导读: “科学知识图谱”作为连接海量科研数据与科学发现的核心纽带,正成为支撑 AI4S 科研范式演进的关键知识底座。浙江大学联合上海人工智能实验室、同济大学等单位持续推进科学知识图谱的建设与应用探索。前期,联合团队在《国家科学评论》(National Science Review)发表综述论文,对知识图谱驱动的AI科学发现进行了系统性分析与介绍。
近期,我们系统整合生命、物质、材料、数理等多学科开源图谱,正式发布 SciGraph-SCP Server。作为首个专为科学智能体打造的 AI原生(AI-Native)科学图谱开放服务,该服务通过集成科学智能上下文协议(SCP)为智能体提供无缝调用接口。进一步基于 SkillNet 完成技能化封装,并支持从 OpenClaw、华为 JiuwenClaw 等多个开源智能体框架直接调用。在此基础上,我们还展示了怎样基于 SciGraph 构建面向科学家的大模型知识维基:SciLLM-Wiki,直观呈现其赋能AI科学发现的多样化价值。
目前,SciGraph-SCP 已集成涵盖 8个 科学领域,逾 3.7亿+ 实体、37亿 +三元组,是当前国内外覆盖领域最多、集聚规模最大的开放科学知识图谱服务。我们诚邀科学社区各界共同参与,持续共建这一开放的科学知识基础设施。本项工作得到科技创新2030— “新一代人工智能”国家科技重大专项 支持。
全文目录
- SciGraph:构建AI原生科学知识服务
- SciGraph SCP Server架构设计
- SciGraph SCP Server实战示例
3.1 常规 SCP 调用
3.2 从OpenClaw访问SciGraph
3.3 从JiuwenClaw访问SciGraph
- 基于SciGraph构建SciLLM-Wiki
- 诚邀共建AI4S科学图谱开放社区
- 书生Intern-Discovery SCP Server:
https://scphub.intern-ai.org.cn/detail/37O
- OpenKG SciGraph Service Catalog:
http://scigraph.openkg.cn/service/
- 《国家科学评论》NSR综述文章:
https://doi.org/10.1093/nsr/nwag140
01 SciGraph:构建AI原生的科学知识服务
在新一代 AI 智能体架构演进中,知识图谱的定位正在发生质变:它不再局限于供人查阅的“静态百科”,而逐步发展成智能体的“外脑皮层”和“逻辑向导”,实现从“人看图谱”向“智能体驾驭(Agent Harness)”的转型。
参考近期Palantir Ontology的成功实践,面向AI Agent的数据基础设施已超越单纯的存储和检索,而跃迁至“以本体为中心(Ontology-Centric)”的解耦表达——将底层数据抽象为AI原生可理解的对象、关联与操作逻辑。这种高度组织的语义结构,不仅为LLM构建了对抗幻觉的“思维锚点”,还为智能体提供了标准的语义框架以消除调用歧义。在此基础上,它还能赋予智能体高效驾驭(Harness)动态上下文与复杂工具链的能力,实现对流程逻辑、因果关联及专业约束条件的精准操控,从而真正释放知识图谱在Agentic推理与自主决策规划中的核心价值。
进一步,通过引入面向AI智能体的协议标准(如MCP模型上下文协议),图谱服务可以实现从“封闭孤岛”向“标准化资源”的进化。它将异构的科学图谱统一抽象为可即插即用的资源,并将复杂的专业查询封装为智能体可直接调用的工具(Tools),在消除接口差异的同时,通过AI原生的模型上下文反馈抹平知识存储与模型推理之间的协作断层。
此外,结合 OpenClaw 和 SkillNet 的实践,将标准化的图谱工具升级为AI原生可调用的知识技能单元,使得分散的图谱不再是孤立的脚本,而是根据逻辑依赖关系连接而成的知识技能网络,从而能最终构建起AI原生的知识服务系统。
秉持上述核心理念,联合团队系统整理并汇集了生命、物质、数理及材料等八个细分学科的开源知识图谱,依托上海AI Lab推出的“科学智能上下文协议(SCP)”完成图谱的标准化封装,并在此基础上集成 SkillNet 实现服务的“技能化”跃迁,构建起 AI原生的开放科学图谱服务 (AI-Native Science Graph Open Service)。
📊 表1:AI原生知识图谱服务
| 维度 |
传统知识图谱 (For Human) |
AI 原生图谱服务 (For Agent) |
| 交互媒介 |
可视化前端 / 复杂查询语言 |
MCP 协议 / 自然语言函数 |
| 内容形态 |
事实描述 |
对象+关系+技能 |
| 集成方式 |
手动集成/ETL |
动态发现/自动挂载 |
| 核心价值 |
辅助人类决策 |
赋能 Agent 自主推理与执行 |
02 SciGraph SCP Server 架构设计
作为 AI 原生开放科学图谱服务的核心载体,SciGraph-SCP Server 依托上海人工智能实验室推出的 SCP (Science Context Protocol),对多学科图谱资源进行协议级统一封装,向上层 AI 智能体提供标准化的知识访问与调用接口,使科学知识能够以可计算、可溯源、可编排的形态被智能体原生调用。
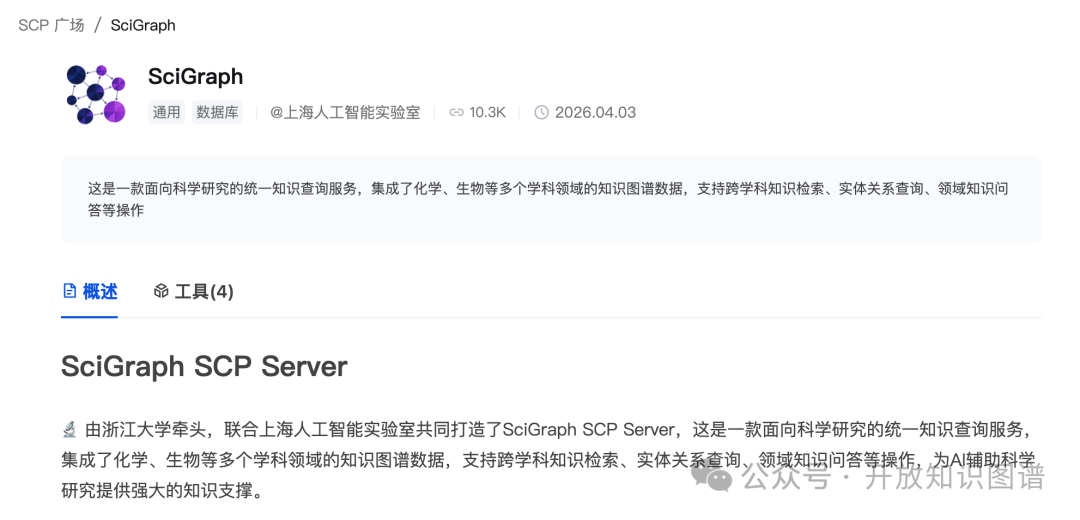
图1:书生Intern-Discovery SCP Server
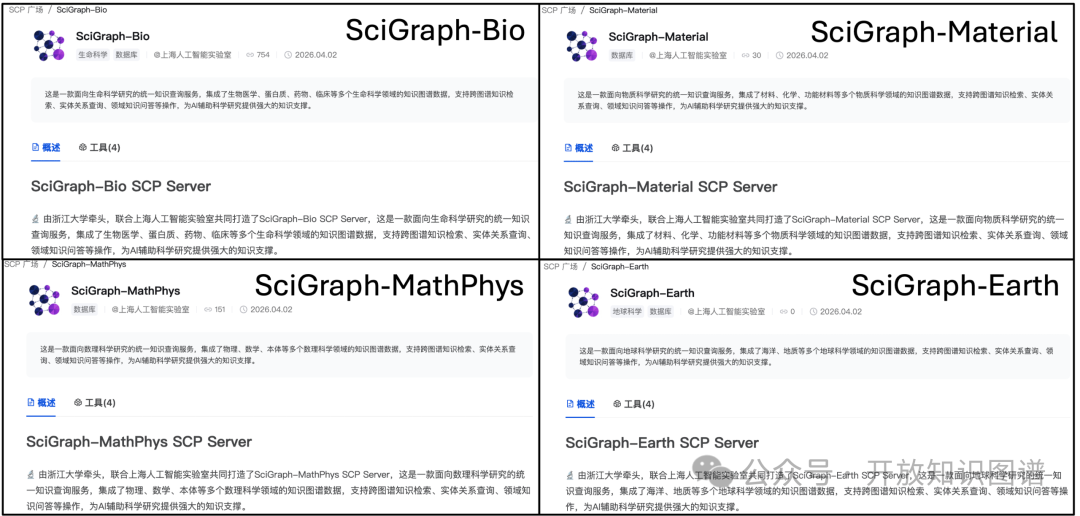
图2:学科专属的SciGraph SCP Server
目前,SciGraph SCP Server 已深度集成覆盖数学、物理、生物、化学、材料等多个细分学科的 68 个 科学知识图谱,拥有 3.7 亿+ 实体与 37 亿+ 条三元组,初步构建起支撑跨学科科研场景的统一知识服务底座。在保留全图谱统一服务能力的基础上,平台通过延伸开发生命科学(SciGraph-Bio)、物质科学(SciGraph-Material)、数理科学(SciGraph-MathPhys) 及 地球科学(SciGraph-Earth) 四大粗粒度学科专属 SCP 服务,实现了跨学科知识组织与垂直领域专业支撑的深度协同。

图3:OpenKG SciGraph Service Catalog首页
SciGraph SCP Server核心特点:
(1)跨学科本体融合,多学科统一接口:基于统一的科学本体方法论,SciGraph SCP Server深度整合化学、材料、生物等领域的结构化知识。通过标准化协议实现异构数据无缝集成,研究者仅需单一接口即可实现跨多个学科的逻辑链接。
(2)多维图谱架构,科研全路径覆盖:不仅追求规模,更强调知识的稠密性。以 ElementKG(化学知识图谱)为例:该图谱包含约 2309 万个节点、7400 余万条关系,涵盖分子、化学反应、实验流程、实验试剂、实验装置、元素等 13 种实体类型。包含实验目的、操作步骤、试剂用量、反应条件、产物产率、官能团及元素物理化学属性等完整信息,支持从实验设计到结果分析的全流程知识查询。知识图谱中的实体通过 97 种关系类型相互连接,形成了一个完整的化学实验与元素知识网络。
(3)MCP原生兼容,开箱即用:所有工具通过标准化MCP(Model Context Protocol)协议封装,提供一致的API调用方式,研究人员无需本地部署图数据库,仅需几行Python代码即可远程访问完整知识图谱,显著降低使用门槛,提升研发效率,让使用者专注于科学探索而非工程实现。
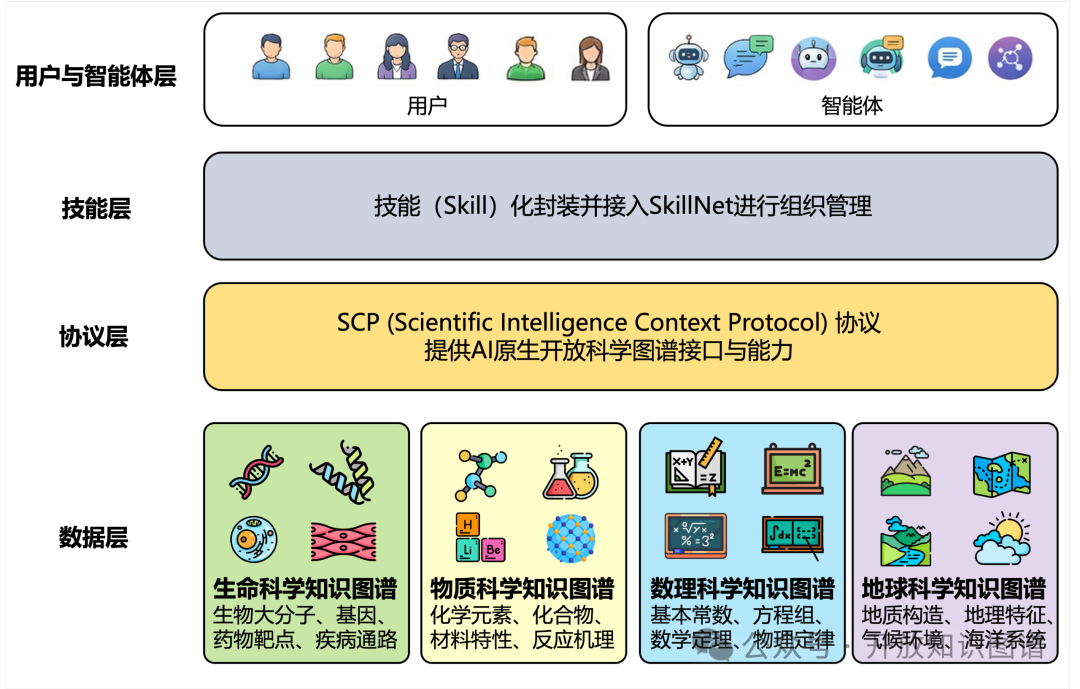
图4:SciGraph SCP Server架构图
03 SciGraph-SCP 实战示例
本节通过一组具体案例,展示 SciGraph-SCP 如何将分散的科学知识图谱组织为 AI 智能体可直接调用的知识服务,并进一步以技能化方式接入 OpenClaw、JiuwenClaw 等开源智能体框架,打通从图谱资源到智能体调用的完整链路。
3.1 常规SCP调用
为了更直观展示SciGraph-SCP的运行方式,本小节提供了三个不同层次的实战示例:
第一层是单图谱调用,即 AI 智能体能够根据问题自动路由到最合适的学科图谱;
第二层是多图谱联合调用,即系统可跨多个知识图谱协同检索与整合;
第三层是图谱与外部工具的协同,即在图谱提供知识依据之后,进一步联动更多工具,将知识检索延伸为任务执行支持。
在开始前请安装SDK pip install mcp,并确保 mcp_config.json 已通过 https://discovery-usercenter.intern-ai.org.cn/ 获取并正确配置API-KEY。
{
"mcpServers": {
"SciGraph": {
"type": "streamableHttp",
"description": "这是一款面向科学研究的统一知识查询服务,集成了化学、生物等多个学科领域的知识图谱数据,支持跨学科知识检索、实体关系查询、领域知识问答等操作",
"url": "https://scp.intern-ai.org.cn/api/v1/mcp/37/SciGraph",
"headers": {
"SCP-HUB-API-KEY": "{API-KEY}"
}
}
}
}
✅ 单一图谱调用
问题输入:
Q6GZX4 蛋白能够参与哪些生物过程,是如何在生物细胞中发挥作用的?
系统将问题路由到生命科学图谱 ProteinKG25,并使用以下Python代码进行查询:
import asyncio
from mcp import ClientSession, StdioServerParameters
async def query():
# scp服务调用
response = await session.call_tool("SciGraph.query_graph", arguments={
# 定义使用的kg
"graph_name": "ProteinKG25",
# kg查询语句
"cypher_query": "MATCH (p:Protein {proteinId: 'Q6GZX4'})-[:ANNOTATED_WITH]->(g:GOTerm) RETURN g.goId, g.definition LIMIT 50"
})
context = response.content
return context
asyncio.run(query())
查询结果返回:
{
"data": [
{
"goId": "GO:0046782",
"definition": "regulation of viral transcription",
"type": "Process"
}
],
"triples": [
["Q6GZX4", "ANNOTATED_WITH", "GO:0046782"],
["GO:0046782", "IS_A", "Biological Process"],
["GO:0046782", "DEFINITION", "regulation of viral transcription"]
]
}
在此基础上,大模型生成面向用户的回答:
根据 Scigraph-Bio/ProteinKG25 知识图谱查询结果,Q6GZX4 蛋白参与的主要生物过程是 病毒转录调控(GO:0046782)。该蛋白通过调节病毒基因组转录的频率、速率或程度发挥作用,可能作为转录辅助因子与病毒或宿主转录机器相互作用。由于参与转录调控,推测该蛋白主要定位于细胞核。

✅ 多图谱联合调用
问题输入:
CID 1268 (Sunitinib) 的主要靶点蛋白是什么类型,参与哪些重要的生物学过程和信号通路?
系统将问题路由到多个生命科学知识图谱 iKraph、MKG-FENN、Otter-UBC 联合处理,并使用以下Python代码进行查询:
import asyncio
from mcp import ClientSession, StdioServerParameters
async def query():
context_list = []
# 查询MKG-FENN中药物-蛋白质相互作用信息
response = await session.call_tool("SciGraph.query_graph", arguments={
"graph_name": 'MKG-FENN',
"cypher_query": "MATCH (d:Drug)-[:BINDS_TO]->(p:Protein) WHERE d.name CONTAINS 'Sunitinib' RETURN d.name, p.name LIMIT 30"
})
context = response.content
context_list.append(context)
# 查询MKG-FENN中蛋白质-通路信息
response = await session.call_tool("SciGraph.query_graph", arguments={
"graph_name": 'MKG-FENN',
"cypher_query": "MATCH (p:Protein)-[:INVOLVED_IN_PATHWAY]->(pw:Pathway) RETURN p.name, pw.name LIMIT 30"
})
context = response.content
context_list.append(context)
# 查询iKraph中药物相关信息
response = await session.call_tool("SciGraph.query_graph", arguments={
"graph_name": 'iKraph',
"cypher_query": "MATCH (n:Node)-[:RELATED_TO]->(m:Node) WHERE n.name CONTAINS 'Sunitinib' RETURN n.name, m.name, m.type LIMIT 50"
})
context = response.content
context_list.append(context)
# 查询Otter-UBC中药物-蛋白质相关信息
response = await session.call_tool("SciGraph.query_graph", arguments={
"graph_name": 'Otter-UBC',
"cypher_query": "MATCH (d:ns0__Drug)-[:ns0__binding_to]->(p:ns0__Protein) WHERE d.name CONTAINS 'Sunitinib' RETURN d.name, p.name LIMIT 30"
})
context = response.content
context_list.append(context)
return context_list
asyncio.run(query())
查询结果返回:
{
"targets": [
["KDR/VEGFR2", "Receptor tyrosine kinase"],
["KIT", "Receptor tyrosine kinase"],
["PDGFRA", "Receptor tyrosine kinase"],
["PDGFRB", "Receptor tyrosine kinase"],
["CSF1R", "Receptor tyrosine kinase"],
["FLT3", "Receptor tyrosine kinase"],
["RET", "Receptor tyrosine kinase"]
],
"processes": [
["GO:0002237", "angiogenesis"],
["GO:0045056", "vascular endothelial cell proliferation"],
["GO:0033993", "vascular endothelial growth factor receptor signaling pathway"],
["GO:0007169", "transmembrane receptor protein tyrosine kinase signaling pathway"],
["GO:0050767", "regulation of cell migration"]
],
"pathways": [
["VEGF signaling pathway", "WikiPathways:WP1981"],
["PI3K-Akt signaling pathway", "PathBank:SMP0000716"],
["Ras-MAPK signaling pathway", "Reactome"],
["PDGF signaling pathway", "WikiPathways:WP3594"],
["JAK-STAT pathway", "PID:PC7_7269"]
],
"triples": [
["Sunitinib", "INHIBITS", "VEGFR2"],
["Sunitinib", "INHIBITS", "KIT"],
["Sunitinib", "INHIBITS", "PDGFR"],
["VEGFR2", "PARTICIPATES_IN", "Angiogenesis"],
["KIT", "PARTICIPATES_IN", "Stem cell development"]
]
}
在此基础上,大模型生成面向用户的回答:
CID 1268 (Sunitinib) 的主要靶点均为 受体酪氨酸激酶(RTKs),包括 VEGFR1/2/3、PDGFRα/β、KIT、FLT3 和 RET。这些靶点参与的重要生物学过程包括 血管生成和血管发生、细胞增殖和分化、细胞迁移和运动 等;相关信号通路主要包括 VEGF 信号通路、PI3K-Akt 通路、Ras-MAPK 通路、PDGF 信号通路、JAK-STAT 通路 等。通过同时抑制多个 RTK 靶点,Sunitinib 能够阻断肿瘤血管生成和肿瘤细胞增殖,实现双重抗肿瘤作用。
✅ 图谱+工具联合调用
问题输入:
设计一个使用 CRISPR-Cas9 系统敲除 HEK293T 细胞中 EGFR 基因的详细实验方案,包括 sgRNA 设计与合成、CRISPR 载体构建、细胞培养与转染、单克隆筛选、基因型鉴定和蛋白水平验证。
系统先将问题路由到生命科学图谱 ProteinKG25 和 TxGNN,检索 EGFR 的功能注释与设计依据,并生成如下查询语句:
import asyncio
from mcp import ClientSession, StdioServerParameters
async def query():
context_list = []
# 查询ProteinKG25 - Function
response = await session.call_tool("SciGraph.query_graph", arguments={
"graph_name": 'ProteinKG25',
"cypher_query": "MATCH (p:Protein {proteinId: 'P00533'})-[:ANNOTATED_WITH]->(g:GOTerm) WHERE g.type = 'Function' RETURN g.goId, g.definition, g.type LIMIT 50"
})
context = response.content
context_list.append(context)
# 查询ProteinKG25 - Process
response = await session.call_tool("SciGraph.query_graph", arguments={
"graph_name": 'ProteinKG25',
"cypher_query": "MATCH (p:Protein {proteinId: 'P00533'})-[:ANNOTATED_WITH]->(g:GOTerm) WHERE g.type = 'Process' RETURN g.goId, g.definition, g.type LIMIT 50"
})
context = response.content
context_list.append(context)
# 查询ProteinKG25 - Component
response = await session.call_tool("SciGraph.query_graph", arguments={
"graph_name": 'ProteinKG25',
"cypher_query": "MATCH (p:Protein {proteinId: 'P00533'})-[:ANNOTATED_WITH]->(g:GOTerm) WHERE g.type = 'Component' RETURN g.goId, g.definition, g.type LIMIT 50"
})
context = response.content
context_list.append(context)
# 查询TxGNN
response = await session.call_tool("SciGraph.query_graph", arguments={
"graph_name": 'TxGNN',
"cypher_query": "MATCH (d:Drug)-[:DRUG_TARGETS_PROTEIN]->(p:Gene_Protein {name: 'EGFR'}) RETURN d.name, d.type, d.status LIMIT 30"
})
context = response.content
context_list.append(context)
return context_list
asyncio.run(query())
查询结果返回:
{
"graphs": {
"ProteinKG25": {
"data": [
["GO:0004672", "protein kinase activity", "Function"],
["GO:0042802", "identical protein binding", "Function"],
["GO:0007173", "EGFR signaling pathway", "Process"],
["GO:0005887", "integral component of plasma membrane", "Component"],
["GO:0005886", "plasma membrane", "Component"]
]
},
"TxGNN": {
"data": [
["EGFR targeted drug information", "20 drugs"]
]
},
"triples": [
["EGFR", "HAS_FUNCTION", "Protein tyrosine kinase"],
["EGFR", "LOCATED_IN", "Plasma membrane"],
["EGFR", "PARTICIPATES_IN", "EGFR signaling pathway"],
["CRISPR-Cas9", "TARGETS", "EGFR"],
["sgRNA", "DIRECTS", "Cas9 to EGFR locus"],
["HEK293T", "CELL_LINE_FOR", "EGFR knockout"]
]
}
}
在图谱检索基础上,系统进一步调用 Thoth SCP Server 的 protocol_generation 工具,用于根据实验需求自动生成结构化湿实验方案:
{
"tool": {
"service_name": "Thoth SCP Server",
"tool": "protocol_generation",
"input": "CRISPR-Cas9 knockout EGFR experiment requirements",
"output": "Structured wet lab protocol"
}
}
在此基础上,生成面向用户的回答:
本实验方案设计了一个完整的 CRISPR-Cas9 介导的 EGFR 基因敲除细胞系构建流程。基于知识图谱检索,EGFR(P00533) 是跨膜受体酪氨酸激酶 (GO:0005887),具有蛋白激酶活性 (GO:0004672) 和二聚化能力 (GO:0042802),定位于细胞膜。
- sgRNA 设计:推荐 4 条靶序列,采用双 sgRNA 策略造成大片段缺失,策略 A(Exon 3-4 缺失) 导致移码突变,策略 B(激酶域 Exon 18-19 缺失) 破坏催化功能。PAM 序列为 NGG,GC 含量 40-60%,使用 CRISPOR 评估脱靶风险。
- 载体构建:推荐 lentiCRISPRv2 慢病毒载体,BsmBI 酶切后连接退火 oligo,转化 DH5α,测序验证。
- 细胞转染:HEK293T 细胞用 Lipofectamine 3000 转染,48h 后开始 1-2 μg/mL 嘌呤霉素筛选 5-7 天。
- 单克隆筛选:有限稀释法 (1 cell/孔) 或 FACS 分选 (GFP 阳性),培养 2-3 周至汇合。
- 基因型鉴定:PCR 扩增靶位点 (~500 bp),T7E1 酶切检测异源双链,Sanger 测序确认突变类型。
- 蛋白验证:Western Blot 检测~170 kDa EGFR 条带,敲除成功则无信号,内参用 GAPDH 或β-Actin。
- 时间线:第 1 周 sgRNA 设计合成与载体构建,第 2 周转染筛选,第 3-5 周单克隆扩增,第 6 周基因型鉴定,第 7 周蛋白验证,总周期 7-8 周。
- 常见问题:转染效率低 (用低代次细胞)、筛选后无存活 (预实验测最小致死浓度)、单克隆生长慢 (加条件培养基)、T7E1 无切割 (优化 PCR 或增加测序克隆数)、Western 仍有信号 (用 N/C 端双抗体验证)、脱靶效应 (重新设计 sgRNA 或用高保真 Cas9)。
- 资源:Scigraph-Bio 提供 EGFR 功能注释,Thoth 工具生成结构化湿实验方案,推荐试剂包括 lentiCRISPRv2、Lipofectamine 3000、CST EGFR 抗体 #4267。
3.2 从OpenClaw访问SciGraph
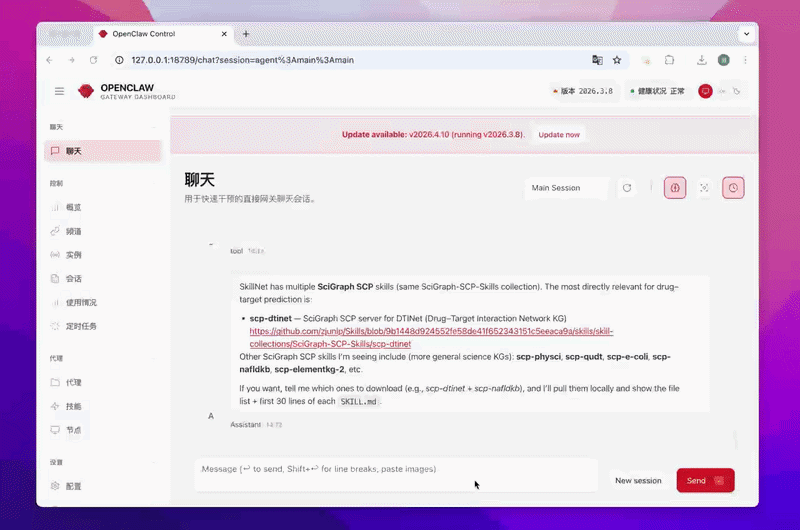
图5:在OpenClaw中调用 SkillNet 中封装的 SciGraph-Skill
在 AI Native 架构下,SciGraph 通过将图谱检索能力进一步解耦为原子化的 SciGraph-Skills,并纳入 SkillNet 进行统一组织,同时支持通过 OpenClaw 接入智能体调用链路,实现从静态“知识库”向持续进化的知识技能引擎的价值转变。
以图5中展示的scp-dtinet为例,该Skill面向药物—靶点相互作用预测和药物重定位任务,底层连接DTINet图谱,通过SciGraph SCP服务 + API Key授权方式接入,并封装了 query_cypher、get_kg_statistics、get_entity_details、pget_experiment_workflow 等工具,支持关系查询、图谱统计、实体详情查看和实验流程追踪等能力。
OpenClaw 会先在 SkillNet 中识别 SciGraph-Skills 集合中的候选技能,再结合当前任务语义,将与 drug-target prediction 最相关的候选项定位为 scp-dtinet。基于此,SciGraph 中原本分散在不同图谱中的知识资源,已经能够以 Skill 的形式被智能体自动发现、按需选择并接入调用链路,从而为后续的分析提供统一的知识技能入口。
SciGraph-Skills 示例:scp-dtinet
面向任务:药物—靶点相互作用预测、药物重定位
底层图谱:DTINet
接入方式:SciGraph SCP 服务 + API Key 授权
可调用工具:query_cypher、get_kg_statistics、get_entity_details、get_experiment_workflow
典型能力:查询图中关系、获取图谱统计、查看实体详情、追踪实验流程
3.3 从华为JiuwenClaw访问SciGraph
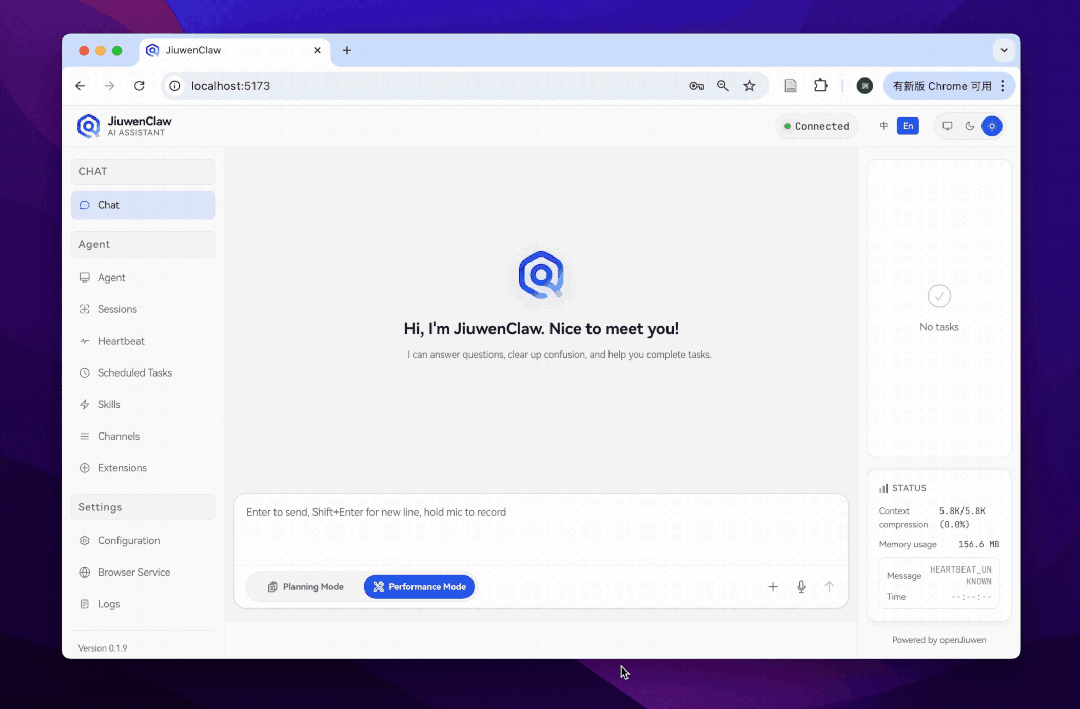
图6:在华为JiuwenClaw中调用 SkillNet 中封装的 SciGraph-Skill
我们进一步将技能化的 SciGraph 深度接入华为 JiuwenClaw智能体框架,并以药物—靶点预测为核心场景展示了全链路闭环。
如图 6 所示,系统实现了从“需求感知”到“环境就绪”的自动化流程:用户发起请求后,SkillNet 立即触发语义检索,从 SciGraph-Skills 资源池中精准定位并匹配最符合 drug-target prediction 任务的技能包 scp-dtinet。随后,框架自动完成该技能包的分发、下载与本地挂载,并实时同步说明文件以辅助推理决策。
这一过程验证了 SciGraph 在 JiuwenClaw 生态中已具备支撑“发现—路由—部署”完整链路的能力,演示了大规模科学图谱已能够以标准化 Skill 的形态,无缝嵌入智能体的原生运行环境。
04 SciLLM-Wiki应用举例
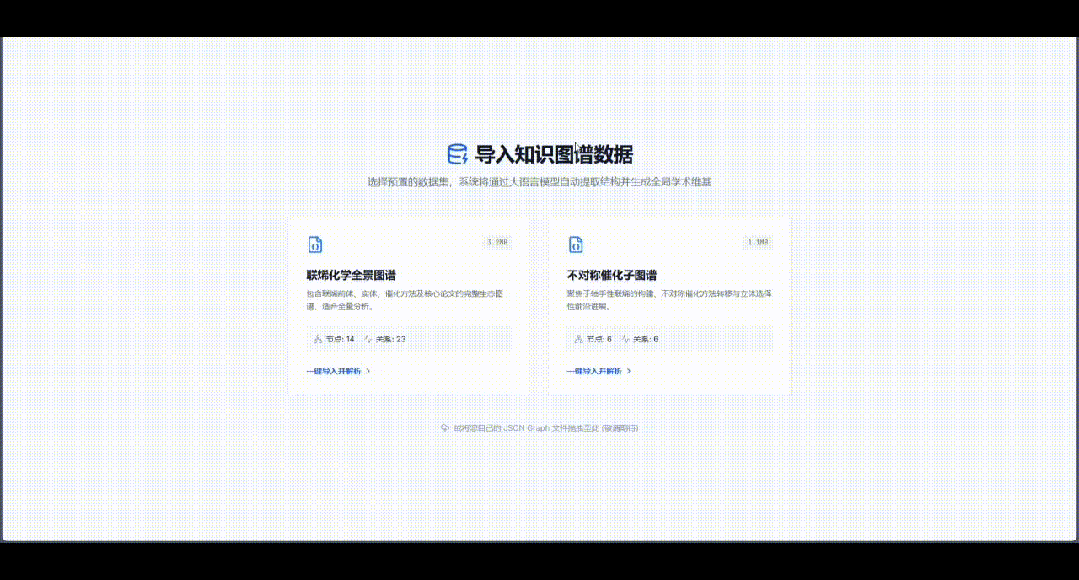
图7:SciLLM-Wiki科学知识维基示例
在大模型驱动的 AI Native 范式下,SciGraph 的核心价值已突破单一的瞬时检索,转而聚焦于更深层次的科研需求:面向特定研究主题的知识沉淀与内生演化。
为了呈现这一价值,我们借鉴了近期大模型知识维基(LLM-Wiki)的构建思路。LLM-Wiki 是一种全新的知识组织形态,它由大模型持续维护一组可积累、可链接、可更新的知识页面,旨在为知识问答、知识归纳与综述生成提供稳定的事实基座。
基于上述理念,我们探索基于SciGraph构建面向科学家的大模型知识维基(SciLLM-Wiki)。在这一系统中,SciGraph 发挥着至关重要的“定海神针”作用:它将结构化的图谱知识与特定主题的海量领域文献深度融合,为复杂庞杂的科研数据提供结构化的索引与锚点,从而沉淀出面向前沿研究问题的结构化知识空间。
在图7中,我们以 ElementKG 中的典型领域为例,展示了其构建思路:
- “联烯化学”主题: 系统首先从 SciGraph 中抽取联烯及其衍生物的反应类型、催化剂体系等核心骨架,利用图谱的结构化特征快速勾勒出该领域的知识拓扑。
- “非对称化学”主题: 通过 SciGraph 精准定位手性配体、不对称合成路径及代表性课题组等关键节点,形成研究脉络的“逻辑锚点”。
具体而言,图7展示了从 Propargylic Precursors 这一关键中间体切入的构建逻辑:SciGraph 负责提供概念间的结构化连接(图7左),帮助系统快速定位关键方法论与代表性工作;而 SciLLM-Wiki 则在这些骨架之上,通过大模型结合海量领域文献进行语义填充、进展归纳与文献综述(图7右)。
这种“图谱定骨架、模型赋语义”的分工协同模式,不仅保证了知识组织的严谨性,更实现了内容随研究进展而持续演化的生命力,构建起真正适合科研实战的知识中枢。
05 诚邀共建AI4S图谱开放社区
展望未来,SciGraph 的演进将超越单纯的知识汇聚,致力于进化为科学智能的 “本体骨架”。一方面,我们将科学实体、复杂关系与可执行动作统一于同一语义层,并在统一的本体框架下系统化地组织与编排智能体技能(Skills)。在这一范式中,科学基座模型充当 “大脑” ,负责深度理解科学问题、构建推理规划并实现任务调度;而科学知识图谱提供的本体骨架则作为 “逻辑支柱” ,为大模型的思考提供确定性的物理约束与知识边界。通过“大脑”与“骨架”的深度协同,我们将构建一套 AI原生的科学知识服务体系,推动科学知识从静态的 “数据仓库” 升级为动态的 “能力基座” ,为 AI for Science(AI4S)提供一个开放、可复用、可持续扩展的知识基础设施。
我们诚邀广大科研社区共同参与,携手定义AI原生时代的科学知识基座,让每一条知识都转化为重构物质和生命世界的智能原动力。
http://scigraph.openkg.cn/donate/
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。
 发表于 2026-4-25 07:52:00
|
查看: 171|
回复: 0
发表于 2026-4-25 07:52:00
|
查看: 171|
回复: 0
