孩子们的好奇心永远不会枯竭,他们的问题也总是天马行空。当孩子问“天上那道彩色的桥是什么?”时,传统的AI往往只会机械地回答“彩虹的形成原理”——知识在这里,只变成了一个孤立的答案,而非思考的起点。为了让AI既能理解儿童千奇百怪的问法,又能从私域知识库里精准提取知识点,并自动生成适合孩子年龄段的科普内容,我们基于 RDS MySQL 向量存储能力 搭建了一个名为“知深识易”的儿童科普生成应用。
整个应用的核心目标是“听得懂、召得准、记得住”,这离不开两大关键技术:从知识库中按语义召回内容的 RAG,以及能够记住用户特征、实现个性化交互的 长期记忆。这两者都高度依赖向量存储与检索。同时,AI应用自身的元数据也需要数据库进行持久化存储。如果为向量数据和业务元数据各自搭建一套存储系统,不仅架构分裂,运维成本也会成倍增加。阿里云 RDS MySQL 将向量能力集成到数据库内核中,通过“一套实例、统一存储、原生支持”的方式,让RAG和长期记忆这两类能力都构建在你最熟悉的MySQL之上,支持开发者一站式完成AI应用的快速开发。
背景
在学龄前(3–6岁)和小学阶段(7–12岁),孩子们每天都在问“为什么”。但无论是教育者还是家长,都面临着几个核心难题:
- 内容难整合:优质的科普知识散落在绘本、视频、网站乃至私域材料中,查找和整理耗时费力。
- 制作门槛高:一条简单的科普视频,需要经历剪辑、配音、脚本撰写等流程,通常需要2–4小时,普通人难以持续产出。
- 注意力匹配难:儿童的专注力通常只有3–10分钟,冗长的视频效果不佳,而优质的、适龄的短内容又极度稀缺。
更深层次的问题在于:即使找到了答案,也常常是孤立的碎片。孩子问“彩虹怎么来的?”,得到的可能只是一句简单的解释——其中没有关联“光的折射”、“水滴形状”、“太阳位置”等概念,知识无法在孩子脑海中生长为一张相互关联的认知网络。更常见的情况是,当孩子换个方式问:“天上那道彩色的桥是什么?”,传统的系统可能直接告诉你“我现在还不会哦,请换一个问题问吧”。
为了解决这些问题,我们构建了一个端到端的系统。它基于私域教材和公域权威资源(例如《十万个为什么》),通过 数据 + 向量检索 + AI框架 + 基础大模型,实现了从多源知识接入到多模态内容生成的全链路能力:多源接入 → 智能提取 → 信息泛化 → 知识召回 → 模型回答 → 多模态生成。
应用介绍
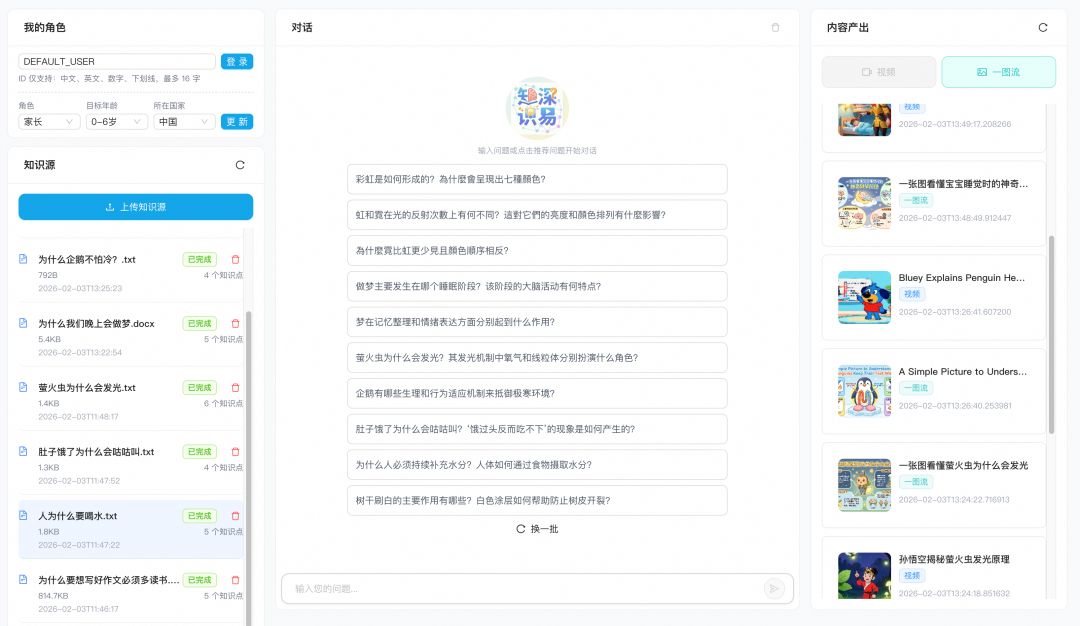
知识源管理功能
- 知识入库:系统将复杂、多格式的知识源(图片、PDF、文档、文本)拆分为清晰的知识点,并对每条知识点进行 embedding 向量化,最后将向量写入 RDS MySQL,为后续的语义检索做好准备。
- 问题挖掘泛化:通过“设问”的形式,预先挖掘并拓展知识点可能对应的问题。有问题才有学习,平铺直叙的知识介绍往往印象不深。预设问题一方面简化了用户的操作路径,另一方面也带来了更好的学习引导效果。
- 向量化构建 RAG:知识源经过模型拆分提取出知识点,经过向量化处理后存放在RDS MySQL的向量表中,为LLM提供“从私域知识库快速、精准召回”的能力,这正是 RAG 的核心。
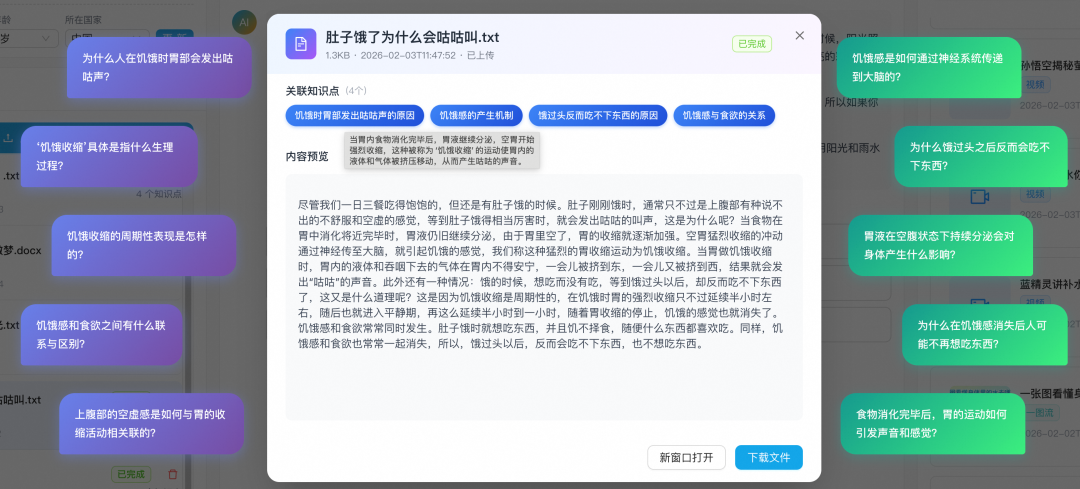
内容脚本生成功能
- 问题提取:当用户提问时,系统会结合存储在长期记忆中的用户画像,将孩子们天马行空的问题进行归一化处理,转化为可供向量检索的“标准问题”。例如,系统会预先知道用户可能是学龄前儿童,在提示词中引导模型进行问题联想,找到用户问法背后的真实意图。
- RAG 知识召回:将归一化后的问题,使用与入库时一致的Embedding模型(如Qwen-Embedding)转换为向量,然后在 RDS MySQL 中进行向量相似度检索,召回Top-K个最相关的知识片段,从而从私域知识库中获取定制化的知识点作为大模型生成脚本的上下文。
- 长期记忆:用户画像、偏好、历史对话等信息以“记忆向量 + 元数据”的形式存储在同一MySQL实例中(可配合基于Mem0的MCP等方案),实现“记住用户”并自动生成贴合该用户特征的内容脚本。
- 内容脚本生成:在 RAG 与长期记忆的基础上,由大模型生成初步回答,再对结果进行针对性的蒸馏和优化,得到适合视频、图片生成的最终prompt。

多模态内容生成功能
- 可扩展架构:系统架构支持快速扩展需要生成的产出类型(如视频、信息图等)。要接入一种新的内容类型,只需在内容脚本生成流程中,添加对应的prompt生成节点,并提供给相应的生成模型即可。
-
Prompt优化:针对轻科普脚本,我们先用大模型把脚本压缩成“核心知识概念”,再交给视频或图像模型。这样做可以减少长文本对多模态模型的干扰,提升生成质量。例如,图片生成的规则提示如下:
将用户输入提取 3~4 个核心的概念知识点,以及一个标题,标题格式是「一张图看懂xxxx」。
你的输出需要严格遵守下面的输出格式范例,替换其中的标题和核心知识点以及一句话解释,不要有多余内容,具体知识点数量根据输入情况自行判断。
## 输出格式
「生成信息图:通俗易懂,适合{age}年龄段的儿童,语言和用户输入语言相同。标题:一张图看懂xxxx,内容:1. 核心概念知识点:一句话解释。2. 省略,同1。3. xxx 4. xxx」。
提取出核心概念后,模型能在不偏离主题的前提下生成更聚焦的媒体内容,并减少过多文字细节对画面质量的干扰。

技术框架与向量集成
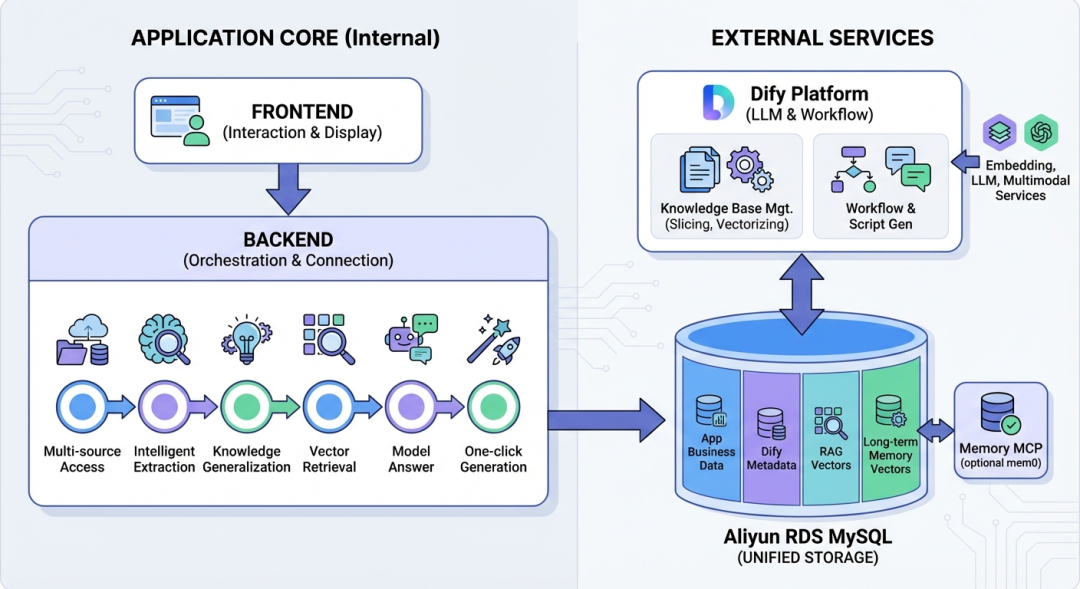
如何使用RDS MySQL 搭建 RAG 服务
RAG 是 AI 应用中的重要组成部分,其基本实现流程是:知识库文档/问法 → embedding → 写入 MySQL 向量表 → 查询时向量检索。
RDS MySQL 目前已经集成了 Dify、LangChain、LlamaIndex 等主流 AI 框架。下面以 Dify 与 LangChain 为例进行介绍。
使用 Dfiy 搭建基于 RDS MySQL 的 RAG 服务
通过「知识库」+ 数据集(Dataset)管理文档,底层可配置为 RDS MySQL 向量,实现「文档 → 切片 → 向量化 → 存入 MySQL → 工作流中检索」的全流程。
- 准备 RDS MySQL
- 使用阿里云 RDS MySQL 8.0,小版本 ≥ 20251031,并开启向量能力[1]。
- 创建好数据库与账号。
- 部署 Dify,使用 Dify v1.11.0 及以上版本。
- 配置向量存储为阿里云 MySQL,在环境变量中配置:
VECTOR_STORE=alibabacloud_mysql
- 创建知识库与数据集
- 在 Dify 控制台创建「知识库」,选择底层向量库为已配置好的 RDS MySQL;上传或录入文档后,Dify 会自动完成切片、向量化并写入 MySQL。
- 在「工作流」中通过「知识库检索」节点即可从该 MySQL 向量库进行 RAG 召回。
使用 LangChain 搭建基于 RDS MySQL 的 RAG 服务
通过 langchain-alibabacloud-mysql 等集成,使用 AlibabaCloudMySQL 作为 VectorStore,在代码中完成文档入库与相似度检索,再接入 Chain 或 Agent。
以下展示如何用 RDS MySQL 向量 创建一个简单的 RAG 链路:初始化向量库、写入文档、检索、并接入 LLM 生成最终答案。
- 环境变量(与 Dify 对齐):
ALIBABACLOUD_MYSQL_HOST、ALIBABACLOUD_MYSQL_PORT、ALIBABACLOUD_MYSQL_USER、ALIBABACLOUD_MYSQL_PASSWORD、ALIBABACLOUD_MYSQL_DATABASE- 若使用 DashScope Embedding:
DASHSCOPE_API_KEY
- 安装依赖:
pip install -U langchain-alibabacloud-mysql
-
初始化向量库与 Embedding:
import os
from langchain_alibabacloud_mysql import AlibabaCloudMySQL
from langchain_community.embeddings import DashScopeEmbeddings
embeddings = DashScopeEmbeddings(
model="text-embedding-v4",
dashscope_api_key=os.environ.get("DASHSCOPE_API_KEY"),
)
vector_store = AlibabaCloudMySQL(
host=os.environ.get("ALIBABACLOUD_MYSQL_HOST", "localhost"),
port=int(os.environ.get("ALIBABACLOUD_MYSQL_PORT", "3306")),
user=os.environ.get("ALIBABACLOUD_MYSQL_USER", "root"),
password=os.environ.get("ALIBABACLOUD_MYSQL_PASSWORD", ""),
database=os.environ.get("ALIBABACLOUD_MYSQL_DATABASE", "test"),
embedding=embeddings,
table_name="langchain_vectors_rag",
distance_strategy="cosine",
hnsw_m=6,
)
-
写入文档与相似度检索:
from langchain_core.documents import Document
docs = [
Document(page_content="彩虹是阳光穿过水滴发生折射和反射形成的", metadata={"source": "科普"}),
Document(page_content="光的折射与波长有关,不同颜色的光折射角不同", metadata={"source": "物理"}),
]
vector_store.add_documents(documents=docs)
# 检索
results = vector_store.similarity_search(query="彩虹的形成原理", k=3)
for doc in results:
print(doc.page_content, doc.metadata)
-
接入 RAG Chain(检索 + LLM 生成):
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_classic.chains import create_retrieval_chain
from langchain_classic.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
prompt = ChatPromptTemplate.from_template(
"仅根据以下上下文回答问题。\n\n上下文:{context}\n\n问题:{input}"
)
llm = ChatTongyi()
document_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(retriever, document_chain)
response = rag_chain.invoke({"input": "天上那道彩色的桥是什么?"})
print(response["answer"])
更多细节可参考 LangChain 官方文档:https://docs.langchain.com/oss/python/integrations/vectorstores/alibabacloud_mysql
如何使用 RDS MySQL 搭建记忆服务
记忆服务用于持久化存储和召回用户画像、对话历史等信息,典型的实现方式是:基于记忆 MCP(如 Mem0 + RDS MySQL)或自建记忆表 + 向量检索。
使用 Mem0 MCP 搭建基于 RDS MySQL 的记忆服务
阿里云 RDS MySQL 提供了基于 Mem0 的、底层使用 RDS MySQL 的记忆 MCP Server,可以一键部署到函数计算等环境中,让 Agent 通过 MCP 协议直接读写长期记忆。
- 项目入口(供参考):mcp-rds-mysql-openmemory
- 部署后,在 Cursor/IDE 或自建 Agent 中配置该 MCP Server,即可在应用中直接使用“记忆”能力,而无需自建复杂的向量记忆表。
应用逻辑与元信息存储:统一数据库存储的价值
值得一提的是,使用 RDS MySQL 作为 RAG 与长期记忆的底层向量存储 的同时,你还可以把应用的元数据(用户、文档、会话、配置等)也放在同一个数据库实例中。这带来的核心好处是:一个数据库即可完成 AI 应用所需的关系型数据与向量数据存储,避免了“业务库 + 向量库”双系统带来的数据一致性、运维复杂度和技能栈分裂问题。在阿里云 RDS 上,还可借助内核级的向量优化(如 HNSW 索引、量化等),在单实例内达到接近专用向量库的性能与规模。
在AgentRun平台一键部署《知深识易》
你可以按照前文的步骤动手开发一个集成了RAG和记忆的AI应用。此外,我们也已将应用接入AgentRun平台的官方应用模板,你可以在这里快速部署“知深识易”进行实战体验。
地址:https://functionai.console.aliyun.com/cn-hangzhou/agent/explore
AgentRun是阿里云提供的以高代码为核心,开放生态、灵活组装的一站式Agentic AI基础设施平台,为企业级Agentic应用提供开发、部署与运维的全生命周期管理。
部署前需要准备的资源:开启了向量功能的RDS MySQL实例;根据平台指引创建记忆存储服务(底层选用自定义的RDS MySQL实例),并将创建的记忆服务名称作为一键部署的参数传入;百炼平台API KEY,用于视频、图片内容的生成。
小结
RDS MySQL 的向量能力在“知深识易”应用中主要承担了两个角色:一是把知识“压”进数据库——知识点与归一化的问题表述经过同一套 Embedding 模型处理,存入MySQL向量表,查询时通过语义相似度快速召回,为大模型提供“按题取料”的精准上下文;二是把用户“记住”——用户画像和使用习惯以向量形式存储在同一个数据库里,需要时按需检索,让生成的内容越用越贴合个人需求。二者共用一套 RDS MySQL 实例,无需再为 RAG 和长期记忆各自维护一套向量数据库,架构更简洁,运维也更可控。希望本文的实践能为你构建自己的AI应用提供一些思路,也欢迎在 云栈社区 交流探讨。
参考链接:
[1] RDS MySQL向量存储官方文档:https://www.alibabacloud.com/help/zh/rds/apsaradb-rds-for-mysql/vector-storage-1
[2] LlamaIndex集成示例:https://github.com/run-llama/llama_index/blob/main/docs/examples/vector_stores/AlibabaCloudMySQLDemo.ipynb
 发表于 2026-2-8 07:42:25
|
查看: 231|
回复: 0
发表于 2026-2-8 07:42:25
|
查看: 231|
回复: 0
