
对于服务器运维人员来说,CPU、内存、硬盘这“三大件”的健康状况直接关系到业务的稳定性。特别是内存,近期DDR4即将停产的消息也引发了市场的波动,这从侧面印证了DDR对于服务器有多么重要。今天我们就来聊聊,如何通过服务器自带的“管家”——BMC(基板管理控制器)来对DDR内存进行故障预测,提前发现问题,避免业务中断。
双倍数据速率同步动态随机存取存储器(DDR SDRAM)自2000年诞生以来,已经迭代了五个主要世代:DDR、DDR2、DDR3、DDR4和DDR5。当前数据中心以DDR4和DDR5为主流,它们在架构与可靠性设计上差异显著。
- DDR1 (2000年):开创了在时钟上升沿与下降沿均传输数据的“双倍数据速率”模式,核心电压2.5V,速率最高400MT/s。单条最大容量仅2GB,多用于早期设备。
- DDR2 (2003年):引入4位预取架构,电压降至1.8V,最高速率达800MT/s,功耗得到改善,曾是消费电子的主流。
- DDR3 (2007年):采用8位预取,电压降至1.5V(后期有1.35V低电压版),速率最高至2133MT/s,并集成了温度传感器,是服役时间最长的一代。
- DDR4 (2014年):电压降至1.2V,采用点对点总线设计,速率突破3200MT/s,引入了Bank Group提升效率,并可选片上ECC纠错功能,是目前服务器的主流选择。
- DDR5 (2020年):采用双独立32/40位通道设计,电压1.1V,速率起步4800MT/s,最高可达8400MT/s以上,标配片上ECC,单条容量最大可达128GB,专为AI计算、高端数据中心等高性能场景设计。
了解代际差异后,我们来看看DDR的运行状态由哪些核心参数决定。这些参数不仅是衡量性能的标尺,更是监测其健康状态的“生命体征”,主要可分为以下三类。
1. 电气参数
- 工作电压(VDD/VPP):DDR4标准电压1.2V,DDR5为1.1V。电压的稳定性直接关系到信号完整性和误码率。
- 温度(Tcase/Tjunction):内存结温通常需要控制在85°C以下,高温会加速电荷泄漏和时序劣化。
- 信号完整性指标:包括眼图高度、抖动(Jitter)、占空比失真等,它们反映了物理层信号传输的实际质量。
2. 时序参数
- CAS延迟(CL):列地址选通延迟,即从发送列地址到数据准备就绪所需的时钟周期数。
- 刷新间隔(tREFI):DRAM存储单元需要定期刷新以维持数据,标准刷新间隔为7.8μs(常温下)。
- 行激活时间(tRAS)与行预充电时间(tRP):这两个参数是决定内存行操作效率的关键时序。
3. 健康监测参数
- 可纠正错误率(CE):指单位时间内ECC(纠错码)成功修复的单比特错误数量。CE计数是预测严重故障的前兆性关键指标。
- 不可纠正错误率(UE):指多比特错误或其他超出ECC纠错能力的故障事件,通常会导致系统宕机或数据损坏。
- 误码率(BER):通常要求控制在10^-15至10^-18量级,是衡量内存可靠性的终极指标。
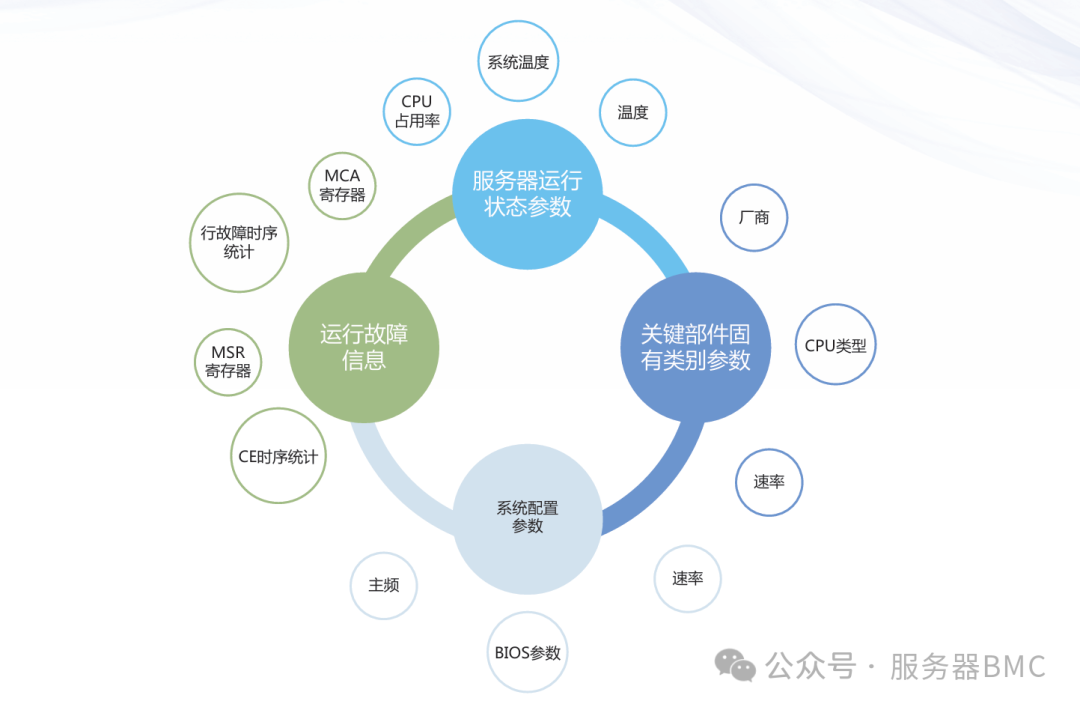
这些参数的异常波动,就是DDR内存即将“生病”发出的警报。不同的偏离模式对应着不同类型的问题,我们可以通过特征数据来精准识别。
电气参数异常:以DDR4为例,工作电压偏离标准值±3%(即低于1.164V或高于1.236V)即属异常,可能引发初始化失败、数据校验错误,表现为系统频繁蓝屏或无法启动。若供电纹波超过50mV,则会导致间歇性的数据传输错误。接触电阻若大于0.2Ω,则容易出现接触不良,表现为内存条被识别为低容量或干脆无法识别。
时序参数异常:如果CL、tRAS等时序数值超出SPD芯片的标定范围,或与主板预设值不匹配,会导致内存读写时序错乱,引发数据错位、读取失败,具体表现就是程序闪退或文件损坏。如果在运行中时序参数出现无规律的跳变,这通常是内存颗粒本身出现硬件损伤的信号,容易引发持续性的时序错误。
健康监测参数异常:这部分是故障预测的核心。CE计数如果在24小时内超过500次,就强烈预示着内存存在潜在故障,有很大概率会进一步演变为UE(不可纠正错误)。更需要注意的是,如果CE错误集中发生在某一个特定的Bank、行或列,形成了固定的错误模式,那么即使整体CE计数不高,也可能快速恶化为不可纠正的错误。通常,列故障的发生率更高,而行故障对系统稳定性的影响更大。此外,如果DDR的工作温度持续超过85℃,会显著加速颗粒老化,导致各类错误发生率呈指数级增长,经验表明温度每升高10℃,内存故障率大约会增加一倍。
BMC作为服务器硬件的监控与管理核心,其职责就是实时采集上述各项参数。通过对这些时序、电气及错误统计数据的持续分析与趋势判断,BMC可以实现对内存故障的早期预警。这本质上就是将运维中的预测性维护理念,通过硬件管理接口落到实处。近十年来,工业界和学术界在内存故障预测方向已有大量研究,国内很多系统厂商也早已投入实际应用。结合当前大数据与人工智能技术,在BMC固件中集成更智能的DDR故障预测算法,无疑是未来提升服务器运维可靠性与效率的重要发展方向。
本文由云栈社区技术内容编辑整理,旨在分享服务器硬件运维知识。文中涉及的技术参数与故障模式,可供运维工程师在实际工作中参考。 |  发表于 2026-2-10 05:30:44
|
查看: 229|
回复: 0
发表于 2026-2-10 05:30:44
|
查看: 229|
回复: 0
