信息过载的痛点
撰写报告或进行市场调研时,一个常见的挑战是信息搜集与整合。以研究“AI Agent技术演进”为例,你往往需要在浏览器中打开数十个标签页,穿梭于知乎讨论、行业报告、技术博客和学术论文之间。这些信息来源混杂,质量参差不齐,导致信息难以抓取、调研效率低下,且数据出处难以追溯。
解决方案:GPT Researcher 介绍
为了应对这一挑战,推荐一款基于大语言模型的开源智能研究工具——GPT Researcher。你只需给定一个研究主题,它便能像专业研究员一样,自动进行网络深度调研,并最终生成一份结构清晰、论证详实且附带完整引用来源的综合性报告。
该项目在GitHub上已获得超过2.4万颗星,采用Python编写,完全免费开源。
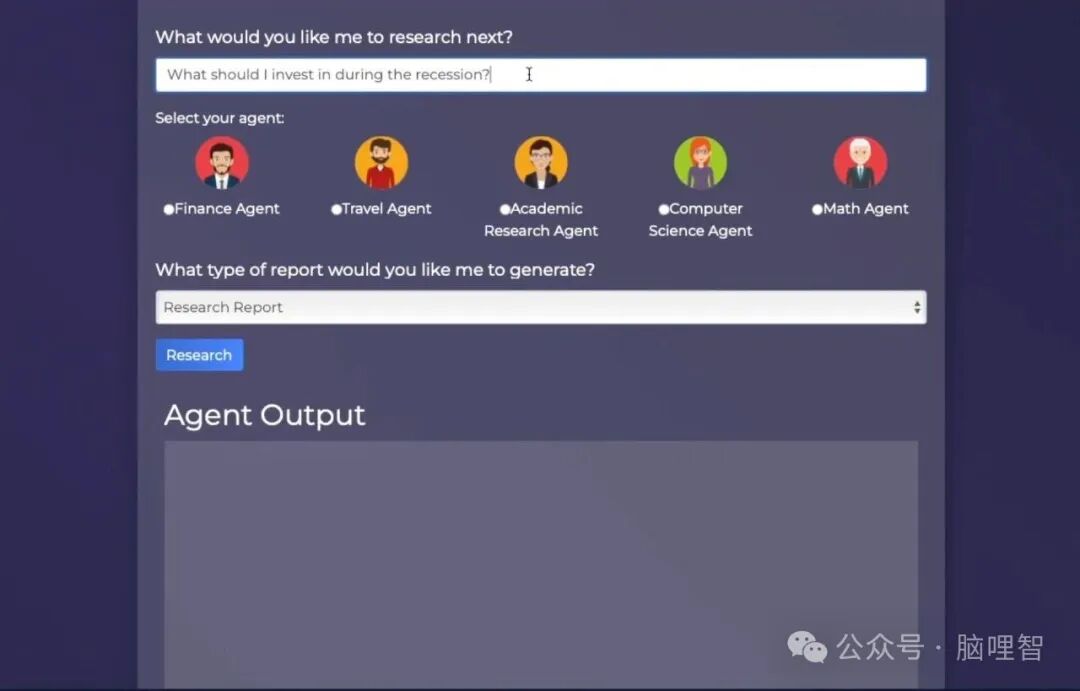
核心特性与优势
🤖 全自动深度研究
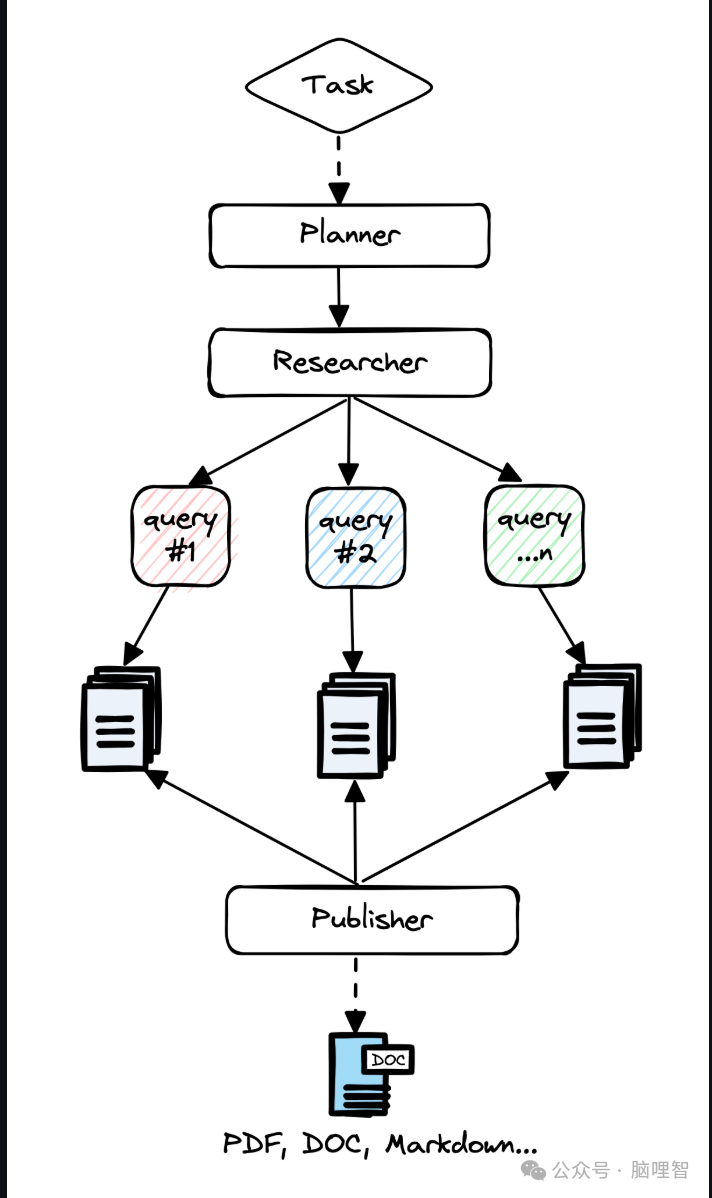
GPT Researcher 并非简单的搜索引擎聚合器。它会自动规划研究路径,并发起多个AI代理任务,分头从可靠的网站(范围可自定义)中搜集信息,随后进行交叉验证、去伪存真和观点提炼,最终形成一份逻辑清晰、带有独立分析的综合报告,而非信息堆砌。
📚 报告专业,引用清晰
生成报告结构规范,通常包含引言、核心论点、深度分析和结论。所有关键结论都会明确标注其网络来源链接,如同严谨的学术脚注,极大方便了后续的核查与引用。
🔧 高度可定制化与本地部署
- 研究范围可控:可限制其仅搜索学术文献、新闻或指定网站。
- 保障数据隐私:支持本地部署,确保敏感研究主题的数据不外流。
- 模型灵活切换:框架支持接入GPT、Claude或本地大语言模型等多种后端,像搭积木一样自由配置。
快速上手教程
跟随以下步骤,即可在几分钟内搭建并体验GPT Researcher。
-
克隆项目
将项目代码克隆到本地。
git clone https://github.com/assafelovic/gpt-researcher.git
cd gpt-researcher
-
安装依赖
建议在虚拟环境中安装必要的Python依赖包。
pip install -r requirements.txt
-
配置API密钥
复制环境变量模板文件,并填入你的OpenAI API密钥以及Tavily搜索API密钥。
cp .env.example .env
# 使用文本编辑器打开 .env 文件,填写 OPENAI_API_KEY 和 TAVILY_API_KEY
-
启动服务
运行以下命令启动本地Web服务。
python -m uvicorn main:app --reload
-
访问界面
在浏览器中打开 http://localhost:8000,输入研究问题,即可开始使用。
整个过程,你仅需提供一个明确的问题,后续的信息搜集、分析与报告撰写均可交由GPT Researcher自动完成,极大地提升了研究效率。
总结
无论是学生撰写论文、产品经理分析竞品,还是开发者调研技术选型,GPT Researcher都能显著提升信息处理与报告生成的效率。它将我们从繁琐的信息搜集与初步整理中解放出来,使我们能更专注于深度思考和策略决策。 在AI工具普及的当下,熟练掌握此类工具是提升个人生产力的有效途径。
项目开源地址:https://github.com/assafelovic/gpt-researcher |  发表于 2025-12-5 12:42:46
|
查看: 196|
回复: 0
发表于 2025-12-5 12:42:46
|
查看: 196|
回复: 0
