混淆矩阵是机器学习、分类模型评估和人工智能中非常常见的一个术语。它用来描述:分类模型把各类样本分别预测成了什么类别。换句话说,混淆矩阵是在回答:模型到底哪些样本分对了,哪些样本分错了,又分别错成了哪一类。
如果说准确率回答的是“模型总体上有多少预测是对的”,那么混淆矩阵回答得更细:每一类样本分别被模型如何判断。因此,混淆矩阵常用于分类模型评估、错误分析、精确率、召回率、F1 值计算以及分类任务的模型诊断,在人工智能中具有重要基础意义。
一、基本概念:什么是混淆矩阵
混淆矩阵(Confusion Matrix)是一种用于评价分类模型预测结果的表格。
它把真实类别和预测类别放在同一个矩阵中进行对照,从而显示模型在不同类别上的分类情况。
对于二分类任务,混淆矩阵通常包含四个基本结果:
• 真正例(True Positive,TP)
• 假正例(False Positive,FP)
• 真负例(True Negative,TN)
• 假负例(False Negative,FN)
其中:
• TN 表示真实为负类,模型也预测为负类
• FP 表示真实为负类,但模型预测为正类
• FN 表示真实为正类,但模型预测为负类
• TP 表示真实为正类,模型也预测为正类
从通俗角度看,混淆矩阵可以理解为:一张分类模型的“错题统计表”。
它不只是告诉我们模型错了多少,还会告诉我们:
• 哪些类别容易被分对
• 哪些类别容易被分错
• 错误主要错在哪里
• 哪些类别之间容易混淆
这也是“混淆矩阵”这个名称的来源。
二、为什么需要混淆矩阵
混淆矩阵之所以重要,是因为单独看准确率往往不够。
例如,一个疾病检测模型在 1000 个样本中预测对了 950 个,准确率为 95%。看起来效果很好。但如果进一步检查发现:大多数健康样本都判断对了,但很多真正患病样本却被判断成健康。
那么这个模型在实际医疗场景中可能并不可靠。
这时,混淆矩阵就非常有价值。它可以显示:
• 患病样本有多少被正确识别
• 患病样本有多少被漏掉
• 健康样本有多少被误判为患病
• 健康样本有多少被正确排除
从通俗角度看,准确率像总分,混淆矩阵像详细错题本。
只看总分,我们只知道模型整体表现;看混淆矩阵,我们才知道模型到底错在什么地方。
因此,混淆矩阵的核心作用是:把分类结果拆开来看,帮助我们理解模型错误的结构。
三、混淆矩阵的重要性与常见应用场景
1、混淆矩阵的重要性
混淆矩阵之所以重要,是因为它能提供比单一指标更细致的分类评估信息。
首先,它能帮助我们分析错误类型。在分类任务中,错误不只是“错了”这么简单。把猫预测成狗,和把猫预测成汽车,错误性质可能不同。混淆矩阵可以显示错误具体发生在哪些类别之间。
其次,它是许多评价指标的基础。精确率、召回率、F1 值、特异度等指标都可以从混淆矩阵中的 TP、FP、TN、FN 推导出来。
再次,它特别适合类别不平衡任务。当某些类别样本特别多、某些类别样本特别少时,准确率可能产生误导,而混淆矩阵能更清楚地显示少数类是否被模型忽略。
可以概括地说:
• 准确率看总体对错
• 混淆矩阵看各类对错
错误分析要从混淆矩阵开始。
2、常见应用场景
(1)在二分类任务中,混淆矩阵用于分析正类和负类的预测情况,例如垃圾邮件识别、疾病筛查、欺诈检测等。
(2)在多分类任务中,混淆矩阵用于分析类别之间的混淆关系,例如手写数字识别、图像分类、文本主题分类等。
(3)在类别不平衡任务中,混淆矩阵用于检查模型是否只偏向多数类,例如异常检测、罕见病识别、风险预警等。
(4)在模型调参中,混淆矩阵可用于观察模型改进是否真正改善了关键类别。
(5)在错误分析中,混淆矩阵可以帮助找出最容易混淆的类别对。
四、二分类混淆矩阵的四个核心结果
二分类混淆矩阵最重要的是理解 TP、FP、TN、FN。
假设任务是判断一封邮件是否为垃圾邮件:
• 正类:垃圾邮件
• 负类:正常邮件
真正例(True Positive,TP)表示:真实为正类,模型也预测为正类。
在垃圾邮件识别中,就是:真实是垃圾邮件,模型也判断为垃圾邮件。这是模型正确识别正类的情况。
假正例(False Positive,FP)表示:真实为负类,但模型预测为正类。
在垃圾邮件识别中,就是:真实是正常邮件,模型误判为垃圾邮件。这也叫误报。从通俗角度看,FP 是:本来不是,模型却说是。
真负例(True Negative,TN)表示:真实为负类,模型也预测为负类。
在垃圾邮件识别中,就是:真实是正常邮件,模型也判断为正常邮件。这是模型正确识别负类的情况。
假负例(False Negative,FN)表示:真实为正类,但模型预测为负类。
在垃圾邮件识别中,就是:真实是垃圾邮件,模型误判为正常邮件。这也叫漏报。从通俗角度看,FN 是:本来是,模型却说不是。
五、如何直观理解 TP、FP、TN、FN
TP、FP、TN、FN 容易混淆,可以用两个问题来判断。
第一个问题:模型预测的是正类还是负类?
• 预测为正类,就看 Positive
• 预测为负类,就看 Negative
第二个问题:模型预测对了还是错了?
• 预测对了,就看 True
• 预测错了,就看 False
因此:
• TP:预测为正类,并且预测对了
• FP:预测为正类,但预测错了
• TN:预测为负类,并且预测对了
• FN:预测为负类,但预测错了
从通俗角度看,可以这样记:
• T 表示“模型判断对了”
• F 表示“模型判断错了”
• P 表示“模型说是正类”
• N 表示“模型说是负类”
所以:
• TP:模型说是正类,说对了
• FP:模型说是正类,说错了
• TN:模型说是负类,说对了
• FN:模型说是负类,说错了
这比直接背英文名称更容易理解。
六、混淆矩阵与准确率的关系
准确率(Accuracy)可以由混淆矩阵计算出来。它表示所有样本中,模型预测正确的比例。
对于二分类任务,准确率可以写为:
$$Accuracy = \frac{TP + TN}{TP + TN + FP + FN}$$
其中:
• TP + TN 表示预测正确的样本数
• TP + TN + FP + FN 表示全部样本数
从通俗角度看,准确率就是:所有题目中做对了多少题。
但准确率有一个问题:它不能告诉我们模型具体错在哪里。比如模型错在漏掉正类,还是错在误报太多;是某一类特别差,还是各类都差不多。这些信息准确率都不能单独说明。
因此,准确率适合做总体概览,而混淆矩阵适合做细节分析。
七、混淆矩阵与精确率、召回率、F1 值的关系
混淆矩阵是许多分类指标的基础。
1、精确率
精确率(Precision)表示:模型预测为正类的样本中,有多少是真的正类。
$$Precision = \frac{TP}{TP + FP}$$
从通俗角度看,精确率回答的是:模型说“是”的时候,有多少次说对了。
2、召回率
召回率(Recall)表示:所有真实正类样本中,有多少被模型找出来了。
$$Recall = \frac{TP}{TP + FN}$$
从通俗角度看,召回率回答的是:真正应该找出来的正类,模型找出了多少。
3、F1 值
F1 值是精确率和召回率的调和平均:
$$F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall}$$
F1 值用于综合衡量精确率和召回率。
从通俗角度看:
• 精确率关心“别乱报”
• 召回率关心“别漏掉”
• F1 值关心二者之间的平衡
因此,混淆矩阵不仅是一张表,也是很多评价指标的来源。
八、混淆矩阵在多分类任务中的形式
混淆矩阵不仅适用于二分类,也适用于多分类。
假设有三个类别:猫、狗、兔子,那么混淆矩阵可以是一个 3 × 3 矩阵。通常可以理解为:
• 行表示真实类别
• 列表示预测类别
例如:
• 第一行表示真实为“猫”的样本被预测成各类的情况
• 第二行表示真实为“狗”的样本被预测成各类的情况
• 第三行表示真实为“兔子”的样本被预测成各类的情况
矩阵对角线上的数字表示预测正确的数量,非对角线上的数字表示预测错误的数量。例如第一行第二列的 3 表示:真实是猫,但被模型预测成狗的样本有 3 个。
从通俗角度看,多分类混淆矩阵可以帮助我们发现:
• 猫容易被错分成狗
• 狗是否容易被错分成兔子
• 哪个类别识别最好
• 哪些类别之间最容易混淆
九、如何阅读混淆矩阵
阅读混淆矩阵时,可以从几个角度入手。
1、先看对角线
对角线表示预测正确的样本数。如果对角线上的数值普遍较大,说明模型整体分类效果较好。
2、再看非对角线
非对角线表示分类错误。如果某个非对角线位置数值很大,说明模型经常把一个类别误判成另一个类别。例如,在手写数字识别中,真实为 8 却经常预测成 3,真实为 5 却经常预测成 6。这说明这些类别在特征上可能较相似,模型容易混淆。
3、按行看召回情况
如果行表示真实类别,那么某一行显示的是某个真实类别被预测成各类的分布。这一行中,对角线数值越高,表示该类别召回越好。
4、按列看精确情况
如果列表示预测类别,那么某一列显示的是被预测为某类别的样本实际来自哪些真实类别。这一列中,对角线数值越高,表示该预测类别的精确率越好。
从通俗角度看:
• 按行看:某个真实类别有没有被找出来
• 按列看:模型预测成某类时是否靠谱
十、混淆矩阵与类别不平衡问题
混淆矩阵在类别不平衡任务中尤其重要。
所谓类别不平衡,是指不同类别的样本数量差异很大。例如,在欺诈检测中,正常交易可能有 9900 条,欺诈交易可能只有 100 条。
如果模型把所有交易都预测为正常,那么总共预测对 9900 条,准确率为 99%,看起来非常高。但这个模型实际上完全没有识别出欺诈交易。
此时混淆矩阵会显示:TN 很大,FN 很大,TP 可能为 0。也就是说,模型虽然准确率高,但对真正重要的少数类完全失效。
从通俗角度看:类别不平衡时,准确率可能很好看,但混淆矩阵会揭示模型是否真的识别了关键类别。
因此,在不平衡分类中,不能只看准确率,还应结合混淆矩阵、精确率、召回率、F1 值、ROC 曲线、AUC、PR 曲线等指标综合分析。
十一、使用混淆矩阵时需要注意的问题
1、要明确正类和负类
在二分类任务中,TP、FP、TN、FN 的含义取决于哪个类别被定义为正类。例如,在疾病检测中,通常把“患病”定义为正类;在垃圾邮件识别中,通常把“垃圾邮件”定义为正类。正类定义不同,TP 和 TN 的解释也会变化。
2、要明确矩阵行列含义
不同工具可能默认行表示真实类别、列表示预测类别,或行表示预测类别、列表示真实类别。阅读时必须先确认行列定义,否则容易解释反。
3、混淆矩阵显示数量,不一定直接显示比例
如果不同类别样本数量差异很大,直接看数量可能不直观。这时可以使用归一化混淆矩阵,把每一行或每一列转换成比例。
4、混淆矩阵本身不是单一分数
它是一张结构化结果表,不像准确率、F1 值那样是一个数字。它更适合分析错误结构,而不是简单排序模型。
5、多分类混淆矩阵可能较大
如果类别很多,混淆矩阵会变得很大。此时通常重点观察对角线表现、高频混淆类别、关键类别召回率和少数类错误情况。
十二、Python 示例
下面给出三个简单示例,用来帮助理解混淆矩阵的计算和使用。
示例 1:手动计算二分类混淆矩阵
# 真实标签(1表示正类,0表示负类)
y_true = [1, 0, 1, 1, 0, 0, 1, 0]
# 模型预测标签
y_pred = [1, 0, 1, 0, 0, 1, 1, 0]
# 初始化混淆矩阵的四个分量
TP = 0 # True Positive: 实际为正,预测为正
FP = 0 # False Positive: 实际为负,预测为正
TN = 0 # True Negative: 实际为负,预测为负
FN = 0 # False Negative: 实际为正,预测为负
# 逐对比较真实标签和预测标签,统计各类数量
for true, pred in zip(y_true, y_pred):
if true == 1 and pred == 1:
TP += 1
elif true == 0 and pred == 1:
FP += 1
elif true == 0 and pred == 0:
TN += 1
elif true == 1 and pred == 0:
FN += 1
# 输出各分量值
print("TP =", TP)
print("FP =", FP)
print("TN =", TN)
print("FN =", FN)
# 输出混淆矩阵(格式:第一行[TN, FP],第二行[FN, TP])
print("混淆矩阵:")
print([[TN, FP],
[FN, TP]])
这个例子中,1 表示正类,0 表示负类。通过这个例子可以直观看到每类预测结果的数量。
示例 2:使用 Scikit-learn 计算混淆矩阵
from sklearn.metrics import confusion_matrix, classification_report
# 真实标签(多分类问题:类别0、1、2)
y_true = [0, 1, 2, 2, 0, 1, 1, 2, 0, 2]
# 模型预测标签
y_pred = [0, 1, 1, 2, 0, 0, 1, 2, 2, 2]
# 计算混淆矩阵(行=真实,列=预测)
cm = confusion_matrix(y_true, y_pred)
print("混淆矩阵:")
print(cm)
# 输出分类报告:包含精确率、召回率、F1分数等指标
print("分类报告:")
print(classification_report(y_true, y_pred))
这个例子中,confusion_matrix() 会生成多分类混淆矩阵,classification_report() 会进一步给出每个类别的精确率、召回率、F1 值和支持样本数。这有助于结合混淆矩阵进行更完整的模型评估。
示例 3:可视化混淆矩阵
在实际分析中,混淆矩阵通常会绘制成热力图,方便观察哪些类别容易混淆。
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
# 根据操作系统选择中文字体(二选一,取消注释对应行)
plt.rcParams["font.sans-serif"] = ["Microsoft YaHei"] # Windows
# plt.rcParams["font.sans-serif"] = ["Songti SC"] # macOS
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示为方块的问题
# 真实标签与预测标签
y_true = [0, 1, 2, 2, 0, 1, 1, 2, 0, 2]
y_pred = [0, 1, 1, 2, 0, 0, 1, 2, 2, 2]
# 类别名称
labels = ["类别0", "类别1", "类别2"]
# 计算混淆矩阵
cm = confusion_matrix(y_true, y_pred)
# 绘制混淆矩阵
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot()
plt.title("混淆矩阵")
plt.show()
输出示意图:
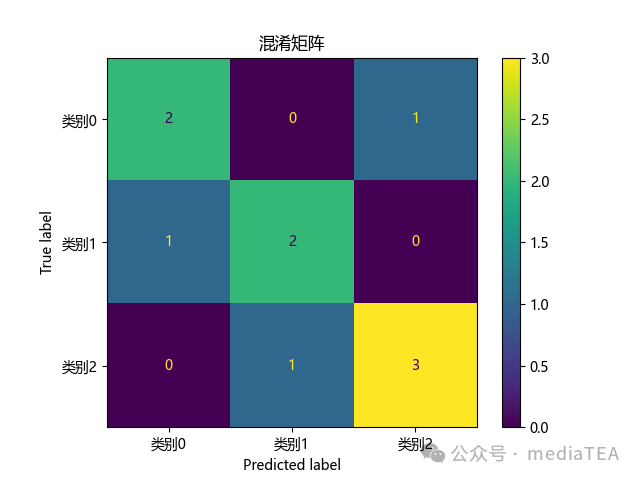
可视化混淆矩阵时,颜色越深通常表示该位置样本数越多。对角线颜色越明显,通常说明分类正确样本越多;非对角线颜色明显,则说明对应类别之间混淆较严重。
📘 小结
混淆矩阵是一种用于分析分类模型预测结果的表格。它通过对照真实类别和预测类别,展示模型分对了哪些样本、分错了哪些样本,以及具体错成了哪一类。在二分类中,混淆矩阵包含 TP、FP、TN、FN 四类结果;在多分类中,它可以显示不同类别之间的混淆关系。对初学者而言,可以把混淆矩阵理解为分类模型的“错题统计表”:准确率告诉我们总体对错,混淆矩阵告诉我们到底错在哪里。在云栈社区,你可以找到更多关于模型评估与调试的实战经验分享。
 发表于 2026-4-30 19:10:01
|
查看: 285|
回复: 0
发表于 2026-4-30 19:10:01
|
查看: 285|
回复: 0
