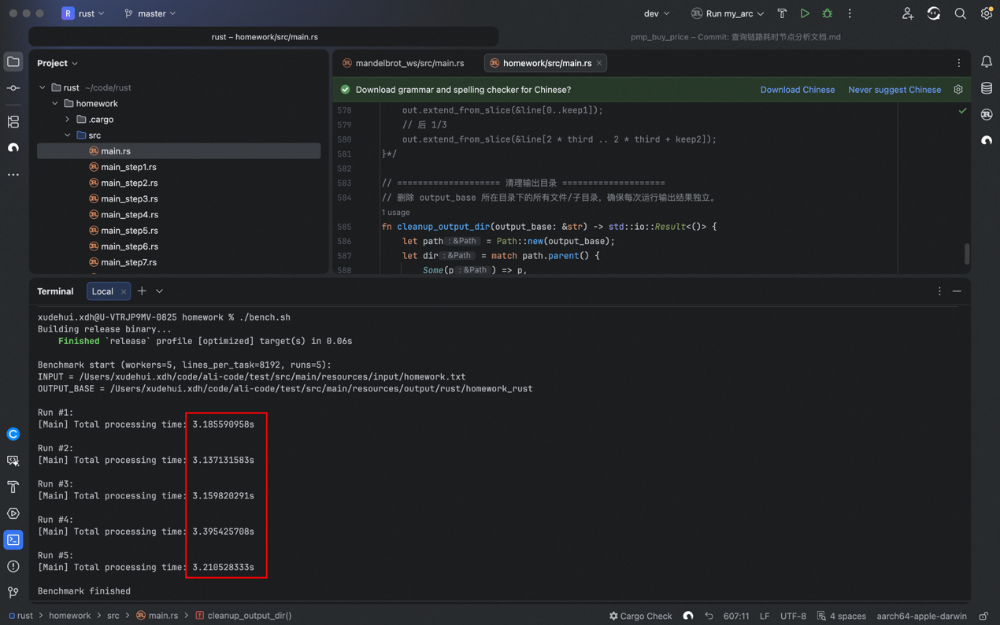
在新架构下(使用Rust实现),处理同一4GB文件的耗时均值达到了 3.22秒。
写在最后
这次优化之旅从637秒到3.2秒,不仅仅是数字的提升,更是一系列系统编程原则的实践:理解抽象成本、尊重硬件特性、平衡内存与IO。无论是使用Java、C++还是Rust,核心思想是相通的——减少系统调用、避免冗余分配、匹配底层特性。希望这些具体的案例和数据分析,能为你在处理类似的大数据量、高性能场景时提供切实的参考。
如果你对系统编程、性能优化或特定语言的高阶用法有更多兴趣,欢迎在云栈社区与其他开发者交流探讨。
 发表于 2026-2-7 07:35:18
|
查看: 225|
回复: 0
发表于 2026-2-7 07:35:18
|
查看: 225|
回复: 0
