你构建过的每一个 AI agent 几乎都有同一个致命缺陷。
你花一小时讲解项目架构、编码偏好、部署约束。AI 任务完成得很漂亮。你关掉标签页。第二天回到同一页,它对你是谁一无所知。
这不是小毛病,而是大模型工作方式里写死的架构问题。LLM 天生是无状态的。会话一结束,一切化为乌有:你的偏好、项目历史、你为让它理解认证方案而花的三个小时,全都没了。
行业多年来主要有两种应对思路。其一是蛮力:往更大的上下文窗口里塞更多的 token。现在的模型一次 prompt 能接收上百万 token。但更大的窗口填充成本高昂,而且研究一再表明,模型很容易丢掉埋在庞大提示词深处的关键信息。“中间丢失”问题是真实存在的,只是不断加大上下文并不能修复底层的检索失败。
第二种思路是基于向量数据库的 RAG(Retrieval-Augmented Generation,检索增强生成)。把对话以 embedding 形式存起来,需要时按语义相似检索片段。对于基础回忆这确实有效。但扁平的向量检索在时间推理(“我们上个月对 auth 的决定是什么?不是六个月前那次”)、多跳逻辑,以及那种在数周数月协作里真正有用的细腻偏好跟踪方面,会显得力不从心。
在这道缺口里,2026 年出现了开源世界里最离奇的发布之一。
一位好莱坞女演员、一位比特币 CEO 和一座记忆宫殿走进了 GitHub
2026 年 4 月 5 日,Milla Jovovich 在她本人的 GitHub 账号下推送了一个 Python 仓库。没错,就是那位 Milla Jovovich——出演过《The Fifth Element》(《第五元素》)和《Resident Evil》(《生化危机》)系列的演员。
这个仓库叫 MemPalace。48 小时内,它拿下了 7,000 多个 star。写下这些文字时,star 数已经过 22,000。开发者社区集体愣了一下,互联网则照例给出互联网式反应:有人指出错过了把它命名为 “Resident Eval” 的梗(对 Resident Evil 与 eval 的双关);X 上的 Community Note(社区注释)声称 Jovovich 的参与更偏“概念或宣传”;有位 AI 评论者顺着 commit 历史挖下去,指控这是一场有偿运作。

撇开戏剧化,这里是更接近真实的情况。Jovovich 花了数月做一个游戏项目,被 AI 无法在多次会话间记住她的世界观设定这件事折磨得够呛。她研究了助记术,找到了古希腊的 “Method of Loci”(地点法,即演说家用来背诵长篇演讲的记忆宫殿法),由此构思出一个围绕空间隐喻构建的系统。她的技术合伙人 Ben Sigman(Libre Labs 的 CEO,一家比特币借贷平台)负责工程实现,并以 MIT 许可将其开源发布。
这个起源故事很非常规。但 MemPalace 要解决的问题是真的,而它的方法确实有意思。接下来我们把营销热度放一边,看看架构里哪些东西是实际有用的。
核心理念:别再让 AI 自己决定该记什么
大多数 AI 记忆系统工作方式都差不多。每当你结束对话,系统会提示一个 LLM 去读这次交互、提取关键信息、并存成结构化摘要。Mem0 是这样,Zep 也是这样,Letta 也这样(不过它让 agent 自己管理这个过程)。
问题在于:到底什么重要,是 AI 说了算。它也许会提炼出“用户偏好 PostgreSQL”,却把你为何偏好 PostgreSQL、你考虑过哪些替代方案、以及促成这个决策的具体权衡,整段对话都丢掉了。上下文就此永远消失。下次你期待 AI 给出细致入微的建议,它手里只剩一个事实,没有背后的推理。
MemPalace 反其道而行之:逐字存储一切,并让它变得可检索。
写入阶段不会有 LLM 碰你的数据。原始对话会直接进入本地的 ChromaDB 向量数据库,每个字都被保留。智能不体现在“存什么”,而体现在“怎么组织和检索已存的数据”。
在当下的市场里,这是一个颇为逆势的立场,伴随的权衡我后面会说。但这个理念值得重视,因为 MemPalace 自己的基准测试揭示了一个被 AI 记忆行业悄悄忽视的事实:原始、未压缩文本配合质量不错的 embedding,往往在检索任务上优于精心策划的 LLM 摘要。原因很直接:摘要时你会丢掉大量细粒度细节,而许多具体问题的匹配正需要这些细节。
记忆宫殿到底怎么运作
“宫殿”的隐喻不是纯营销。它直接映射到系统的元数据模式上,这也是你高效使用 MemPalace 的关键。
古希腊演说家会想象一栋建筑,把特定观点放进特定房间。需要回忆时,他们在脑中“走动”,按位置找到对应内容。MemPalace 将同样的原则应用到向量数据库的元数据里,创建了四层空间层级。
- Wings(“翼”) 是顶层。可以把它当作面向一个宽泛领域的整栋建筑。你可以有一个项目专用的 wing(如
orion_project),一个个人笔记的 wing(如 emotions),或者一个客户的 wing(如 acme_corp)。Wings 能防止“交叉污染”:在 orion_project wing 里调试认证代码的 AI,不会误检索到你的私人日记,即使两者词汇上有所重叠。
- Rooms(“房间”) 位于 Wings 之内,代表更聚焦的子域。在
orion_project 这个 wing 里,你可能有 authentication、database、deployment 等 rooms。所有与认证相关的架构决策、bug 与讨论,都会聚类在这一个 room。
- Halls(“走廊”) 是对记忆“类型”的元标签。它用来区分:这是事实陈述?时间事件?用户偏好?系统将内容分为五类:Travel、Work、Health、Relationships、General(旅行、工作、健康、关系、通用)。
- Drawers(“抽屉”) 是原子单元。每个 drawer 都包含一段向量化的原始文本,并带有数值化的“重要性”和“情绪强度”权重。
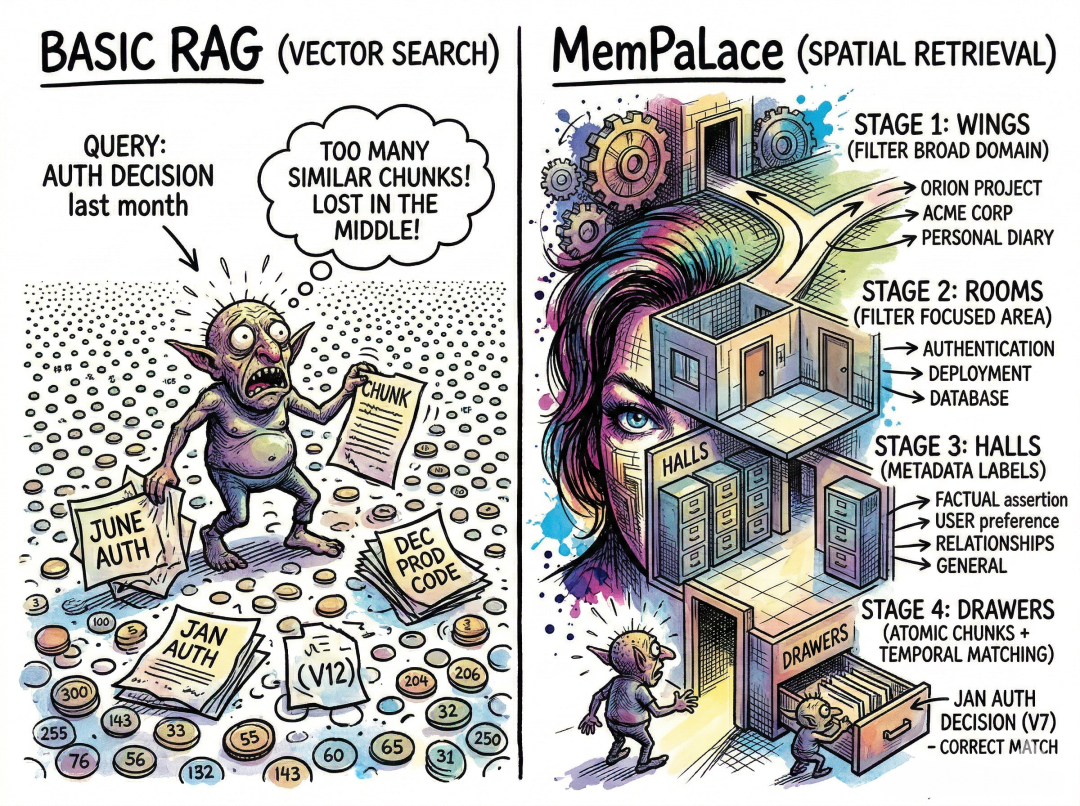
这个空间层级在检索时充当一套预过滤器。与其在整个向量数据库里搜“authentication decisions”,系统会先把范围收敛到特定的 wing 与 room,再在这个受限空间内做语义相似度检索。这个想法很简单,却能有效提升检索准确度,避免那些只是“语义相似但不相关”的结果干扰。
系统还会构建 Tunnels(“隧道”):当不同 wings 里出现相同的 room 名称时,会自动创建交叉引用。如果你在 orion_project 和 nova_project 里都各有一个 authentication room,这条隧道就允许你的 AI 在它们之间穿梭,对比你在不同语境下如何解决同类问题。对长期研发协作来说,这个能力相当实用。
Token 经济学:为何“启动成本”很关键
MemPalace 最强的设计之一,是它的四层记忆栈。这正是系统能为构建 agent 的人带来切实价值的地方。
- Layer 0 是你的 identity 文件。一份很小的文本(约 50–100 tokens),包含你的核心指令、语气风格、行为边界。每次会话都会加载。
- Layer 1 加载整个宫殿里按重要性与情绪权重排序的“Top 15”记忆。大约 500–800 tokens。
- Layer 2 加载与你当前对话主题相关的上下文。比如你开始谈认证,它会从对应的 wing 与 room 里拉取记忆。再花 200–500 tokens。
- Layer 3 是深度检索。跨全量内容做语义相似搜索。只在明确需要时触发。
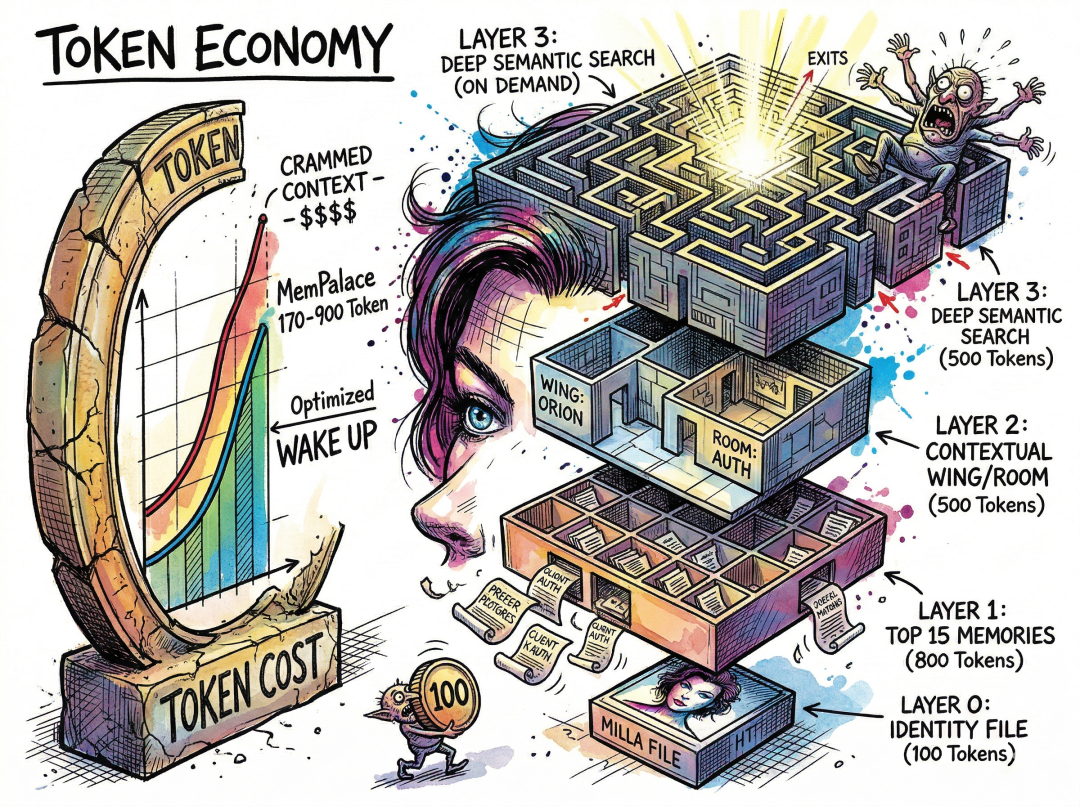
结果是:你的 agent 可以用大约 170–900 个 token “醒来”,却已具备充分的操作上下文。对比那种把完整对话历史一股脑塞进 prompt 的方案。对于按 token 计费的独立开发者来说,这决定了系统是否可用——或者还没让 AI 输出一句话,你的预算就被吞光了。
Letta 也用了类似的分层思路(受计算机内存层级启发:RAM、cache、cold storage),但 Letta 需要通过 LLM 调用来管理交换。MemPalace 则用确定性的 metadata 触发来做切换:更快、更便宜,但在边缘场景下可能不够精确。这个权衡要心里有数。
那些与宣传不符的地方
下面说些大多数博文会跳过的内容。MemPalace 的确存在问题,其中一些够严重,足以影响你是否要投入时间搭建。
- “无损”压缩的说法不成立。 MemPalace 引入了一个名为 AAAK 的“专有压缩语法”,号称“30 倍压缩、零信息损失”。对代码库的独立分析表明,这并不属实。其压缩函数会把内容截断到“最多三个实体、三个主题词、三个情绪码、以及一条最长 55 字符的单句引用”。
decode() 函数并不能还原原文,只是把这种缩略格式再解析成一个字典。MemPalace 自己的基准测试显示,AAAK 压缩文本在检索任务上的得分为 84.2%,而原始文本是 96.6%,下降了 12.4 个百分点。按定义,无损压缩不应降低检索准确率。AAAK 本质是有损摘要,而非压缩。维护者已承认部分问题,包括他们在示例里用的是粗略启发式 token 估算,而不是真正的 tokenizer。
- 100% 基准分是“造”出来的。 LongMemEval 上 96.6% 的基线是真实且可观的,但这是标准的 ChromaDB 对原始文本做向量检索的结果,并非 MemPalace 的空间架构所独有。96.6% 到 100% 的跃升来自定向硬编码。开发者手动检查了系统出错的三个问题,然后写了专门针对这三道题的 regex 模式。一处增强针对了名为 “Rachel” 的问题,另一处搜的是精确短语 “when I was in high school”。项目文档在
BENCHMARKS.md 第 461 行自己也写了:“This is teaching to the test.”(典型的“针对性刷题”)。Ben Sigman 也公开承认,系统的优越性“尚未被证明”。
- “矛盾检测”并不存在。 营销声称系统能“在你看到结果之前就抓出错误的人名、代词、年龄”。逐行代码审查显示,knowledge graph 模块里根本没有“contradict”这个词。唯一的去重是阻止完全相同的三元组重复插入。如果你的 agent 周二存了
Age: 30,周三又存了 Age: 45,这两条都将一直留在数据库里。
- 知识图谱很初级。 MemPalace 用 SQLite 做知识图谱。它能应付基础的实体关系与简单的时间查询,但缺乏实体解析(无法识别 “Alice”“Alice S.”“A. Smith” 是同一人)、社群发现,以及像 Zep/Graphiti 这类基于 Neo4j 的系统所提供的复杂图算法。
这些都不是小问题,而是“营销与现实之间的显著落差”。GitHub 上的独立审阅者评价道:MemPalace 是他们评测过的“唯一一个在 README 中存在多处明显错误声明的系统”。
那为什么你仍然应该关注它?
因为在夸大的营销之外,MemPalace 在一些对实际使用很重要的点上,做得很对。
- 完全本地运行。 你的数据不会离开你的机器。写入时没有 API 调用,也无云端依赖。对处理私有代码、敏感客户数据,或注重隐私的人来说,这比 Mem0 的托管云(专业版要到 $249/月)或 Zep 的基础设施要求有明显优势。
- 成本为零。 整个系统仅依赖 ChromaDB 和 PyYAML。两个依赖。存储与基础检索不需要任何 API Key。对独立开发者和爱好者,这消除了尝试持久记忆的最大门槛。
- 空间隐喻确实有帮助。 不是因为它是计算机科学上的突破,而是因为它让你能以直觉方式去组织 AI 的记忆。Wings、Rooms、Halls、Drawers 的划分,自然贴合大多数人管理项目与知识域的思维方式。由此带来的元数据过滤,相比扁平向量检索,是实打实的改进。
- MCP 集成很棒。 Claude、ChatGPT、Cursor 可直接使用 19 个现成工具。配置只需一条终端命令。
- 96.6% 的基线确实亮眼。 把“100%”的虚高部分剔除,你仍然得到一个在 LongMemEval 上分数高于 Mem0(约 49%)与 Zep(约 64%)的系统。那个“高质量 embedding + 原始逐字文本优于 LLM 摘要”的洞见,值得整个行业重视。
2026 年的记忆版图里,MemPalace 处在什么位置
AI agent 记忆市场很碎片化,不同工具面向不同用例。基于我的调研,给出一个尽量诚实的定位。
- Mem0 是托管记忆的行业标配。适合你想要“即插即用的个性化”、不介意云依赖、并有预算上专业版($249/月)以解锁图功能的团队。它的生态最大(5 万+ 开发者),集成覆盖也最广。
- Zep/Graphiti 适合需要时间推理的场景。如果你的 agents 必须精确跟踪事实随时间的变化(“我们 1 月与 3 月的部署策略分别是什么?”),Zep 以 Neo4j 为底的时间知识图谱是为此而生。但它的基础设施更重、起步价 $25/月。
- Letta 在架构上最有意思。它受操作系统启发的思路(agent 像 OS 管理 RAM 一样自管记忆)确实很新。但采用 Letta 往往意味着接受一整套 agent 运行时,而非只是一层记忆组件。
- MemPalace 填补了一个特定空白:独立开发者或小团队,希望在“零云成本、完全数据私有、无基础设施负担”下拥有持久记忆。它是最轻量的选项,空间化组织让管理出奇直观。但它不是企业级系统的替代品,你也必须带着清醒的预期面对它的局限。
快速上手:一份实操指南
说够了原理,下面是真正把 MemPalace 用起来的步骤。
Step 1: Install
pip install mempalace
就这一步。两个依赖(chromadb 和 pyyaml)会自动安装。
Step 2: Create Your Identity File
这是 Layer 0,每次会话的地基。把文件创建在 ~/.mempalace/identity.txt:
Name: [Your name]
Role: Senior backend developer
Primary languages: Python, TypeScript
Coding style: Prefer explicit over implicit, type everything, test first
Communication: Direct, skip the pleasantries, give me the tradeoffs
Current focus: Migrating auth system from JWT to session-based tokens
尽量精炼,控制在 50–100 tokens。把它当成让你的 AI 变得有用所需的最小上下文。你不是在写自传,而是在写一段“引导启动(boot sequence)”。
Step 3: Mine Your Existing Conversations
如果你有导出的聊天记录或项目文件,喂给它:
mempalace mine ~/chats/project-orion/ --mode convos --wing orion_project
mempalace mine ~/code/orion/src/ --mode projects --wing orion_project
miner 会自动处理 20 种文件类型(.py、.js、.ts、.md、.txt 等),忽略构建目录与 node_modules,并按四步级联分配文件到 rooms:目录路径匹配、文件名分析、关键词频率打分、以及回退到一个通用 room。
提醒:这种确定性分配并非总是完美。内容含糊的文件可能被分错房间。请检查结果,并手动调整看起来不对的项。系统不会自动纠错错误分类。
Step 4: Connect to Your AI via MCP
以 Claude Code 为例(其他 MCP 客户端如 Cursor、OpenCode 使用各自的配置文件):
claude mcp add mempalace -- python -m mempalace.mcp_server
在 Cursor 中,将其加入你的 MCP 配置。现成的 19 个工具包括 mempalace_search、mempalace_store,以及用于知识图谱查询的专用工具。
连接后,你的 AI 可以在对话中自主搜索记忆宫殿。问它几周前的某个决策,它会自动从正确的 wing 与 room 拉取相关上下文,无须你再次解释。
Step 5: Structure Your Palace Intentionally
多数人会在这里“过度设计”或“设计不足”。一个务实的起点是:
- 每个重要项目或生活领域建一个 wing。比如你是自由职业开发者,有三个客户,那就三个 wings,再加一个
personal 和一个 learning 也未尝不可。
- 在每个项目的 wing 内,让 rooms 随你的实际工作自然生长。别一开始就预建 20 个空房间。先从宽泛的房间入手(
backend、frontend、devops),让 miner 去填充。当一个 room 太大或话题太杂,就拆分。
- 默认的 halls(Work、Health、Relationships、Travel、General)基本能覆盖大多数分类。没有明确理由,不要和默认对着干。
Step 6: Use the Python API for Custom Agents
如果你在 GUI 环境之外自建 agent:
from mempalace.searcher import search_memories
results = search_memories(
"auth migration decisions",
palace_path="~/.mempalace/palace"
)
# Inject results into your local model's context
for memory in results:
print(f"[{memory['wing']}/{memory['room']}] {memory['text'][:200]}")
这适配任意本地模型(Llama、Mistral 等)。把相关记忆取出,注入你的 prompt,本地 agent 就能以几百个 token 的代价,拥有“数周上下文”。
What to Skip
- 暂时跳过 AAAK 方言。它是有损摘要,会显著降低检索质量。在不碰到上下文窗口瓶颈前,都用原始文本存储;即便遇到瓶颈,也先考虑是否通过更合理的 Layer 2/3 选择性加载来解决。
- 跳过把知识图谱用于关键任务。它对基础实体跟踪有用,但缺少复杂时间推理所需的解析能力。如果你要回答“1 月与 3 月之间发生了哪些变化”,Zep 甚至一套结构良好的按日期组织的 Markdown 文件,可能更靠谱。
- 别把基准分当作采用理由。采用 MemPalace,是因为它本地优先、零成本、空间化组织的模式符合你的工作流,而不是因为“100%”这个通过手工调教固定测试集得来的分数。
更大的启示
MemPalace 的爆发式采纳,透露了当下 AI 生态的一个现实:开发者迫切需要本地、私有、零成本的记忆方案。市场长期被依赖云端、订阅定价的工具占据,而有一大群独立构建者只想让 AI 记住“昨天聊过什么”,却又不愿把自家代码传到别人的服务器。

至少在初期,空间隐喻比代码质量更重要。给人们一个直觉的方式去组织 AI 的记忆(wings、rooms、drawers),能显著降低上手门槛——远胜于“请配置向量数据库的 metadata schema”。这个仓库尽管在 README 里被实锤有误,却仍拿下 2.2 万+ star,也从侧面说明社区对“好上手”的解法有多饥渴。
MemPalace 不是最好的 AI 记忆系统,但它是最“易达”的一个。对许多开发者来说,这比基准分更重要。
代码还需要打磨,营销需要诚实。但“逐字存储、空间化组织、分层加载上下文”这个核心思想是靠谱的,而且今天就很实用。装上它,按你的实际项目来搭建你的宫殿,通过 MCP 连起来,看看明天早上你的 AI 是否终于还记得你是谁。
光是这点,或许就值得那 10 分钟的安装与配置。
如果你也想在技术浪潮中找到一个纯粹、硬核的开发者交流圈,不妨来 云栈社区 看看,这里聚集着许多和你一样热衷造轮子、啃源码的极客。
 发表于 2026-4-25 05:58:40
|
查看: 134|
回复: 0
发表于 2026-4-25 05:58:40
|
查看: 134|
回复: 0
