故障现象
2025年9月20日,某业务在凌晨进行变更后,其所在的Kubernetes集群出现以下问题:
- 集群更新业务后,Calico网络组件出现频繁重启的故障。
- Calico重启问题被临时修复后,又出现了网络规则下发至iptables异常的情况,导致Pod能分配到IP地址但网络不通。
影响范围
该K8s集群中Calico异常的节点无法提供网络服务,影响了业务的正常运行。
环境信息
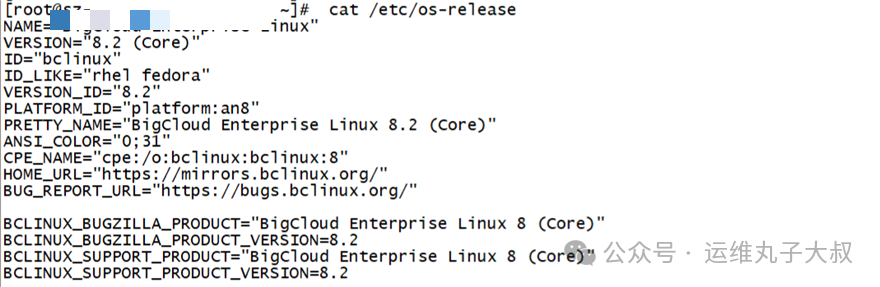
- 操作系统版本:龙蜥Linux 8.2
- 内核版本:4.19.0-240.23.35
- K8s版本:v1.19
- Calico版本:v3.18.1


排查过程
-
初步现象与日志分析
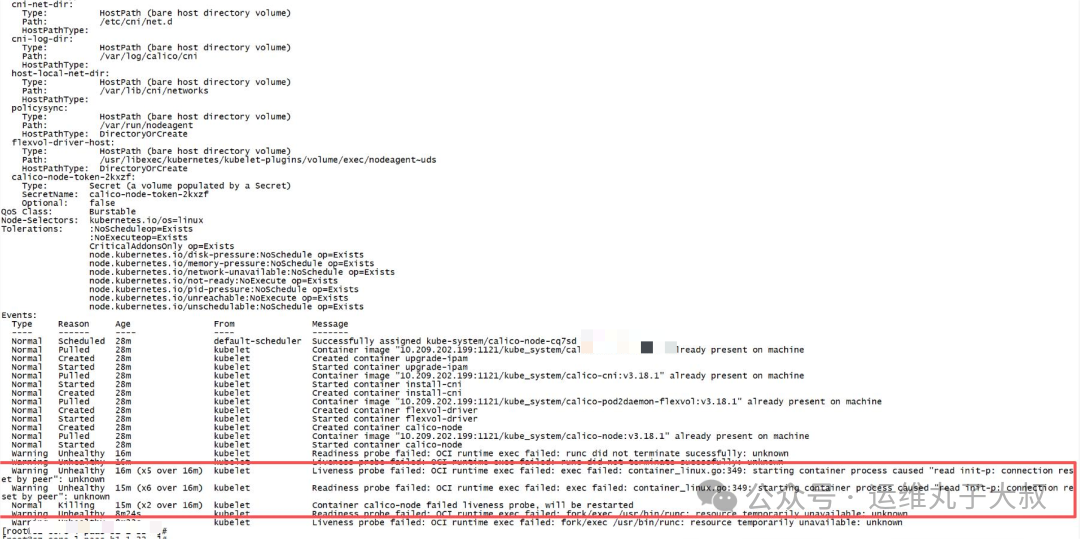
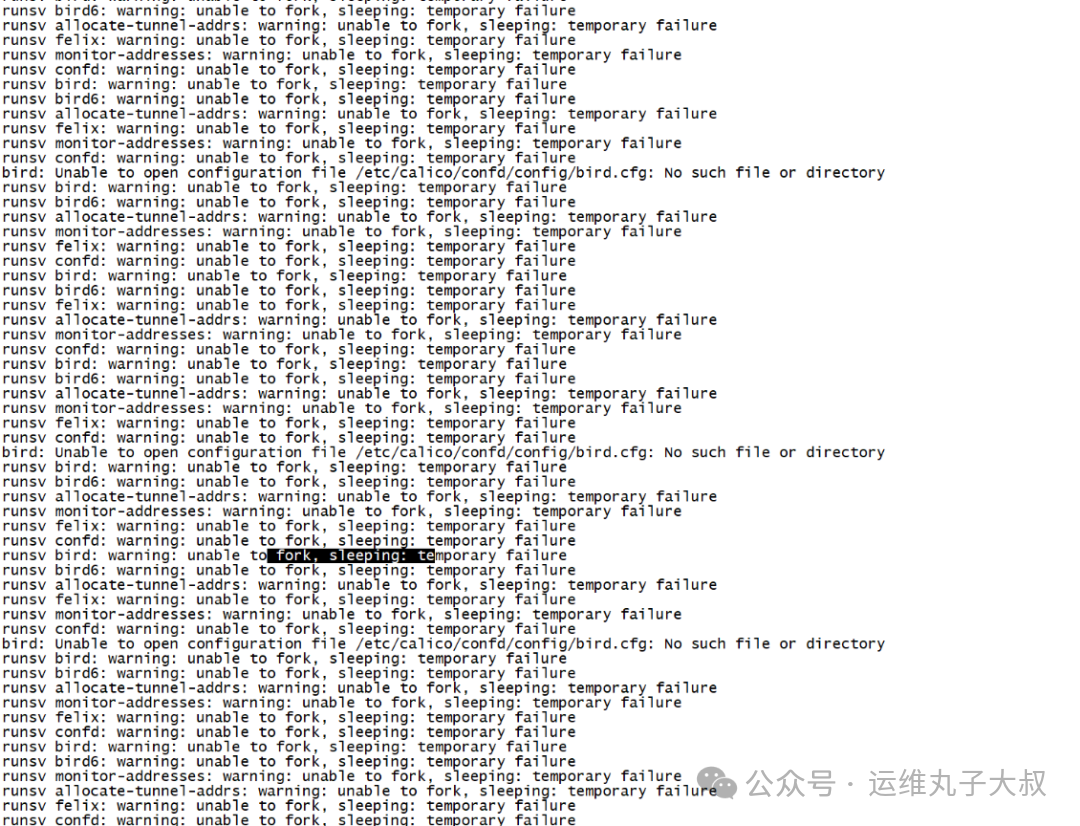
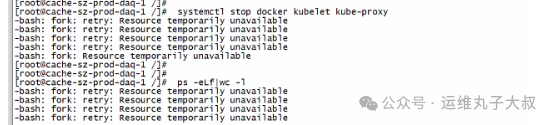
在排查过程中,发现故障节点的calico-node、kubelet、kube-proxy等核心组件频繁异常。查看日志时,捕获到关键报错信息:runtime/cgo: pthread_create failed:Resource temporarily unavailable,这表明系统资源不足。其中Calico组件表现为持续重启。

-
定位资源瓶颈
针对资源不足的报错,结合cgroup报错信息和系统内核参数配置排查,发现cgroup.pids.max的当前配置值为65535。进一步检查问题节点上的业务Pod线程数,发现单个Pod的线程数就达到了1600-1800个。该节点运行了30多个业务Pod,线程占用总量远超65535的限制,从而确认线程资源耗尽是导致组件无法创建新线程、进而引发Calico不断重启的根本原因。
- 进入业务Pod查看线程数:
ps -T -p <pid> | wc -l (显示启动了1600多个线程)
- 查看cgroup的pids限制:
cat /sys/fs/cgroups/pids/kubepods/pids.max (显示为65535)
- 查看当前已使用值:
cat /sys/fs/cgroups/pids/kubepods/pids.current (显示为64413,此值为删除部分Pod后的值,故障时已触达上限)
-
调整系统参数
调整系统参数,重新设置pids_max与fs.file-max的值:
pids_max=2000000
fs.file-max=2000000
参数调整后,各系统组件运行恢复正常,Calico成功启动。
-
出现新问题:Pod网络不通
Calico启动正常后,出现了新的问题——Pod网络无法ping通。检查基础网络配置(如MTU)、路由表等均正常,排除了底层网络故障。通过tcpdump抓包分析发现:从主机ping容器,容器能收到包并发出响应,但主机收不到回包;从容器ping主机,主机则无任何响应。由此初步推测是iptables规则导致了流量被丢弃。
-
确认Calico后端模式
查看故障节点的Calico日志,发现其绑定的后端规则为iptables。
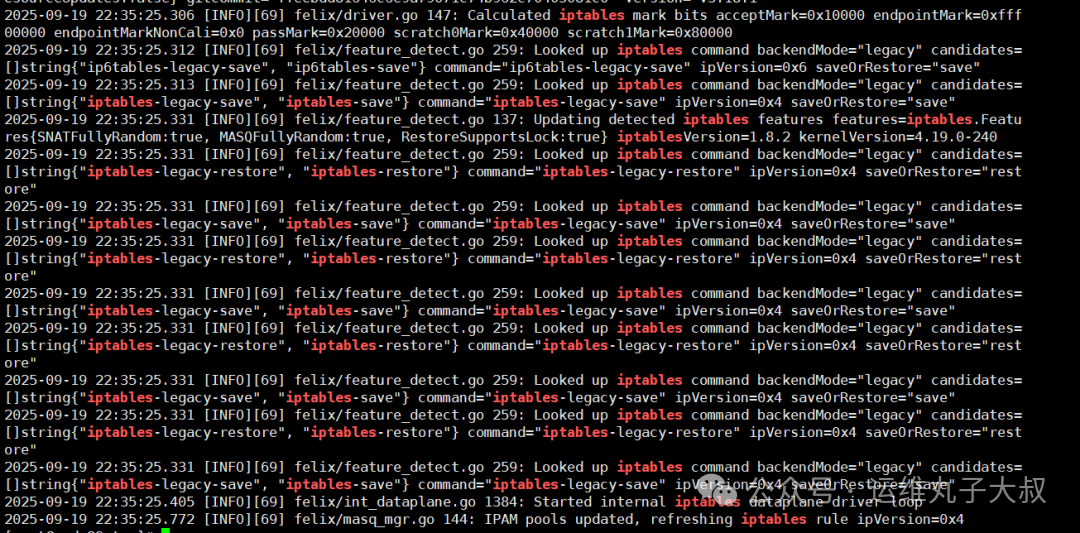
-
验证推断
为了验证是iptables规则导致的问题,尝试清空节点的iptables规则:iptables -F。规则清除后,Pod网络立即恢复畅通,这基本定位了问题根源。
-
规则下发异常
重启Calico服务,期望其重新下发正确的网络规则。但发现iptables规则并未被刷新,通过iptables -L -n命令查看不到任何Calico相关的规则。问题变得清晰:Calico的后端虽然是iptables,但它下发的规则并没有成功写入iptables,导致流量被默认策略(或残留规则)丢弃。
-
临时恢复与发现
重启异常服务器节点后,Pod网络访问恢复正常。再次查看Calico日志,发现此时Calico使用的后端变成了nft(Netfilter的下一代框架)。
-
深入代码分析
对Calico v3.18.1的代码进行分析发现,Calico在未明确指定规则后端(FELIX_IPTABLESBACKEND)时,会按照一套固定逻辑自动判断使用iptables还是nft。判断逻辑为:当iptables规则数量大于10条,或者nft规则数量少于iptables规则数量时,都会默认使用iptables后端。
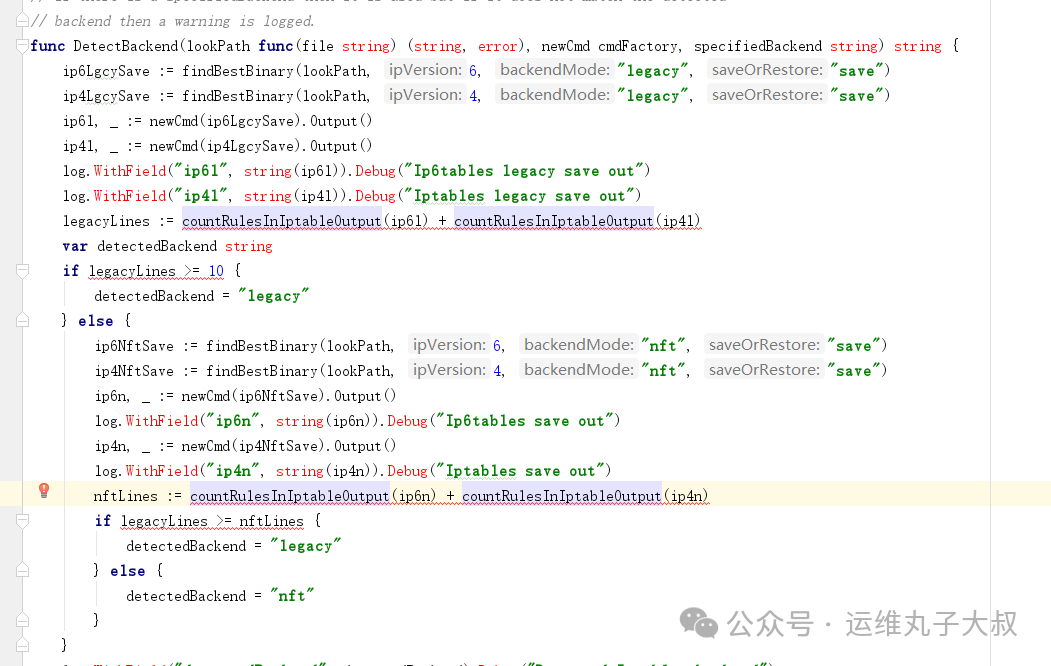 其启动流程是:启动时获取一次后端类型(只探测一次),如果此时因为资源问题(如
其启动流程是:启动时获取一次后端类型(只探测一次),如果此时因为资源问题(如fork进程失败)导致探测出错,有极大概率会走入默认优先级更高的iptables路径。之后,Calico会循环尝试更新iptables规则。一旦某次fork成功并插入了iptables规则,后续的流程中,Calico会因为能获取到已有的iptables规则而持续进入iptables模式。
-
根因串联
问题的完整链条如下:
- 大量业务Pod更新,瞬间创建海量线程,超过系统
pids.max限制。
- 线程资源耗尽导致
kubelet、kube-proxy、Calico运行异常。kubelet和kube-proxy使用宿主机工具链,而运行在Docker容器中的Calico使用的是镜像自带的iptables/nft客户端。
- 在资源极度紧张、
fork进程频繁失败的情况下,Calico的后端自动判断逻辑出错,误入了iptables模式。
- 一旦进入该模式并生成了部分iptables规则,就形成了“路径依赖”,即使后续系统资源恢复,Calico也会基于已有的iptables规则持续判断错误,无法切换回集群本该使用的
nft后端。
- 故障前主机上已生效的
nft规则并未被清理,新建Pod的网卡因名称前缀无法匹配旧的nft规则链而导致流量被拦截。



问题原因
- 直接原因:业务Pod批量更新时,线程数瞬时暴涨,总量远超
cgroup.pids.max(65535)的限制,导致Calico存活探针等操作因无法创建线程而失败,引发组件持续重启。
- 根本原因:在线程资源耗尽的异常状态下,Calico的后端自动判断逻辑失效,误绑定到
iptables模式。且由于“判断惯性”,在资源恢复后仍无法自纠正,持续向错误的iptables后端下发规则(实际未成功),而集群实际生效的是残留的旧nft规则,新旧规则混杂导致新建Pod网络不通。
解决措施
- 应急处理:调整系统
pids_max和fs.file-max参数,解决资源瓶颈,使Calico等组件恢复正常运行。
- 恢复网络:重启故障服务器节点,迫使Calico重新进行后端探测,从而切换回正确的
nft模式。
- 配置固化:修改Calico的DaemonSet配置,显式指定环境变量
FELIX_IPTABLESBACKEND为"nft",避免再次发生自动判断错误。
后续建议
- 显式指定后端:在Calico部署清单中,明确设置后端模式,杜绝自动判断带来的不确定性。
containers:
- name: calico-node
env:
- name: FELIX_IPTABLESBACKEND
value: "nft" # 明确指定后端为nft
updateStrategy:
type: OnDelete # 建议使用OnDelete策略,避免DaemonSet修改触发全量滚动更新
- 完善监控告警:建立对主机节点线程数、进程数等关键资源的监控,并设置合理的阈值告警,以便提前发现资源瓶颈。
- 规范变更流程:制定业务Pod批量更新预案,控制并发更新速率,避免大量Pod同时创建线程导致系统资源瞬间被击穿。
|  发表于 2025-12-5 13:57:24
|
查看: 173|
回复: 0
发表于 2025-12-5 13:57:24
|
查看: 173|
回复: 0
