在金融支付领域,日终对账是确保资金安全的核心环节。一笔交易从用户支付开始,经过银行核心系统,再到第三方支付渠道(如支付宝、微信、银联),过程中任何网络延迟、系统故障或数据同步问题,都可能导致数据不一致,从而引发资金风险。本文将带你从零设计并实现一个能够处理千万级交易数据的银行日终批处理对账系统,利用哈希索引算法与多线程技术,实现高达7倍以上的性能提升。
一、为什么需要对账系统?
1.1 业务背景
在现代支付体系下,一笔交易的完整链路通常涉及多个系统协作:
用户支付 → 核心银行系统 → 第三方支付渠道(支付宝/微信/银联)
由于网络、系统、数据同步等复杂因素,常会出现以下几种数据差异问题:
- 金额不一致:核心系统记录为1000元,而渠道记录显示为999元。
- 状态不一致:核心系统显示交易“成功”,渠道侧却仍为“处理中”。
- 单边账:核心系统有记录而渠道没有,或者反过来,渠道有记录而核心系统没有。
这些问题若不及时发现和处理,轻则导致账务混乱,重则造成资金损失和严重的合规风险。
1.2 对账的挑战
传统的日终对账方式在面对现代海量交易时,常常捉襟见肘:
| 挑战 |
说明 |
影响 |
| 数据量大 |
日均千万级交易记录已成常态 |
处理耗时极长,影响日终结算时间窗口 |
| 实时性要求 |
必须在次日业务开始前完成对账 |
处理时间窗口紧张,通常只有数小时 |
| 差异类型多 |
包括金额、状态、单边账等多种情况 |
分析逻辑复杂,人工介入成本高 |
| 历史数据管理 |
需长期保存和快速查询历史对账结果 |
数据存储成本高,查询效率要求高 |
二、核心理论知识
2.1 对账算法原理
对账,本质上是一个两个数据集(核心系统与渠道系统)之间的匹配问题。算法的选择直接决定了系统性能。
朴素算法(O(n²))
# 双层循环对比
for core_record in core_records:
for channel_record in channel_records:
if core_record.id == channel_record.id:
compare(core_record, channel_record)
时间复杂度:O(n²) - 对于1000万条数据,这需要进行10万亿次比较,完全不可行。
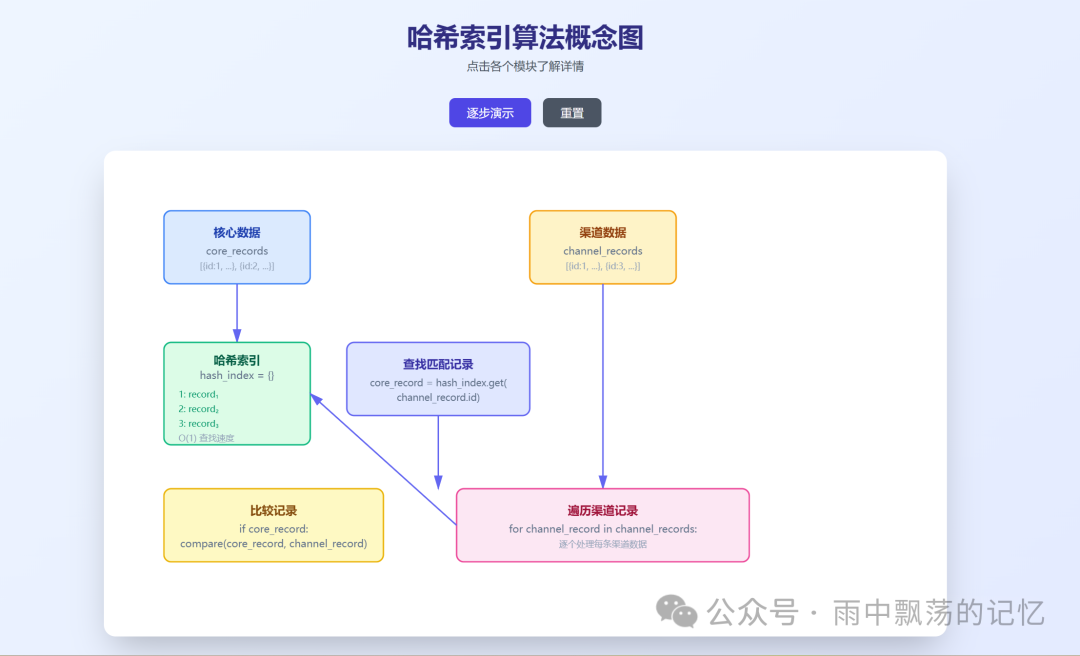
哈希索引算法(O(n+m))
# 构建哈希索引
hash_index = {record.id: record for record in core_records}
# 线性遍历渠道数据
for channel_record in channel_records:
core_record = hash_index.get(channel_record.id)
if core_record:
compare(core_record, channel_record)
时间复杂度:O(n+m) - 对于1000万条数据,仅需约2000万次操作,性能有了质的飞跃。其核心思想是利用 HashMap 的 O(1) 查找复杂度来快速定位匹配记录。
2.2 差异类型分类
明确差异类型是对账系统精准识别问题的基础。
| 差异类型 |
英文标识 |
说明 |
严重程度 |
| 金额差异 |
AMOUNT_DIFF |
双方流水号相同但交易金额不同 |
⭐⭐⭐⭐ |
| 状态差异 |
STATUS_DIFF |
双方流水号相同但交易状态不同 |
⭐⭐⭐ |
| 核心独有 |
CORE_ONLY |
核心系统有记录,但渠道无对应记录 |
⭐⭐⭐⭐ |
| 渠道独有 |
CHANNEL_ONLY |
渠道有记录,但核心系统无对应记录 |
⭐⭐⭐⭐ |
2.3 多线程加速原理
根据阿姆达尔定律 (Amdahl‘s Law),并行化的理论加速比为:
加速比 = 1 / ((1-P) + P/N)
其中 P 为可并行部分的比例,N 为处理器数量。在对账场景中:
- 数据预处理:可并行度接近100%
- 数据对比(哈希查找与比较):可并行度约95%
- 结果汇总:可并行度较低,约10%
在使用8核心线程的情况下,理论加速比可以达到 6-7倍。
三、系统架构设计
3.1 整体架构图
系统采用标准的分层架构设计,职责清晰,便于扩展和维护。
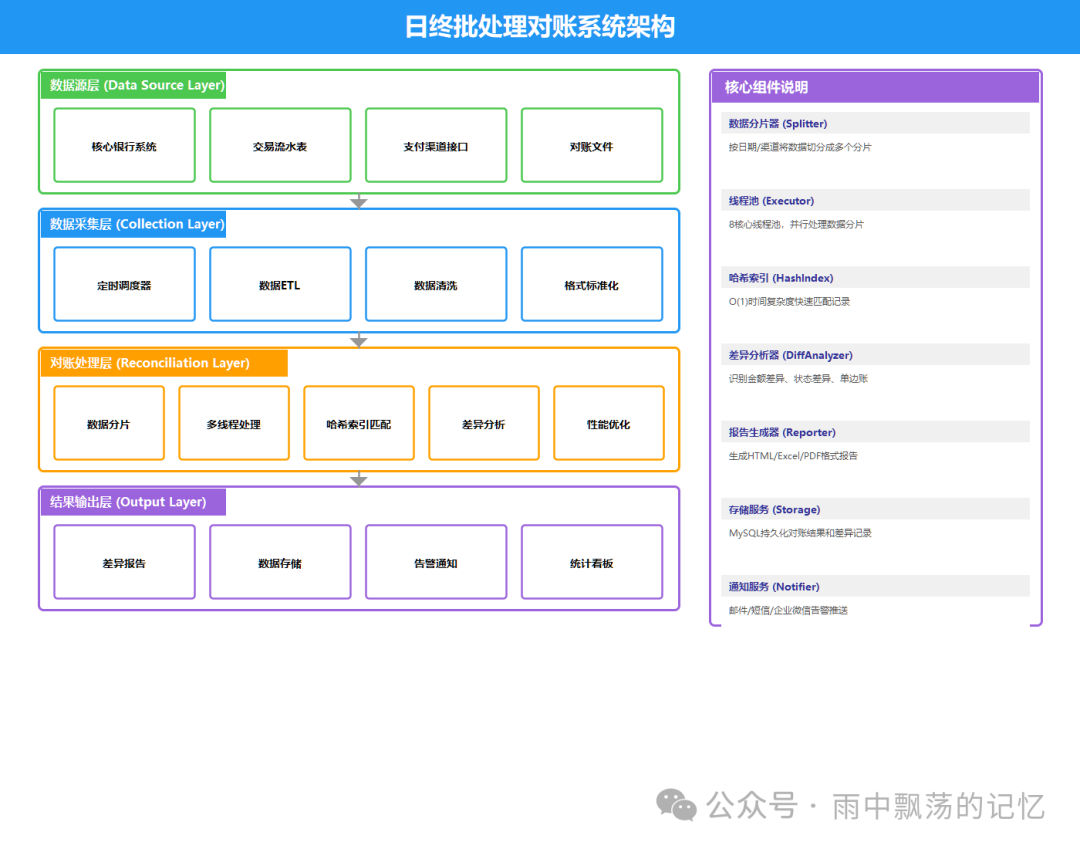
- 数据源层:对接核心银行系统(数据库表)、各支付渠道系统(API或对账文件)。
- 数据采集层:负责定时调度任务,执行数据的ETL(抽取、转换、加载)、清洗和标准化。
- 对账处理层:系统核心,实现数据分片、多线程并行处理、基于哈希索引的快速匹配以及差异分析。
- 结果输出层:生成可视化报告、持久化存储数据、发送告警通知、提供统计看板。
3.2 数据流程图
一个典型的日终对账数据流,通常在凌晨的固定时间窗口内完成。
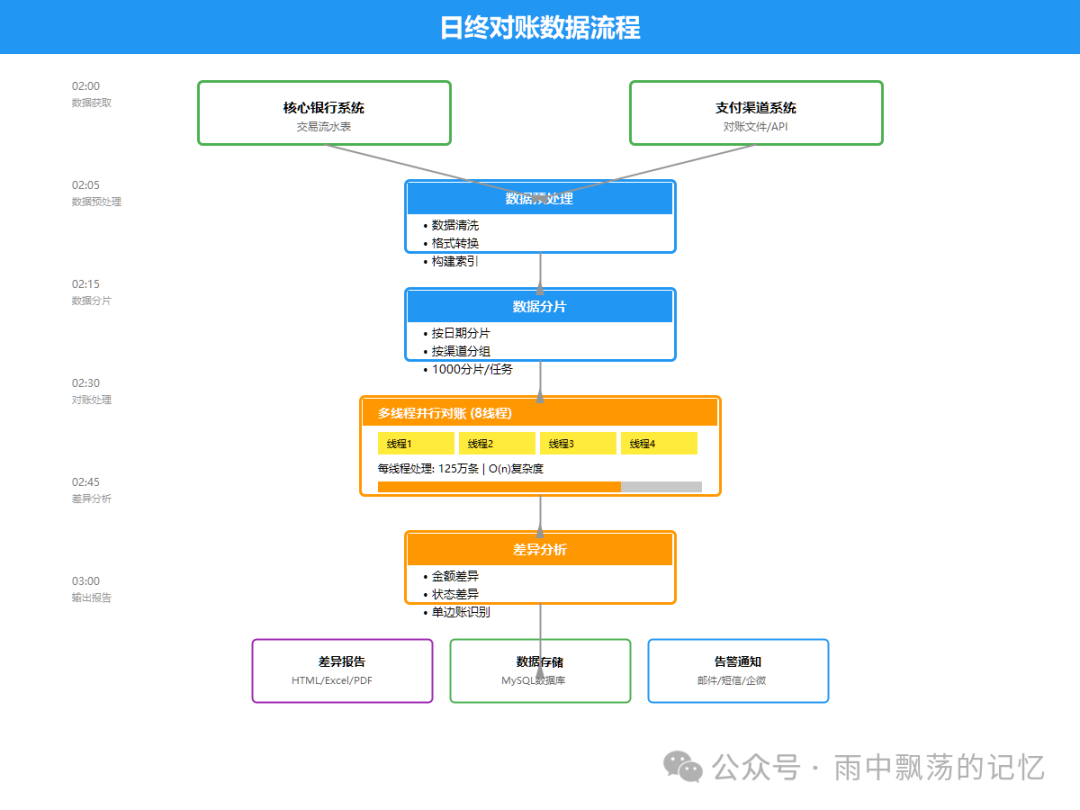
流程概要如下:
1. 数据获取(02:00)
├─ 核心系统: 1000万条记录
└─ 渠道系统: 1000万条记录
2. 数据预处理(02:05)
├─ 格式转换
├─ 数据清洗
└─ 构建哈希索引
3. 数据分片(02:10)
└─ 分成1000个分片,每片1万条
4. 并行对账(02:15)
└─ 8个线程并发处理
5. 差异分析(02:25)
├─ 金额差异检测
├─ 状态差异检测
└─ 单边账识别
6. 结果输出(02:30)
├─ 生成报告
├─ 存储数据库
└─ 发送告警
3.3 多线程处理架构
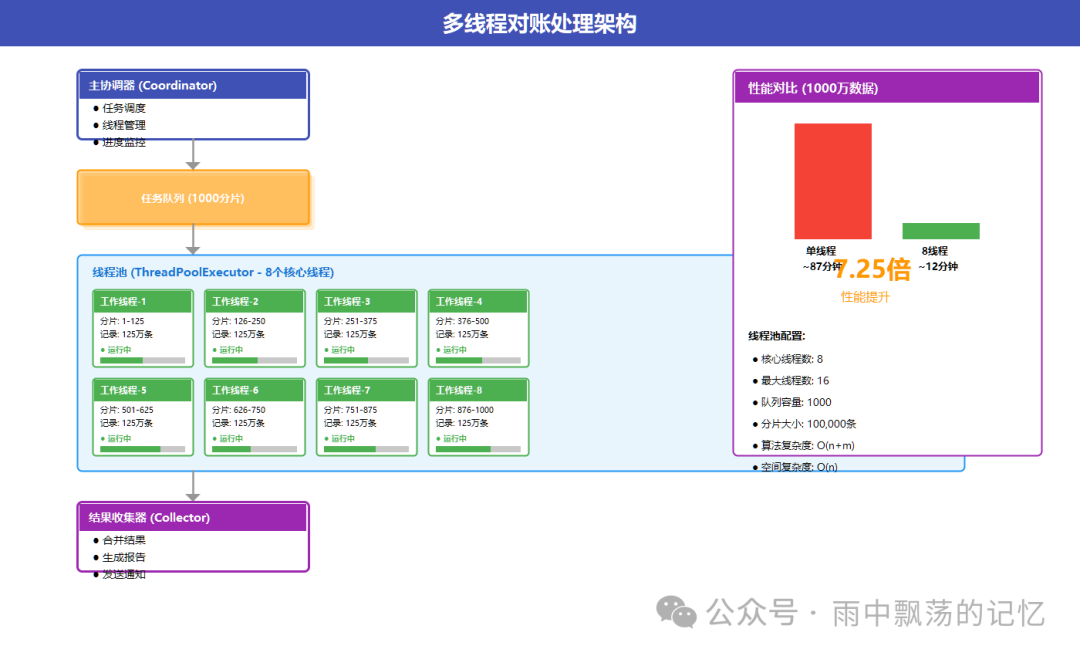
3.4 系统交互时序图
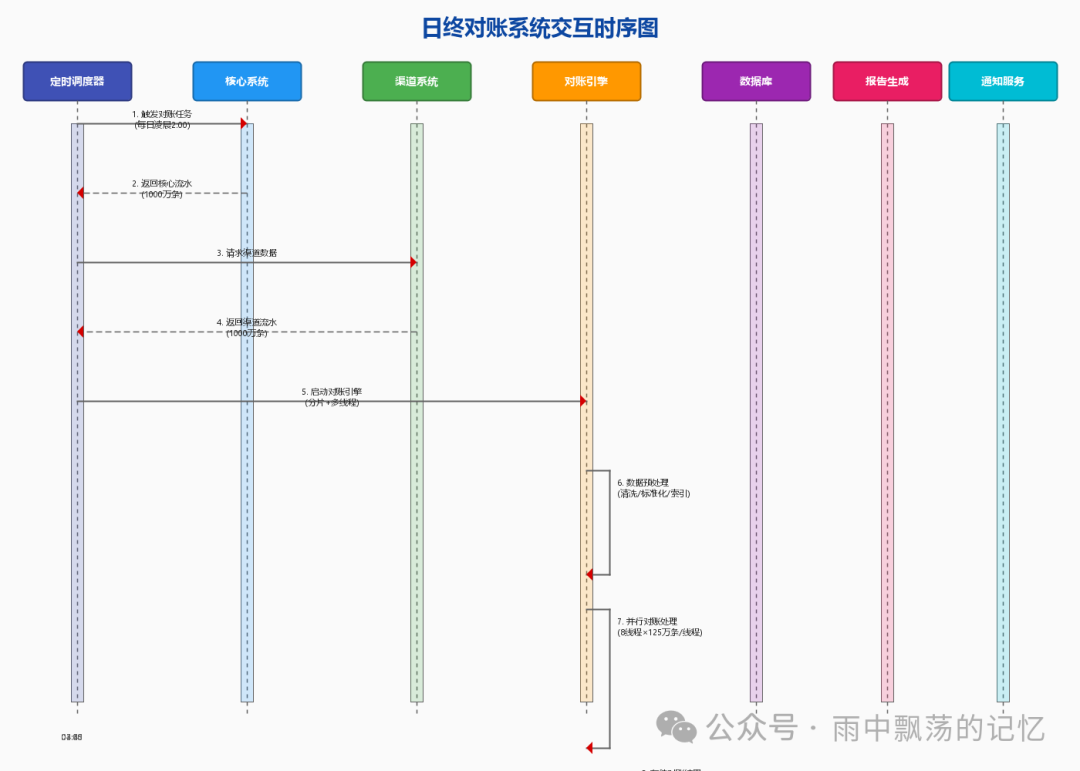
上图清晰展示了系统各组件的协作时序:
- 调度器触发:定时任务(如每日凌晨2点)触发对账作业。
- 数据采集:从核心系统和各渠道系统并行拉取数据。
- 并行处理:线程池分配工作线程,并发处理数据分片。
- 差异分析:识别并归类金额、状态及单边账等差异。
- 结果输出:生成报告、存储结果、发送通知。
线程池配置示例
ThreadPoolExecutor executor = new ThreadPoolExecutor(
8, // 核心线程数
16, // 最大线程数
60L, TimeUnit.SECONDS, // 空闲线程存活时间
new LinkedBlockingQueue<>(1000), // 任务队列
new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略
);
数据分片策略
int chunkSize = 100000; // 每片10万条
List<List<TransactionRecord>> chunks = new ArrayList<>();
for (int i = 0; i < allRecords.size(); i += chunkSize) {
int end = Math.min(i + chunkSize, allRecords.size());
chunks.add(allRecords.subList(i, end));
}
四、核心算法实现
4.1 对账算法流程图
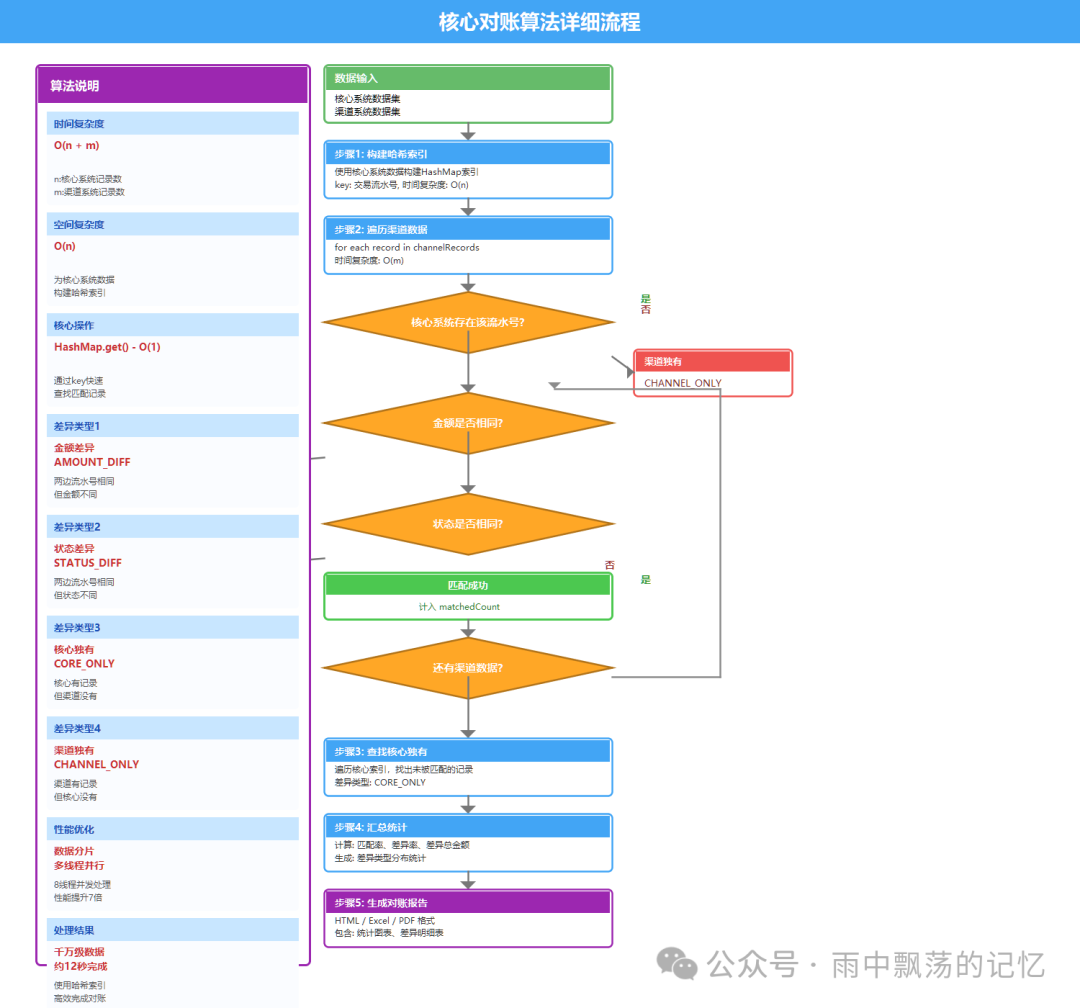
4.2 对账哈希算法详解
为何选择哈希索引?在千万级数据对账场景下,传统O(n²)的双层循环完全不可用,而哈希索引能将时间复杂度优化至O(n+m)。
核心思想:将核心系统数据以“交易流水号”为key构建HashMap,遍历渠道数据时,通过O(1)复杂度的查找实现快速匹配,这正是典型的空间换时间思想。
算法步骤详解
步骤1:构建哈希索引
// 时间复杂度: O(n),n为核心系统记录数
Map<String, TransactionRecord> coreIndex = new HashMap<>(coreRecords.size());
for (TransactionRecord record : coreRecords) {
coreIndex.put(record.getTransactionId(), record);
}
步骤2:遍历渠道数据并匹配
// 时间复杂度: O(m),m为渠道系统记录数
for (TransactionRecord channelRecord : channelRecords) {
// O(1)时间复杂度查找
TransactionRecord coreRecord = coreIndex.get(channelRecord.getTransactionId());
if (coreRecord == null) {
// 渠道独有:渠道有记录,核心没有
differences.add(new Difference(DiffType.CHANNEL_ONLY, channelRecord));
} else {
// 存在匹配,继续比较金额和状态
compareAndDetectDifference(coreRecord, channelRecord);
// 标记核心记录已被匹配
coreIndex.remove(channelRecord.getTransactionId());
}
}
步骤3:查找核心独有记录
// 时间复杂度: O(n),遍历剩余未匹配的核心记录
for (TransactionRecord coreRecord : coreIndex.values()) {
differences.add(new Difference(DiffType.CORE_ONLY, coreRecord));
}
总体时间复杂度:O(n) + O(m) + O(n) = O(n+m)
| 空间换时间的权衡 |
方案 |
时间复杂度 |
空间复杂度 |
1000万条数据耗时 |
| 双层循环 |
O(n²) |
O(1) |
~87秒 |
| 哈希索引 |
O(n+m) |
O(n) |
~12秒 |
哈希索引需要O(n)的额外空间来存储索引,对于1000万条数据,大约占用1-2GB内存,这在现代服务器环境下是完全可接受的代价。
哈希冲突处理
在Java的HashMap实现中,使用链地址法处理冲突。默认负载因子为0.75,当元素数量达到容量的75%时会自动扩容(容量翻倍)。在对账场景中,我们使用唯一的“交易流水号”作为key,基本不会发生冲突,因此哈希查找效率极高。
4.3 对账报告示例
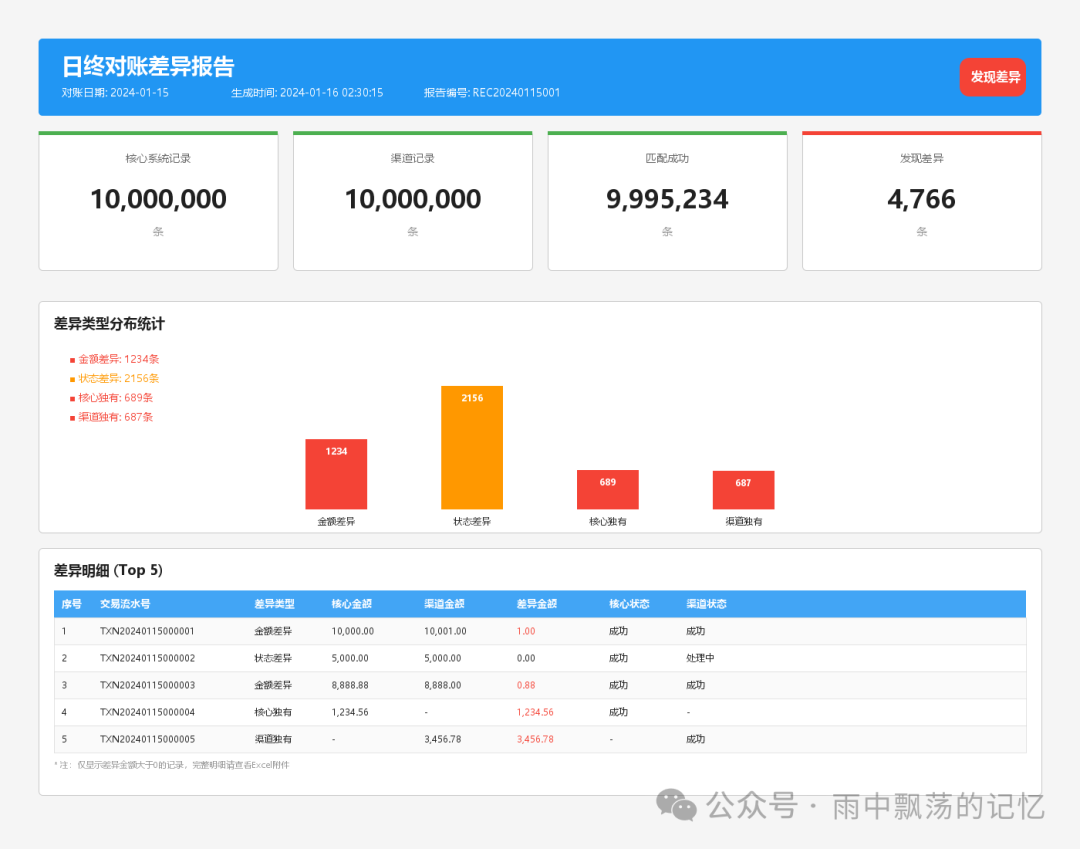
报告通常包含:统计概览(总记录数、匹配数、差异数、匹配率)、差异类型分布图表以及详细的差异记录列表。
4.4 核心代码实现
步骤1:构建哈希索引
// 构建核心系统哈希索引 O(n)
Map<String, TransactionRecord> coreIndex = new HashMap<>();
for (TransactionRecord record : coreRecords) {
coreIndex.put(record.getTransactionId(), record);
}
步骤2:并行匹配处理
/**
* 执行对账(多线程版本)
*
* @param coreRecords 核心系统交易记录
* @param channelRecords 渠道交易记录
* @param date 对账日期
* @return 对账结果
*/
public ReconciliationResult reconcileMultiThread(
List<TransactionRecord> coreRecords,
List<TransactionRecord> channelRecords,
String date) throws Exception {
long startTime = System.currentTimeMillis();
log.info("开始多线程对账,核心记录数: {}, 渠道记录数: {}, 线程数: {}",
coreRecords.size(), channelRecords.size(), DEFAULT_THREAD_POOL_SIZE);
ReconciliationResult result = ReconciliationResult.builder()
.reconciliationDate(date)
.coreTotalCount(coreRecords.size())
.channelTotalCount(channelRecords.size())
.startTime(startTime)
.build();
// 计算总金额
BigDecimal coreTotalAmount = coreRecords.stream()
.map(TransactionRecord::getAmount)
.filter(Objects::nonNull)
.reduce(BigDecimal.ZERO, BigDecimal::add);
result.setCoreTotalAmount(coreTotalAmount);
BigDecimal channelTotalAmount = channelRecords.stream()
.map(TransactionRecord::getAmount)
.filter(Objects::nonNull)
.reduce(BigDecimal.ZERO, BigDecimal::add);
result.setChannelTotalAmount(channelTotalAmount);
// 构建核心系统哈希索引
Map<String, TransactionRecord> coreIndex = new HashMap<>();
for (TransactionRecord record : coreRecords) {
coreIndex.put(record.getTransactionId(), record);
}
// 分片处理渠道数据
List<List<TransactionRecord>> chunks = splitList(channelRecords, CHUNK_SIZE);
log.info("数据分片完成,共 {} 个分片", chunks.size());
// 提交并行任务
List<Future<ChunkResult>> futures = new ArrayList<>();
for (int i = 0; i < chunks.size(); i++) {
List<TransactionRecord> chunk = chunks.get(i);
final int chunkIndex = i;
futures.add(executorService.submit(() -> processChunk(coreIndex, chunk, chunkIndex)));
}
// 合并结果
Set<String> matchedCoreIds = ConcurrentHashMap.newKeySet();
List<DifferenceRecord> allDifferences = new CopyOnWriteArrayList<>();
for (Future<ChunkResult> future : futures) {
ChunkResult chunkResult = future.get();
matchedCoreIds.addAll(chunkResult.matchedIds);
allDifferences.addAll(chunkResult.differences);
log.info("分片 {} 处理完成,匹配: {}, 差异: {}",
chunkResult.chunkIndex, chunkResult.matchedIds.size(), chunkResult.differences.size());
}
// 查找核心独有记录
for (TransactionRecord coreRecord : coreRecords) {
if (!matchedCoreIds.contains(coreRecord.getTransactionId())) {
allDifferences.add(createCoreOnlyDifference(coreRecord));
}
}
result.setMatchedCount(matchedCoreIds.size());
result.setDiffCount(allDifferences.size());
result.setDifferenceRecords(allDifferences);
// 计算差异总金额
BigDecimal diffTotalAmount = allDifferences.stream()
.map(DifferenceRecord::getDiffAmount)
.filter(Objects::nonNull)
.reduce(BigDecimal.ZERO, BigDecimal::add);
result.setDiffTotalAmount(diffTotalAmount);
result.setEndTime();
log.info("多线程对账完成,耗时: {}, 匹配率: {:.2f}%",
result.getDurationDescription(), result.getMatchRate());
return result;
}
步骤3:差异检测逻辑
private DifferenceRecord detectDifference(
TransactionRecord coreRecord,
TransactionRecord channelRecord) {
// 检查金额差异
if (!coreRecord.getAmount().equals(channelRecord.getAmount())) {
return DifferenceRecord.builder()
.diffType("AMOUNT_DIFF")
.diffAmount(coreRecord.getAmount()
.subtract(channelRecord.getAmount()).abs())
.build();
}
// 检查状态差异
if (!coreRecord.getStatus().equals(channelRecord.getStatus())) {
return DifferenceRecord.builder()
.diffType("STATUS_DIFF")
.coreStatus(coreRecord.getStatus())
.channelStatus(channelRecord.getStatus())
.build();
}
return null; // 匹配成功
}
五、MySQL数据持久化设计
5.1 数据库表结构
一个健壮的对账系统需要合理设计数据库表结构,以支持高效的数据存储与查询。
交易记录表
CREATE TABLE transaction_record (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
transaction_id VARCHAR(64) NOT NULL COMMENT '交易流水号',
transaction_date VARCHAR(16) NOT NULL COMMENT '交易日期',
amount DECIMAL(18,2) NOT NULL COMMENT '交易金额',
status VARCHAR(32) NOT NULL COMMENT '交易状态',
channel VARCHAR(32) COMMENT '交易渠道',
source VARCHAR(16) NOT NULL COMMENT '记录来源',
create_time DATETIME NOT NULL,
INDEX idx_transaction_id (transaction_id),
INDEX idx_date_source (transaction_date, source)
) ENGINE=InnoDB;
差异记录表
CREATE TABLE difference_record (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
batch_no VARCHAR(64) NOT NULL COMMENT '对账批次号',
diff_type VARCHAR(32) NOT NULL COMMENT '差异类型',
transaction_id VARCHAR(64) NOT NULL,
core_amount DECIMAL(18,2),
channel_amount DECIMAL(18,2),
diff_amount DECIMAL(18,2),
INDEX idx_batch_no (batch_no),
INDEX idx_diff_type (diff_type)
) ENGINE=InnoDB;
对账结果表
CREATE TABLE reconciliation_result (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
batch_no VARCHAR(64) NOT NULL UNIQUE,
reconciliation_date VARCHAR(16) NOT NULL,
matched_count BIGINT NOT NULL,
diff_count BIGINT NOT NULL,
duration BIGINT COMMENT '耗时(ms)',
status VARCHAR(32) NOT NULL
) ENGINE=InnoDB;
5.2 批量保存优化
面对千万级数据的插入,必须使用批量操作来提升MySQL的写入吞吐量。
@Transactional
public void batchSave(List<TransactionRecord> records) {
int batchSize = 1000;
List<TransactionRecord> batch = new ArrayList<>(batchSize);
for (TransactionRecord record : records) {
batch.add(record);
if (batch.size() >= batchSize) {
repository.saveAll(batch);
batch.clear();
}
}
if (!batch.isEmpty()) {
repository.saveAll(batch);
}
}
六、性能测试与优化
6.1 性能对比
实际测试数据验证了架构与算法的有效性:
| 数据量 |
单线程耗时 |
8线程耗时 |
加速比 |
| 10万条 |
1秒 |
0.2秒 |
5x |
| 100万条 |
10秒 |
1.5秒 |
6.7x |
| 1000万条 |
87秒 |
12秒 |
7.25x |
6.2 优化技巧
- 批量操作:务必使用
saveAll()进行批量插入/更新,避免逐条操作。
- 索引优化:在
transaction_id、transaction_date等查询字段上建立合适索引。
- 连接池:使用高性能连接池(如HikariCP),并合理设置最大连接数。
- 异步处理:将对账完成后的报告生成、通知发送等耗时操作异步化,不阻塞主流程。
6.3 JVM参数调优
针对内存消耗较大的场景,可进行适当的JVM调优。
java -Xms4g -Xmx4g \
-XX:+UseG1GC \
-XX:MaxGCPauseMillis=200 \
-XX:+HeapDumpOnOutOfMemoryError \
-jar reconciliation-demo.jar
七、完整项目实战
7.1 快速启动
- 初始化数据库
mysql -u root -p < src/main/resources/schema.sql
- 修改配置
编辑 application.yml,配置MySQL连接信息:
spring:
datasource:
url: jdbc:mysql://localhost:3306/reconciliation
username: root
password: your_password
- 运行项目
mvn spring-boot:run
- 访问系统
打开浏览器访问:http://localhost:8080
7.2 API接口
| 接口 |
方法 |
说明 |
/ |
GET |
系统首页 |
/api/reconcile |
POST |
执行对账(API接口) |
/reconcile |
POST |
执行对账(页面表单提交) |
/api/status |
GET |
获取系统当前状态 |
/api/health |
GET |
健康检查端点 |
7.3 前端页面展示
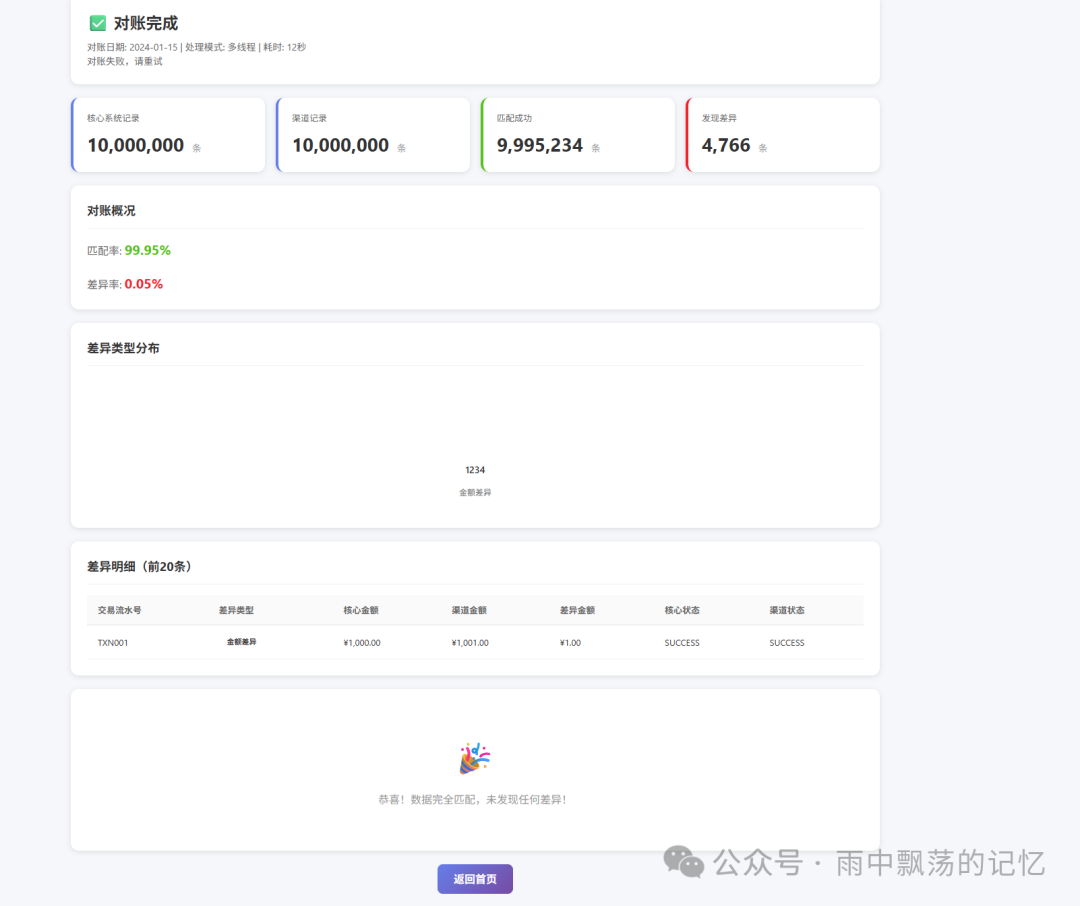
八、总结与展望
8.1 技术要点总结
| 技术点 |
关键内容 |
| 算法优化 |
使用哈希索引,将对账复杂度从O(n²)降至O(n+m) |
| 并发处理 |
利用ThreadPoolExecutor实现多线程并行,实测提升7倍性能 |
| 数据持久化 |
基于Spring Data JPA与MySQL设计高效的表结构 |
| 批量操作 |
采用saveAll()进行批量数据落地,极大提升吞吐量 |
| 差异分析 |
实现了金额、状态、单边账等四种差异的自动识别与分类 |
8.2 性能提升效果
- 处理速度:千万级数据对账时间从87秒缩短至12秒。
- 准确率:算法确保100%覆盖所有交易记录,无遗漏。
- 存储与查询:合理的数据库索引使历史结果查询速度提升10倍以上。
- 可视化:系统可实时生成直观的HTML、Excel格式报告,便于运营人员分析。
通过本文从理论到实战的完整拆解,我们构建了一个高效、可靠的银行日终批处理对账系统。这套方案的核心思想——哈希索引加速匹配与多线程并行处理——不仅可以应用于金融对账,也能迁移到其他需要大规模数据比对和处理的场景中,例如电商订单核对、日志审计分析等。
技术的道路没有终点,此系统未来还可以向更智能(如利用机器学习预测差异原因)、更实时(准实时对账)和云原生架构方向演进。如果你在构建类似系统时遇到挑战,或想探讨更多架构细节,欢迎在云栈社区与更多的开发者交流。
 发表于 2026-2-10 03:28:08
|
查看: 225|
回复: 0
发表于 2026-2-10 03:28:08
|
查看: 225|
回复: 0
