1. 数据库规范化设计:打造高效整洁的"仓库"
1.1 什么是规范化设计?
专业性描述
规范化设计是一个系统性的过程,它通过一系列预定义的规则(称为"范式"),将数据库中的数据进行重新组织,其核心目标是消除数据冗余、解决数据操作异常,最终确保数据的一致性、完整性和操作的灵活性。
大白话类比
这就像整理一个杂乱无章的工具仓库。最初,各种螺丝刀、扳手和钉子都混放在一个大箱子里(相当于未规范化的表)。要找一件小工具非常困难,而且同一款螺丝刀可能在不同角落重复存放了好几个(数据冗余)。规范化就是给仓库安装上各种规格的抽屉和挂钩,每个工具都有其唯一、固定的位置,且同类工具只保留一件,并通过清晰的标签系统来管理。这大大提高了查找效率和管理水平。
1.2 规范化设计的作用
规范化通过分解数据表来解决三类主要问题:
- 消除数据冗余:相同的数据(如客户地址)只存储一次,节省空间,并从根本上避免了一个数据在多处出现可能造成的不一致。
- 解决数据操作异常:
- 插入异常:解决了无法单独添加某种信息(如新增一个尚未开课的讲师)的问题。
- 删除异常:避免了在删除一条信息时,无意中丢失另一条有价值信息(如删除某门课程后,该课程的分类信息也丢失了)的风险。
- 更新异常:确保只需修改一处即可全局更新,不会出现同一数据在不同地方值不同的情况。
- 确保数据一致性:这是规范化最核心的价值,它为数据建立了清晰、严谨的模型,使其能够准确反映业务规则。
1.3 设计范式:规范化程度的"阶梯"
范式是规范化程度的衡量标准,像阶梯一样,每一级都建立在上一级的基础之上。
1.3.1 第一范式:保证原子的"最小单元"
专业性描述:第一范式是关系型数据库必须满足的最基本条件。它要求属性具有原子性(每个字段都是不可再分的最小数据单元),并且表中存在主键以唯一标识每一行。
“在线教育平台”示例:
假设我们有一个初始的 课程订单 表,记录如下:
| 订单ID |
用户ID |
课程信息 |
| 1001 |
U123 |
课程名称:Java入门, 价格:¥299 |
这违反了1NF,因为“课程信息”列包含了可再分的复合值。规范化后,我们将其拆分为原子字段:
| 订单ID |
用户ID |
课程名称 |
价格 |
| 1001 |
U123 |
Java入门 |
299 |
现在,每一列都是不可再分的,符合1NF。
1.3.2 第二范式:消除“部分依赖”
专业性描述:在1NF基础上,要求所有非主属性必须完全依赖于整个候选键,而不能只依赖于候选键的一部分。
“在线教育平台”示例:
考虑一个 选课记录 表,其候选键由(学号, 课程号)组成。
| 学号 |
课程号 |
课程名称 |
成绩 |
| S001 |
C01 |
Java入门 |
85 |
这里,“课程名称”只依赖于候选键的一部分——“课程号”,而与“学号”无关。这违反了2NF,会导致数据冗余和更新异常。解决方案是拆分表:
成绩表(主键:学号, 课程号):学号,课程号,成绩课程表(主键:课程号):课程号,课程名称
1.3.3 第三范式:消除“传递依赖”
专业性描述:在2NF基础上,要求所有非主属性必须直接依赖于候选键,而不能依赖于其他非主属性(即不存在传递依赖)。
“在线教育平台”示例:
有一个 用户表 如下:
| 用户ID |
姓名 |
所在学院 |
学院院长 |
| U123 |
张三 |
计算机学院 |
李教授 |
这里,“学院院长”依赖于“所在学院”,而“所在学院”又依赖于“用户ID”,形成了传递依赖。这会导致更新异常。符合3NF的设计是将其拆分:
用户表(主键:用户ID):用户ID,姓名,学院ID学院表(主键:学院ID):学院ID,学院名称,学院院长
1.3.4 BCNF范式:更严格的3NF
专业性描述:BCNF是3NF的增强,要求所有函数依赖的决定因素都必须包含候选键。
“在线教育平台”示例:
一个简化的场景:假设一门课程(课程号)只能由一位讲师(讲师ID)讲授,而一位讲师只属于一个学院(学院ID)。如果设计一张包含(课程号, 讲师ID, 学院ID)的表,其中存在 讲师ID -> 学院ID 的依赖,但 讲师ID 本身不是候选键(候选键是 课程号),这就违反了BCNF。解决方案是拆分表,将 讲师ID -> 学院ID 这个依赖关系独立成一张表。
1.3.5 第四范式:处理“独立的多值关系”
专业性描述:在BCNF基础上,要求消除非平凡的多值依赖。
“在线教育平台”示例:
一个表要记录讲师(讲师ID)的两种独立信息:他所能讲授的课程(课程号)和他掌握的语言(语言)。一个讲师可以对应多门课程和多种语言。如果设计成一张表(讲师ID, 课程号, 语言),那么课程和语言是相互独立的,修改一门课程会影响到语言的记录,造成不必要的冗余和复杂性。4NF要求将这种独立的多值关系拆分成两张表:讲师-课程关系表 和 讲师-语言关系表。
1.4 规范化设计的优缺点
- 优点:
- 数据一致性高:更新操作只需在一处进行。
- 减少冗余,节省存储空间。
- 避免数据操作异常,模型更健壮。
- 缺点:
- 查询性能可能下降:获取完整信息常常需要关联多张表,复杂的JOIN操作可能较慢。
- 增加了查询的复杂性:编写SQL语句时需要考虑多表连接。
2. 数据库反规范化设计:用空间换时间的“权衡术”
2.1 什么是反规范化设计?
专业性描述
反规范化是在已完成规范化设计的基础上,为了提高查询性能,而有意识地、可控地引入数据冗余的设计技术。它是一种权衡策略。
大白话类比
在高度规范化的仓库(数据库)里,取一份“客户订单完整信息”需要跑遍“订单区”、“客户信息区”、“产品目录区”(多次表连接)。虽然管理严谨,但拣货速度慢。反规范化就像在“订单区”旁边开辟一个小货架,提前把最常用的客户姓名和产品名称复制一份放过来。这样,大部分订单查询只需在一个区域就能完成,速度极快,代价是需要在客户或产品信息变更时,额外维护这个小货架上的副本数据。
2.2 反规范化设计的优缺点
- 优点:
- 显著提高查询性能:减少了表连接次数,尤其利于复杂查询和报表生成。
- 简化查询语句:SQL更易于编写和理解。
- 缺点:
- 引入数据冗余,增加存储成本。
- 可能降低数据更新操作的性能,并增加复杂度。
- 可能牺牲数据的实时一致性,需要额外机制保障。
2.3 常见的反规范化设计方法
2.3.1 增加冗余列
示例:在 订单表 中,除了 用户ID,还直接加入 用户姓名 列。这样查询订单列表时,无需连接 用户表 即可显示姓名。
2.3.2 增加派生列
示例:在 订单表 中增加一个 订单总金额 列,其值由 订单明细表 中的单价和数量计算得出。查询时避免实时汇总计算。
2.3.3 重新组表(表合并)
示例:根据“学员学习进度看板”这个高频查询,将规范化的 学员表、课程表、学习记录表 合并成一张宽表 学员学习进度宽表,包含学员、课程、最新学习章节、完成时间等所有相关信息。
2.3.4 水平分割表
示例:将数据量巨大的 用户学习行为日志表 按年份(如 log_2023, log_2024)进行水平分割。查询某一年的日志时,只需扫描较小的表,极大提升性能。
2.3.5 垂直分割表
示例:将 用户表 分割为 用户基本信息表(ID, 姓名, 邮箱等高频访问字段)和 用户扩展信息表(个人简介、地址等不常访问字段)。提高对核心数据的查询效率。
2.3.6 预计算
示例:为“课程销量排行榜”创建一张 课程日销量汇总表,由定时任务在凌晨计算好各课程的当日销量并存入。白天查询排行榜时直接读取该表,性能极高。
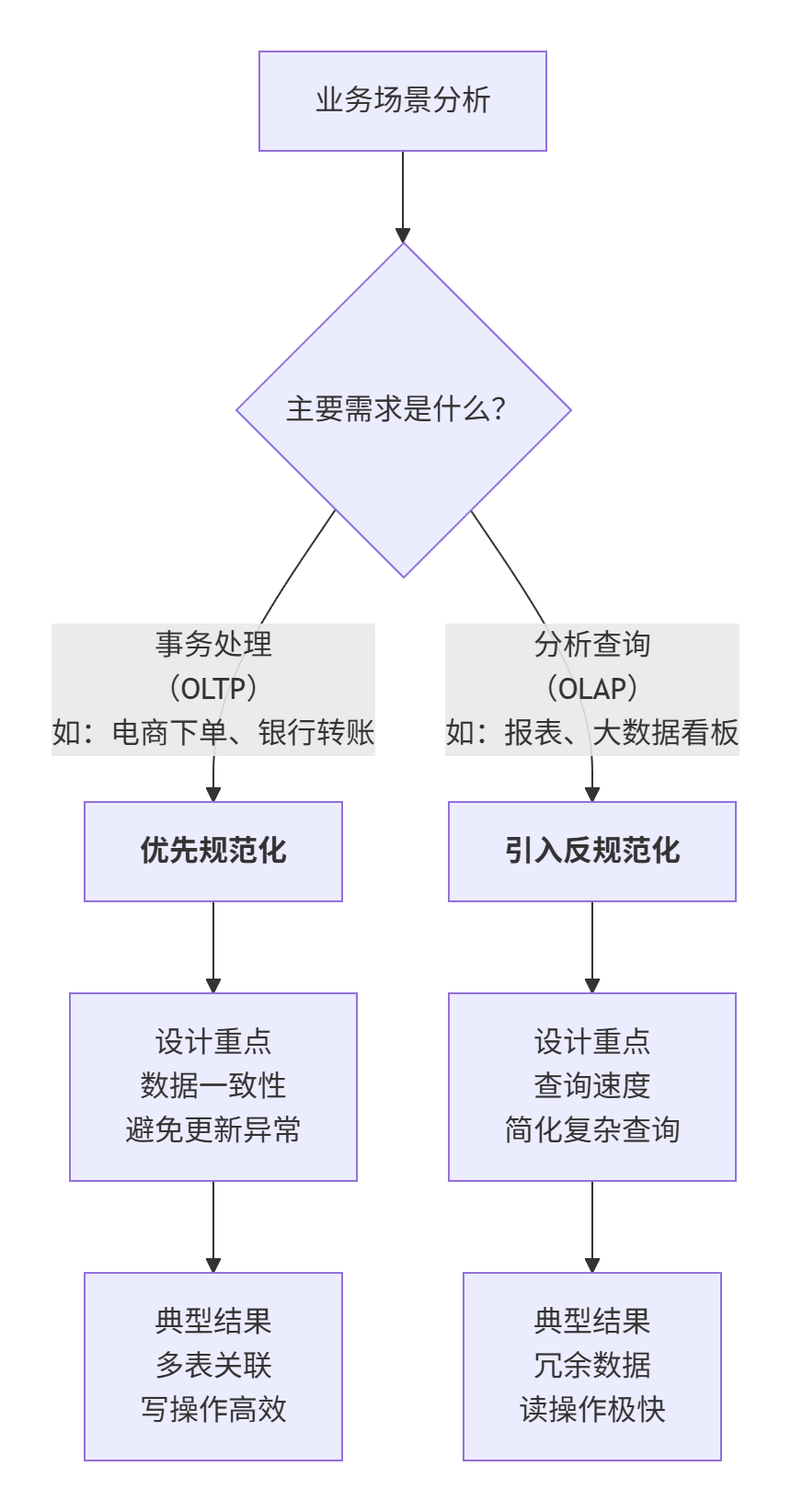
3. 如何选择:规范化与反规范化的平衡艺术
规范化和反规范化并非对立,而是数据库设计的一体两面。正确的做法是:先进行彻底的规范化设计,得到一个结构清晰、逻辑严谨的基底,然后根据具体的业务查询需求,有针对性地、局部地实施反规范化。
3.1 规范化与反规范化权衡图
4. 核心口诀与实战技巧
记忆口诀:
设计数据库,范式是基础。先到三范式,冗余异常除。
若要性能优,反范出马速。冗余换时间,权衡要记熟。
4.1 实战技巧
- 没有银弹:不要试图设计一个完全规范化或完全反规范化的数据库。优秀的系统架构师总是在一致性与性能、冗余与简洁之间寻找最佳平衡点。
- 基于用量决策:对读写比例极高(如超过9:1)且对查询延迟敏感的系统(如报表、大屏),大胆使用反规范化。对写操作频繁或数据一致性要求极高的系统(如核心交易系统),坚守规范化底线。
- 使用辅助工具:利用物化视图来预计算和存储复杂查询结果,它是实现反规范化效果的强大工具。使用触发器或应用层逻辑来维护反规范化引入的冗余数据的一致性。
希望这篇关于数据库规范化与反规范化的解读能为你带来启发。想深入探讨更多后端架构设计模式与技术选型,欢迎访问 云栈社区 与更多同行交流。
 发表于 2026-2-12 00:55:13
|
查看: 226|
回复: 0
发表于 2026-2-12 00:55:13
|
查看: 226|
回复: 0
