在这个数字资源泛滥的时代,谁的硬盘里没有囤积几个TB的文档、电子书和项目文件?特别是技术人员,各种技术秘籍、编程思想、白皮书PDF塞满了存储空间。
我们热衷于“收藏”,却在急需查找某个具体函数说明或架构原理时,迷失在层层嵌套的文件夹中。最令人沮丧的情形莫过于:你清晰地记得自己下载过那份关键资料,但无论是系统搜索还是文件名匹配都无果,最终不得不再次求助于网络搜索引擎。
如果你已经厌倦了Windows资源管理器那令人心焦的搜索转圈,或是受够了NAS自带搜索工具缓慢的索引速度,那么今天介绍的这款小众利器——Sist2,或许正是你需要的解决方案。
为什么选择 Sist2?
大多数传统搜索工具仅停留在文件名匹配层面,而Sist2则深入文件内容。它是一个基于 C语言 编写、以 Elasticsearch 作为后端存储的高性能文件内容索引与检索引擎。简单来说,它能为你本地的海量文件库构建一个智能的“搜索引擎大脑”。
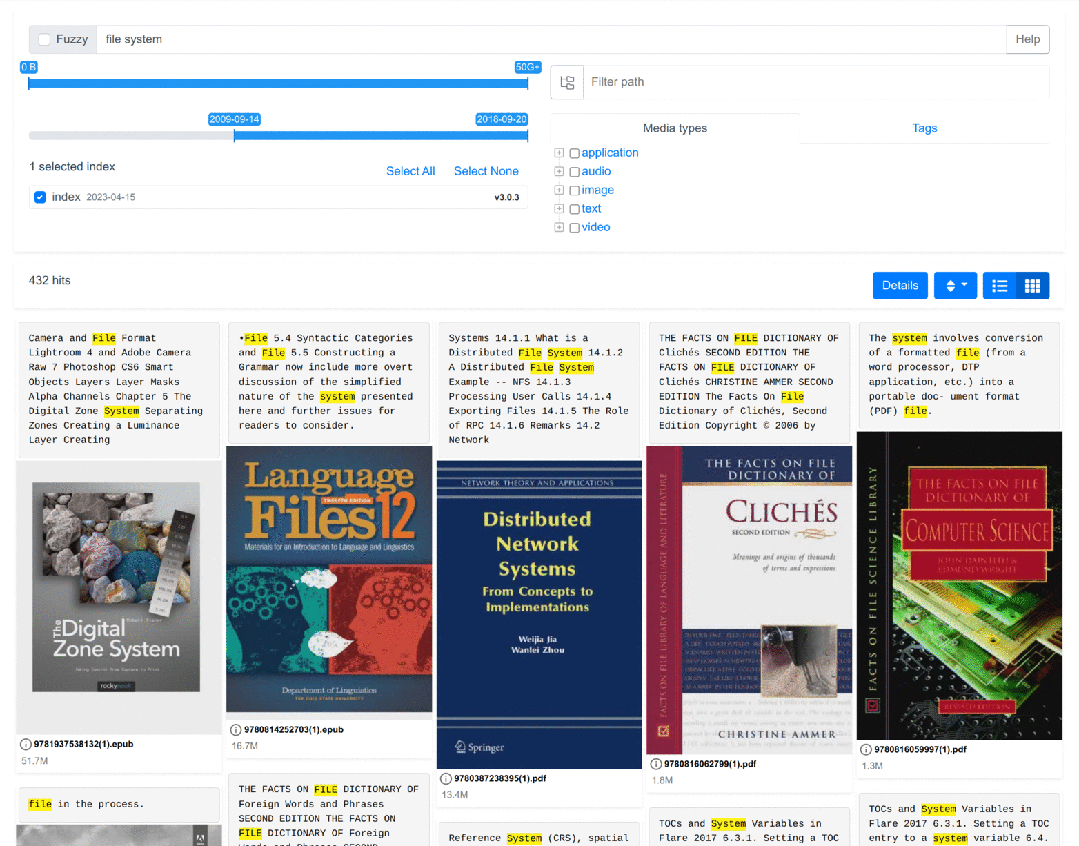
Sist2的Web搜索界面,支持按内容、类型、路径等多维度筛选。
核心优势解析
1. OCR集成,解锁图片与PDF内容搜索
这是Sist2的杀手级功能。它内置集成了 Tesseract OCR 引擎。这意味着,你扫描的纸质文档图片、或是无法直接复制文字的PDF文件,只要其中包含可识别的文字信息,Sist2就能通过关键词直接定位到它们。它不仅仅是在查找文件,而是在真正“阅读”并理解你文件的内容。
2. C语言带来的极致性能
相较于许多使用Python等高级语言编写的同类工具,Sist2采用C语言进行底层开发,充分利用了多线程处理能力,索引速度极快且内存占用极低。它支持增量扫描与递归扫描,即便是压缩包(如ZIP)内的文件内容也能被提取和索引。
3. 完全离线的隐私保障
将包含敏感信息的技术文档或商业报告上传至云端进行索引总会让人心存疑虑。Sist2的设计哲学是完全本地化运行,所有索引数据都存储在你自己的服务器或电脑上,从根本上杜绝了隐私泄露的风险。
4. 丰富的元数据与智能处理能力
为了让你更全面地了解其能力,下表列出了其主要特性:
| 功能 |
描述 |
| 标签与脚本 |
支持通过手动或自定义脚本为文件打标签,实现更智能的分类管理。 |
| 元数据提取 |
自动提取图片的EXIF信息、视频时长、PDF作者、创建日期等丰富元数据。 |
| 磁盘空间可视化 |
内置统计面板,直观展示各类文件所占用的空间比例。 |
| 命名实体识别(NER) |
(在客户端)能够识别文档中出现的人名、地名等实体信息。 |
| 现代化Web界面 |
提供简洁流畅的Web前端,支持模糊匹配、过滤,体验接近使用谷歌搜索。 |
如何快速部署与使用?
Sist2推荐使用 Docker Compose 进行部署,流程清晰且易于管理。这对于熟悉 Docker 和容器化运维的开发者而言非常友好。
提示:配置的核心在于将本地存放文件的目录路径正确映射到容器内。
以下是一个基础的 docker-compose.yml 配置示例:
services:
elasticsearch:
image: elasticsearch:7.17.9
environment:
- "discovery.type=single-node"
- "ES_JAVA_OPTS=-Xms2g -Xmx2g"
sist2-admin:
image: sist2app/sist2:x64-linux
volumes:
- /你的本地数据路径:/data # 请替换为你的实际文件目录
ports:
- 4090:4090 # Web前端访问端口
- 8080:8080 # 管理后台端口
- 将上述配置中的
/你的本地数据路径 替换为你需要索引的文件目录实际路径。
- 在配置文件所在目录下执行
docker-compose up -d 启动服务。
- 访问
http://你的服务器IP:8080 进入管理后台。
- 在后台界面中,点击 “Index Now” 开始首次全量索引。
索引完成后,你就可以通过访问 http://你的服务器IP:4090 来使用搜索前端,像使用互联网搜索引擎一样快速查找本地文件内容了。
它适合哪些用户?
- 个人知识库/资料管理者:拥有大量扫描版书籍、技术论文、报告PDF,需要快速定位其中特定内容的用户。
- Homelab/NAS玩家:Sist2的Docker化部署和低资源消耗特性,使其非常适合于家庭实验室或NAS环境,为你的媒体库和文档库添加强大搜索能力。
- 注重数据隐私的团队或个人:对敏感数据有严格的本地化要求,不希望任何内容被第三方服务接触。
潜在的考量点:由于依赖Elasticsearch,首次建立全量索引时对CPU和内存有一定要求(建议为Elasticsearch分配至少2GB内存)。此外,其Web界面秉承极简实用风格,视觉效果可能不如一些商业软件华丽,但在其惊人的搜索速度面前,这一点显得微不足道。
更深度的思考:为什么不是向量数据库?
看到这里,技术敏锐的读者可能会问:当下向量数据库和Embedding技术正热,直接使用AI进行语义搜索不是更“智能”吗?
这是一个很好的问题。答案在于“效率”与“精度”的权衡。
虽然向量搜索在理解语义关联方面优势明显,但对于精确的技术术语、代码片段或特定字符串的查找,传统的关键词索引(如Sist2采用的方案)往往更加精准直接,“指哪打哪”。此外,将成千上万份技术文档全部进行向量化处理,对于普通家用设备的计算资源来说是一个巨大的负担,其耗时可能远超基于 C语言 高效索引的Sist2。
总结
在信息过载的今天,“占有数据”并不等同于“掌控知识”。只有当你能在瞬间从海量文件中精确检索到所需信息时,这些数据才真正产生了价值。Sist2所做的,正是通过高效的技术栈组合(Elasticsearch + C语言),唤醒沉睡在你硬盘深处的数据宝藏。
如果你正在寻找一个轻量、快速、隐私安全且功能强大的本地文件搜索方案,Sist2绝对值得你花时间尝试。更多像这样提升开发效率的工具和深度讨论,欢迎关注 云栈社区,与广大开发者一起探索技术的无限可能。
 发表于 2026-2-11 09:02:50
|
查看: 244|
回复: 0
发表于 2026-2-11 09:02:50
|
查看: 244|
回复: 0
