在业务复杂度日益增长的今天,单纯依赖数据库这类存储系统的性能提升已经捉襟见肘。你是否遇到过以下两种典型场景?
-
场景一:复杂运算,存储系统无能为力
想象一下,一个论坛需要实时在首页展示当前在线用户总数。如果使用 MySQL 来存储用户状态,每次都需要执行 COUNT(*) 来统计海量数据。无论怎么优化索引和查询,这样的聚合操作对数据库而言都是巨大的负担,性能瓶颈难以突破。
-
场景二:读多写少,存储系统有心无力
如今绝大多数互联网业务,如微博、淘宝、微信,读操作的比例往往超过90%。以微博为例:一位明星发布一条动态,可能会迎来数千万次的浏览。如果所有读取请求都直接落到 MySQL 上,即便有索引,数千万条 SELECT 语句带来的压力也足以让数据库不堪重负。
正是在这些复杂场景下,缓存的价值得以凸显。它的核心思想很简单:将可能被重复使用的数据放在内存中,做到一次生成、多次复用,从而避免每次请求都去“打扰”背后的存储系统。缓存带来的性能提升是飞跃性的,以经典的 Memcache 为例,其简单的键值查询能够达到惊人的 TPS 50000+。一个典型的缓存基本架构如下图所示:
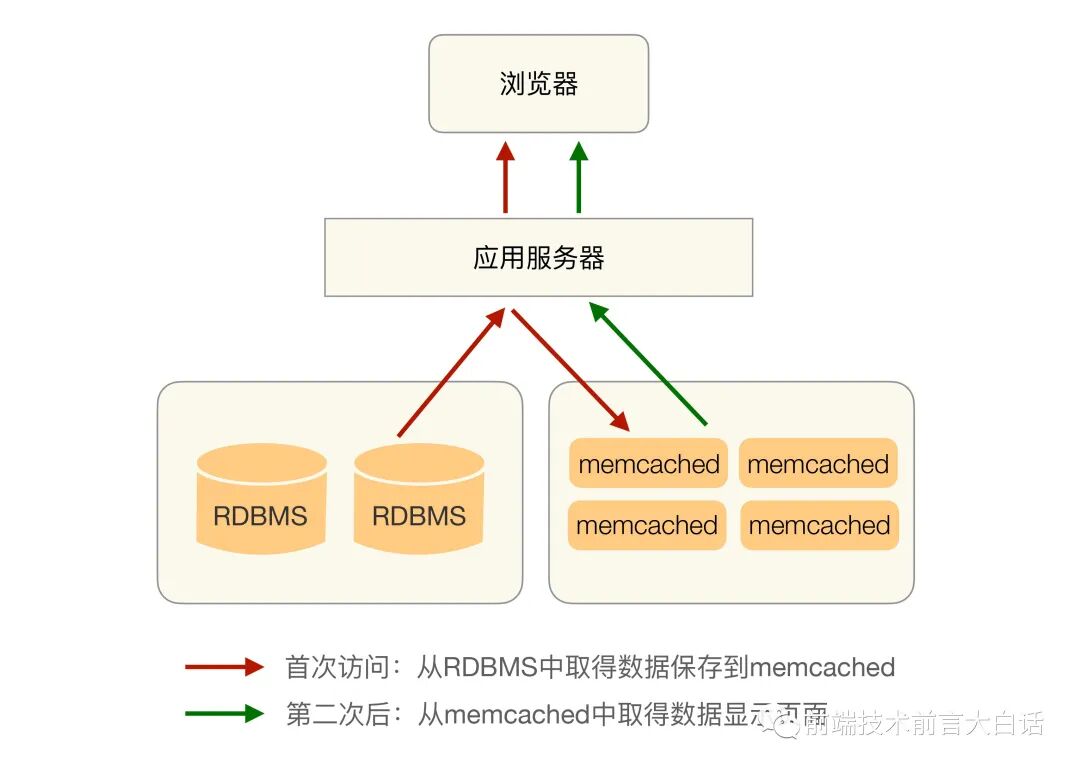
但是,缓存真的这么完美吗?它为系统引入高性能的同时,也带来了额外的架构复杂性。如果在设计时没有妥善处理这些复杂性,在某些极端情况下,缓存甚至会成为系统崩溃的导火索。接下来,我们就深入探讨缓存架构设计中的三大核心挑战及其应对策略。
缓存穿透:当缓存“形同虚设”
缓存穿透是指业务系统查询数据时,缓存中没有命中,导致请求直接穿透到存储系统的现象。这通常发生在以下两种情况:
-
查询的数据根本不存在
这是最常见的情况。如果存储系统(如 MySQL)中没有某条数据,那么缓存中自然也不会存在。这导致用户的每次查询,都会绕过缓存直接访问数据库,然后返回空结果。缓存在这里完全没起到分担压力的作用。
业务正常运行时,查询不存在数据的请求量通常不大。但如果遭遇恶意攻击,黑客故意大量发起针对不存在数据的查询,就可能导致数据库被直接拖垮。
-
生成缓存数据成本高昂
另一种情况是数据本身存在,但生成缓存数据需要耗费大量时间或计算资源。如果在业务访问的高峰期,这份缓存恰好过期失效,那么所有请求都会涌向数据库去重新生成缓存,瞬间给存储系统带来巨大压力。
一个典型的例子是电商网站的商品分页列表。由于数据量巨大,我们无法缓存所有数据,通常只会缓存用户最常访问的前几页。缓存有效期可能设置为1天,以保证数据的相对时效性。
问题在于,如果遭遇竞争对手的爬虫程序,它会遍历所有分类的所有分页。当爬虫访问到那些很少被用户点击、缓存已经失效的深分页(例如第100页)时,每个请求都会触发数据库执行 ORDER BY ... LIMIT ... OFFSET ... 这类高成本操作来重新生成缓存。大量此类请求并发,极易导致数据库性能急剧下降。
对于爬虫引发的这类问题,并没有一劳永逸的解决方案。因为爬虫的访问模式(遍历所有数据)和频率是不确定的。常见的应对思路有两种:一是识别并拦截爬虫,但这可能影响正常的搜索引擎抓取(SEO);二是加强系统监控,在发现异常访问模式导致性能下降时及时介入处理,因为爬虫通常不是瞬时暴力攻击,而是持续性的,给运维留下了响应时间。
缓存雪崩:当失效引发“连锁灾难”
缓存雪崩指的是在某一时刻,大量缓存同时失效,导致所有请求瞬间涌向数据库,引发系统性能急剧下降甚至崩溃的灾难性场景。
想象一下:一个高并发系统,某份关键缓存在毫秒级内过期。此时,成百上千的请求同时到达,它们发现缓存为空,于是都认为自己应该去数据库查询并重建缓存。这会导致数据库在同一时刻承受远超其处理能力的请求,进而可能引发宕机。数据库的宕机又会导致所有依赖它的服务线程阻塞,整个系统就像雪崩一样层层崩溃。
如何防止雪崩?这里有两种核心策略:
1. 更新锁机制
核心思想是对缓存重建过程加锁,确保同一时间只有一个线程(或进程)去数据库拉取数据并更新缓存。其他未能获取锁的线程可以选择等待,或者直接返回一个默认值/空值,避免对数据库造成冲击。
在单机环境下,使用本地锁(如Java的 synchronized 或 ReentrantLock)即可。但在 分布式系统 中,我们必须使用分布式锁(例如基于 ZooKeeper 或 Redis 实现)来协调集群中所有服务器上的线程。
2. 后台更新机制
这是一个更优雅的方案:缓存的有效期设置为“永久”,而数据的更新工作交由一个独立的后台线程/任务来定时执行。业务线程只负责读取缓存,永远不负责更新它。
这种方式完美避开了缓存失效瞬间的并发冲突问题,既适用于单机多线程,也天然适应分布式集群环境。它还有一个额外优势:非常适合系统上线时的缓存预热——提前将热点数据加载到缓存中,而不是等待用户访问才触发冷启动。
不过,后台更新机制需要注意一个边界情况:当缓存系统(如 Redis)内存不足时,会基于某种策略(如LRU)清理掉一部分数据。从数据被清理到下次后台更新触发的这段时间内,业务读取将得到空值。有两种方法可以缓解:
- 后台线程主动巡检:后台更新线程不仅定时写,还高频(如每秒)读取缓存。一旦发现数据被“踢出”,立即触发更新。这种方式简单,但巡检间隔设置太大会导致空窗期较长。
- 业务线程被动通知:业务线程读取缓存发现数据不存在时,发送一条消息到消息队列(如
Kafka)。后台线程消费消息并更新缓存。这种方式更及时,用户体验更好,但架构复杂度更高,引入了消息队列的依赖。
缓存热点:当焦点成为“性能单点”
即使缓存服务器本身性能强悍,但如果业务请求过分集中在某一份特定的缓存数据上,也会导致该缓存实例成为瓶颈。例如,某顶流明星发布一条官宣微博,瞬间可能有数千万请求涌向同一个缓存 Key。
解决方案是 数据副本分流。为这份热点数据创建多个副本,每个副本拥有不同的 Key(例如在原Key后加上随机编号),并将这些副本分散到不同的缓存服务器上。每次读取时,客户端随机选取一个副本 Key 进行访问,从而将压力分散到多台机器。
这里有一个至关重要的细节:切勿为所有副本设置相同的过期时间。否则所有副本将在同一时刻失效,引发小范围的缓存雪崩。正确的做法是为缓存过期时间设定一个范围(如5-10分钟),每个副本的过期时间在这个范围内随机取值。
写在最后
缓存的设计策略与存储系统的访问模式紧密相关。上述的穿透、雪崩、热点等解决方案,通常会被集成在存储访问层中实现,可以是嵌入业务代码的“客户端模式”,也可以是独立的中间件(如 Redis 的各种客户端 SDK 已经内置了许多最佳实践)。
深入理解这些缓存挑战与模式,是构建高可用、高性能 缓存架构 的基础。希望本文的梳理能为你带来启发。如果你想了解更多关于系统设计、高可用的深度讨论,欢迎来到 云栈社区 与更多开发者交流切磋。
 发表于 2026-2-8 09:03:42
|
查看: 241|
回复: 0
发表于 2026-2-8 09:03:42
|
查看: 241|
回复: 0
