代码中自有颜如玉!代码中自有黄金屋!那么,Linux内核代码的汪洋大海到底有多少行?对于一个开发者来说,需要多久才能真正“读完”或者说“学懂”它呢?
一、内核行数:一个天文数字
Linux内核是一个庞然大物,它被划分为CPU调度、内存管理、网络和存储四大子系统,并包含成百上千种硬件驱动。要直观感受它的体量,我们可以从数据入手。
很多驱动工程师都曾从《Linux内核完全剖析》这类书籍入门,研究早期的内核如0.11版本,这已经需要花费数周甚至数月的时间。

那么,最新的内核代码量是什么概念呢?让我们看看具体的统计数据。
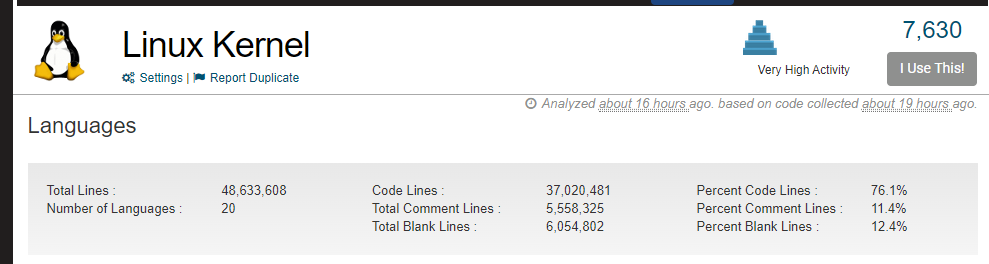
根据统计,截至统计时(约2025年11月),Linux内核Git源码树中的核心代码行数已达到 37,020,481 行。
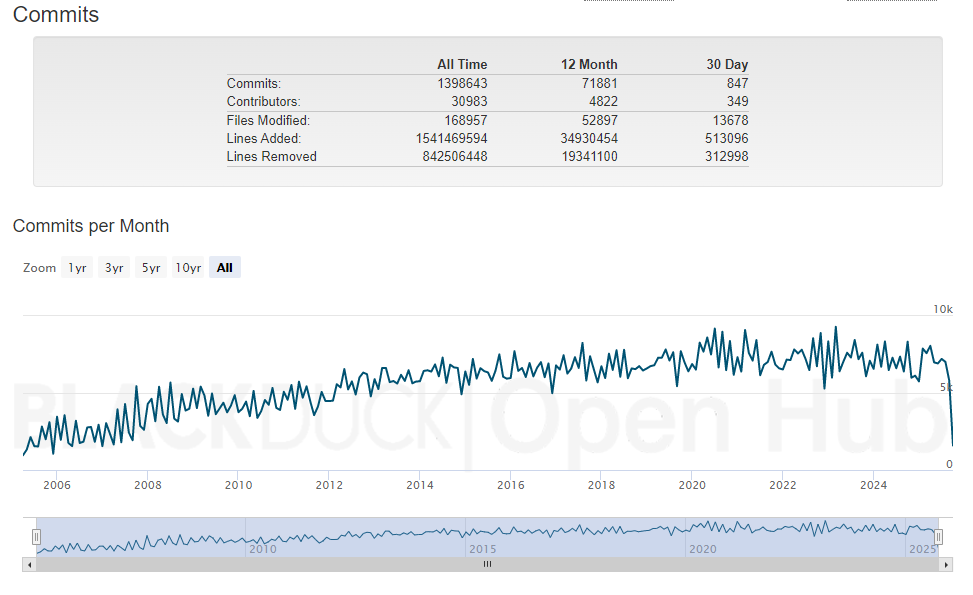
更全面的统计数据包括:
- 总行数 (含文档、Kconfig等):48,633,608 行
- 总提交次数 (Commits):1,398,643 次
- 贡献者数量:31,042 名

这是一个由全球精英共同构建的史诗级项目,其历史累计开发工作量按COCOMO模型估算,相当于12,541人年。从最初的约一万行代码到如今的数千万行,是开源协作的伟大成果。
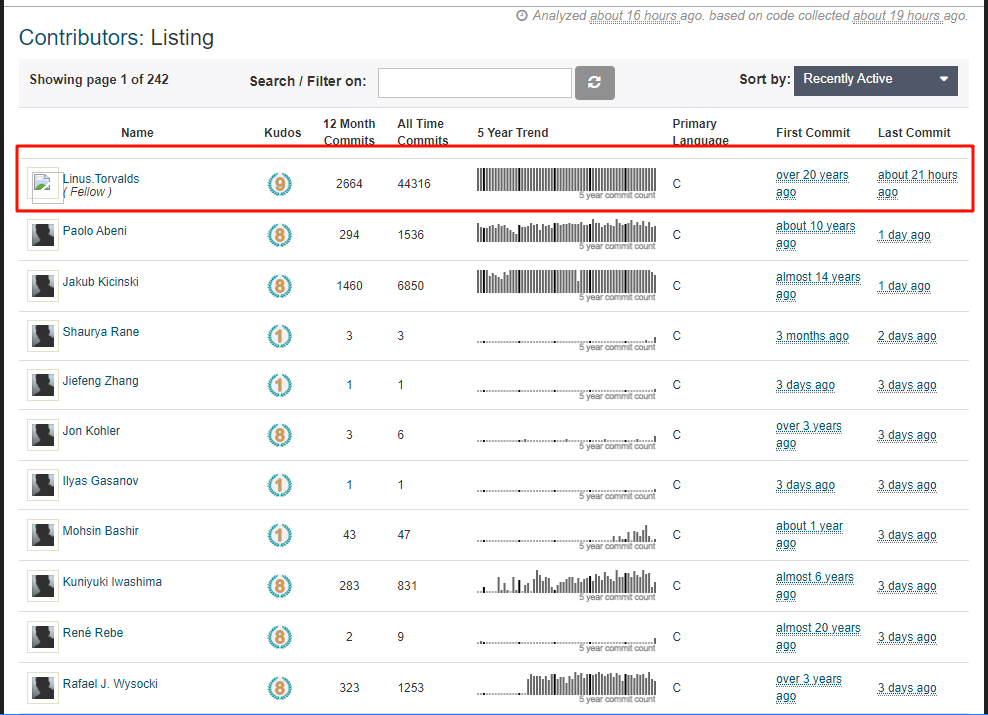
在贡献者榜单中,Linus Torvalds 祖师爷的地位无可撼动。值得一提的是,内核中只有约2%的代码由他本人编写,其余均由其他个人和组织贡献,而Linus保留了合并新代码的最终裁定权。
那么,如果按一天阅读一万行代码的速度计算,看完3700万行需要近4000天,也就是超过11年。这还是在假设你能理解每一行逻辑且过目不忘的前提下。实际上,内核在不断飞速迭代,可能在你“看完”之前,新的代码又已大量加入。因此,试图“读完”所有内核代码是一个不切实际的目标。
二、内核目录文件大小分布
我们以相对早期的linux-4.1.15版本为例,用 du -sh 命令看看各目录的占用空间,就能明白内核的“膨胀”主要体现在哪里。
整个内核源码目录大小约 793M:
root@ubuntu:/home/peng/linux-imx-rel_imx_4.1.15_2.1.0_ga_alientek# du -sh
793M.
其中,驱动代码占据了近半壁江山,约 380M:
root@ubuntu:/home/peng/linux-imx-rel_imx_4.1.15_2.1.0_ga_alientek/drivers# du -sh
380M
与硬件体系架构相关的代码约 134M:
root@ubuntu:/home/peng/linux-imx-rel_imx_4.1.15_2.1.0_ga_alientek/arch# du -sh
134M
网络子系统代码约 26M:
root@ubuntu:/home/peng/linux-imx-rel_imx_4.1.15_2.1.0_ga_alientek/net# du -sh
26M
文件系统相关代码约 37M:
root@ubuntu:/home/peng/linux-imx-rel_imx_4.1.15_2.1.0_ga_alientek/fs# du -sh
37M
而最核心的内核代码(如调度、进程管理等)大约只有 6.8M:
root@ubuntu:/home/peng/linux-imx-rel_imx_4.1.15_2.1.0_ga_alientek/kernel# du -sh
6.8M
由此可见,内核的复杂性不仅在于核心逻辑,更在于其对海量硬件设备和外围子系统的支持。上述任意一个目录,想要完全吃透都非常不易。
三、Linux内核子系统纵览
在深入代码之前,有必要了解内核的宏观架构。内核是现代操作系统最基本的部分,它管理所有软件对硬件资源的请求,并将其转换为CPU等组件的处理指令。它就像一位管家,为应用程序提供对计算机硬件有限且受控的安全访问。
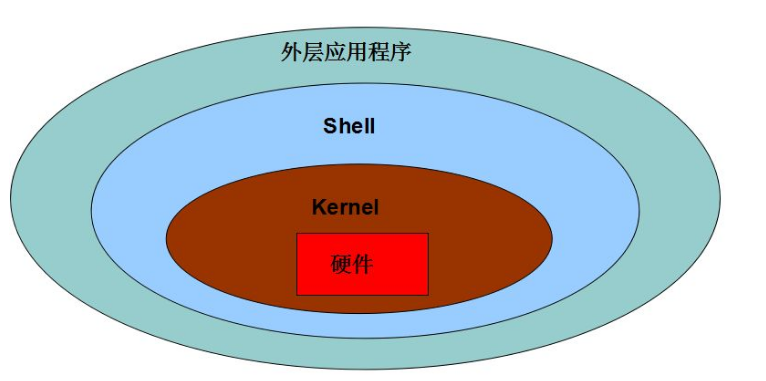
直接操作硬件异常复杂,因此内核提供了一层硬件抽象。应用程序通过系统调用(System Call)等机制,间接控制所需的处理器和IO设备资源。
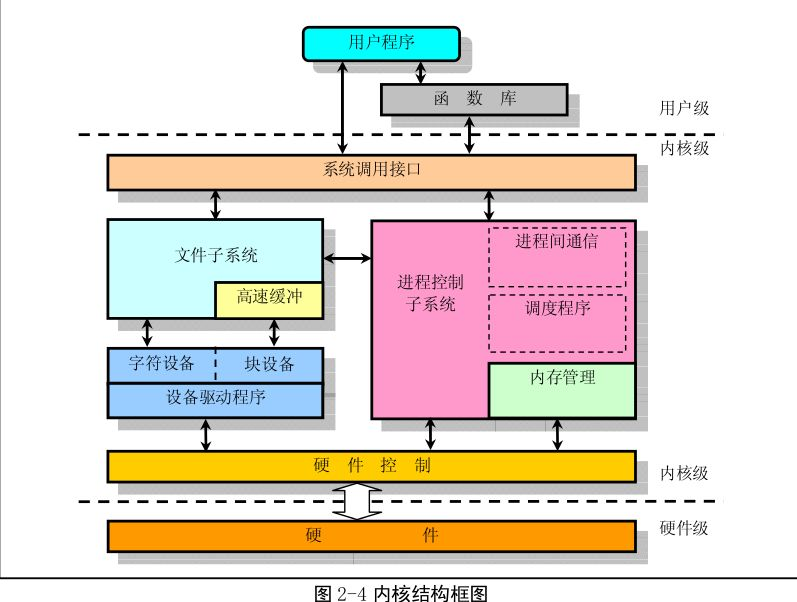
从上图可以看到,最上层是用户空间,运行着各种应用程序。用户空间之下是内核空间,GNU C库(glibc)在此提供了连接内核的系统调用接口。内核和用户空间进程使用不同的受保护地址空间。
Linux内核本身可以进一步划分为三层:
- 最上层:系统调用接口(SCI),提供
read, write 等基本功能。
- 中间层:独立于体系结构的内核代码,这是所有CPU架构通用的核心逻辑。
- 最底层:依赖于体系结构的代码,即板级支持包(BSP),包含特定处理器和平台的代码。
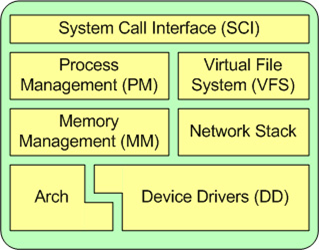
现代Linux内核主要包括以下几大子系统:
- SCI: 系统调用接口
- PM: 进程管理
- VFS: 虚拟文件系统
- MM: 内存管理
- Network Stack: 网络协议栈
- Arch: 体系架构相关代码
- DD: 设备驱动
1. 系统调用接口 (SCI)
SCI是用户空间程序进入内核空间的官方“大门”。它依赖于具体的CPU架构,其实现位于 ./linux/kernel 和 ./linux/arch 目录下。
2. 进程管理 (PM)
进程管理的核心是“执行”。在内核中,进程和线程的概念并未严格区分,都可视为拥有独立代码、数据、堆栈和CPU寄存器上下文的执行实体。内核通过SCI提供创建进程(fork, exec)、停止进程(kill, exit)以及进程间通信(信号等)的API。
3. 内存管理 (MM)
内存是内核管理的另一核心资源。为了效率,内存通常按页(如4KB)管理。Linux内核包含管理可用内存的机制,以及物理地址与虚拟地址映射所需的硬件抽象。
4. 虚拟文件系统 (VFS)
VFS是Linux内核的一大亮点,它为各种不同的文件系统(如ext4, XFS, Btrfs)提供了一个统一的抽象接口。
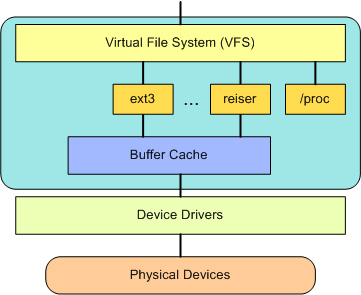
在VFS之上,是 open, close, read, write 等通用文件操作API。在VFS之下,是具体的文件系统实现(超过50种),它们如同插件一样工作。文件系统层之下是缓冲区缓存,用于优化对物理设备的访问。最底层则是具体的设备驱动程序。
5. 网络堆栈 (Network Stack)
网络子系统的设计遵循了网络协议本身的分层模型。IP协议是核心网络层,其上运行着TCP、UDP等传输层协议。再往上是套接字(Socket)层,它通过SCI向用户空间提供网络编程的标准API(如 socket, bind, connect)。网络源代码主要位于 ./linux/net 目录。
6. 设备驱动程序 (DD)
Linux内核中占比最大的代码可能就是设备驱动程序,它们负责驱动特定的硬件设备。内核源码树提供了 ./linux/drivers 目录,并进一步按设备类型细分为蓝牙、I2C、串口等子目录。
下面这张幽默的漫画,形象地展示了Linux内核中运行的各种“居民”:
四、如何高效学习内核?
既然无法通读,那么应该如何学习Linux内核呢?关键在于找到主线,由点及面,层层深入。
1. 选择一条学习主线
建议沿着以下某一条主线进行深入研究,在吃透主线的过程中,自然地向其他相关子系统扩展:
- Linux驱动架构:从字符设备等基础驱动学起,是理解内核模块、设备模型的最佳入口。
- Linux内存管理机制
- Linux进程管理与调度器
- Linux网络子系统
- Linux内核启动过程
- Linux虚拟化机制 (KVM)
- Linux内核实时化技术
为什么从驱动入手?
内核为众多外设(I2C, SPI, PCIe, 网络设备等)定义了成熟的驱动框架。我们可以从编写一个简单的LED或按键驱动模块开始,这是接触内核代码最直观、门槛相对较低的路径。
2. 利用高效的代码阅读工具
工欲善其事,必先利其器。选择一个强大的代码阅读工具至关重要。
- Source Insight:被广泛推荐的神器,尤其适合在Windows环境下进行大型代码的索引、跳转和阅读。
- VSCode 或 Vim + Ctags/Cscope:在Linux原生环境下流行的选择,灵活且强大。
阅读内核代码不是“看小说”,而是像“研究化石”或“解密”。有时需要亲手实现一遍某个功能模块,在动手和思考中才能真正理解其设计精髓。
3. 选择合适的内核版本
- 避免过于古老的版本:如0.11版,虽然代码量小(约1万行),有助于理解基本思想,但其代码结构与现代内核差异巨大,对理解当前代码帮助有限。
- 推荐较新的稳定版本:建议选择3.10版本之后的内核进行学习。从这个版本开始,设备树(Device Tree)被广泛支持,这是现代嵌入式Linux开发必须掌握的知识。
- 结合开发板实践:理论学习必须结合实践。选择一款资料齐全、社区活跃的开发板(如正点原子、友善电子等品牌),可以让你在遇到问题时快速找到解决方案,避免被一个小问题卡住数周,极大提升学习效率。
4. 培养能力,而非背诵代码
学习Linux内核,最重要的是培养写代码的能力和对整体框架的理解。内核代码由全球顶尖开发者编写,其设计体现了极高的“高内聚、低耦合”原则。阅读高质量的内核源码,仿佛在欣赏精妙的艺术品,其简洁性、精准度和背后的设计哲学常常令人震撼。
如果有人问如何提高C语言编程水平,一个极佳的建议就是:阅读Linux内核源码。
学习内核需要激情、耐性和持之以恒的精神。像“泡功夫茶”一样,沉下心来,天天读,日日练,从量变引发质变。愿每位开发者都能在Linux内核的深海中找到自己的方向,实现从程序员到系统级软件专家的蜕变。
在云栈社区这样的技术平台上,与更多同行交流分享,也能让你的内核学习之路走得更远。
 发表于 2026-2-12 09:59:06
|
查看: 260|
回复: 0
发表于 2026-2-12 09:59:06
|
查看: 260|
回复: 0
