在构建企业级知识库时,RAG (Retrieval-Augmented Generation) 已成为业界主流方案。它通过将外部知识库与 大语言模型 结合,有效缓解了模型幻觉、知识滞后等问题。然而,随着业务规模扩大和文档数量激增,许多团队会发现系统响应变慢、推理成本增加、资源利用率下降。这通常不是 RAG 架构本身的问题,而是 工程实现层面的优化空间尚未被充分挖掘。
RAG的典型工作流程回顾
一个典型的RAG流程通常包含以下步骤:
- 预处理阶段:将静态文档(如PDF、Word)切分为文本块,通过嵌入模型(Embedding Model)转化为向量,并存入向量数据库(如Pinecone、Milvus等)。
- 查询阶段:用户提问 → 问题被编码为向量 → 向量数据库执行近似最近邻搜索(ANN)→ 返回最相关的若干文本块。
- 生成阶段:将检索结果拼接为上下文,输入大语言模型(LLM),生成最终回答。
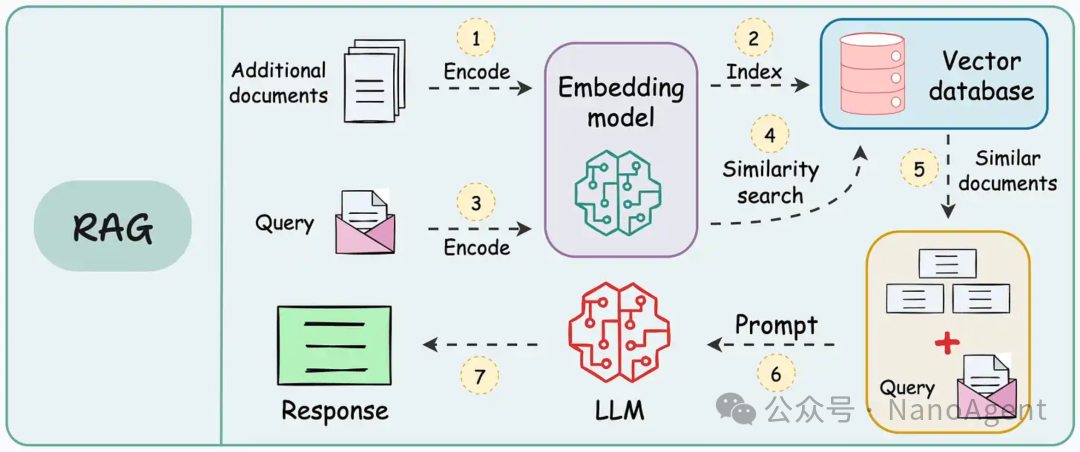
在实际工程化落地中,若缺乏精细化设计,这个流程可能引发几个显著问题:
- 成本上升:高频问题反复触发完整的 RAG 流程,消耗大量 Token,带来高昂的API成本。
- 延迟增加:召回内容过长、检索过程未优化,导致首字输出时间(Time to First Token)显著拉长,影响用户体验。
- 计算冗余:相同或语义相似的问题被反复编码、检索和推理,造成算力资源的浪费。
缓存增强的RAG:给系统装上“记忆”
如果说原始 RAG 是考试时每次都要翻书查答案,那么结合缓存机制的增强型 RAG,就像把常识和重点直接记在心里——无需每次都查资料,能直接给出精准回应。缓存主要可以从三个层面切入:
1. 结果缓存
这是最直接的方式。对于高频、稳定且答案确定的问答对(例如“年假怎么休?”“报销流程是什么?”),直接缓存最终生成的回答。
- 优势:缓存命中时,能跳过整个检索与生成流程,实现毫秒级响应,并且 Token 消耗为零。
2. 检索结果缓存
缓存“问题 → 检索到的相关文档片段”的映射关系。即使生成环节需要根据最新指令微调,也可以复用之前检索到的上下文。
- 优势:避免了重复的向量相似度查询,显著降低了向量数据库的负载和查询延迟。
3. 嵌入缓存
缓存用户问题或文档片段的嵌入向量,避免对相同或相似的文本内容重复调用 Embedding 模型。
- 优势:节省宝贵的 CPU/GPU 计算资源,尤其在高并发查询场景下收益非常明显。
构建高效的知识缓存体系:冷热数据分层
要最大化缓存的收益,关键在于对知识进行“冷、温、热”分层治理。这种分层策略不仅能提升性能,还能显著优化成本。实测数据表明,引入结果缓存后,高频问答的 Token 消耗可下降 76%,平均响应时间从 1.8 秒降至 0.2 秒。

如上图所示:
- 热数据:实时性强、频繁更新(如今日库存、最新公告)。处理策略是走全流程 RAG,确保信息绝对新鲜。
- 温数据:中频访问、偶有变更(如季度政策、项目文档)。处理策略是“检索 + 结果缓存”,设置 TTL(生存时间)自动失效。命中缓存则直接返回,失效则重新走流程生成。
- 冷数据:低频访问、长期稳定(如公司愿景、基础制度)。处理策略是“语义直出”,匹配到关键词或语义后,直接从键值缓存(K-V Cache)返回标准答案,完全绕过模型推理。
缓存需有策略:不是所有数据都值得缓存
缓存虽好,但不能滥用。其核心原则是:只缓存那些 “高价值、高频率、长效性” 的知识。滥用缓存反而会适得其反,因此在实施时需注意:
- 控制缓存规模:对于低频或长尾问题,缓存命中率极低,强行缓存只会徒增内存开销。
- 必须设置 TTL:确保知识源更新后,缓存能及时失效,避免用户读到过时或错误的信息。
- 建立监控机制:持续跟踪缓存命中率、节省的 Token 数、错误率等核心指标,基于数据驱动进行策略优化。
- 结合语义去重:利用向量相似度技术,识别语义相近但表述不同的问题,从而扩大缓存的覆盖范围,提升命中率。
构建真正好用的RAG系统
RAG 让大模型拥有了“查资料”的能力,而缓存机制则赋予它“长记性”的智慧。两者的紧密结合,标志着企业知识系统从“功能可用”迈向“体验丝滑、成本可控、运维可靠”的工程化新阶段。
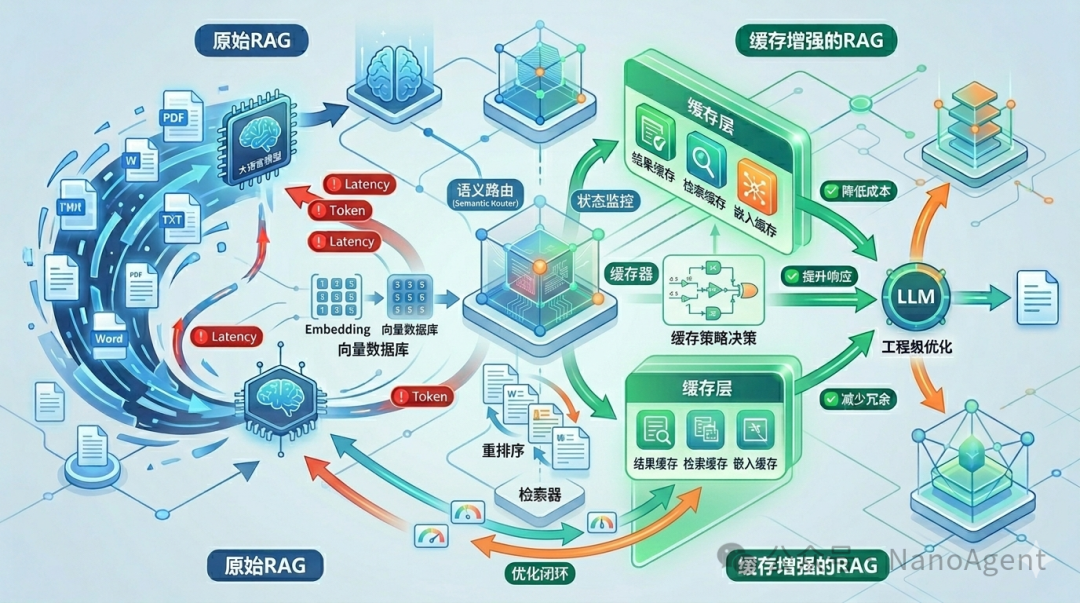
从架构图可以看出,缓存增强的 RAG 通过引入缓存层和智能策略决策,形成了一个“降低延迟、提升响应、减少冗余”的优化闭环。
随着模型上下文窗口的扩大和推理效率的提升,RAG 与缓存的协同将更加紧密。但无论底层技术如何演进,精细化的数据治理、场景化的架构设计、持续的性能监控,始终是构建高效、稳健 RAG 系统的三大基石。对于追求极致性能与成本平衡的团队而言,这已不是一道选择题,而是一门必须掌握的工程必修课。如果你想了解更多系统架构与性能调优的实践经验,欢迎在云栈社区与同行们交流探讨。 |  发表于 2026-3-10 07:03:08
|
查看: 252|
回复: 0
发表于 2026-3-10 07:03:08
|
查看: 252|
回复: 0
