与 Claude Code 等同类工具相比,OpenClaw 有一个显著且独有的特性,那就是它的记忆系统。
很多介绍都会提到 OpenClaw 的记忆能力:它能记住你的工作习惯和偏好,理解项目的长期背景,并且随着时间推移,它会越来越懂你。这些说法都没错,但关键在于它是如何做到的。
按照常规思路,要让 AI 助手了解我们,最常见的方法就是把所有个性化信息一股脑儿塞进提示词里,每次提问时都把这些上下文喂给大模型。但这样做立刻会陷入一个两难境地:信息塞少了怕它不了解你,信息塞多了又太浪费 Token 成本,甚至可能直接超出模型的上下文窗口限制。
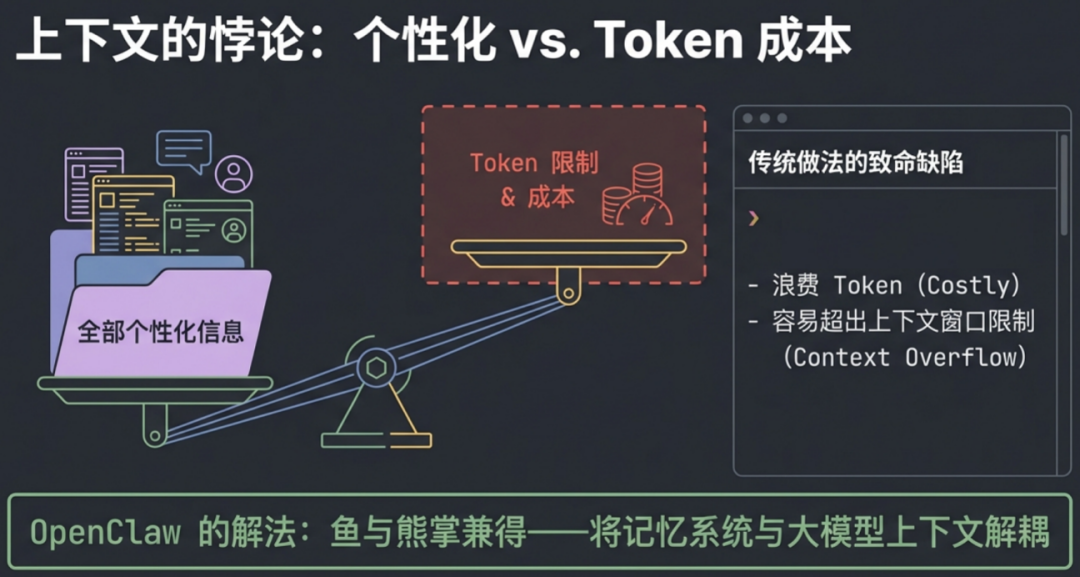
OpenClaw 的解法非常巧妙且经济:它将大模型的上下文与独立的记忆系统进行解耦管理。这套记忆系统基于两种文件:
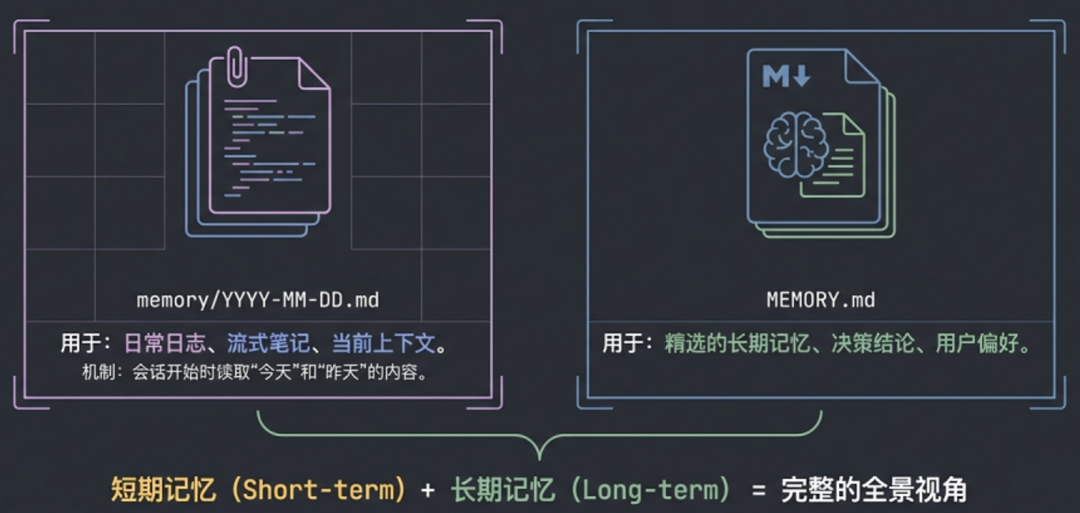
- 短期记忆文件:每天产生的日志和当前上下文,保存为
memory/YYYY-MM-DD.md。在每次会话开始时,会自动读取“今天”和“昨天”的文件内容。
- 长期记忆文件:精选的、需要持久化的决策、结论和用户偏好,保存为根目录下的
MEMORY.md 文件。
短期记忆结合长期记忆,构成了对用户和工作全景视角的记录。
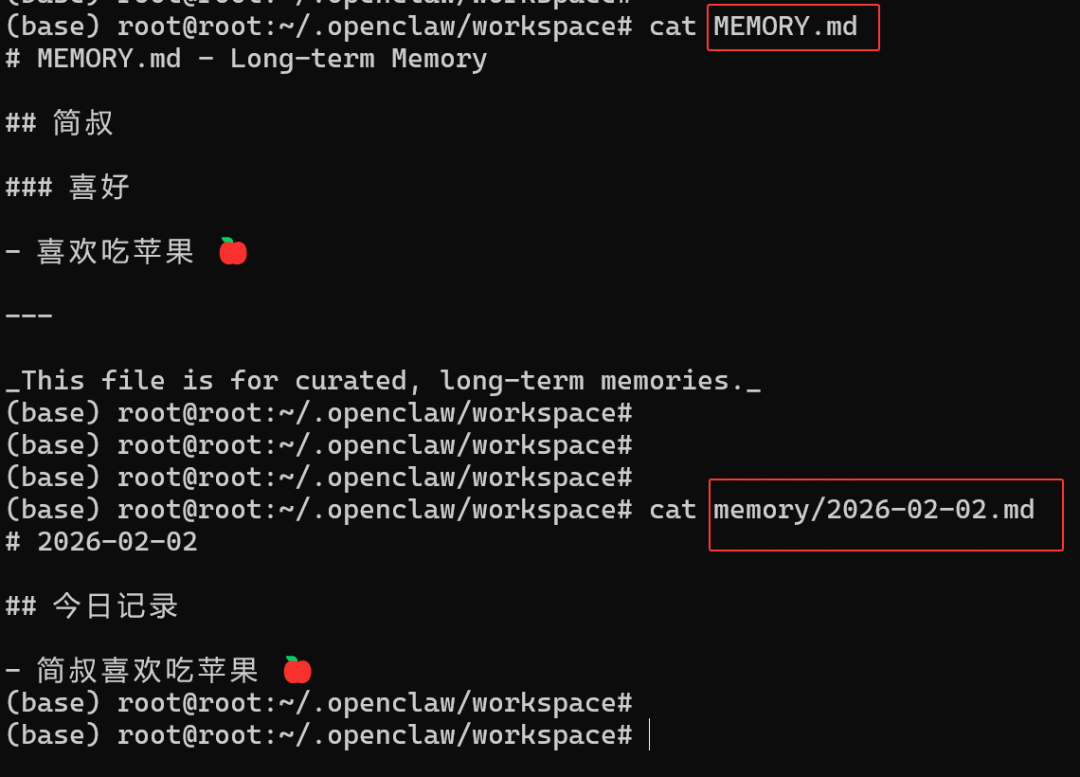
那么,这些文件何时被写入呢?决策、偏好和需要长期记住的事实会存入 MEMORY.md;日常的笔记和临时的上下文则存入对应的日期文件中。这个过程是后台静默更新的,随着你持续使用 OpenClaw,这两个文件会不断累积你的个性化信息。你也可以主动要求它记录某些内容,例如直接告诉它:“我喜欢吃苹果,把这个信息记下来。”

有了这些文件,OpenClaw 在回答问题时就有了参考依据。但文件内容会越来越多,每次回答并不需要全部信息。因此,它采用了检索(RAG) 的方式:根据用户当前的问题,去记忆文件中查找最相关的片段(比如历史偏好、同类问题的解决方案等)。
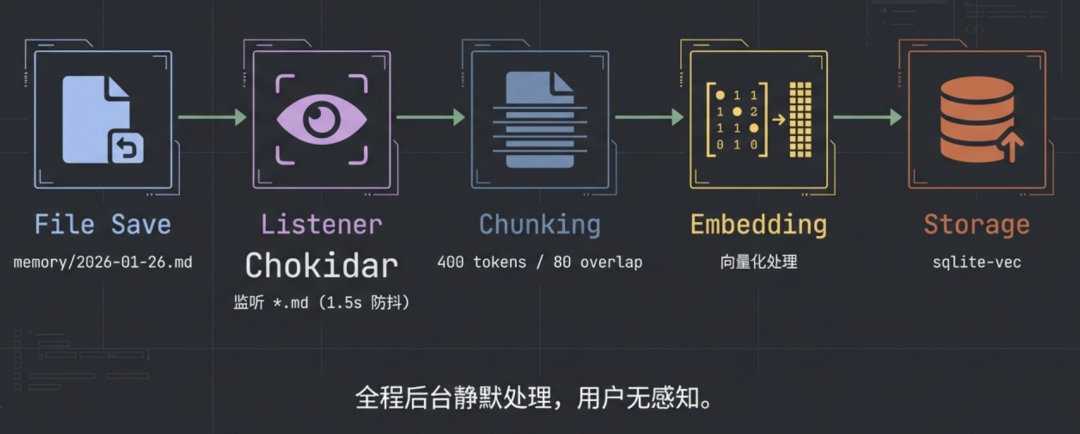
为了实现高效检索,OpenClaw 在后台为 MEMORY.md、memory/*.md 等文件建立了一个小型的向量索引(使用 sqlite-vec 向量数据库)。向量化的流程是自动触发的:
- 监听文件保存:使用 Chokidar 监听
.md 文件的保存事件,并设置 1.5 秒防抖。
- 文本分块:将文件内容按 400 个 Token、80 个 Token 重叠的方式进行分块。
- 向量化处理:将文本块转化为向量。
- 存储:将向量存入
sqlite-vec 数据库。
整个过程在后台静默完成,用户无感知。
那么,当用户提问时,OpenClaw 具体如何检索呢?它内置了两个核心工具:memory_search 和 memory_get。
memory_search 是一个强制性的信息回溯步骤。它的描述明确指出:在回答任何涉及过往工作、决策、日期、人员、偏好或待办事项的问题之前,必须先对记忆文件进行语义搜索。其参数配置决定了召回结果:
maxResults:决定最终召回几个文档分片。minScore:指定召回文档分片的最小相似度阈值,默认 0.35。
{
"name": "memory_search",
"description": "Mandatory recall step: semantically search MEMORY.md + memory/*.md before answering questions about prior work, decisions, dates, people, preferences, or todos",
"parameters": {
"query": "What did we decide about the API?",
"maxResults": 6,
"minScore": 0.35
}
}
memory_get 工具则用于在 memory_search 找到相关内容后,精确读取特定文件的指定行内容。
{
"name": "memory_get",
"description": "Read specific lines from a memory file after memory_search",
"parameters": {
"path": "memory/2026-01-20.md",
"from": 45,
"lines": 15
}
}
通过这两个工具的配合,OpenClaw 能精准定位并提取出与当前问题最相关的记忆片段,然后将这些片段作为上下文注入系统提示词,最终提交给大模型生成结合了“个性化记忆”的回答。
而让这套检索机制更加精准的核心,在于其混合检索(Hybrid Search) 策略,即同时使用 BM25 关键词检索和向量语义检索。
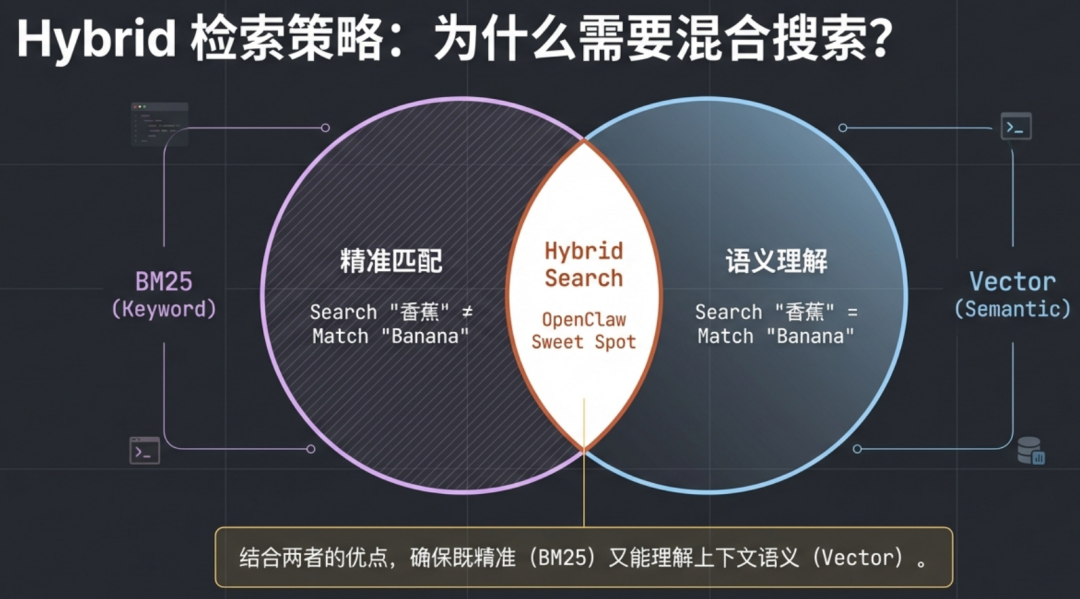
BM25 擅长精准的关键词匹配。例如,搜索“香蕉”只会匹配包含“香蕉”这个词的文档,对于包含“banana”的文档则无能为力。
向量检索则基于语义理解。经过训练的嵌入模型知道“香蕉”和“banana”语义相近,因此搜索“香蕉”时,包含“banana”的文档也能被匹配到。
混合检索结合了两者的优点,确保在从海量记忆文件中查找相关信息时,既能做到精准匹配关键词,又能理解上下文语义,从而让 OpenClaw 显得“更懂你”。
在配置层面,OpenClaw 提供了细致的参数来控制混合检索的行为:
agents:
defaults:
memorySearch:
query:
hybrid:
enabled: true
vectorWeight: 0.7
textWeight: 0.3
candidateMultiplier: 4
其检索与评分流程如下图所示:
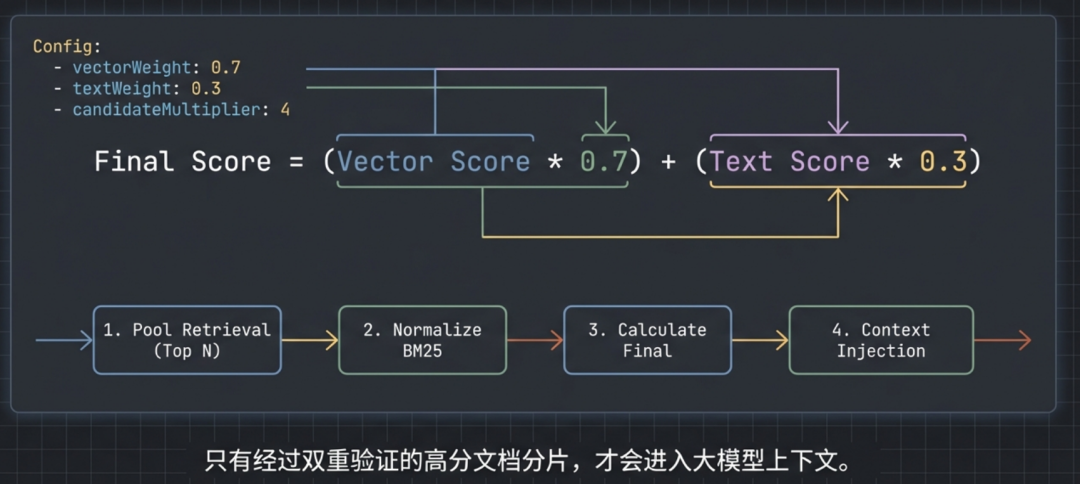
具体步骤分解如下:
-
候选池检索:
- 向量检索:按余弦相似度排序,取前
maxResults * candidateMultiplier 个候选。
- BM25 检索:按 FTS5 BM25 排名排序,同样取前
maxResults * candidateMultiplier 个候选。
-
分数归一化:将 BM25 排名转换为 0 到 1 之间的分数。
textScore = 1 / (1 + max(0, bm25Rank))
-
计算加权最终分:按文档分片 ID 合并候选,并计算加权得分。
finalScore = vectorWeight * vectorScore + textWeight * textScore
-
上下文注入:根据 finalScore 排序,仅将经过双重验证的高分文档片段注入大模型上下文。
通过这种独立于大模型上下文的记忆系统,以及背后高效、精准的混合检索机制,OpenClaw 得以持续沉淀用户的个性化信息,并在每次交互中智能地调用相关记忆。这正是它能实现“越用越懂你”体验的技术基石。这种将长期记忆与智能检索解耦的设计思路,为构建更懂用户的智能助手提供了宝贵的实践参考。
 发表于 2026-2-11 21:39:51
|
查看: 448|
回复: 0
发表于 2026-2-11 21:39:51
|
查看: 448|
回复: 0
