凌晨1:45,Anthropic发布了Claude Opus 4.6。短短半小时后,OpenAI的CEO Sam Altman便宣布了GPT-5.3-Codex的到来。
这接连的发布,立刻在国内科技圈引发了一波“剧情猜想”,各种关于狙击、贴脸开大、正面硬刚的讨论层出不穷。一次正常的产品迭代能被解读出这么多故事,也侧面说明了大家对这两家头部人工智能公司的关注。今天我们不谈八卦,只聚焦模型本身,聊聊这两个新版本到底有何不同。
一、先搞清楚出身:定位截然不同
很多人一看到AI模型对比,就默认它们是直接竞品。其实,从底层逻辑看,Claude Opus 4.6和GPT-5.3-Codex的出身和定位完全不同。
Claude Opus 4.6是“全能优等生”的专项加强。 它本质上是Claude Opus系列的迭代版本。Opus一直是Anthropic旗下最聪明的模型,以擅长复杂推理、长文本分析和跨领域知识整合而闻名。这次的4.6版本,可以看作是在保持其全能优势的基础上,对编程能力进行了一次重点加强。
GPT-5.3-Codex则是“专业码农”的通用化尝试。 它属于OpenAI专为代码而生的Codex系列。这个系列从诞生起目标就非常明确:写代码。以往的Codex模型几乎只懂编程,不通其他。而这次的5.3版本,OpenAI做了一个有趣的改变——为它注入了一些通用能力,让它不仅能写代码,还能理解需求、解释设计思路,试图成为一个更“好沟通”的编程伙伴。

正是这种根本性的差异,决定了它们在许多具体场景下的表现会大相径庭。
二、关键数据对比:各有胜负
官方和第三方评测机构公布了不少数据,我们挑几个最有代表性的来看:
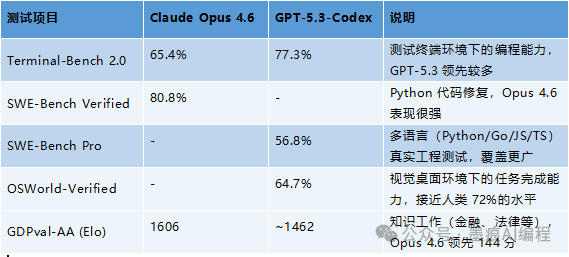
从这份对比中,我们可以抓住几个重点:
- 在特定编程基准测试上,GPT-5.3-Codex领先。 在Terminal-Bench 2.0(测试终端环境下的编程能力)上,77.3%对65.4%的差距不小。这类测试更接近真实的开发环境,说明在纯粹的编码执行和终端操作上,GPT-5.3-Codex的专业性依然强悍。
- Claude Opus 4.6的百万Token上下文是“核武器”。 它提供了目前主流模型中已知最长的上下文窗口(测试版),高达100万Token。这意味着它可以一次性处理极其庞大的代码库或文档,对于需要进行深度、全局分析的场景是降维打击。
- 解读分数需要结合测试背景。 不要单纯比较百分比。例如,Opus 4.6在SWE-Bench Verified(Python代码修复)上拿到了80.8%的高分,但这个测试主要针对Python。而GPT-5.3-Codex在SWE-Bench Pro上取得56.8%,这个测试覆盖了Python、Go、JS/TS四种语言,难度和广度都不同。哪个对你更有用,很大程度上取决于你的主要技术栈。
三、核心功能差异:两种产品思路
除了冰冷的跑分,这次更新带来的一些新功能更能体现两家公司不同的产品思路。
Claude Opus 4.6 的新武器:
- 四级自适应思考模式: 以前Claude的“深度思考”是一个手动开关。现在升级为低、中、高、最高四档,并且由模型根据问题复杂度自动选择。简单问题秒回,复杂问题它会“多想想”再给出更可靠的答案,这提升了回答质量和效率的平衡。
- 多智能体协作: 这个功能类似于让多个AI专家组成一个项目组。例如,当你需要重构一个系统时,架构师Agent会先规划蓝图,然后前端、后端Agent分别设计方案,测试Agent同步编写用例,最后整合成一份可执行的开发清单。这适合复杂的、需要多角度规划的任务。
- 百万Token上下文与对话压缩API: 如前所述,百万Token是测试版福利。但即便是标准版的20万Token上下文,配合新推出的Compaction API(可自动压缩和总结历史对话内容),理论上能实现近乎无限的连续性长对话,非常适合长文档分析、连载式代码评审等场景。
GPT-5.3-Codex 的发力点:
- 任务中实时引导: OpenAI这次特别强调了GPT-5.3-Codex的“可操控性”。你可以在AI编写代码或执行任务的过程中随时打断它、提出新要求、调整方向,它能够理解并继续,而不会“失忆”或需要从头开始。这让交互过程更像与一个真正的程序员合作。
- 自我参与开发: 根据OpenAI官方说法,GPT-5.3的早期版本曾参与到自身的开发过程中,辅助进行调试、管理部署和分析测试结果。当然,这并非指AI完全自我训练,而是OpenAI的工程师团队将其作为高级开发工具来使用,就像我们使用代码助手一样。
- 原生桌面应用体验: OpenAI为Codex推出了原生的macOS桌面应用(Windows版已在规划中),旨在提供更流畅、集成的开发体验。相比之下,Claude的高级功能(如多智能体协作、压缩API)目前更依赖API或网页端,需要一定的技术背景来集成和调用。
四、价格与门槛:算一笔经济账
谈到实际使用,价格是无法回避的因素。
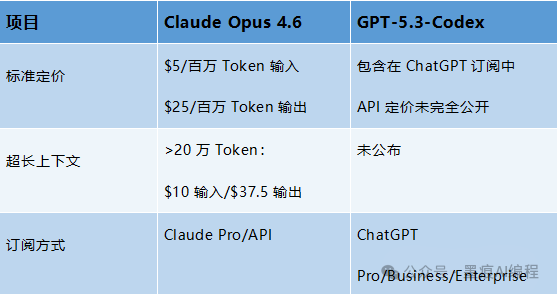
从上表可以看出,Claude Opus 4.6的API调用费用确实不菲,特别是输出Token的价格。其超长上下文版本(百万Token)价格更高。但反过来想,如果你的业务场景需要一次性消化整个代码仓库或数百页的合同、论文,这个投入可能是值得的,因为它能避免多次调用和信息割裂带来的成本与误差。
GPT-5.3-Codex则被包含在ChatGPT的订阅服务中(Pro/Business/Enterprise等层级),对于已经订阅的用户来说,相当于新增了一个强大的专业模块。其独立的API定价细节尚未完全公开,但预计会遵循OpenAI的一贯风格。
五、如何选择?回归你的核心场景
综合来看,选择哪一款模型,关键在于你的核心需求是什么:
当然,对于有条件的团队或个人,两者搭配使用可能是更理想的选择:用Opus 4.6进行宏观架构设计、遗留代码库分析和复杂文档处理,用GPT-5.3-Codex聚焦于具体的功能模块实现和日常编码。
技术的迭代永远在继续,模型的对比也只是当下的快照。对于开发者而言,更重要的是理解这些工具的特性,将它们应用到能真正产生价值的场景中去。关于AI编程工具的更多实践和讨论,欢迎在云栈社区交流分享。 |  发表于 2026-2-8 07:37:35
|
查看: 261|
回复: 0
发表于 2026-2-8 07:37:35
|
查看: 261|
回复: 0
