SpringBoot+Cloud项目学习可参考:macrozheng.com
线上事故回顾
前段时间,团队上线一个特别简单的功能。晚上上线前 review 代码时,或许是想到了公司“拼搏进取”的价值观,我临时起意,加了一行 log 日志。当时觉得,区区一行日志,能有什么大问题?
结果呢?代码刚部署上线,报警信息就炸了锅。我手忙脚乱地赶紧回滚,定位到问题根源,正是那行“无辜”的日志代码。删除它之后重新上线,一切才恢复平静。
这个故事听起来像段子,但它真实地发生在了线上环境。一行日志,怎么就引发了 P1 级别的故障?这背后,其实藏着一个关于 Java 序列化的隐蔽陷阱。
情景还原
我们通过一段简单的代码来复现这个场景。
定义了一个 CountryDTO
public class CountryDTO {
private String country;
public void setCountry(String country) {
this.country = country;
}
public String getCountry() {
return this.country;
}
public Boolean isChinaName() {
return this.country.equals("中国");
}
}
定义测试类 FastJonTest
public class FastJonTest {
@Test
public void testSerialize() {
CountryDTO countryDTO = new CountryDTO();
String str = JSON.toJSONString(countryDTO);
System.out.println(str);
}
}
运行这段测试代码,会直接抛出 空指针 错误:
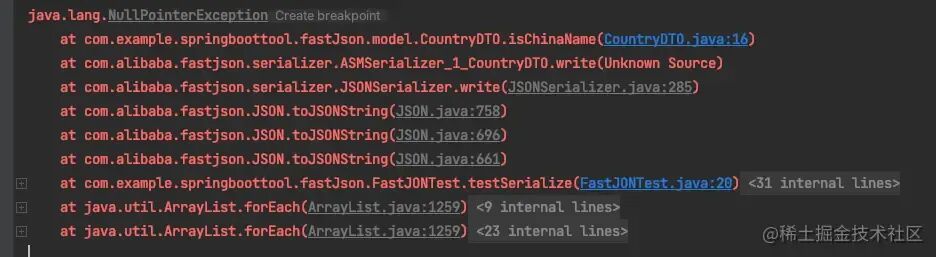
从堆栈信息可以清晰地看到,问题出在序列化过程中执行了 isChinaName() 方法。而此时 this.country 变量为 null。
问题来了:
- 序列化为什么会执行
isChinaName() 呢?
- 引申一下,序列化过程中到底会执行哪些方法?
源码分析
通过调试观察调用链路的堆栈信息,我们可以追踪问题的执行路径。
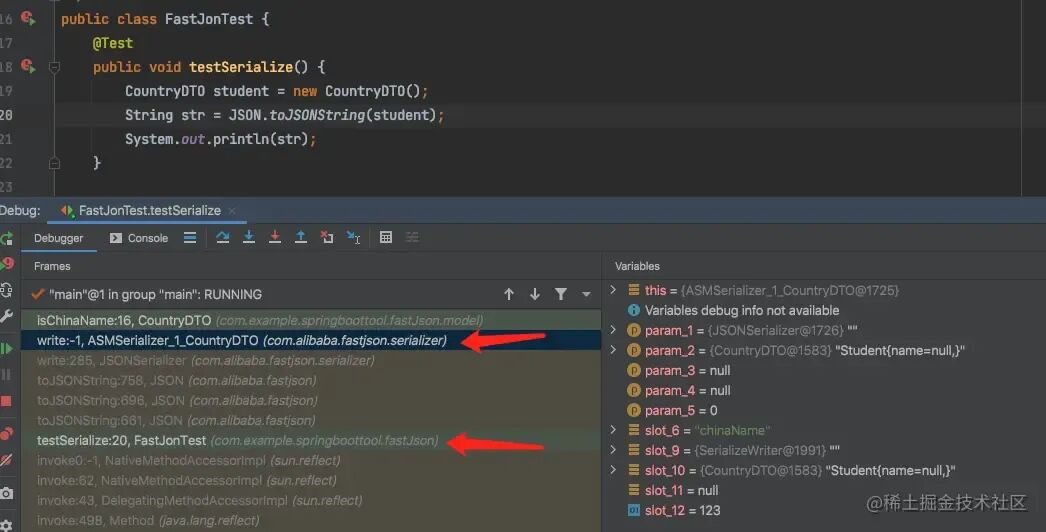
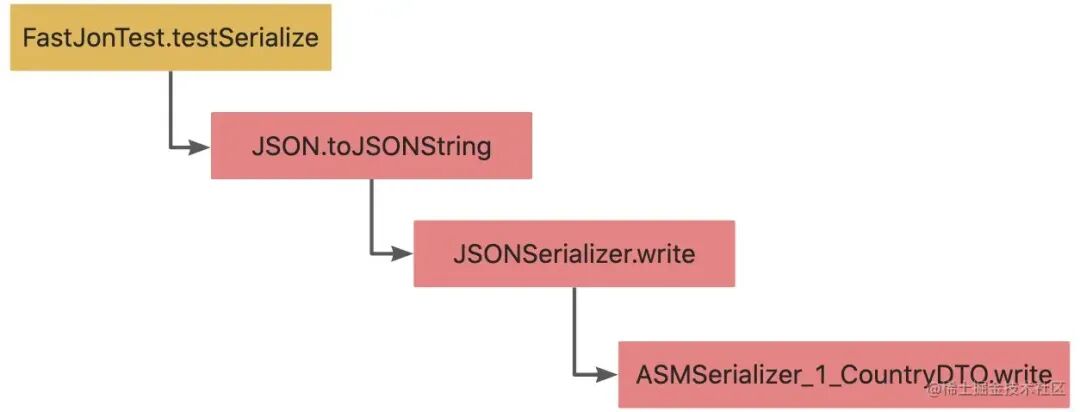
调用链中的 ASMSerializer_1_CountryDTO.write 是 FastJson 使用 asm 技术动态生成的类。
asm技术其中一项使用场景就是通过动态生成类来代替 java 反射,从而避免重复执行时的反射开销。
JavaBeanSerizlier序列化原理
从下图可以看出,序列化的核心是调用 JavaBeanSerializer 类的 write() 方法。
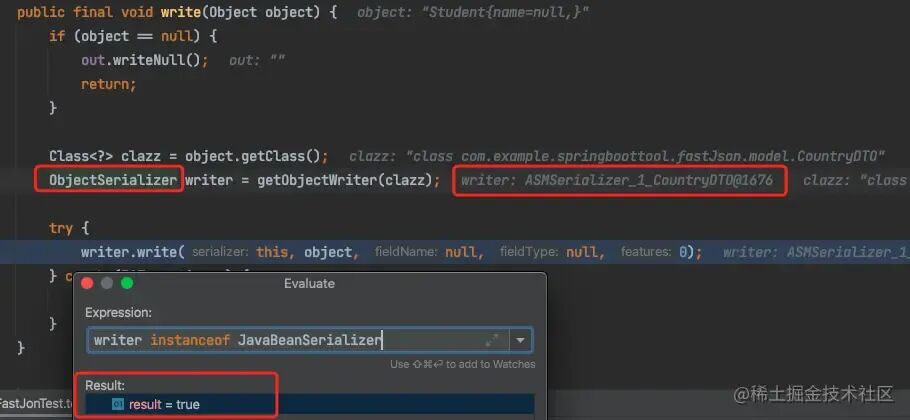
而 JavaBeanSerializer 主要是通过 getObjectWriter() 方法获取的。通过深入调试 getObjectWriter() 的执行过程,我们可以定位到关键方法 com.alibaba.fastjson.serializer.SerializeConfig#createJavaBeanSerializer,进而找到最核心的逻辑所在:com.alibaba.fastjson.util.TypeUtils#computeGetters。
public static List<FieldInfo> computeGetters(Class<?> clazz, //
JSONType jsonType, //
Map<String,String> aliasMap, //
Map<String,Field> fieldCacheMap, //
boolean sorted, //
PropertyNamingStrategy propertyNamingStrategy //
) {
//省略部分代码....
Method[] methods = clazz.getMethods();
for(Method method : methods){
//省略部分代码...
if(method.getReturnType().equals(Void.TYPE)){
continue;
}
if(method.getParameterTypes().length != 0){
continue;
}
//省略部分代码...
JSONField annotation = TypeUtils.getAnnotation(method, JSONField.class);
//省略部分代码...
if(annotation != null){
if(!annotation.serialize()){
continue;
}
if(annotation.name().length() != 0){
//省略部分代码...
}
}
if(methodName.startsWith("get")){
//省略部分代码...
}
if(methodName.startsWith("is")){
//省略部分代码...
}
}
}
从这段核心代码可以看出,FastJson 在计算需要序列化的 getter 时,大致分为三种情况:
- 带有
@JSONField(serialize = false, name = "xxx") 注解的方法(根据注解属性决定)。
- 以
get 开头的方法。
- 以
is 开头的方法。
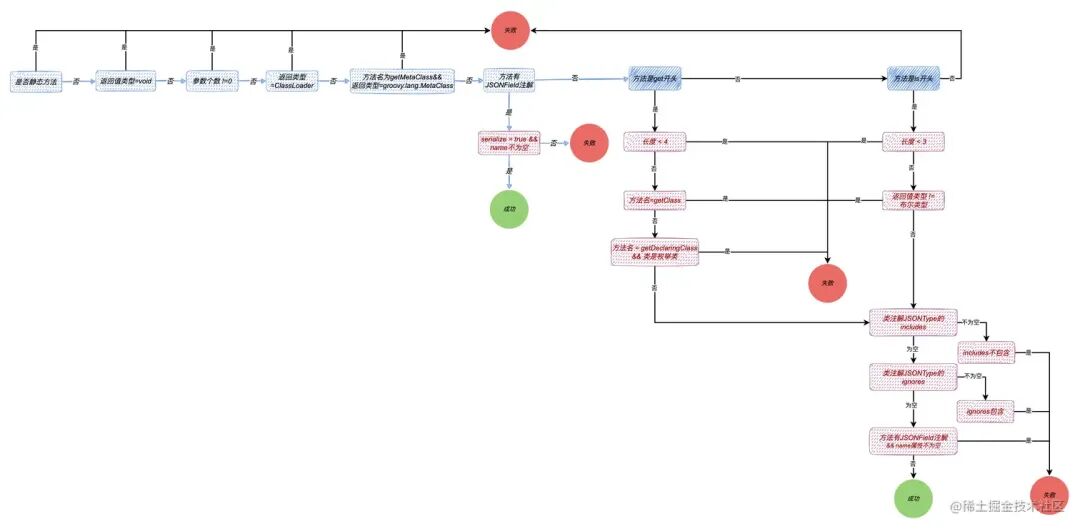
序列化流程图
整个方法筛选的逻辑相当复杂,下图清晰地展示了其决策流程:
示例代码
为了验证上述规则,我们编写了如下包含多种情况的测试类:
/**
* case1: @JSONField(serialize = false)
* case2: getXxx()返回值为void
* case3: isXxx()返回值不等于布尔类型
* case4: @JSONType(ignores = "xxx")
*/
@JSONType(ignores = "otherName")
public class CountryDTO {
private String country;
public void setCountry(String country) {
this.country = country;
}
public String getCountry() {
return this.country;
}
public static void queryCountryList() {
System.out.println("queryCountryList()执行!!");
}
public Boolean isChinaName() {
System.out.println("isChinaName()执行!!");
return true;
}
public String getEnglishName() {
System.out.println("getEnglishName()执行!!");
return "lucy";
}
public String getOtherName() {
System.out.println("getOtherName()执行!!");
return "lucy";
}
/**
* case1: @JSONField(serialize = false)
*/
@JSONField(serialize = false)
public String getEnglishName2() {
System.out.println("getEnglishName2()执行!!");
return "lucy";
}
/**
* case2: getXxx()返回值为void
*/
public void getEnglishName3() {
System.out.println("getEnglishName3()执行!!");
}
/**
* case3: isXxx()返回值不等于布尔类型
*/
public String isChinaName2() {
System.out.println("isChinaName2()执行!!");
return "isChinaName2";
}
}
运行测试后,控制台输出结果为:
isChinaName()执行!!
getEnglishName()执行!!
{"chinaName":true,"englishName":"lucy"}
结果分析:
isChinaName() 和 getEnglishName() 被成功序列化。getEnglishName2() 因为 @JSONField(serialize = false) 被排除。getEnglishName3() 因为返回 void 被排除。isChinaName2() 因为返回值不是布尔类型被排除。getOtherName() 因为被 @JSONType(ignores = "otherName") 忽略。queryCountryList() 因为是静态方法,在 clazz.getMethods() 中不会被返回(实际上,即使返回,也会因为参数个数不为0被过滤)。
代码规范
从上面的分析可以看出,序列化的规则相当繁杂:有时需要关注返回值类型,有时要看参数个数,有时又涉及 @JSONType 或 @JSONField 注解。
当一个功能的实现逻辑存在多种判断路径时,由于团队成员对技术细节的掌握程度参差不齐,这种“认知方差”极易导致代码问题。因此,最佳实践是确立一种团队内推荐且统一的方案。
这里强烈推荐使用 @JSONField(serialize = false) 来显式地标注不参与序列化的方法。下面是用推荐方案重构后的代码,哪些方法被排除在序列化之外,是不是一目了然?
public class CountryDTO {
private String country;
public void setCountry(String country) {
this.country = country;
}
public String getCountry() {
return this.country;
}
@JSONField(serialize = false)
public static void queryCountryList() {
System.out.println("queryCountryList()执行!!");
}
public Boolean isChinaName() {
System.out.println("isChinaName()执行!!");
return true;
}
public String getEnglishName() {
System.out.println("getEnglishName()执行!!");
return "lucy";
}
@JSONField(serialize = false)
public String getOtherName() {
System.out.println("getOtherName()执行!!");
return "lucy";
}
@JSONField(serialize = false)
public String getEnglishName2() {
System.out.println("getEnglishName2()执行!!");
return "lucy";
}
@JSONField(serialize = false)
public void getEnglishName3() {
System.out.println("getEnglishName3()执行!!");
}
@JSONField(serialize = false)
public String isChinaName2() {
System.out.println("isChinaName2()执行!!");
return "isChinaName2";
}
}
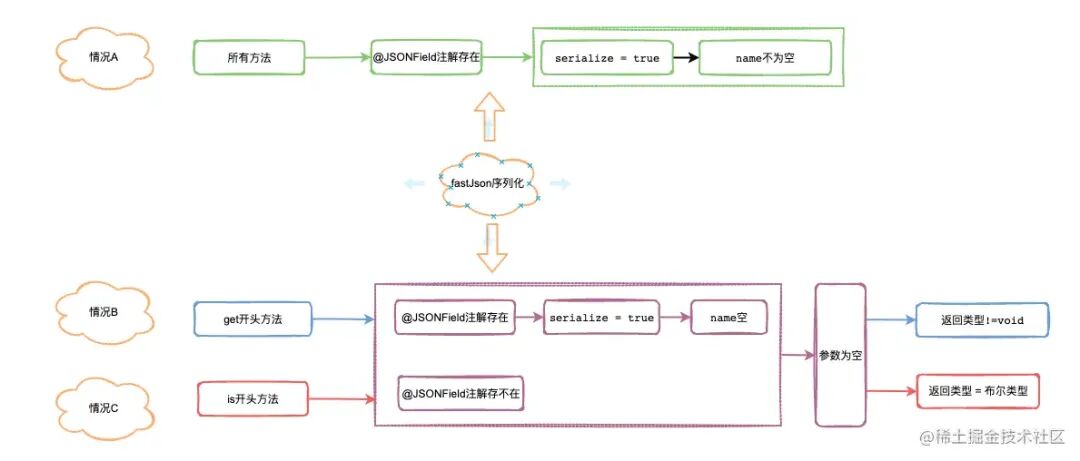
三个频率高的序列化的情况
下图总结了三种高频的序列化规则判断场景:
回顾整个分析过程,我们基本遵循了 发现问题 --> 原理分析 --> 解决问题 --> 提炼规范(编程规范) 的技术探究路径。
这种思考方式可以延伸到更广的维度:
- 围绕业务:解决问题 -> 如何选择最优解决方案 -> 优秀方案如何复用到 N 个系统中。
- 围绕技术:解决单个具体问题 -> 沿着问题链条深入掌握其底层原理。
无论是业务还是技术,深挖一层,往往能获得超出预期的收获。在 云栈社区 的后端 & 架构和数据库/中间件/技术栈等板块,经常有开发者分享类似的深度踩坑与调优经验,值得借鉴。
作者:老鹰汤
来源:juejin.cn/post/7156439842958606349
目前星球内有两套教程(文档+视频),涵盖Spring Boot到Spring Cloud的学习。
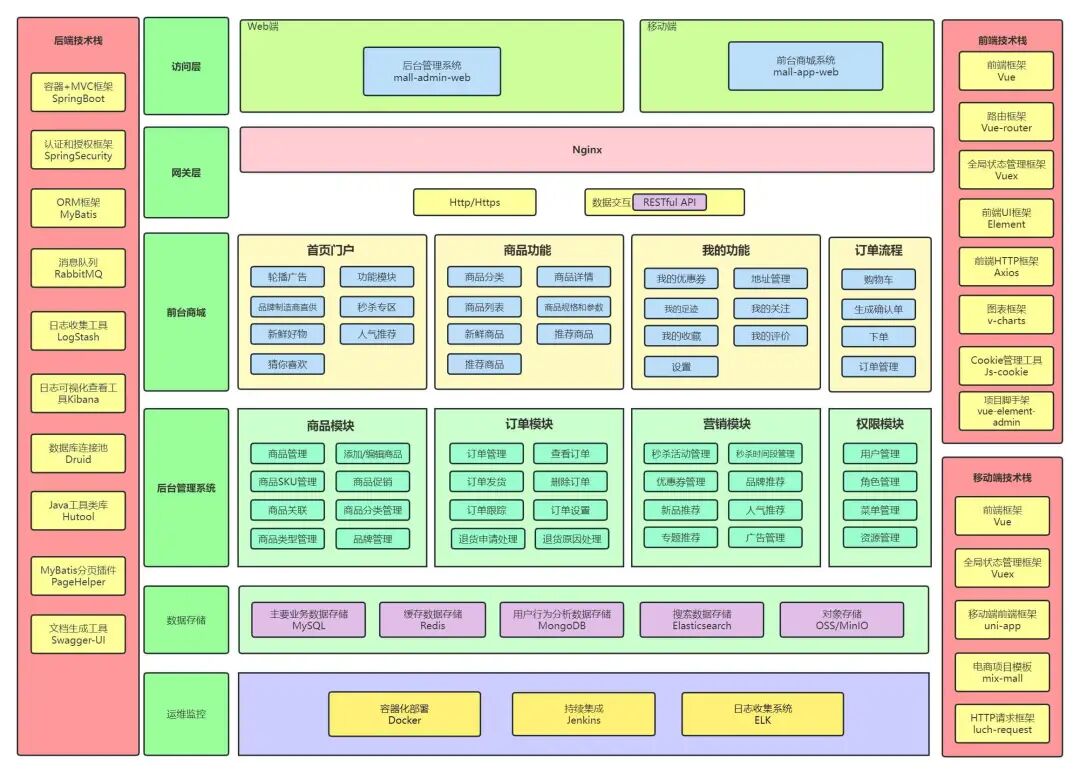
项目的微服务架构图如下!
 发表于 2026-3-10 07:00:06
|
查看: 169|
回复: 0
发表于 2026-3-10 07:00:06
|
查看: 169|
回复: 0
