

近期,OpenClaw在全球范围引发了广泛关注,GitHub近20万的Stars数无疑证明了其多平台对话能力的成功。不过,在我们看来,其背后能够实现跨平台、跨会话的长期AI记忆系统设计,同样值得深入探讨。
在OpenClaw中,AI可以自动记录日志并以Markdown格式存储,而开发者也能手动编辑这些文件,提炼长期原则。这使得AI的记忆变得前所未有的可控、透明且易于管理。正是这套系统的理念打动我们,促使我们将其核心设计抽象出来,构建了memsearch。现在,任何开发者都能为自己的AI Agent注入持久、透明且可控的记忆能力,不再受限于OpenClaw的单一形态。
项目地址:https://github.com/zilliztech/memsearch (MIT开源,可直接商用)
先搞懂:OpenClaw的记忆系统,到底牛在哪?
要理解OpenClaw的记忆,首先得分清两个容易混淆的概念:上下文和记忆。
- 上下文:主要包括四部分——静态和条件化的系统提示词、如AGENTS.md和SOUL.md这类引导文件构成的项目上下文、过往的对话历史(含压缩摘要),以及用户当前的消息。本质上,这就是Agent处理每次请求时能接收到的所有信息,内容相对精简。
- 记忆:则是持久化存储在本地磁盘中的数据,是历史会话、文件、用户偏好等的总和,属于全量存储。
OpenClaw最具启发性的设计在于,其所有记忆都以Markdown格式存储在本地文件中。AI会自动写入,人类也可以直接手动编辑这些.md文件。而向量数据库在这里仅作为派生索引存在。一旦Markdown文件被修改并保存,系统会自动对新内容重新建立索引,无需额外操作。
这种“Markdown优先”的模式,相比Mem0、Zep等将向量库作为唯一记忆来源的主流方案,有三个显著优点:透明(格式可读)、可编辑(改完即生效)、可移植(复制文件即迁移)。
但问题也随之而来:要使用这套记忆系统,你必须运行整个OpenClaw生态(Gateway进程、消息平台连接等),这对于只想为自家Agent添加持久记忆的开发者来说,门槛过高。
因此,我们创造了memsearch:保留OpenClaw的核心记忆理念,剥离所有冗余,做成一个能无缝集成到任何Agent框架中的轻量级库。
memsearch核心思路:可编辑、插件化、高度透明
memsearch完全继承了“Markdown优先”的理念。所有AI记忆都以明文形式存储在本地文件夹中,结构一目了然:
~/your-project/
└── memory/
├── MEMORY.md # 手写的长期记忆
├── 2026-02-09.md # 今天的工作日志
├── 2026-02-08.md
└── 2026-02-07.md
在此基础上,Milvus仅作为辅助工具,用于为Markdown内容建立索引以加速搜索。即使你删除了向量数据库文件,只要Markdown文件还在,重新索引几分钟内即可恢复所有记忆。
这种设计带来了多重好处:
1. 透明可读,调试容易
传统方案中,AI回答出错时,你很难追溯它基于什么记忆做出了判断,看到的往往是难以理解的向量和JSON。而在memsearch方案下,直接打开memory文件夹下的对应Markdown文件,就能看到完整记忆。如果AI“说错话”,可能是某段记忆过时了。用任何编辑器修改后保存,系统会自动重新索引,问题迎刃而解。
2. 版本控制,团队协作
传统方案中,记忆的修改历史难以追溯,协作成本高。memsearch方案则可以直接使用Git管理Markdown文件,通过git log和git diff命令清晰追溯所有修改。在团队代码评审时,你甚至可以直接评审AI的记忆变更,所有增删一目了然。
3. 迁移自由,不被锁定
想从Mem0迁移到Zep?传统方案需要复杂的数据导出、格式转换和导入。而memsearch的记忆是纯明文Markdown,迁移成本为零。无论是换电脑、换embedding模型,还是将向量数据库从本地部署切换到云端服务,都只需极简的配置变更,Markdown文件本身无需任何改动。
4. 人机共创,各司其职
传统方案下,人类想修改AI记忆,需要了解API并编写代码。memsearch则实现了自然的分工协作:
- AI负责:自动生成每日日志(如
YYYY-MM-DD.md),记录执行细节。
- 人类负责:手动维护
MEMORY.md,提炼长期有效的原则和知识。
你和AI实质上是在共同编辑同一套Markdown文档——无需懂代码,打开文件就能修改。这种协作模式,在传统的数据库方案中几乎无法实现。
架构拆解:四大流程,看懂memsearch怎么工作
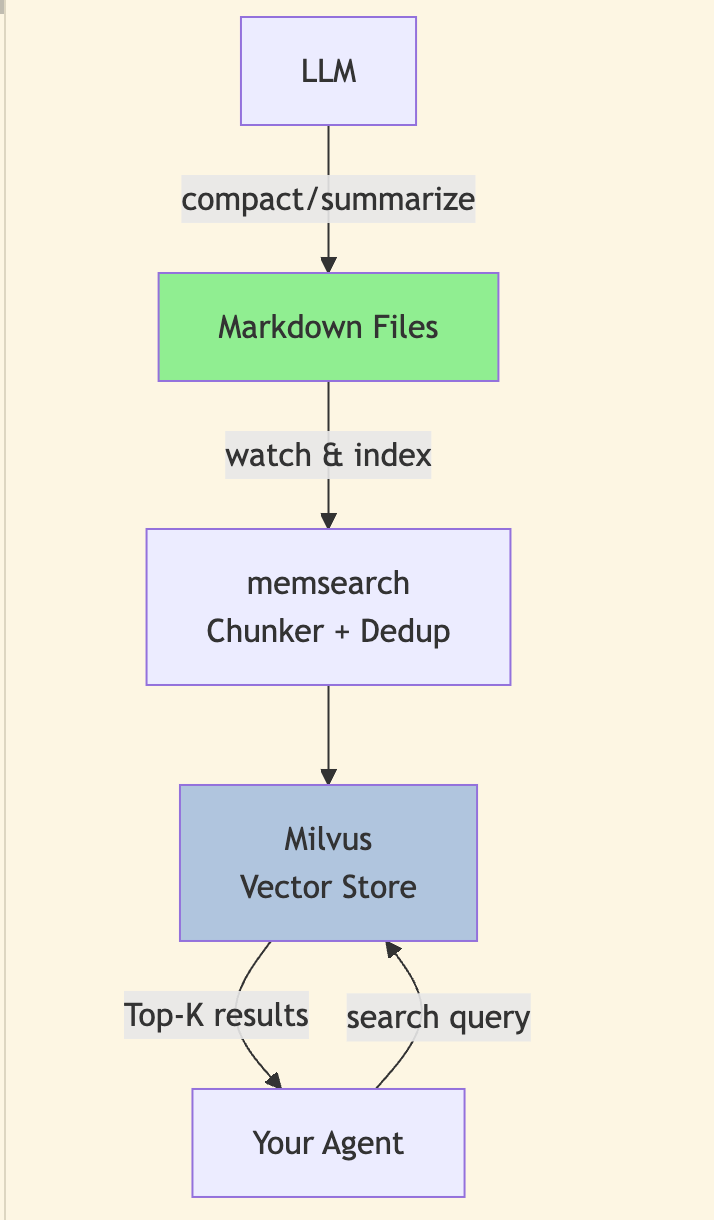
memsearch的核心工作流程包含四个环节:监听(Watch)→ 索引(Index)→ 搜索(Search)→ 压缩(Compact)。
流程 1:监听(Watch)文件变化
此流程负责监听memory文件夹下的所有Markdown文件。当文件被修改并保存后,系统会等待1500毫秒(经验值,平衡了响应速度与资源消耗)再自动触发重新索引,采用了防抖设计以避免频繁操作。
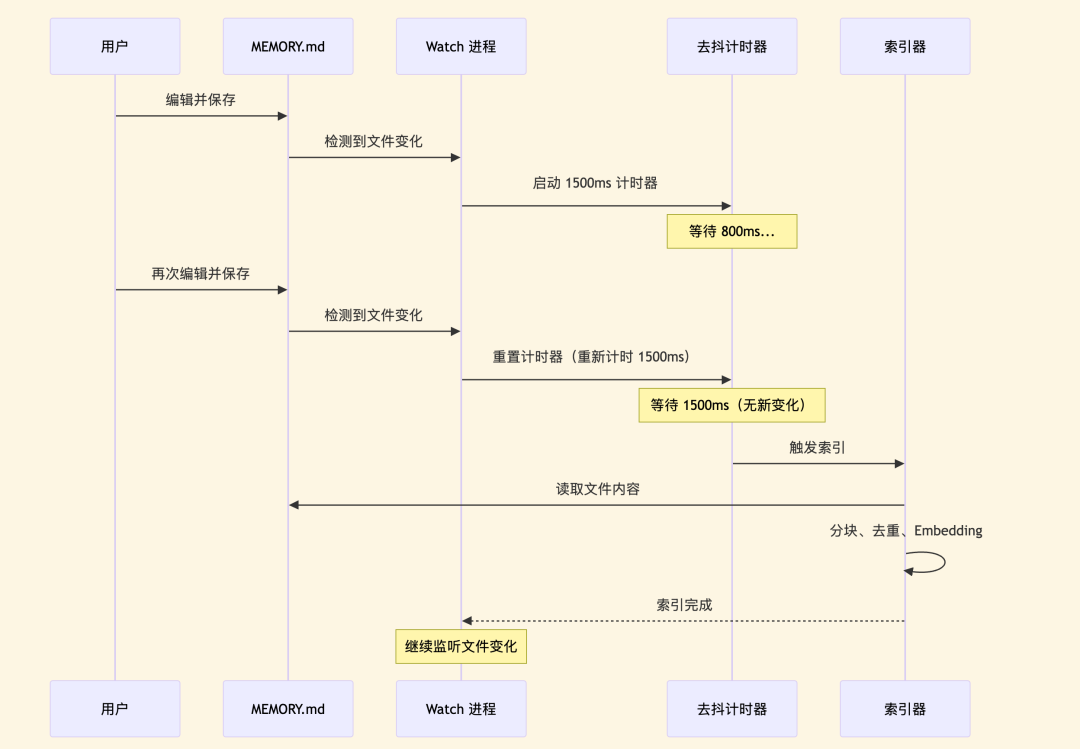
启动监听进程后,你可以随时手动修改MEMORY.md(例如添加新的API文档链接),保存后无需重启服务,下一次AI查询就能用到更新后的记忆。
流程 2:索引(Index):分块、去重、索引
这是性能关键,主要做三件事:
- 分块:按标题和段落进行语义切分,确保每个信息块(Chunk)语义完整。
- 去重:计算每个Chunk的SHA-256哈希,重复内容只索引一次,可节省大量Embedding API调用成本。
- Chunk ID设计:采用
hash(source_path:start_line:end_line:content_hash:model_version)格式。其中包含model_version至关重要,它使得在更换Embedding模型时,系统能自动识别并重新处理过期的索引,无需人工清理。
流程 3:搜索(Search):混合搜索
采用向量搜索(70%权重)+ BM25关键词搜索(30%权重)的混合模式,兼顾语义相似性与精确匹配。
- 向量搜索:负责语义匹配,例如查询“Redis缓存配置”能匹配到“Redis L1 cache with 5min TTL”。
- BM25搜索:负责精确匹配,例如查询“PostgreSQL 16”不会匹配到“PostgreSQL 15”。
搜索结果默认返回Top-K个Chunk的摘要(截断至200字),需要时再调用完整内容,以节省LLM的上下文窗口。
流程 4:压缩(Compact)旧记忆
随着Agent长期运行,旧记忆会占用大量空间并可能干扰回答准确性。Compact流程会调用LLM总结所有历史记忆,生成精简摘要,并视情况删除或归档原始文件。此过程可手动触发,也可配置为定时自动执行。
实操指南
memsearch支持Python API和CLI工具两种使用方式,适配不同开发场景。
数据库选型建议:
- Milvus Lite(默认):本地
.db文件,零配置,适合个人开发。
- Milvus Server:自托管服务,支持多Agent共享数据,适合团队环境。
- Zilliz Cloud:全托管服务,自动扩容备份,适合生产环境。
三种模式代码接口完全一致,仅需修改一个配置项即可切换。同时,memsearch支持多种Embedding提供商(OpenAI、Google、Voyage、Ollama及本地模型)。
第一步:快速安装
pip install memsearch
第二步:两种使用方式
方式1:Python API(集成到Agent框架)
以下是一个完整的、带记忆的Agent循环示例:
from openai import OpenAI
from memsearch import MemSearch
llm = OpenAI()
ms = MemSearch(paths=["./memory/"])
async def agent_chat(user_input: str) -> str:
# 1. Recall — 搜索相关记忆
memories = await ms.search(user_input, top_k=3)
context = "\n".join(f"- {m['content'][:200]}" for m in memories)
# 2. Think — 调用 LLM
resp = llm.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": f"Memories:\n{context}"},
{"role": "user", "content": user_input},
],
)
# 3. Remember — 写入 markdown,更新索引
save_memory(f"## {user_input}\n{resp.choices[0].message.content}")
await ms.index()
return resp.choices[0].message.content
核心逻辑遵循 Recall(搜索记忆)→ Think(LLM推理)→ Remember(写入记忆) 的闭环,可轻松集成到LangChain、AutoGPT或任何自研的Agent框架中。
方式2:CLI工具(快速操作与调试)
memsearch index ./docs/ # 索引文件
memsearch search "Redis caching" # 搜索
memsearch watch ./docs/ # 监听文件变化
memsearch compact # 压缩旧记忆
和其他方案对比:我们到底不一样在哪?
面对Mem0、Zep等现有记忆方案,memsearch的差异化价值在哪里?我们通过一张对比表来清晰呈现:
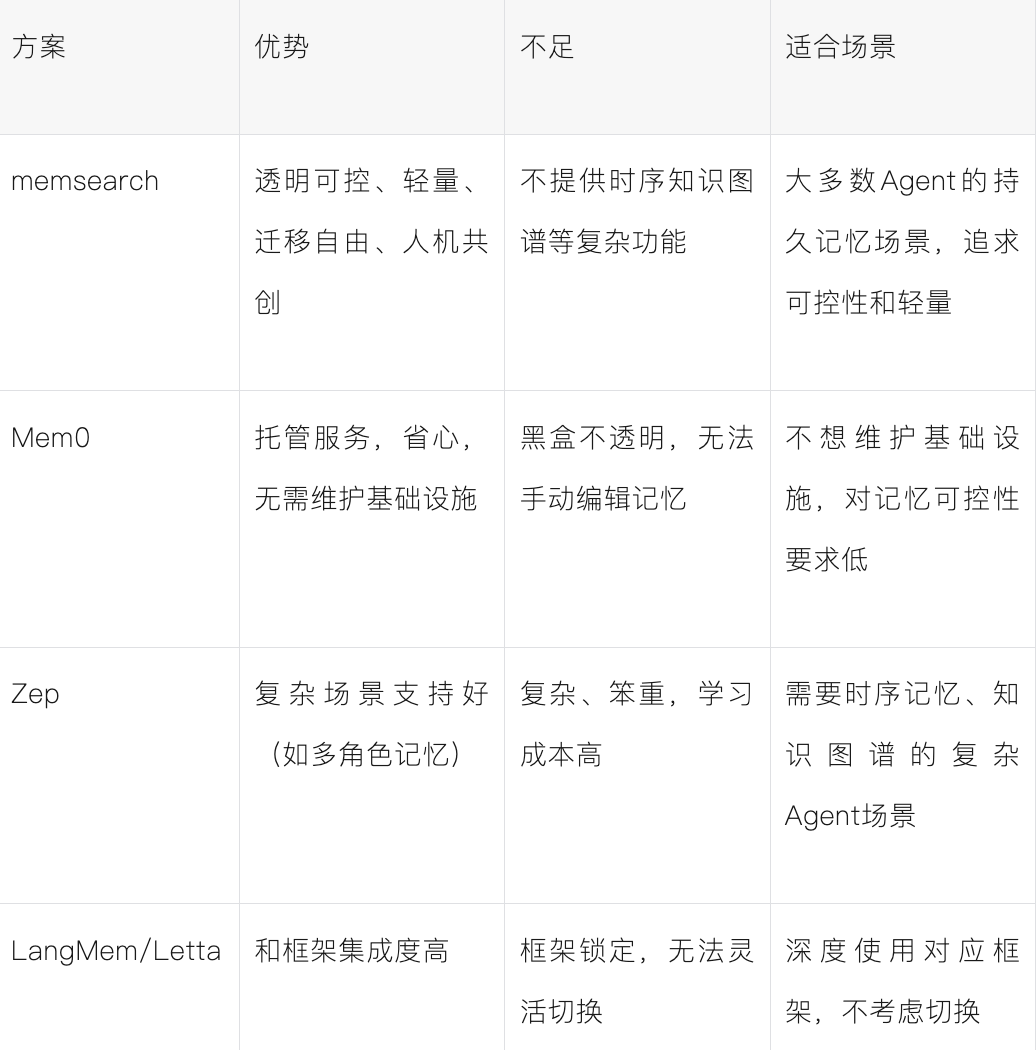
memsearch的定位非常明确:为大多数追求可控性、轻量化和迁移自由的Agent持久记忆场景,提供一个透明、可编辑的开源解决方案。它不试图解决所有复杂问题(如时序知识图谱),而是在核心痛点——记忆的透明与可控上做到极致。
最后,欢迎各位开发者试用memsearch,并反馈问题或贡献代码。
项目地址:https://github.com/zilliztech/memsearch
文档页面:https://zilliztech.github.io/memsearch/
 发表于 2026-2-12 11:46:00
|
查看: 388|
回复: 0
发表于 2026-2-12 11:46:00
|
查看: 388|
回复: 0
