在算法交易日益普及的现代市场中,实时监控系统性风险变得愈发重要。本文构建了一个市场压力概率指数(MSPI),用于预测未来一个月出现高压市场状态的概率。该指数利用CRSP日度数据,将每个月的市场状态概括为一组可解释的横截面脆弱性信号,并通过实时扩张窗口设计下的L1正则化逻辑回归(Lasso-Logit)将这些信号映射为前瞻性的压力概率。
在样本外测试中,MSPI能够有效追踪主要的压力时期。相较于仅基于滞后市场收益率和已实现波动率的简约基准模型,MSPI在区分度和概率准确性上均有显著提升,并能提供具有经济意义的校准概率。更重要的是,MSPI不仅仅是一个黑盒预测工具,更是一个金融计量学中的概率测量对象,为近期权益市场压力风险提供了一种透明且易于更新的度量标准,这正是现代算法监控所追求的核心目标之一。
1. 背景与研究动机
市场环境的变迁
金融压力的信息环境和制度环境在过去二十年发生了根本性变化。交易、流动性提供和订单处理日益电子化和算法化。算法交易在正常时期影响市场质量和流动性提供,而在极端时期,同样的自动化机制可能与反馈效应相互作用,引发系统性压力。例如,同步的流动性撤回、相关的去杠杆化或订单处理摩擦,可能触发或放大市场压力。
算法监控的必要性
在这种环境下,传统的宏观金融实证研究面临挑战。现有的压力指标往往依赖于难以解释的综合指数、非权益市场数据,或者无法在高频下保持一致性。更重要的是,当被监控的对象(市场本身)是算法化运作时,监控层必须具备与之匹配的速度和规模。纯人工的自由裁量式监控难以实时汇总成千上万证券的微弱噪音信号。因此,监控本身必须是算法化的:即使用透明的统计学习系统,将高维市场信息压缩为可解释的、实时的状态变量。
MSPI的定位
MSPI被设计为一种针对现代电子市场的金融计量测量管道。它仅使用权益市场数据,将收益率和交易活动的横截面脆弱性压缩为单一的、经过校准的概率值。该指标强调概率输出的准确性和可靠性,而非仅仅是排序性能,使其能够直接嵌入标准实证设计或风险控制协议中。与深度神经网络等黑盒方法不同,MSPI采用了稀疏且可解释的线性映射,并与随机森林和梯度提升树等非线性模型进行了“赛马”对比,以验证简约结构在有限样本下的稳健性。
2. 数据说明
本研究使用CRSP日度股票数据。
- 样本范围: 美国普通股(CRSP share codes 10 和 11),在NYSE/AMEX/NASDAQ上市(exchange codes 1, 2, 3),且股价不低于1美元。
- 市场变量: 使用CRSP日度价值加权市场指数收益率构建聚合市场变量。月度市场收益率由日度收益率复利计算得出,月度已实现波动率由日度收益率的月内标准差年化(乘以 $\sqrt{12}$)得出。
- 数据频率: 横截面预测因子在月度频率上构建,具体方法是计算符合条件股票的日度横截面统计量,然后在月内取平均值。
- 时间跨度: 模型训练起始于有足够历史数据计算扩张实时波动率分位数之时,样本外评估在初始的120个月训练窗口之后开始。
3. 构建横截面脆弱性信号
MSPI的核心逻辑在于:市场压力会在个股收益率和交易活动的横截面上留下独特的“足迹”。当市场状况恶化时,收益率离散度增加,下行极端值变得更加频繁,横截面高阶矩发生偏移,反映出尾部风险和联动性的提升。这些横截面特征被定义为“脆弱性信号”。
令 $r_{i, d}$ 表示股票 $i$ 在交易日 $d$ 的日收益率,$N_d$ 为当日可用股票数量。首先定义日度横截面平均收益率:
$$\bar{r}_d = \frac{1}{N_d} \sum_{i=1}^{N_d} r_{i, d}$$
3.1 分布矩信号
为了捕捉异质性冲击和相关性结构的崩溃,研究计算了日度横截面的离散度及高阶矩:
- 横截面标准差: $\sigma_d^{x,s} = \sqrt{ \frac{1}{N_d} \sum_{i=1}^{N_d} (r_{i, d} - \bar{r}_d)^2 }$
该指标衡量市场的分化程度。在压力时期,个股表现差异巨大,相关性结构可能发生改变。
- 横截面偏度: $Skew_d^{x,s} = \frac{ \frac{1}{N_d} \sum_{i=1}^{N_d} (r_{i, d} - \bar{r}_d)^3 }{ (\sigma_d^{x,s})^3 }$
反映收益分布的不对称性,特别是下行风险的集中度。
- 横截面峰度: $Kurt_d^{x,s} = \frac{ \frac{1}{N_d} \sum_{i=1}^{N_d} (r_{i, d} - \bar{r}_d)^4 }{ (\sigma_d^{x,s})^4 }$
衡量尾部的厚度,反映极端横截面波动的发生频率。
3.2 尾部参与度信号
为了稳健地捕捉类尾部行为,计算极端赢家和输家的比例:
- 下行极端占比: $Frac_d^{dn}(q) = \frac{1}{N_d} \sum_{i=1}^{N_d} \mathbf{1}_{\{r_{i, d} \leq -q\}}$
基准设定 $q = 5\%$。该指标衡量发生大额负收益的股票比例,反映市场崩盘的广度。
- 上行极端占比: $Frac_d^{up}(q) = \frac{1}{N_d} \sum_{i=1}^{N_d} \mathbf{1}_{\{r_{i, d} \geq +q\}}$
衡量发生大额正收益的股票比例。
3.3 交易强度与价格幅度
除了收益率分布,交易活动也是压力的重要体现:
- 价格波动幅度: $|r|_d = \frac{1}{N_d} \sum_{i=1}^{N_d} |r_{i, d}|$,衡量价格变动的平均振幅。
- 平均对数成交量: $\log(1 + Vol)_d = \frac{1}{N_d} \sum_{i=1}^{N_d} \log(1 + volume_{i,d})$,反映市场参与度和活动峰值。
- 平均成交金额: $\$$Vol_d = \frac{1}{N_d} \sum_{i=1}^{N_d} |P_{i,d}| \times Vol_{i,d}$,衡量流动性使用情况和资金周转。
- 平均换手率: $Turn_d = \frac{1}{N_d} \sum_{i=1}^{N_d} (Vol_{i,d} / SharesOut_{i,d})$,衡量筹码交换和重新配置的速度。
3.4 月度特征聚合
上述指标均为日度统计量 $z_d$。为了构建月度预测因子 $x_t$,研究将日度指标在月内进行平均:
$$x_t = \frac{1}{D_t} \sum_{d \in month\ t} z_d$$
其中
$D_t$ 为月度
$t$ 的交易天数。此外,还包括月度平均股票数量
$n\_stocks_t$ 以控制覆盖范围的变化。
这一特征集设计的核心在于直接从权益市场横截面中提取潜在的压力信息,而不依赖期权隐含数据,从而保证了长历史跨度和实时可用性。
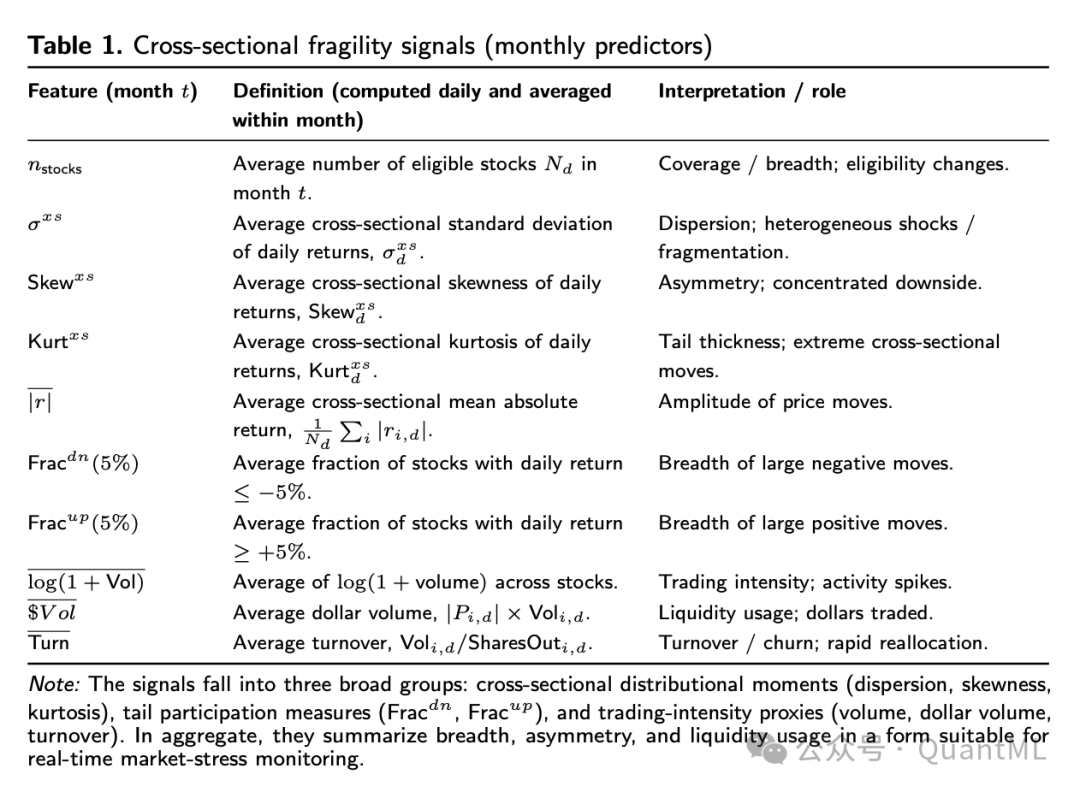
4. 定义压力与学习压力概率指数
4.1 压力状态定义
MSPI的目标是预测下一个月是否为“压力月”。压力的定义结合了市场大幅下跌和波动率异常升高两个维度。令 $r_t^m$ 为月度市场收益率,$RV_t$ 为月度已实现波动率。 压力状态变量 $S_t$ 定义如下:
$$S_t = \mathbf{1}_{\{ r_t^m \leq \bar{r} \ \text{and} \ RV_t \geq q_\tau(RV_{1:t-1}) \}}$$
- 下行阈值 $\bar{r}$: 固定为 -5%。这代表了具有经济意义的月度回撤。
- 波动率阈值 $q_\tau$: 这是一个扩张的、实时的分位数(基准设为 $90\%$)。关键在于,该分位数仅使用截至 $t-1$ 月的历史数据计算,确保压力标签的定义完全基于实时信息,不包含未来数据。
该定义将大约10%的最动荡月份归类为压力月。预测目标是下一期的压力状态:$y_t = S_{t+1}$。
4.2 MSPI的学习机制(Lasso-Logit)
MSPI被定义为模型隐含的压力概率:
$$MSPI_t = P(y_t = 1 | x_t) = \frac{1}{1 + \exp(-(\beta_0 + \beta^T x_t))}$$
其中
$x_t$ 是第3节构建的横截面脆弱性信号向量,
$\sigma(·)$ 为Logistic函数。
为了避免过拟合并鼓励模型的稀疏性与可解释性,参数 $\beta$ 通过L1正则化逻辑回归进行估计。估计器求解以下优化问题:
$$\hat{\beta} = \arg\min_{\beta} \left\{ -\sum_{i=1}^{T_{train}} \left[ y_i (\beta_0 + \beta^T x_i) - \log(1 + e^{\beta_0 + \beta^T x_i}) \right] + \lambda \sum_{j=1}^{p} |\beta_j| \right\}$$
实时扩张窗口协议: 这是MSPI构建的关键。
- 初始窗口: 使用最初120个月的数据进行训练。
- 超参数选择: 正则化参数 $\lambda$ 在初始窗口内通过时间序列交叉验证选择,并在随后的评估中保持固定。
- 动态重估: 在每个样本外月份 $t$,仅使用截至 $t-1$ 的可用数据重新估计模型参数。这模拟了从业者在预测时面临的真实信息约束。预测因子在每个训练窗口内进行标准化。
4.3 基准模型与非线性模型
为了评估MSPI的增量价值,研究引入了对比模型:
- 简约基准: 一个仅使用滞后市场收益率 $r_{t-1}^m$ 和滞后已实现波动率 $RV_{t-1}$ 的L2正则化逻辑回归。
- 非线性模型: 随机森林和梯度提升树。这些模型使用与MSPI相同的横截面特征集。
为了进行公平比较,所有模型均在相同的实时扩张窗口协议下运行。对于RF和GB,由于其原始分数未必是校准良好的概率,研究在每个训练窗口内应用了实时Platt Scaling校准,以确保输出的是具有可比性的概率值。
5. 样本外实证结果
5.1 时间序列动态
MSPI在主要的市场压力时期前均出现显著上升,尤其是在2008-2009年金融危机和2020年COVID冲击期间。MSPI不仅能识别这些大事件,还显示出压力状态的聚集性。
在与非线性模型的“赛马”中,结果显示:
- 信号稳定性: MSPI产生的时间序列路径相对平滑且稳定。
- 非线性模型的局限: RF和GB生成的概率路径更加锯齿状和偶发性,尤其是在危机前和过渡期。
- 结论: 稀疏的线性模型在提供作为持续监控工具所需的稳定性方面优于复杂的非线性模型。
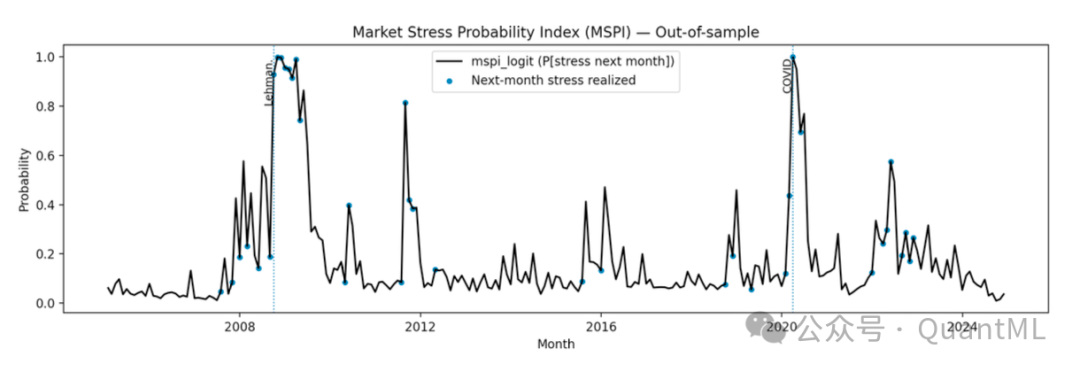
5.2 区分度与概率准确性
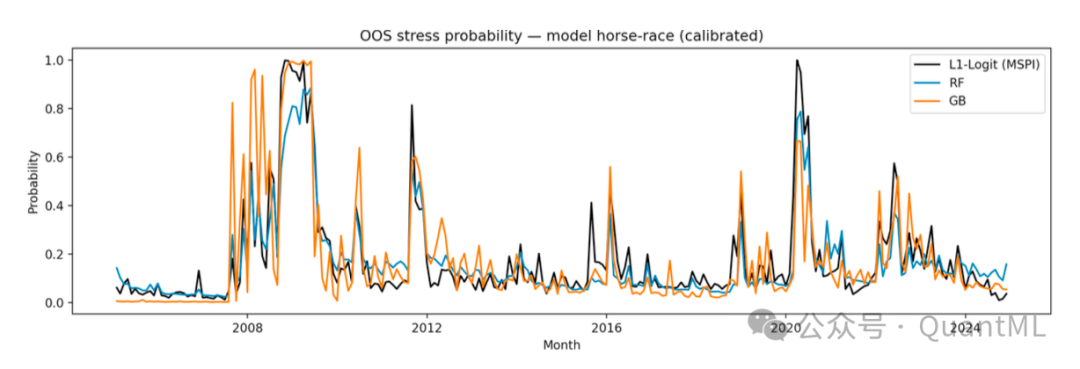
下表和图展示了模型在样本外的表现,主要指标包括AUC、PR-AUC、Brier Score和Log Loss。
-
区分度:
- MSPI实现了0.800的AUC和0.538的PR-AUC,均优于基准模型。
- 即使与复杂的非线性模型相比,MSPI也极具竞争力。梯度提升树的AUC为0.756,随机森林为0.727,均未超过MSPI。这表明,在月度频率和有限样本下,增加模型复杂性并不一定能提高对压力状态的排序能力。
-
概率准确性与校准:
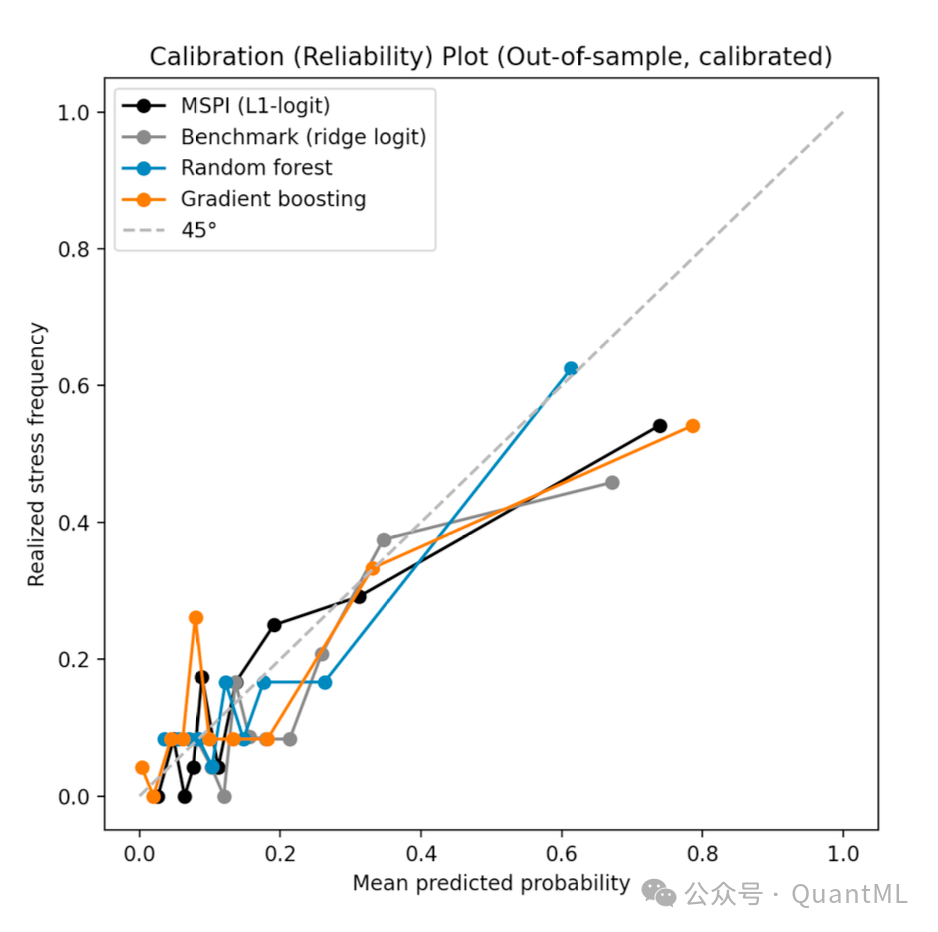
- 由于MSPI是作为概率度量设计的,校准至关重要。
- MSPI取得了最低的Brier Score (0.106) 和 Log Loss (0.352) ,优于基准模型和非线性模型。
- 预期校准误差: MSPI的ECE为0.062,显示出良好的校准水平。相比之下,基准模型的ECE较高。
- 这说明MSPI提供的不仅仅是正确的方向,更是准确的风险水平。
5.3 结果解读
MSPI的优越表现并非来自复杂的函数形式,而是来自信息集(横截面脆弱性信号优于纯宏观聚合变量)和正则化策略(L1稀疏性在低信噪比环境下优于全参数非线性拟合)。
6. 经济解释与算法监控应用
本节阐述如何将MSPI作为金融计量学中的测量工具,而不仅仅是预测工具。
6.1 概率尺度上的经济价值
MSPI的概率输出可以直接映射到决策阈值。由于其经过了良好的校准,风险管理者可以依据具体的损失函数设定操作规则(例如:当MSPI > 20%时触发降低仓位)。Brier Score和Log Loss的显著改善表明,MSPI作为决策依据比未校准的分类器更可靠。
6.2 不同MSPI分组下的已实现结果
通过将样本外月份按MSPI预测概率分组,研究发现:
- 实际压力频率: 随着MSPI分组的提升,下月实际发生压力的频率急剧上升(从低分组的2.7%升至高分组的51.9%)。
- 市场波动率: 高MSPI状态与随后的高市场波动率显著相关。
- 这证实了MSPI蕴含了关于体制性压力和波动性动态的有意义的前瞻性信息。
6.3 波动率与下行尾部风险的预测解释
MSPI可作为预测回归中的状态变量。
$$RV_{t+1} = \alpha + \gamma MSPI_t + \delta_1 r_t^m + \delta_2 RV_t + \epsilon_{t+1}$$
由于MSPI是基于横截面信号构建的,它包含的信息正交于滞后的市场聚合变量。实证结果表明,MSPI对未来波动率和下行崩盘风险具有显著的预测能力。
6.4 从测量到压力风险新息
为了在动态分析中使用MSPI,需要提取其“冲击”成分。研究构建了压力风险新息:
$$\eta_t = MSPI_t - E_{t-1}[MSPI_t]$$
$\eta_t$ 代表了关于近期压力风险的“消息”,它正交于滞后信息。
6.5 算法市场的算法监控
本节在概念上进一步升华。现代市场结构本身是算法化的。压力往往源于快速变化的横截面动态和非线性放大机制。在这种环境下,监控系统必须满足三个原则,而MSPI的设计正是基于这三个原则:
- 实时可执行性: 必须基于实时数据流。
- 透明性: 必须可解释,以便纳入治理流程。
- 校准概率: 输出必须是可靠的概率,而非任意分数,以支持基于阈值的决策。
MSPI正是算法市场中手动监控与完全黑盒之间的桥梁,提供了一种可复制、可审计的“算法辅助”监控手段。这种对机器学习模型透明性和可解释性的追求,对于构建可信的金融风险系统至关重要。
7. 结论
本文提出了一种基于权益市场横截面数据的市场压力概率指数。该指数通过L1正则化逻辑回归在实时扩张窗口中估计,将微观层面的脆弱性信号转化为宏观层面的压力概率。
主要贡献包括:
- 构建方法: 提出了一套基于日度横截面统计量的特征工程方法,捕捉市场压力的微观结构足迹。
- 实证表现: 样本外测试证明,MSPI在区分度、准确性和校准性上均优于仅依赖滞后市场变量的基准模型,且相对于复杂的非线性机器学习模型表现出更高的稳定性和可靠性。
- 应用价值: MSPI被设计为一个透明的、仅依赖权益数据的实时监控输入变量。其校准良好的概率属性使其能够直接应用于风险管理阈值设定和金融计量分析。
对于希望深入探讨量化模型构建与风险管理的开发者,可以在云栈社区找到更多相关的技术讨论与资源。
 发表于 2026-2-11 12:11:25
|
查看: 225|
回复: 0
发表于 2026-2-11 12:11:25
|
查看: 225|
回复: 0
