嗨,朋友们,先来聊聊 FastRTC。它是一个超轻量的 Python 实时通信库,能把你写好的函数瞬间变成音视频流服务。支持 WebRTC、WebSocket,甚至电话接口,让你从此不用再烦恼前端复杂对接和异步细节。想调试?内置 Gradio UI,一句 .ui.launch() ,本地立马预览;想线上部署?.mount(app) 直接挂到 FastAPI。
它解决了哪些痛点?
- 繁琐对接:传统要写前端、后端、信令、转码一大堆,FastRTC 全给你封装好了。
- 延迟高、丢包惨:内置回合检测(Vad+ReplyOnPause),自动触发交互,不卡壳。
- 部署难:从命令行到电话接口
.fastphone() 一条命令搞定,连临时电话号都免费给你。
- 二次开发:一条挂载方法就能扩展,想接 OpenAI、Gemini、Claude、ElevenLabs 任你组合。
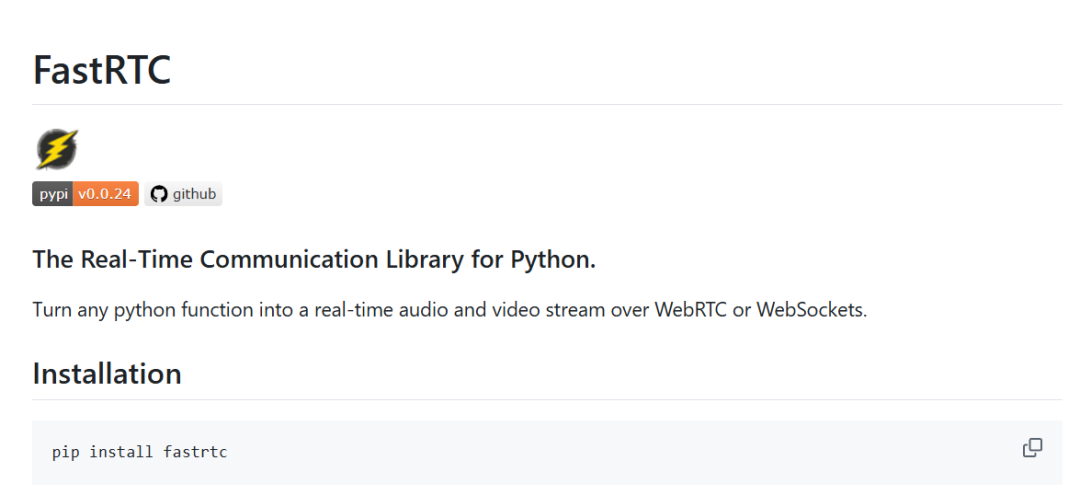
安装
只需一行命令即可安装 FastRTC:
代码示例:玩转音视频流
下面简单示范几个常见玩法。
- Echo 音频回声
from fastrtc import Stream, ReplyOnPause
import numpy as np
def echo(audio: tuple[int, np.ndarray]):
yield audio # 用户一说完,就把声音返还
stream = Stream(
handler=ReplyOnPause(echo),
modality="audio",
mode="send-receive",
)
stream.ui.launch()
- LLM 语音对话
from fastrtc import Stream, ReplyOnPause, audio_to_bytes, aggregate_bytes_to_16bit
import anthropic, numpy as np
from elevenlabs import ElevenLabs
claude = anthropic.Anthropic()
tts = ElevenLabs()
def chat(audio):
# 语音转文本
text = ... # 自行调用 Whisper
# Claude 回复
resp = claude.messages.create(..., messages=[{"role": "user", "content": text}])
reply = ... # 提取纯文本
# 文本转语音流
for chunk in tts.text_to_speech.convert_as_stream(text=reply, voice_id="...", model_id="..."):
yield from aggregate_bytes_to_16bit(chunk)
stream = Stream(
handler=ReplyOnPause(chat),
modality="audio",
mode="send-receive"
)
stream.mount(app) # 挂到 FastAPI,自己写前端接入
- 简单视频处理
from fastrtc import Stream
import numpy as np
def flip(image):
return np.flip(image, axis=0)
stream = Stream(handler=flip, modality="video", mode="send-receive")
stream.ui.launch()
优缺点一览
优点:
- 上手零成本:只要有 Python 环境,pip 安装立马能跑。
- UI+API 一条龙:调试、部署不分家。
- 可扩展:想集成任何模型(LLM、TTS、VAD、CV)都能花式拼接。
- 电话接入:临时号码、免费试用,当客服小助手或电话机器人都行。
缺点:
- 性能依赖本地带宽和 CPU/GPU,超大并发得自己调参。
- 自定义前端时,要对接信令和流处理,有点学习成本。
- 生态还在打磨,新手文档、示例还不够丰富。
总结
总的来说,FastRTC 就像给 Python 装了个“实时通信引擎”,让你把函数变成 OK 级别的音视频服务、电话机器人或者 WebRTC 应用,不用纠结底层协议。无论是快速原型验证,还是二次开发集成,FastRTC 都能帮你省去大量琐碎工作。想在项目里嵌入实时对话、远程物联网视频监控,或者语音客服,FastRTC 都能轻松搞定。

FastRTC 是一个非常有潜力的开源项目,项目地址:https://github.com/gradio-app/fastrtc |  发表于 2026-4-25 08:22:57
|
查看: 204|
回复: 0
发表于 2026-4-25 08:22:57
|
查看: 204|
回复: 0
